在实际业务中,我们经常需要将多张表关联后进行多表分析,但当A表多对多B表,又或者B表又多对多C表时,笛卡尔积带来的数据膨胀问题让人无法忽视。虽然可以用某些复杂迂回的办法方法解决,但投入产出比着实太低了,有么有一种更简洁优雅的方式呢?
01 背景
使用过BI的用户一定都知道,我们在搭建一个数据看板之前,先要把源数据接入BI产品内,即和数据源「建立连接」,然后进行「数据处理」,对原始数据进行清洗(若有需要也可以增加「数据落库」这一步骤,增强性能),最后将清洗的数据表关联成面向分析的主题「数据模型」。

创建面向分析主题的「数据模型」是数据分析的基础,但是基于原来数据模型的功能,无法有效解决“关联不同粒度事实表”统一分析的场景,比如以下两个场景:
(1)老王手上有两张表。A表是每个商品的销售记录(商品id、订单id、订单金额),因为同一id的商品会被出售多次,所以商品销售记录表里有多个「商品id」;B表是每个商品的销售目标(商品id,销售目标),同一id的商品只有唯一的「销售目标」,所以商品销售目标表里只有唯一的「商品id」
A表B表根据商品id直接关联(多对一关联),创建的数据模型中「销售目标」数据会膨胀(扩大N倍)
(2)老王手上又来了两张表。A表是每个客户的贷款记录(客户id、贷款单id、贷款金额),B表是每个客户的存款记录(客户id、存款单id、存款金额),统一id的客户贷款记录和存款记录均有多条,所以两表中的「客户id」也有多条
A表B表根据客户id直接关联(多对多关联),创建的数据模型中「贷款金额」、「存款金额」等指标同样会膨胀
为了解决上述多事实表关联为代表的度量数据膨胀的问题,有数BI重磅推出「关系模型」的功能。
02 解决方案
何谓关系模型?
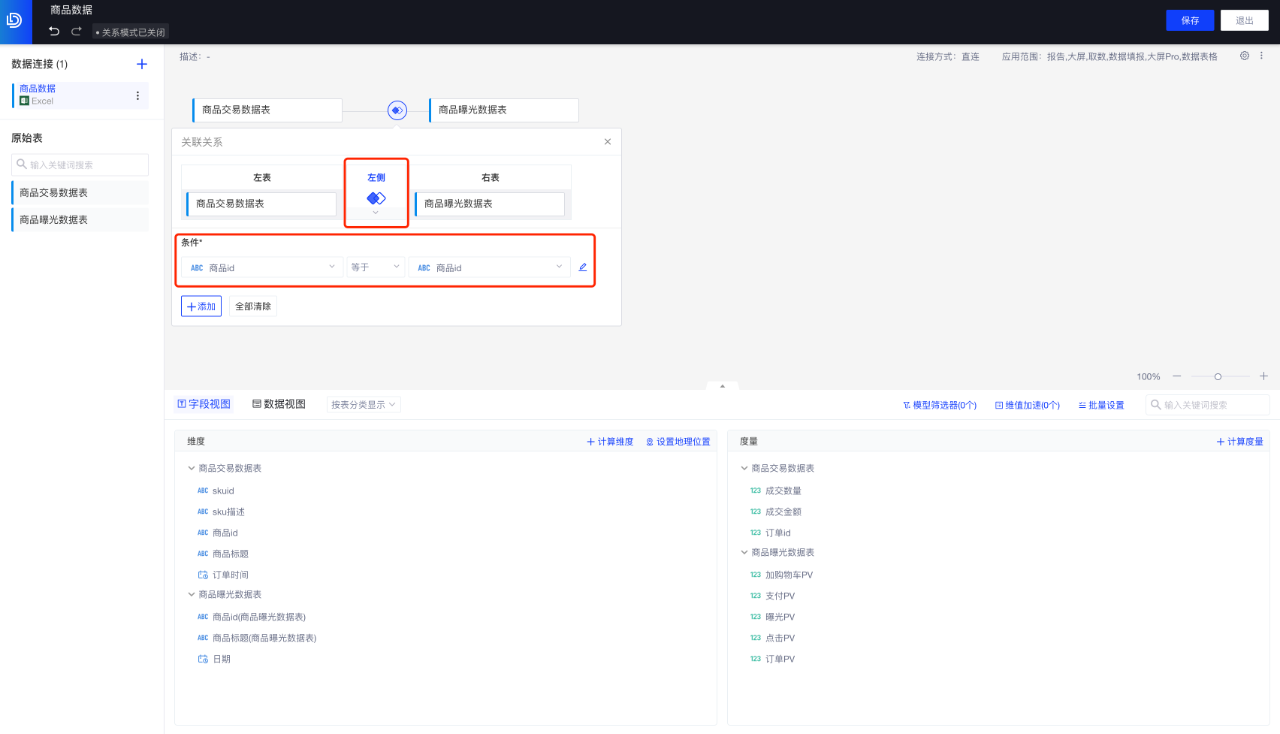
如下图所示,关系模型是在逻辑表(即原有数据模型)基础之上再增加关系层,关系层只需要设置逻辑表之间的关联字段,不必精确定义关联(join)方式;这就使得关系模型足够灵活,能够把用户所选的字段针对性地做聚合,并保证了数据的准确性和完整性,有效避免多事实表关联产生的数据膨胀问题。
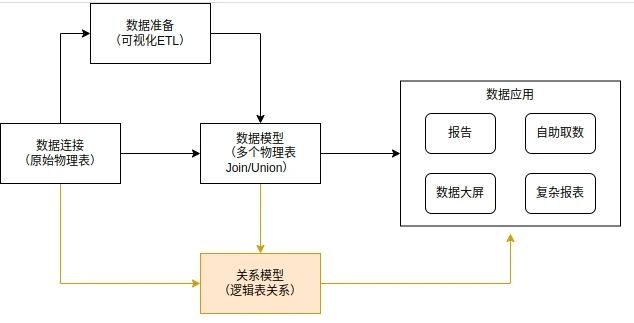
因此,关系模型分为关系(即:逻辑层)和联接(即:物理层)两层,其中物理层即为原先的数据模型,即通过多个原始表(也称物理表)进行确定的关联方式来形成物理层(即原先的宽表);逻辑层是将多个物理层(也称逻辑表)建立关系,关系需要指定关系键,但不需要指定关联方式,具体的关联形式将由视图上的维度和度量共同决定。
具体的使用步骤包括:
(1)在「关系」层配置逻辑表之间的关联
类似于数据模型的创建,拖入两张表时,若它们在原数据库中存在外键关联,则会自动进行关联;若无外键,系统会自动将两张表中相同名称的字段设置为外键进行关联。您可以在此自行添加/修改/删除关联字段。
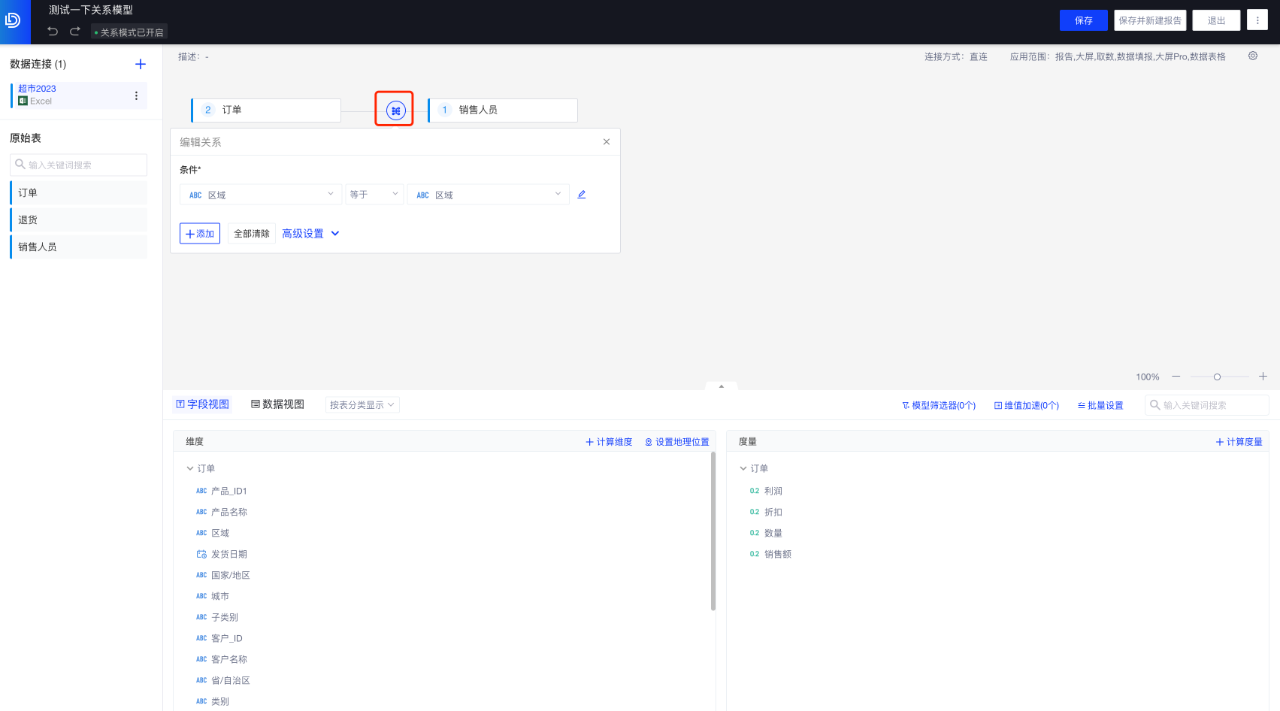
展开「高级设置」,可以根据基数和引用完整性来保障查询性能:
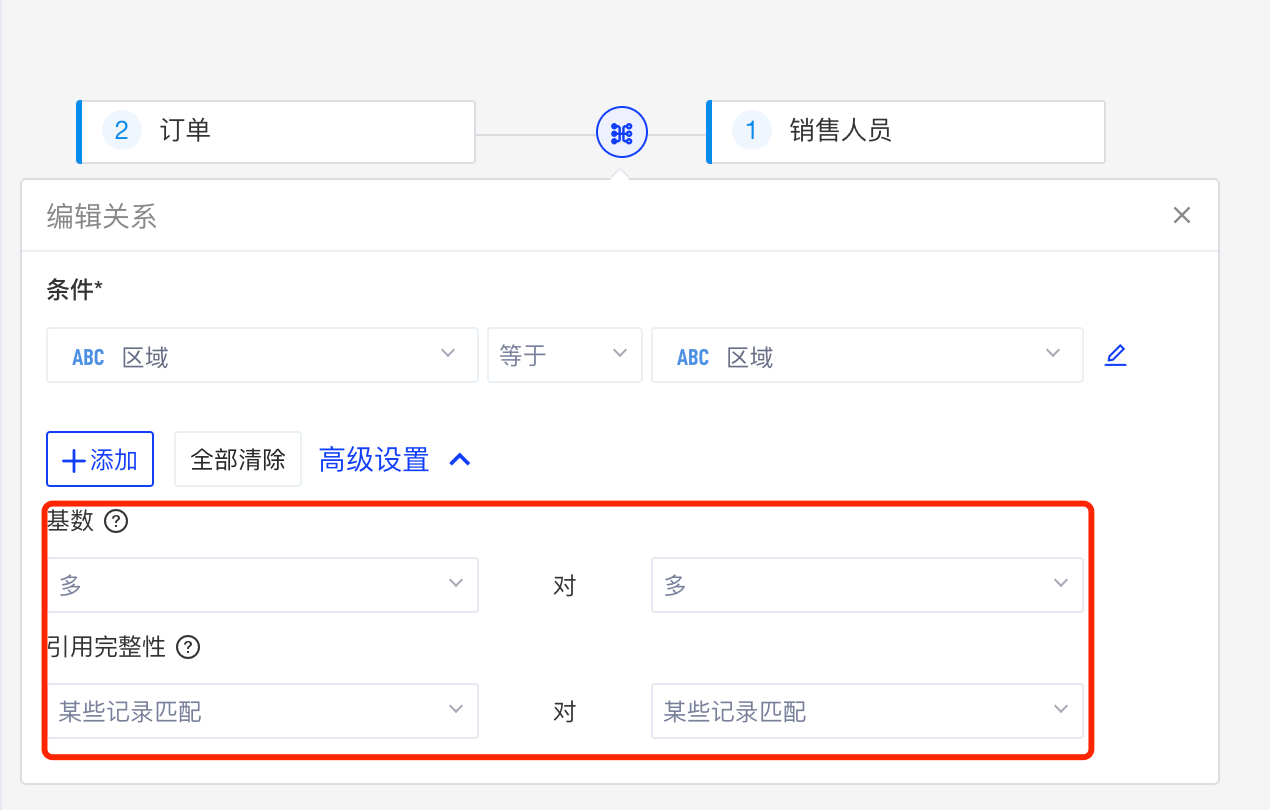
配置逻辑表的基数:确定当前表跟其他表关联时,关联和聚合的先后顺序
如果关联字段值不唯一,或者不确定是否唯一的情况下,请选择“多”,则该逻辑表跟其他表关联时会“先聚合再关联”;
如果字段值是唯一的,请选择“一”,则该逻辑表跟其他表关联时“先关联再聚合”;
配置引用完整性:确定表联接的类型
如果字段中的某些值在其他表中没有相同的成员值,或者您不确定是否有完全一致的成员值,请选择引用完整性为“某些记录匹配”,则表join时为“外部联接”;
如果字段中的值确定在其他表中有相同的成员值,请选择引用完整性为“所有记录匹配”,则表join时为“内部联接”;
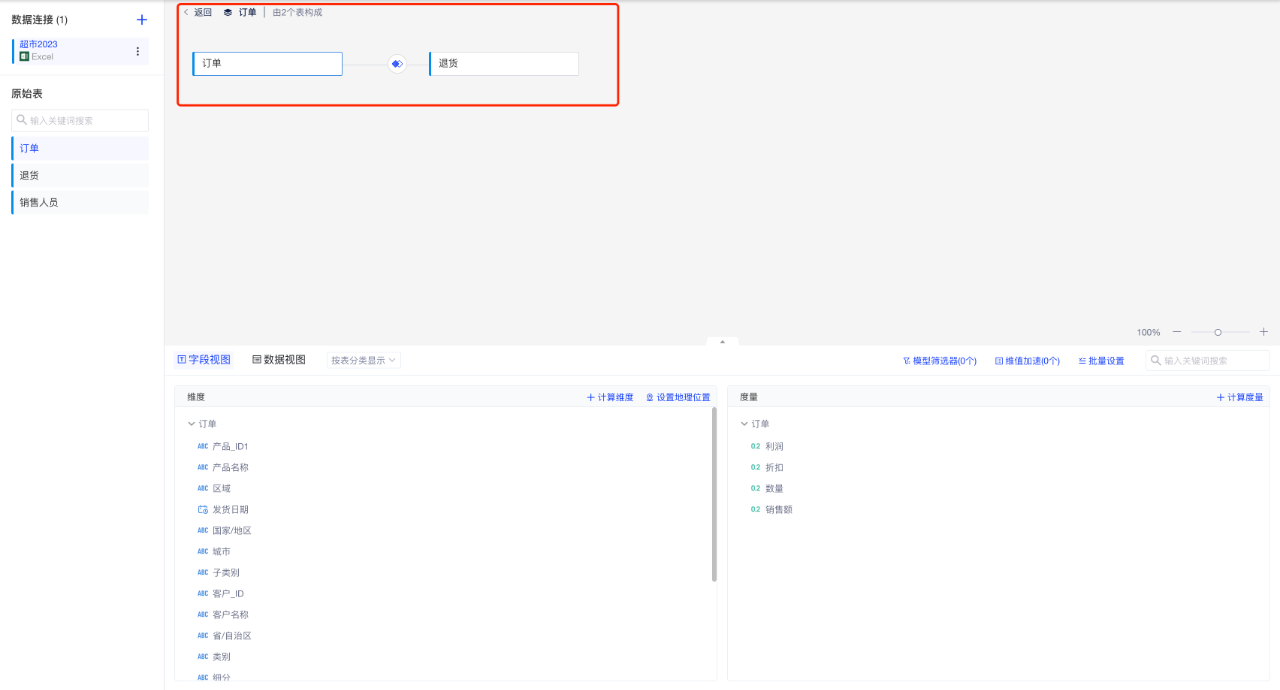
(2)在「联接」层配置物理表之间的关联
在某个逻辑表右下角的下拉菜单中点击「编辑表」或者直接双击逻辑表,可进入第二层,进入该逻辑表的内部联接配置,您可以配置物理表之间的联接类型和关联字段,操作与普通数据模型相同。
03 应用案例
接下来以直播电商计算GPM指标为例,给大家介绍下关系模型的实际应用。直播电商场景下,比起GMV,大家更关心GPM(千次曝光成交量)指标,该指标的计算公式:
GPM=(GMV/曝光PV)*1000
GMV,即商品的成交金额,该数据存在商品的交易表中(如表1),而曝光PV则在商品的曝光数据表中(如表2),因此需要将商品交易数据跟商品曝光数据关联在同一个数据模型里,才能计算出商品的GPM。
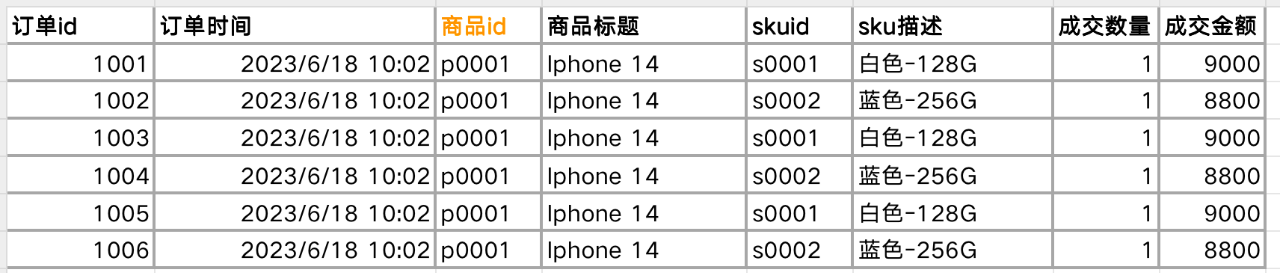
(表1.商品交易数据表样例)

(表2. 商品曝光数据表样例)
当需要把商品交易数据跟商品曝光数据用商品id字段直接关联(Join),就会产生数据膨胀:
因为表1是订单粒度的,同一个商品id存在多笔订单,一个商品id会对应多条记录。而表2是商品粒度,一个商品id只会有一条记录。两个表用商品id进行关联(Join)后,表2中的曝光PV指标就会产生膨胀——“p0001”这个商品id在表1中出现过6次,表2中的曝光pv数据汇总后就会放大6倍(如下图),这样计算得到的GPM则会比真实值小很多:
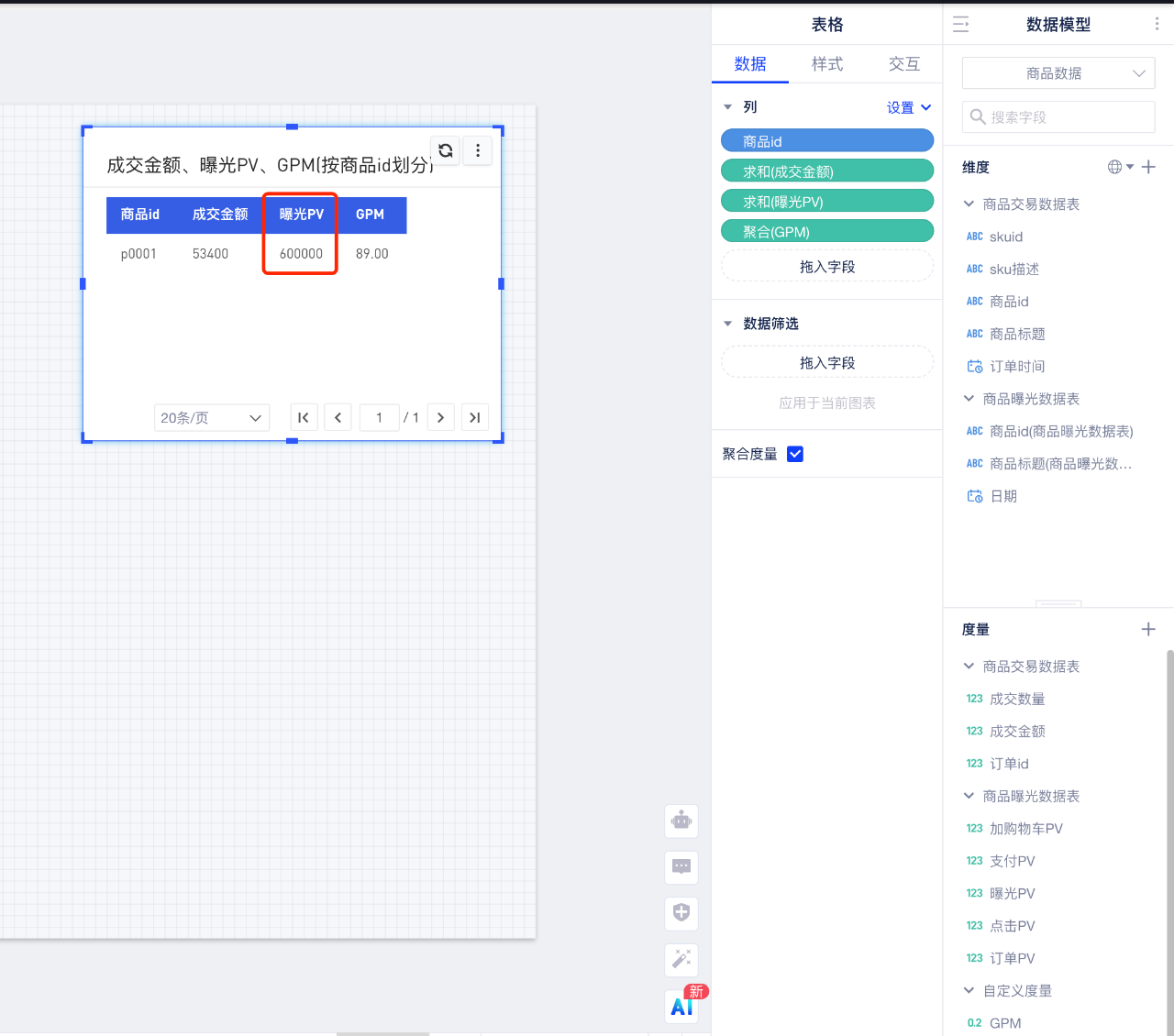
虽然可以先将表1按照商品id粒度聚合,再跟表2进行关联,如此不会发生数据膨胀的问题。但是表1中的sku、订单等粒度的信息也在聚合的过程中丢失了。无法在分析的过程中下钻到sku或者订单粒度查看交易数据。
而利用关系模型,则可以很好地解决上述问题。不同粒度事实表一同分析时,在保留事实表详细信息的同时,也不会产生数据膨胀。
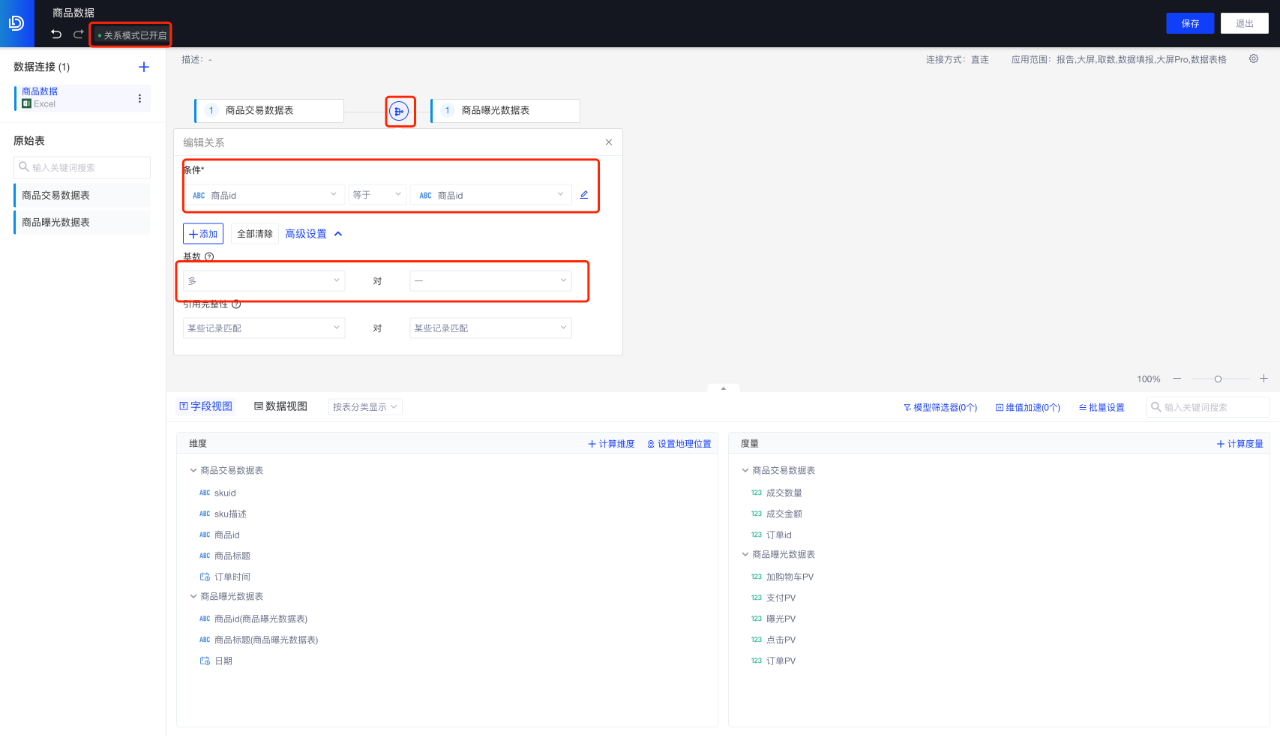
步骤1:新建一个数据模型,打开“关系模型”的开关
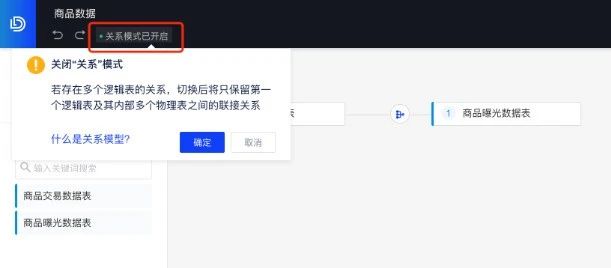
步骤2:拖入要分析的“商品交易数据表”、“商品曝光数据表”
使用商品ID字段作为关联字段,建立两个表的关系。性能选项中可以选择“多对一”
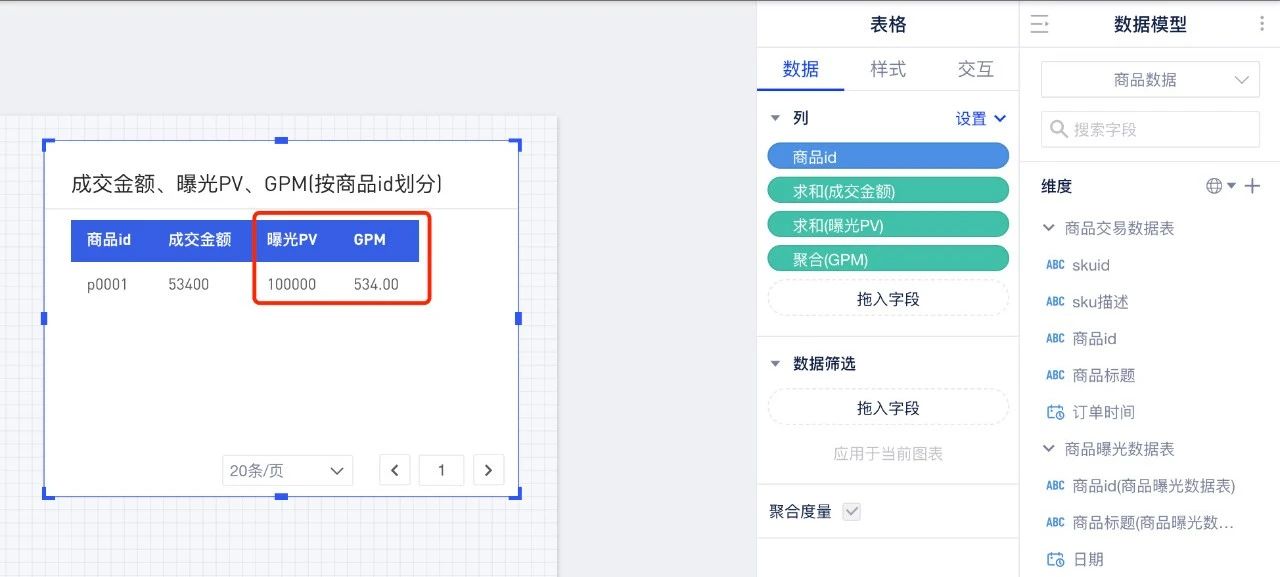
步骤3:在报告模块引用该数据模型,并进行数据分析
拖入商品id、成交金额、曝光PV和GPM,可以发现曝光PV指标展示的值是正确的,未发生数据膨胀,由此得到了正确的GPM~
04 邀您体验
由于篇幅有限,本文只展示了一个非常简单的例子,但其中的操作也同样适用于实际业务中更复杂的场景,相信关系模型会为您带来全新的体验。
目前关系模型已于昨晚正式上架有数BI8.9版本,欢迎前往官网免费体验,私有部署的客户可联系技术支持进行升级。
在设计关系模型的过程中,我们也对跨视图粒度计算(LOD)的性能做了优化,欢迎一并体验