部分复制概述
MySQL默认的复制是全库复制,从库会执行所有主库发送过来的事务。
但某些应用场景我们并不需要全库复制,例如将不同的数据分散到不同的从库上或者考虑网络带宽不充足时,
此时我们需要用到复制过滤来控制仅复制数据库的一部分。
MySQL实现部分复制的方式是对binlog进行过滤,有两类过滤方法:
主库过滤:主库控制事务是否写入binglog,如果未将事务写入binlog,则不会复制该事务。
从库过滤:主库将事务全量写入binlog并发送到从库,由从库决定执行哪些事务。
MySQL的部分复制可以通过配置数据库级复制或表级复制
数据库级复制选项:
--binlog-do-db:主库选项,匹配的数据库记录binlog
--binlog-ignore-db:主库选项,匹配的数据库不记录binlog
--replicate-do-db:从库选项,匹配的数据库进行复制
--replicate-ignore-db:从库选项,匹配的数据不进行复制
表级复制选项:
--replicate-do-table :从库选项,匹配的表进行复制
--replicate-ignore-table :从库选项,匹配的表不进行复制
--replicate-wild-do-table :从库选项,匹配的表进行复制,可以使用通配符
--replicate-wild-ignore-table:从库选项,匹配的表不复制,可以使用通配符
以上参数可以配合使用,当需要多个复制选项时,只需要重复指定相关参数即可,但为了防止理解混乱,尽量不要将do和ignore选项混合使用。
MySQL 5.7以后,可以使用change replication filter语句动态地设置由这些选项指定的过滤器,
而不需要重启MySQL实例(但最好同时把参数加入配置文件防止丢失)。
例如下列语句可以动态设置复制过滤器:
change replication filter replicate_do_db=(db1); -- 仅复制db1
change replication filter replicate_do_table=(db1.t1); -- 仅复制db1.t1表
change replication filter replicate_wild_do_table=(db1.%); --复制db1下所有表
change replication filter replicate_do_db=(); -- 清除复制过滤
1.1主库过滤
在主库端,可以使用--binlog-do-db和--binlog-ignore-db选项来控制要在二进制日志中记录更改的数据库。
但binlog除了复制还有恢复的作用,如果数据库崩溃时又没有binlog,可能导致数据丢失,
这在生产环境是不可接受的。因此不考虑主库过滤选项,推荐的方法是在从库上使用过滤。
1.2从库过滤
在从库端,可以用的--replicate-*参数来控制过滤选项。从库匹配过滤选项时,有两种过滤级别:
数据库级选项(--replicate-do-db,--replicate-ignore-db)
表级选项(-- replicate_do_ table,-- replicate_ignore_ table)
评估过滤选项时,从库会先评估数据库级的过滤选线,如果未使用任何数据库级选项,则继续检查表级的过滤选项。
数据库级选项对DML语句的影响
在评估数据库级过滤选项时,首先要先判断语句的归属数据库。
判断的方式取决于二进制日志的格式:
binlog是row格式,那修改的数据的数据库就是归属数据库。
binglog是statement格式,默认数据库(use db)指定的数据库就是归属数据库。
二、数据库级复制
数据库级复制只考虑从库的选项(--replicate-do-db,--replicate-ignore-db),
主库的binlog过滤方式存在风险,通常不会采用。
下面演示从库数据库级复制选项下,不同的日志格式(statement / row)对DML和DDL语句的影响。
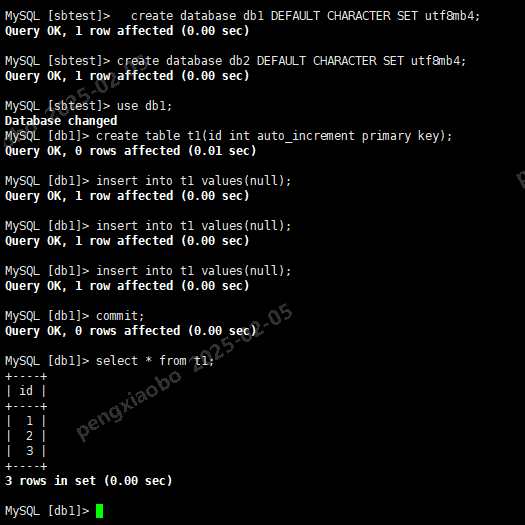
先准备测试环境,在默认全库复制配置下,主库执行下列SQL,新建数据库db1,db2,
并在db1中新建表t1并插入数据;
create database db1 DEFAULT CHARACTER SET utf8mb4; create database db2 DEFAULT CHARACTER SET utf8mb4; use db1; create table t1(id int auto_increment primary key); insert into t1 values(null); insert into t1 values(null); insert into t1 values(null); commit; select * from t1;
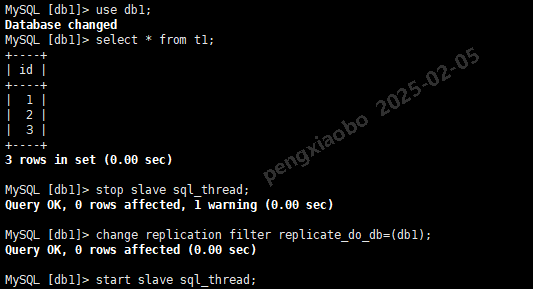
use db1; select * from t1; stop slave sql_thread; change replication filter replicate_do_db=(db1); -- 设置仅复制db1 start slave sql_thread;
2.1数据库级复制DML语句测试
主库,将日志格式设置为statement,从db2跨库删除db1的数据(id=1),主库确认数据已经删除。
use db2; -- 默认数据库选择db2 set binlog_format=statement; -- 设置日志格式为statement delete from db1.t1 where id=1; -- 从db2删除db1中的数据 commit; select * from db1.t1;

select * from db1.t1; -- 从库数据未删除

use db2; set binlog_format=row; delete from db1.t1 where id=2; -- 跨库删除db1的数据 commit;
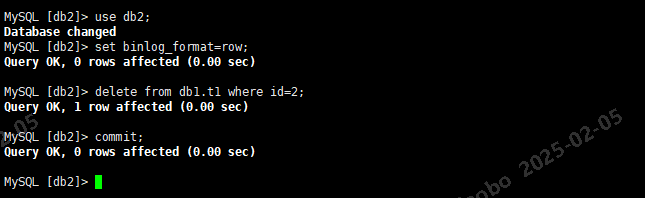
从库上:

根据实验结果得出:数据库级别的复制过滤选项,statement格式DML无法跨库复制(需要用use db指定正确的数据库), row格式DML可以跨库复制(无需指定默认数据库)。
2.2数据库级复制DDL语句测试
下面测试不同日志格式下DDL的复制情况,在主库执行下列SQL,默认数据库选择db2(我们的复制匹配数据库是db1),观察不同日志格式下db2执行DDL对db1的影响:
use db2; set binlog_format=statement; drop table db1.t1; -- 跨库删除db1的表 desc db1.t1;
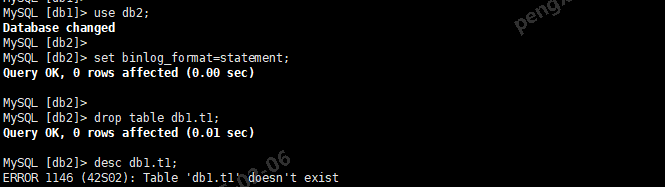
从上面输出看到主库的db1.t1被删除,回到从库执行 desc db1.t1,表没有被删除,原因是在statement格式下,use db2选择了db2,则所有语句归属都是db2,即使删除跨库删除db1的表,语句也不会生效。
从库上:

使用row格式再试一次,这次在主库新建一张表t2:
use db2; set binlog_format=row; create table db1.t2(id int auto_increment primary key); desc db1.t2;
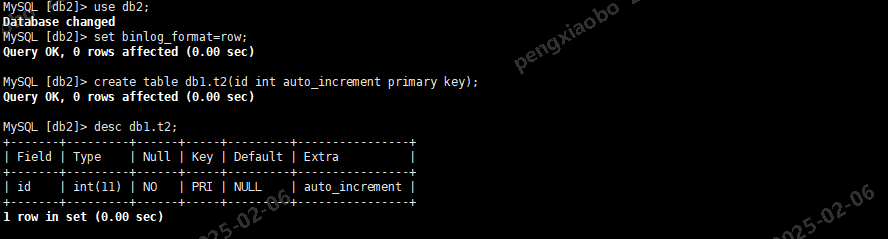
从上面输出看到主库的db1.t2创建成功,回到从库。发现表依然没有创建(这里和DML语句表现不一样, DML在row格式下可以跨库,而DDL依然不可以跨库)
无论日志是statement格式还是row格式,DDL都无法跨库。原因是即是设置日志格式为row,
但DDL依然会使用statement格式的日志。所以我们看到设置什么日志格式都无法跨库执行DDL。
这个特性在生产环境升级时需要特别注意,如果要更新数据库的结构,需要用use db切换到对应的数据库执行,
否则复制可能丢失。
总结:使用数据库级选项时
binlog的格式是statement或者mixed,DML和DDL复制是否生效都与当前默认数据库有关。
binlog的格式是row格式时,DDL复制是否生效与当前默认数据库有关,DML复制是否生效与当前数据库无关。
三、表级复制
当满足以下两个条件之一时,从库才会检查并评估表选项:
1、没有数据库选项,直接评估表选项。
2、有数据库选项,评估完成后再评估表选项。
数据库级过滤选项优先级高,只有评估数据库级后才会进行表级复制选项:
1、对于--replicate-do-table或--replicate-wild-do-table选项,则事件需要匹配选项才会执行,剩余的事件都不会执行。
2、对于--replicate-ignore-table或--replicate-wild-ignore-table选项,则事件需要匹配选项才会不执行,剩余的事件都会被执行。
如果在同一个SQL中同时涉及do和ignore的表,最终复制结果取决于日志的格式:
1、row格式,do规则生效,ignore规则生效,即两条规则都生效。
2、statement格式,do规则生效,ignore规则失效,即SQL所有的更新都会被复制。
3.1表级复制测试
下面测试在同一个SQL中混合了do_table和ignore_table选项时,不同日志格式下数据的选项:
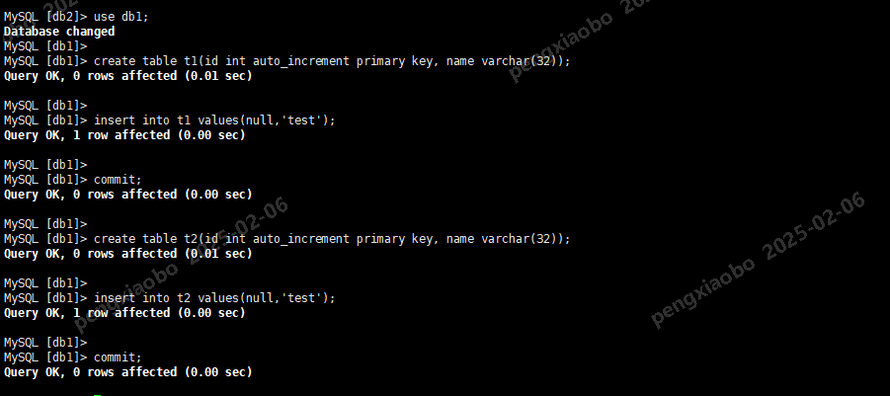
主库执行下列SQL在db1创建测试表t1和t2:
use db1; create table t1(id int auto_increment primary key, name varchar(32)); insert into t1 values(null,'test'); commit; create table t2(id int auto_increment primary key, name varchar(32)); insert into t2 values(null,'test'); commit;
从库上:
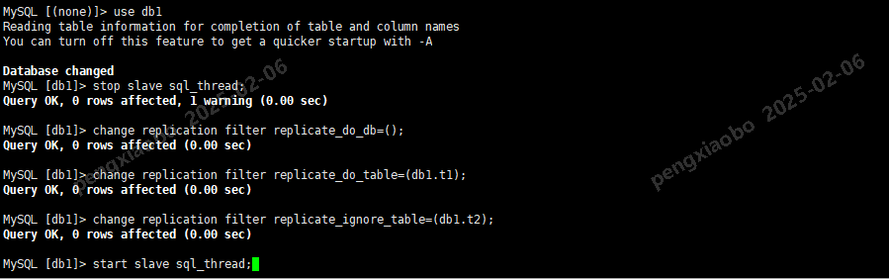
从库执行下列SQL,清除数据库级过滤选项,仅测试表级过滤选项(db1.t1)。
stop slave sql_thread; change replication filter replicate_do_db=(); -- 关闭db级过滤选项 change replication filter replicate_do_table=(db1.t1); -- 表级复制db1.t1 change replication filter replicate_ignore_table=(db1.t2); -- 表级过滤db1.t2(不复制) start slave sql_thread;
主库设置日志格式为statement,执行下面SQL,update语句同时更新了需要复制的表t1,和不需要复制的表t2
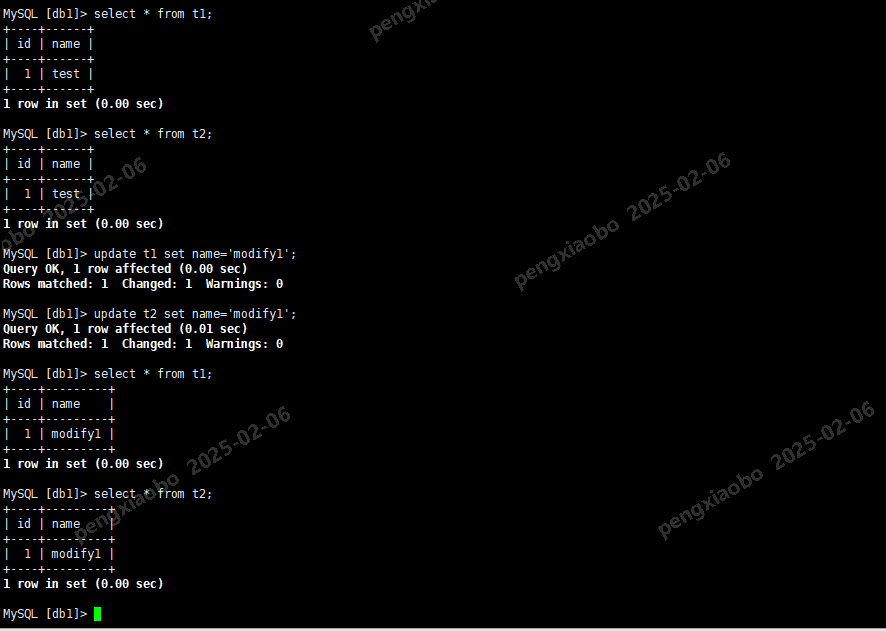
select * from t1; select * from t2; set binlog_format=statement; -- 设置日志格式为statement update t1 set name='modify1'; -- 同时更新2张表 update t2 set name='modify1'; commit; select * from t1; select * from t2;
从库上:
在从库查看复制结果,当同一个SQL中出现replicate_do_table(t1)和replicate_ignore_table(t2)时, 如果binlog格式为statement,忽略的选项不生效。t1和t2都更新了。
select * from t1; select * from t2;
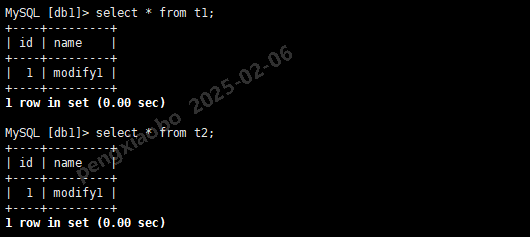
set binlog_format=row; -- 设置日志格式为row update t1 set name='modify2'; -- 同时更新2张表 update t2 set name='modify2'; commit;
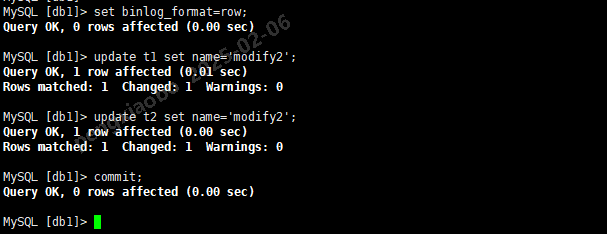
从库上:
从库查看复制结果,t1更新复制了,t2更新未复制,两个选项均生效了:
select * from t1; select * from t2;
