Oracle在线重定义介绍
• Oracle 在线重定义(Online Redefinition)是一种功能,允许数据库管理员在不需要停
止或显著影响数据库正常操作的情况下,对数据库表进行结构化修改。
• 这个功能在大型企业级数据库环境中非常重要,因为停机时间可能导致业务中断和收入
损失。
• Oracle 在线重定义功能通过`DBMS_REDEFINITION` 包提供,允许在表数据仍在被查询
和修改的同时,对表进行复杂的结构化修改,如添加或删除列、重组表空间、重新定义
分区等。
可以实现的功能:
•将表移动到其它表空间
•增加、修改或者删除表的字段
•将非分区表转换为分区表
•修改表的分区结构
•减少表的碎片
•将普通表转换为索引组织表
以下限制适用于在线重新定义表
◼ 主键或伪主键要求:
➢ 如果使用主键或伪主键(所有列都有非空约束的唯一键或约束)重新定义,则重新定义后的表必须保留相同的主键或伪主键
列。
➢ 如果使用行ID(rowid)重新定义,则表不能是索引组织表(index-organized table)。
◼ 物化视图日志:
➢ 重新定义具有物化视图日志的表后,任何依赖的物化视图在随后的刷新中必须进行完全刷新。
◼ 复制限制:
➢ n-way master configuration中的表可以重新定义。
➢ 不允许水平子集(表中行的子集)、垂直子集(表中列的子集)和列转换进行在线重定义
◼ 溢出表限制:
➢ 索引组织表的溢出表不能单独在线重新定义。
◼ 细粒度访问控制限制:
➢ 具有细粒度访问控制(行级安全性)的表不能在线重新定义。
◼ 闪回数据归档限制:
➢ 启用了闪回数据归档的表不能在线重新定义。
➢ 不能为中间表启用闪回数据归档。
◼ BFILE列限制:
➢ 具有BFILE列的表不能在线重新定义。
◼ LONG和LONG RAW列要求:
➢ 具有LONG列的表可以在线重新定义,但这些列必须转换为CLOB。
➢ LONG RAW列必须转换为BLOB。
➢ 具有LOB列的表是可接受的。
◼ 系统架构限制:
➢ SYS和SYSTEM架构中的表不能在线重新定义。
◼ 临时表限制:
➢ 临时表不能重新定义。
◼ 行子集限制:
➢ 表中的行子集不能重新定义。
◼ 列映射限制:
➢ 在将中间表的列映射到原始表时,只能使用简单的确定性表达式、序列和SYSDATE。例如,不允许使用子查询。
◼ 新列的非空约束:
➢ 如果在重新定义过程中添加了新列且这些列没有列映射,则在重新定义完成之前,这些列不能声明为非空。
◼ 参照约束限制:
➢ 被重新定义的表与中间表之间不能有任何参照约束。
◼ 日志记录限制:
➢ 表重新定义不能以NOLOGGING方式进行。
◼ 物化视图日志和队列表的限制:
➢ 对于物化视图日志和队列表,在线重新定义仅限于物理属性的更改。不允许水平或垂直子集,也不允许任何列转换。列映射字符串的唯一有效值
是NULL。
◼ 分区表限制:
➢ 如果分区表包含一个或多个嵌套表,则不能对该表进行在线重新定义。
◼ VARRAY和嵌套表转换:
➢ 可以使用CAST操作符在列映射中将VARRAY转换为嵌套表。但不能将嵌套表转换为VARRAY。
◼ 顺序列映射限制:
➢ 当DBMS_REDEFINITION.START_REDEF_TABLE过程的col_mapping参数中的列包含序列时,orderby_cols参数必须为NULL。
◼ 多表会话限制:
➢ 如果表通过引用分区相关联,则不能在不同的DBMS_REDEFINITION会话中同时对多个表运行在线重新定义。
◼ 对象表或XMLType表的限制:
➢ 如果其他表有引用被重新定义表的REF列,在线重新定义对象表或XMLType表可能会导致其他表中的REF悬空。
https://docs.oracle.com/cd/E11882_01/server.112/e25494/tables.htm#i1006754
总体工作过程
◼ 选择执行方式:主键还是ROWID
◼ 检查选择的表是否可以执行在线重定义: dbms_redefinition.can_redef_table
◼ 按照要求创建空的中间表
◼ 开始进行在线重定义dbms_redefinition.start_redef_table
◼ 复制依赖对象(自动或者手动)
◼ 同步表的数据dbms_redefinition.sync_interim_table
◼ 完成在线重定义dbms_redefinition.finish_redef_table
需要注意的细节
◼ 选择执行方式:主键还是ROWID
➢ 主键:如果表上有主键,那么首选的方式是主键
➢ ROWID:如果表上没有主键,那么只能使用ROWID方式,此时需要注意以下几点:
✓ 索引索引表不能使用rowid方式
✓ Rowid方式会在最终表上生成一个名称为M_ROW$$的隐藏字段
✓ 在完成在线重定义之后来,可以使用ALTER TABLE ... DROP UNUSED COLUMNS来删除这个字段
◼ 创建空的中间表,有两种选择:
➢ 只创建空表,原表所有对象使用自动复制的方式
➢ 手动按照原表建立所有对象,并且将中间表的对象与原表的对象一对一进行注册
另外,中间表最终会替换原表,因此中间表需要按照期望的结构来进行创建,比如字段数量,
字段类型,分区等等。
◼ 复制依赖对象(自动或者手动):
➢ 使用自动方式,需要建立一个空的中间表,不要建任何表的相关对象,由
dbms_redefinition.copy_table_dependents 这个过程自动建立中间表的相关对象,并且一对一地与原表进行关
联注册,最后在将中间表切换为原表时,所有对象都会改名,与原表的对象名称一致。
➢ 使用手动方式,在建立中间表时,需要手动按照原表建立所有对象,并且将中间表的对象与原表的对象使用
dbms_redefinition.register_dependent_object 过程进行一对一地关联注册,注册过的对象,在最后切换为原表
时会自动改名,与原表的对象名称一致。
◼ 同步表的数据dbms_redefinition.sync_interim_table :
➢ 这个过程是可以多次重复执行的
➢ 如果表比较大,可以在平时业务不忙时定期发起表的数据同步,这样可以减少最后将中间表切
换为原表的时间窗口。
◼ 完成在线重定义dbms_redefinition.finish_redef_table :
➢ 这个过程会有一个短暂的锁表操作
➢ Finish操作会等待所有DML操作提交,然后才去锁表,完成中间表到原表的切换
➢ 如果使用rowid方式,最终表会出现一个名为M_ROW$$的隐藏字段,可以使用ALTER TABLE...
DROP UNUSED COLUMNS 语句删除这个隐藏字段
➢ 这个隐藏字段不会重复增加,即使这张表经过10次在线重定义,也只会有一个M_ROW$$ 的隐藏
字段
在线重定义的结果
◼ 原始表重新定义
➢ 原始表将被重新定义,包含中间表的列、索引、约束、授权、触发器和统计信息
◼ 依赖对象重命名
➢ 注册的依赖对象(通过REGISTER_DEPENDENT_OBJECT显式注册或通过COPY_TABLE_DEPENDENTS隐式注
册)将自动重命名,以便重新定义后的表上的依赖对象名称与重新定义前相同。
➢ 涉及中间表的参照约束现在涉及重新定义后的表,并且这些约束已启用。
◼ 转移与删除
➢ 重新定义前定义在原始表上的任何索引、触发器、物化视图日志、授权和约束都将被转移到中间表,并在用户
删除中间表时被删除。
➢ 重新定义前涉及原始表的任何参照约束现在涉及中间表,并且这些约束已禁用。
◼ 对象失效
➢ 一些PL/SQL对象、视图、同义词和其他表依赖对象可能会失效。
➢ 只有那些依赖于表中已更改元素的对象会失效。
Oracle在线重定义使用场景,下面是一个具体的案例
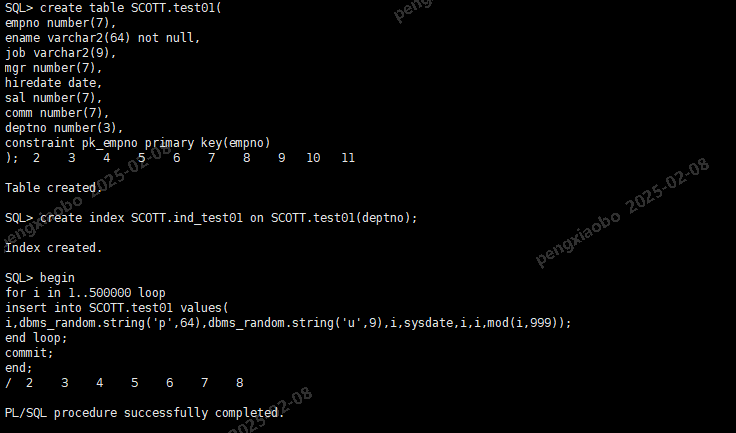
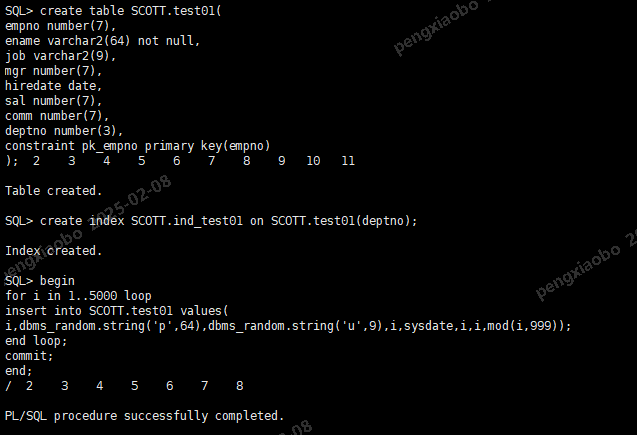
原表
drop table SCOTT.test01;
create table SCOTT.test01(
empno number(7),
ename varchar2(64) not null,
job varchar2(9),
mgr number(7),
hiredate date,
sal number(7),
comm number(7),
deptno number(3),
constraint pk_empno primary key(empno)
);
create index SCOTT.ind_test01 on SCOTT.test01(deptno);
begin
for i in 1..500000 loop
insert into SCOTT.test01 values(
i,dbms_random.string('p',64),dbms_random.string('u',9),i,sysdate,i,i,mod(i,999));
end loop;
commit;
end;
/
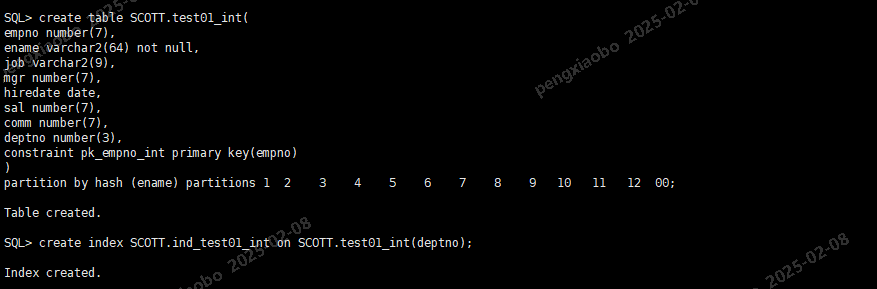
中间表
drop table SCOTT.test01_int; create table SCOTT.test01_int( empno number(7), ename varchar2(64) not null, job varchar2(9), mgr number(7), hiredate date, sal number(7), comm number(7), deptno number(3), constraint pk_empno_int primary key(empno) ) partition by hash (ename) partitions 100; create index SCOTT.ind_test01_int on SCOTT.test01_int(deptno);
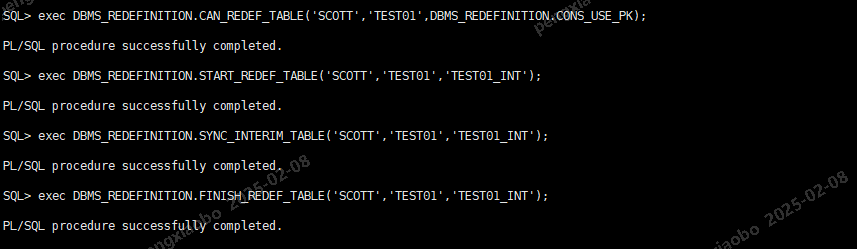
在线重定义执行过程
SQL> exec DBMS_REDEFINITION.CAN_REDEF_TABLE('SCOTT','TEST01',DBMS_REDEFINITION.CONS_USE_PK);
SQL> exec DBMS_REDEFINITION.START_REDEF_TABLE('SCOTT','TEST01','TEST01_INT');
PL/SQL procedure successfully completed.
SQL> exec DBMS_REDEFINITION.SYNC_INTERIM_TABLE('SCOTT','TEST01','TEST01_INT');
PL/SQL procedure successfully completed.
SQL> exec DBMS_REDEFINITION.FINISH_REDEF_TABLE('SCOTT','TEST01','TEST01_INT');
PL/SQL procedure successfully completed.
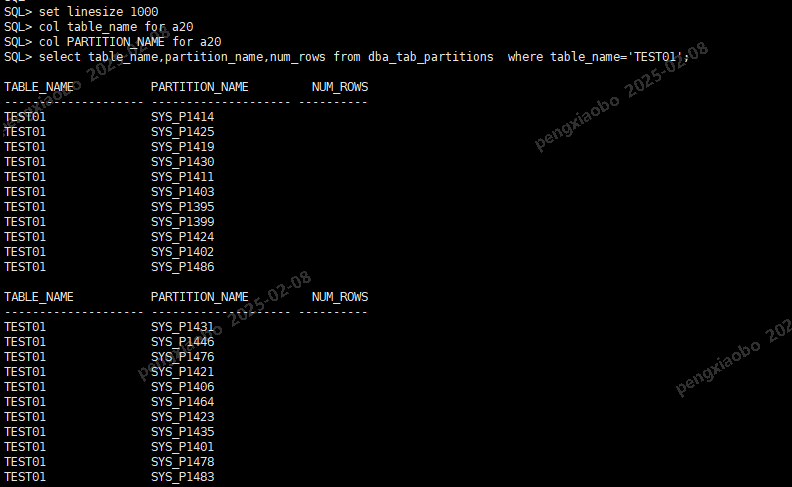
结果:
SQL> set linesize 1000 SQL> col table_name for a20 SQL> col PARTITION_NAME for a20 SQL> select table_name,partition_name,num_rows from dba_tab_partitions where table_name='TEST01';
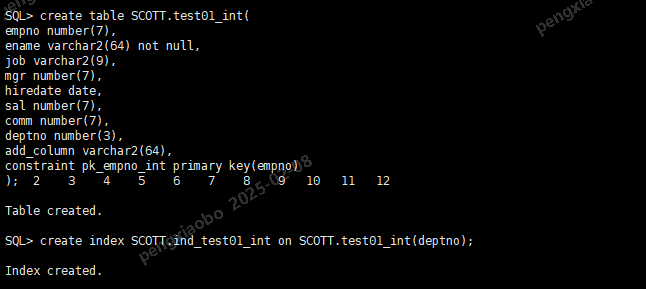
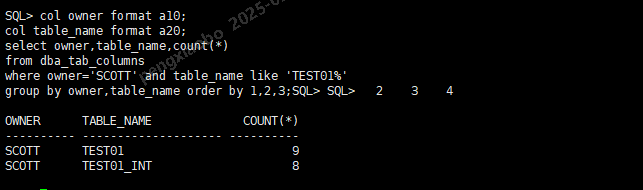
对表增加一个字段
-- 原表
drop table SCOTT.test01;
create table SCOTT.test01(
empno number(7),
ename varchar2(64) not null,
job varchar2(9),
mgr number(7),
hiredate date,
sal number(7),
comm number(7),
deptno number(3),
constraint pk_empno primary key(empno)
);
create index SCOTT.ind_test01 on SCOTT.test01(deptno);
begin
for i in 1..500000 loop
insert into SCOTT.test01 values(
i,dbms_random.string('p',64),dbms_random.string('u',9),i,sysdate,i,i,mod(i,999));
end loop;
commit;
end;
/
--中间表
drop table SCOTT.test01_int;
create table SCOTT.test01_int(
empno number(7),
ename varchar2(64) not null,
job varchar2(9),
mgr number(7),
hiredate date,
sal number(7),
comm number(7),
deptno number(3),
add_column varchar2(64),
constraint pk_empno_int primary key(empno)
);
create index SCOTT.ind_test01_int on SCOTT.test01_int(deptno);
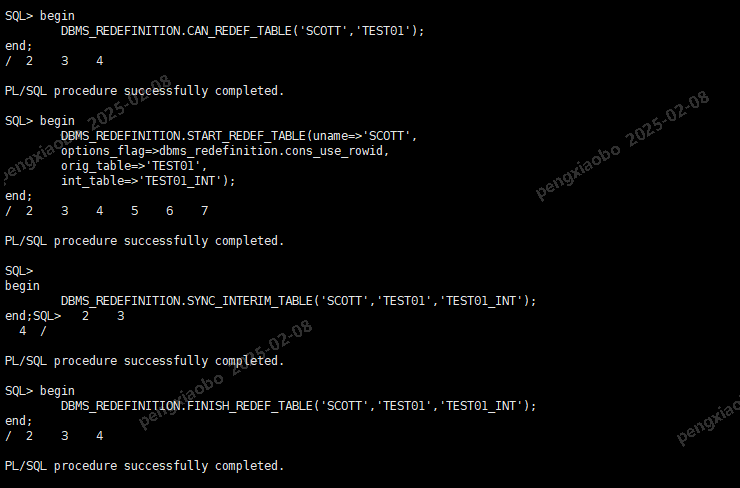
begin
DBMS_REDEFINITION.CAN_REDEF_TABLE('SCOTT','TEST01');
end;
/
begin
DBMS_REDEFINITION.START_REDEF_TABLE(uname=>'SCOTT',
options_flag=>dbms_redefinition.cons_use_rowid,
orig_table=>'TEST01',
int_table=>'TEST01_INT');
end;
/
PL/SQL procedure successfully completed.
begin
DBMS_REDEFINITION.SYNC_INTERIM_TABLE('SCOTT','TEST01','TEST01_INT');
end;
/
PL/SQL procedure successfully completed.
begin
DBMS_REDEFINITION.FINISH_REDEF_TABLE('SCOTT','TEST01','TEST01_INT');
end;
/
Oracle在线重定义经验总结
经验一:2351452.1,DBMS_REDEFINITION.FINISH_REDEF_TABLE会执行flush share pool
◼ DBMS_REDEFINITION.FINISH_REDEF_TABLE 阶段,底层会执行flush share pool 的动作
◼ From 11.1 Online Redefinition May Flush Shared Pool When Execute
DBMS_REDEFINITION.FINISH_REDEF_TABLE (Doc ID 2351452.1)
◼ 按照文档,这是预期行为
◼ 规避方法
➢ alter session set events '10995 trace name context forever, level 2';
经验二:DBMS_REDEFINITION.ABORT_REDEF_TABLE是否对原表造成影响
◼ DBMS_REDEFINITION.ABORT_REDEF_TABLE 中途取消在线重定义
➢ abort 过程会执行一些列的底层操作,其中包括truncate 中间表的操作
➢ alter table "SCOTT"."EMP_INT" drop (m_row$$)
➢ drop table "SCOTT"."MLOG$_EMP" purge
➢ truncate table "SCOTT"."EMP_INT"
◼ 所以结论是abort不会对原表造成影响
➢ abort 方式取消在线重定义后,建议将中间表drop
经验三:新表的统计信息怎样与原表保持一致
◼ 使用copy_statistics方式
➢ 在DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS 阶段
➢ 指定copy_statistics = TRUE
➢ 此时统计信息会由在线重定义复制到中间表
◼ 在线重定义完成后,手动更新统计信息
➢ 设置参数copy_statistics = FALSE
➢ 然后手动收集统计信息
经验四:对大表或超大表进行在线重定义,如何提高速度
◼ 在重定义开始阶段,在session 级别配置并行
➢ alter session force parallel dml parallel N;
➢ alter session force parallel ddl parallel N;
➢ alter session force parallel query parallel N;
◼ 注意事项
➢ 多次测试发现,在sync 和finish 阶段需要session noparallel
➢ 否则sync 和finish 的执行时间会明显变长