核心观点: 在人工智能迈向真正理解、预测和重构现实世界的道路上,“世界模型”(World Model)是下一代智能的核心引擎。美团 LongCat 团队发布的 LongCat-Video 视频生成模型,正是通过长视频生成任务,压缩和模拟物理规律、时空演化等知识,为构建世界模型奠定了关键基础。

一、 核心定位与能力
LongCat-Video 不仅是一个高性能的视频生成模型,更是美团探索世界模型的第一步。它旨在通过精准重构真实世界的运行状态,支持未来的自动驾驶、具身智能等深度交互业务场景。
-
世界模型引擎: 赋予 AI “看见”世界运行本质的能力,通过视频生成任务来模拟、推演真实世界的运行逻辑。
-
长视频连贯生成: 凭借原生视频续写任务的预训练,实现 分钟级长视频连贯输出,从根本上保障跨帧时序一致性和物理运动合理性。
二、 技术亮点:三大创新与效率飞跃
LongCat-Video 凭借其统一的模型架构和多重优化策略,在性能和效率上达到了行业顶尖水平。
1. 统一模型架构:多任务一体化视频基座
基于 Diffusion Transformer(DiT)架构,LongCat-Video 创新性地通过**“条件帧数量”**实现任务区分,形成“文生 / 图生 / 视频续写”的完整任务闭环,无需额外模型适配:
-
文生视频: 无条件帧输入,可生成 720p、30fps 高清视频,语义理解和视觉呈现能力达开源 SOTA 级别。
-
图生视频: 输入 1 帧参考图,严格保留主体属性和风格,动态过程自然且符合物理规律。
-
视频续写(核心差异化能力): 依托多帧前序内容续接视频,为长视频生成提供原生技术支撑。
2. 长视频生成:原生支持 5 分钟级连贯输出
LongCat-Video 稳定输出 5 分钟级别的长视频且无质量损失,处于行业顶尖水平。通过 视频续写预训练、Block-Causual Attention 机制和 GRPO 后训练,有效规避了色彩漂移、画质降解、动作断裂等长视频生成的行业痛点。
-
效率突破: 结合块稀疏注意力(BSA)与条件 token 缓存机制,打破了长视频生成中“时长与质量不可兼得”的瓶颈。
3. 高效推理:三重优化,速度提升 10.1 倍
针对高分辨率、高帧率视频的计算瓶颈,模型通过“二阶段生成 + 稀疏注意力 + 模型蒸馏”三重优化,将视频推理速度提升至 10.1 倍:
-
二阶段粗到精生成(C2F): 先生成低分辨率视频,再经 LoRA 超分至 720p、30fps,兼顾降本提效与画面细节。
-
块稀疏注意力(BSA): 将计算量降至标准密集注意力的 10% 以下,支持稀疏注意力适配并行训练。
-
模型蒸馏优化: 结合 CFG 与一致性模型(CM)蒸馏,将采样步骤从 50 步减少至 16 步。
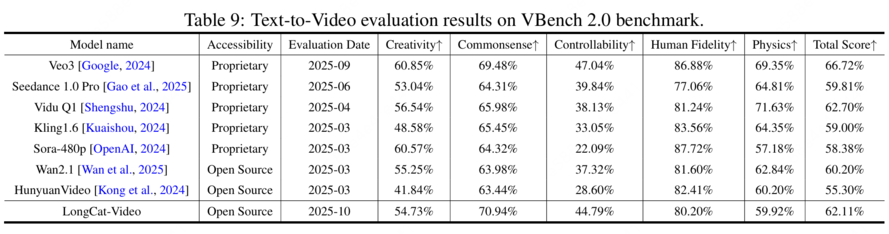 三、 模型性能:开源 SOTA 级综合表现
三、 模型性能:开源 SOTA 级综合表现
LongCat-Video 是一款拥有 136 亿参数的视频生成基座模型,在内部与公开基准测试中,其综合能力已跻身开源领域 SOTA(State-of-the-Art)级别。
-
在文生视频、图生视频两大核心任务中,综合性能表现优秀。
-
在文本对齐度、运动连贯性等关键指标上展现出显著优势,并于 VBench 等公开基准测试中整体表现优异。