SwiGLU 激活函数名称是Swish-Gated Linear Unit 的缩写,它融合了Swish 激活函数和门控线性单元(Gated Linear Unit ,GLU )的特性。具体来说,SwiGLU 通过引入一个可调节的参数,结合Swish 的非线性和GLU 的门控机制,为深度学习模型提供了更强的表达能力和灵活性。
SwiGLU激活函数详解
首先,我们来回顾一下GLU 激活函数。GLU 是一种门控激活函数,其特点是将输入分为两部分,其中一部分经过Sigmoid 函数作为门控信号,另一部分则保持原样或经过其他线性变换。然后,将这两部分逐个元素相乘,产生最终的输出。GLU 的这种门控机制使得网络能够选择性地传递信息,从而提高建模能力。
然而,SwiGLU 在GLU 的基础上进行了改进。它引入了Swish 激活函数,这是一种具有非单调性和自门控特性的激活函数。在SwiGLU 中,原始的输入信号会经过两个不同的线性变换层,其中一个变换的结果会与经过Swish 激活函数的另一个变换结果逐元素相乘。这种设计使得SwiGLU 既保留了GLU 的门控机制,又增加了Swish 激活函数带来的非线性,从而提高了模型的表达能力。
Swish 、GLU 、SwiGLU 激活函数的公式分别如下:
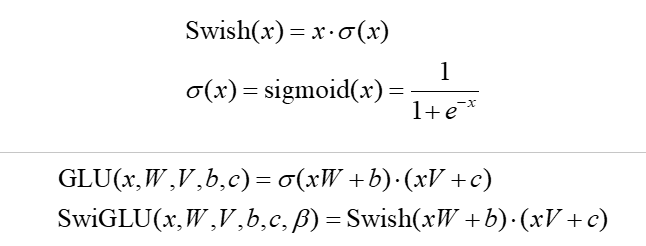
可以看到,SwiGLU 还引入了一个可调节的参数,用于动态地控制门控单元的输出。这个参数使得SwiGLU 能够根据不同的任务需求和数据特点进行调整,进一步增强了模型的灵活性。当这个参数接近于0 时,SwiGLU 的输出将更接近于输入,而当参数接近于1 时,其输出则更接近于标准的GLU 激活函数的输出。
在实践中,SwiGLU 与标准GLU 激活函数相比,已经表现出的性能改进。特别是在某些具有挑战性的任务和数据集上,使用SwiGLU 的模型往往能够取得更好的效果。这主要归功于SwiGLU 的灵活性和强大的表达能力。
总的来说,SwiGLU 激活函数通过结合Swish 和GLU 的特性,为深度学习模型提供了一种新的、高效的激活方式。它的引入不仅提高了模型的性能,还为深度学习研究者提供了新的思路和方法。在未来的研究中,我们期待看到更多关于SwiGLU 的应用和改进。
SwiGLU的PyTorch 实现
在SwiGLU 的具体实现上,我们可以通过使用对应的全连接层来完成,如图11-16 所示。

图11-16 结合MLP 的SwiGLU 实现
简单的SwiGLU 实现代码如下所示:
import torch.nn as nn import torch.nn.functional as F # 定义Swish激活函数 class Swish(nn.Module): def __init__(self, beta=1.0): super(Swish, self).__init__() self.beta = beta def forward(self, x): return x * torch.sigmoid(self.beta * x) # 定义SwiGLU激活函数 class SwiGLU(nn.Module): def __init__(self, input_dim, hidden_dim): super(SwiGLU, self).__init__() self.w1 = nn.Linear(input_dim, hidden_dim, bias=False) self.w2 = nn.Linear(hidden_dim, input_dim, bias=False) self.swish = Swish() def forward(self, x): x1, x2 = x.chunk(2, dim=-1) # 将输入张量一分为二 swish_x1 = self.swish(self.w1(x1)) # 对x1应用Swish激活函数 gate = torch.sigmoid(self.w2(x2)) # 对x2应用Sigmoid激活函数作为门控信号 output = swish_x1 * gate # 逐元素相乘 return output
结合经典缩放的SwiGLU
除了前面讲解的经典SwiGLU 激活函数外,在实践中我们更多采用的是结合了缩放维度变换的SwiGLU 激活函数,其代码如下所示:
# 定义一个名为SwiGLU的PyTorch模块,它继承自torch.nn.Module class Swiglu(torch.nn.Module): """MLP(多层感知机). 该MLP将接收一个具有h隐藏状态的输入,将其投影到4*h的隐藏维度,执行非线性变换, 然后将状态重新投影回h隐藏维度。 """ # 初始化函数 def __init__(self, hidden_size=384, add_bias_linear=False): # 调用父类的初始化函数 super(Swiglu, self).__init__() #是否在线性层中添加偏置项 self.add_bias = add_bias_linear # 隐藏层的大小 self.hidden_size = hidden_size # 定义一个线性层,将h维度投影到4h维度 # 参考论文:https://arxiv.org/pdf/2002.05202.pdf,如果使用SwiGLU,则输出宽度加倍 self.dense_h_to_4h = torch.nn.Linear( hidden_size, # 输入维度 hidden_size * 4, # 输出维度 bias=self.add_bias #是否添加偏置项 ) # 定义一个内部的SwiGLU激活函数 def swiglu(x): # 将输入x沿着最后一个维度分割成两部分 x = torch.chunk(x, 2, dim=-1) # 返回SiLU激活函数处理的第一部分与原始的第二部分的逐元素乘积 return torch.nn.functional.silu(x[0]) * x[1] # 将内部定义的SwiGLU函数保存为类的一个属性,供后续使用 self.activation_func = swiglu # 定义一个线性层,将4h维度投影回h维度 # 注意这里只使用了4h中的2h,因为SwiGLU激活后输出的是2h维度 self.dense_4h_to_h = torch.nn.Linear( hidden_size * 2, # 输入维度 hidden_size, # 输出维度 bias=self.add_bias #是否添加偏置项 ) # 前向传播函数 def forward(self, hidden_states): # 将输入隐藏状态投影到4h维度,得到中间并行输出[s, b, 4hp] intermediate_parallel = self.dense_h_to_4h(hidden_states) # 应用swiglu激活函数 intermediate_parallel = self.activation_func(intermediate_parallel) # 将激活后的输出投影回h维度,得到最终输出[s, b, h] output = self.dense_4h_to_h(intermediate_parallel) # 返回最终输出 return output
在上面代码中,我们使用了自定义的SwiGLU 激活函数。这个激活函数结合了SiLU (也称为Swish )和门控线性单元(GLU )的思想。在MLP 中,输入首先被投影到一个更高的维度(4 倍于原始隐藏层大小),然后应用SwiGLU 激活函数,最后再被投影回原始隐藏层大小。
本文节选自《DeepSeek原生应用与智能体开发实践》一书,获出版社和作者授权发布,仅供读者个人学习使用。
