Undo表空间耗尽问题
1、 问题描述
oracle版本19.16,发现undo表空间使用率过高,查询发现事物占用的表空间与undo表空间 active 状态的空间大小不一致 。
事物 使用 undo 的 表空间 sql 查询:
SELECT s.username,
s.sid,
pr.PID,
s.OSUSER,
s.MACHINE,
s.PROGRAM,
rs.segment_id,
r.usn,
rs.segment_name,
r.rssize/1024/1024,
sq.sql_text
FROM gv$transaction t, gv$session s, gv$rollstat r, dba_rollback_segs rs ,gv$sqltext sq,gv$process pr
WHERE s.saddr = t.ses_addr
AND t.xidusn = r.usn
AND rs.segment_id = t.xidusn
AND s.sql_address=sq.address
AND s.sql_hash_value = sq.hash_value
AND s.PADDR=pr.ADDR
ORDER BY t.used_ublk DESC ,sq.PIECE;
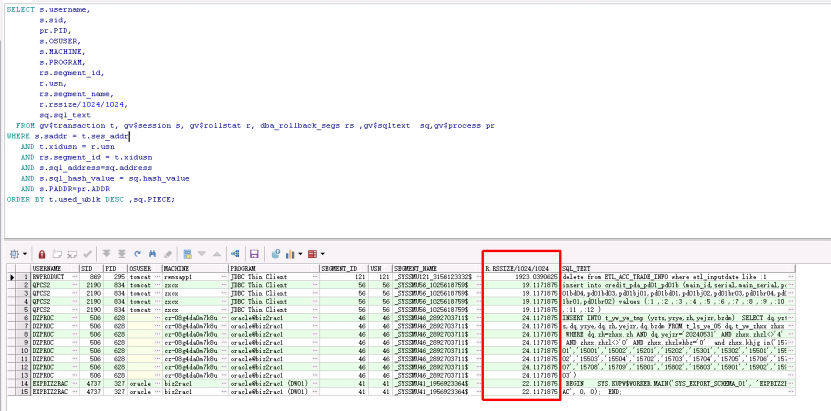
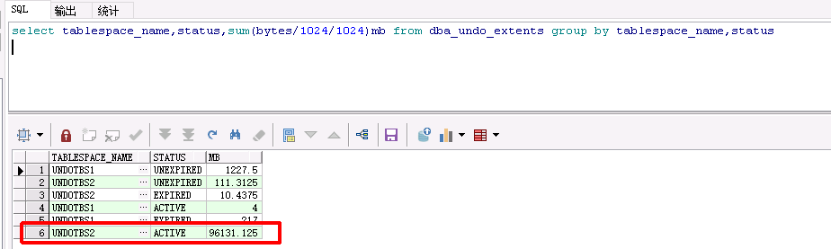
undo表空间 的 active 的过大 , 与事物占用空间相差太大 :
SELECT tablespace_name,status,SUM (bytes)/1024/1024 "Bytes(M)" FROM dba_undo_extents GROUP BY tablespace_name,status;
2、 问题分析
排查过程中间 , 预估 dba/v$ 视图与基表的收集问题,尝试根据基表来查结果,未果。
后面 mos上查到一片文档:
High UNDO Tablespace Usage Caused By Recursive SQL f3yfg50ga0r8n From KTSJ Slave Process (Doc ID 3013880.1)
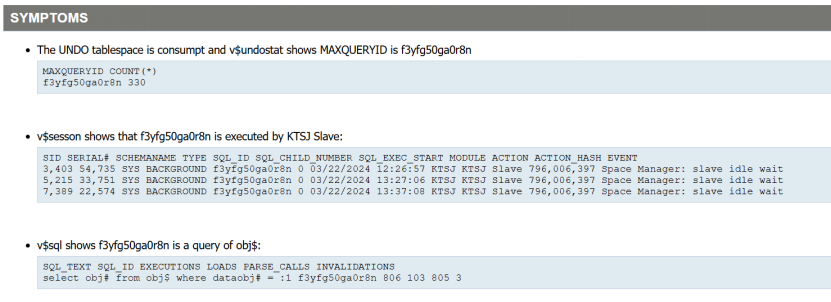
查询消耗的 sql_id确实是:“ f3yfg50ga0r8n ”
select MAXQUERYID,count(*) from gv$undostat group by MAXQUERYID;
通过 gv$session 查询确实有 KTSJ Slave执行,事件“Space Manager: slave idle wait”,也就是回收undo空间一直处于等待状态
select SID,SERIAL#,SCHEMANAME,TYPE,SQL_ID,SQL_CHILD_NUMBER,SQL_EXEC_START,MODULE,ACTION,ACTION_HASH,EVENT from gv$session where SQL_ID='f3yfg50ga0r8n';
查询 sql_id对应的sql:
select SQL_TEXT,SQL_ID,EXECUTIONS,LOADS,PARSE_CALLS,INVALIDATIONS from v$sql where SQL_ID='f3yfg50ga0r8n';
Sql为:select obj# from obj$ where dataobj# = :1
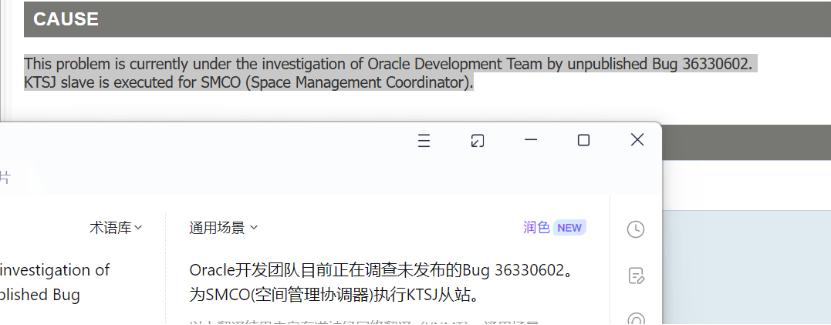
3、问题原因
这是一个 bug,Bug 3633060,“ KTSJ slave ”执行空间管理协调( SMCO ) 出现了资源等待 , 但是目前 oracle开发团队未发布补丁 。
4、 问题解决
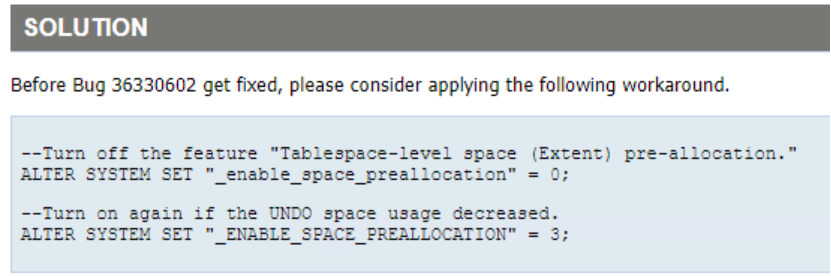
在 Bug 36330602得到修复之前,请考虑应用以下解决方案。
高了就关 smco:
ALTER SYSTEM SET "_enable_space_preallocation" = 0;
低了就开 smco,3也是默认参数:
ALTER SYSTEM SET "_ENABLE_SPACE_PREALLOCATION" = 3;
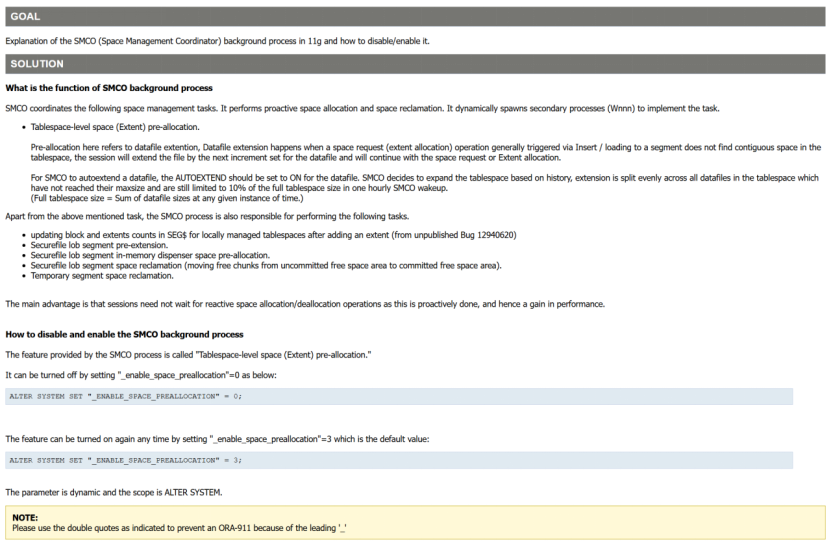
5、 技术原理 ( smco )
smco的含义 :
SMCO (Space Management Coordinator) For Autoextend On Datafiles And How To Disable/Enable (Doc ID 743773.1)

翻译:
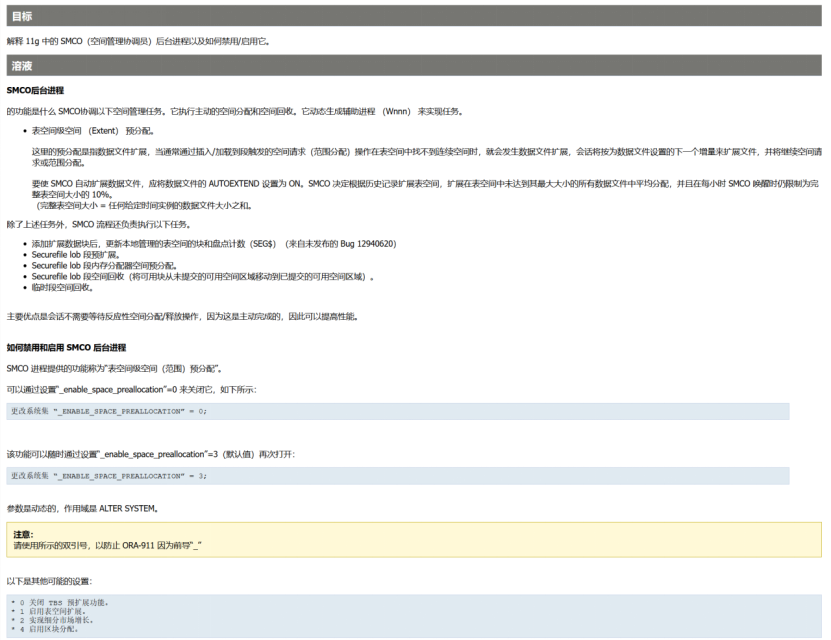
6、 总结建议
1、该问题 最终结论( Bug 36330602,未发布的bug)(Doc ID 3013880.1) 。
2、我们要了解undo表空间,Undo段中区3中状态: DBA_UNDO_EXTENTS的STATUS列 的 三种状态:
ACTIVE : 未提交的 Undo信息 , 事物还在活动, ACTIVE状态的Undo区不会被覆盖。
EXPIRED : 过期的 Undo信息 , 事务已经提交且超过了 UNDO_RETENTION指定时间,该状态可以被覆盖使用。
UNEXPIRED : 提交的未过期 的 Undo信息:表示事务已经提交但是还没有超过UNDO_RETENTION指定时间,该状态可以被覆盖使用。
3、Undo相关报错
ORA-30036
如果 undo 表空间设置为 guarantee, 那么当 undo表空间的 expire d段不够时 , 不会覆盖 unexpire d状态的undo段 , 就会出现事务失败 ,ORA-30036 错误。
ORA-01555
如果 undo 表空间设置为 noguarantee, 那么当 undo表空间的 expire d不够时 , 会强行覆盖 unexpired 的段 , 来保证事务的成功执行 , 这样可能会导致出现 ORA-01555 错误 , 因为保留的旧数据被覆盖掉了。
查看是否为 guarantee
select tablespace_name,contents,retention from dba_tablespaces;
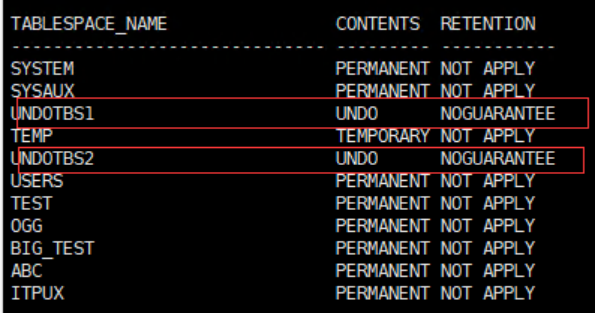
Undo_retention 默认 900,就是15分钟 。 只要表空间足够, Oracle内部会尽量保证将Undo数据保留超过undo_retention设置的时间。
4、 事务回滚
事物未回滚情况:数据库 Abort,再启动;Kill;未提交,rollback;
回滚过程:
SMON 进程的 CPU 使用率高
在大型事务恢复期间数据库可能会挂起。
如果数据库被关闭中止,则数据库可能在随后的启动过程中挂起。
并行事务恢复 :
FAST_START_PARALLEL_ROLLBACK
LOW- 将最大并行度限制为 2 * CPU_COUNT 默认值
HIGH- 将最大并行度限制为 4 * CPU_COUNT
串行事务恢复
此模式顺序恢复事务。
将 FAST_START_PARALLEL_ROLLBACK 参数设置为 false 将启用串行事务恢复。
alter system set fast_start_parallel_rollback=false;
死事务,一般是事务正在跑的时候,被 kill掉了,或者数据库shutdown abort了,那么当数据库再次启动的时候,这些事务就需要做回滚。
在一般情况下,并发的回滚总是比串行的快,一般在系统资源可以接受的范围内采用并发回滚,但是 也有 例外 情况 ,就是并发的子进程之间存在资源冲突的情况 , 所以我们有时候发现回滚时业务也卡住了 。
在并发子进程之间需要的资源冲突时,往往此时 smon的等待事件是长期处于Wait for stopper event to be increased,而子进程的等待事件是较多出现Wait for a undo record。此时,就是子进程冲突了。并发的回滚速度反而不如串行的回滚速度。冲突时,我们需要把fast_start_parallel_rollback 改成 false。
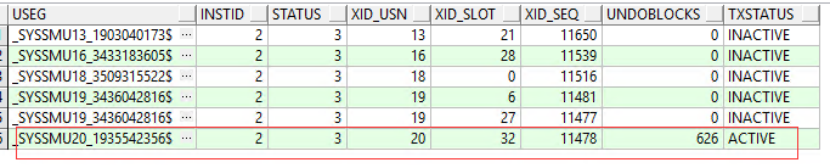
死事务 回滚段查询
select b.name useg,
b.inst# instid,
b.status$ status,
a.ktuxeusn xid_usn,
a.ktuxeslt xid_slot,
a.ktuxesqn xid_seq,
a.ktuxesiz undoblocks,
a.ktuxesta txstatus
from x$ktuxe a, undo$ b
where a.ktuxecfl like '%DEAD%'
and a.ktuxeusn = b.us#;
确认事务完成恢复的时间
select usn,
state,
undoblockstotal "Total",
undoblocksdone "Done",
undoblockstotal - undoblocksdone "ToDo",
decode(cputime,
0,
'unknown',
sysdate + (((undoblockstotal - undoblocksdone) /
(undoblocksdone / cputime)) / 86400)) "Estimated time to complete"
from v$fast_start_transactions;
USN STATE Total Done ToDo Estimated time to c
---------- ---------------- ---------- ---------- ---------- -------------------
11005 RECOVERING 17772 6624 11148 202 4 -0 7 -03 14:46:05
查询并行恢复的数量:
select * from v$fast_start_servers;
STATE UNDOBLOCKSDONE PID XID
----------- -------------- ---------- ----------------
RECOVERING 6624 27 FD2A0B008A000000
RECOVERING 0 30 FD2A0B008A000000
RECOVERING 0 32 FD2A0B008A000000
RECOVERING 0 33 FD2A0B008A000000
查询事务恢复的对象:
|
select decode(px.qcinst_id, NULL, username, ' - ' || lower(substr(s.program, length(s.program) - 4, 4))) "Username", decode(px.qcinst_id, NULL, 'QC', '(Slave)') "QC/Slave", to_char(px.server_set) "Slave Set", to_char(s.sid) "SID", s.serial#, decode(px.qcinst_id, NULL, to_char(s.sid), px.qcsid) "QC SID", px.req_degree "Requested DOP", px.degree "Actual DOP" from gv$px_session px, gv$session s where px.sid = s.sid(+) and px.serial# = s.serial# order by 5, 1 desc;
select distinct current_obj# from v$active_session_history where SESSION_ID = 145 and SESSION_SERIAL# = 15; select Object_name, object_type from dba_objects where object_id = 77211; |
|
select * from v$fast_start_transactions; USN SLT SEQ STATE UNDOBLOCKSDONE UNDOBLOCKSTOTAL PID CPUTIME PARENTUSN PARENTSLT PARENTSEQ XID PXID RCVSERVERS ---------- ---------- ---------- ---------------- -------------- --------------- ---------- ---------- ---------- ---------- ---------- ---------------- ---------------- ---------- 11005 11 138 RECOVERING 5555 17772 27 21 0 0 0 FD2A0B008A000000 0000000000000000 3
select * from v$rollname where usn=11005; USN NAME ---------- ------------------------------ 11005 _SYSSMU11005_3138824131$
alter system dump undo block "_SYSSMU11005_3138824131$" XID 11005 11 138;
select * from v$diag_info where name='Default Trace File';
object number ( objn )或者 object id ( objd )
more /ora11203/app/diag/rdbms/crmdb/crmdb/trace/crmdb_ora_8070.trc |grep objn |more * Rec #0x2e slt: 0x0b objn: 76496(0x00012ad0) objd: 76496 tblspc: 4(0x00000004) * Rec #0x2d slt: 0x0b objn: 76495(0x00012acf) objd: 76495 tblspc: 4(0x00000004) * Rec #0x2c slt: 0x0b objn: 83147(0x000144cb) objd: 83147 tblspc: 4(0x00000004) * Rec #0x2b slt: 0x0b objn: 76497(0x00012ad1) objd: 76497 tblspc: 4(0x00000004)
select owner,object_name,object_type from dba_objects where object_id in ('76496','76495','83147','76497'); |