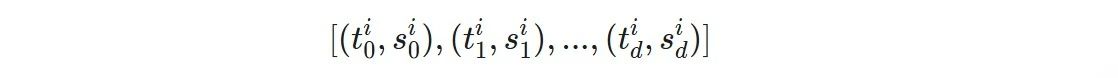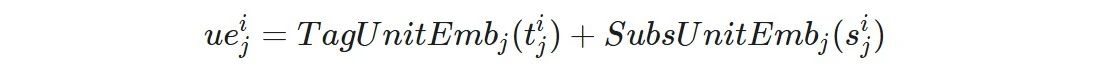百度搜索拥有着几十亿级的流量,作弊团伙通过各种各样的手段妄想从巨大的流量中不劳而获。搜索反作弊团队维护百度搜索生态安全和质量,经过不断探索并利用前沿技术过滤低质作弊网页,保护真正付出劳动的站长的利益。本文介绍了基于MarkupLM的网页建模方式,引入XPath embedding自动化提取作弊页面结构特征,并与文本结合来进行采集站点识别。
01 背景
1.1 业务背景
采集是指网站维护人员(下文中统称站长)通过程序或者人工手段,将他人网站的内容复制到自己的网站中的行为。优质的采集网站会在原有内容的基础上进行加工,为用户输出更有价值的内容,比如删掉不必要的内容、高成本的编辑和内容的重新排版等。而少量站长为了利用搜索引擎获取更多不法流量,无视用户的浏览体验,从别处大量采集内容并通过使用一些作弊手段来提升自身排名。
恶劣采集网站的展现会使得投入大量精力建设优质内容的站长流失本该属于他们的流量,造成站长获得的收益与付出的精力不匹配。长此以往,互联网上的原创内容将会越来越少,因此识别并打击这部分作弊站点,是维护站长创作公平性和搜索内容生态环境质量的关键。

△采集示例(1)
△采集示例(2)
1.2 传统解决方案
恶劣采集站采集的内容排版质量差,将一些问答站(如知乎、百度知道等)的多个主题相似的问题和回答拼凑,如图1和图2所示。页面除了文本语义、句子通顺度特征外,也存在文本重复堆叠的特征。文本模型会难以捕捉到该类表征,因此需要结合网页结构和网页内容综合分析,常规的策略和技术手段可以分为:
内容重复检测:
文本指纹:通过构建网页指纹(如SimHash、MD5等)进行不同页面的相似文本识别。
文本相似度:使用自然语言处理技术计算页面内容的语义相似度。
网页结构分析:
DOM树分析:通过对比不同页面的DOM树结构,识别出结构高度相似的网页。
网页标签分析:通过计算网页中特定HTML标签(如
、
等)的标签密度和套嵌关系进行内容堆叠识别
机器学习模型:
特征工程:结合HTML结构特征、内容相似度、用户行为等信号构建特征向量,用于训练机器学习模型。
模型训练与验证:使用作弊站点和正常站点的样本数据进行模型训练,并通过交叉验证评估模型效果。
持续学习与更新:不断优化特征集和模型参数,提高识别效果。
辅助手段:除了技术识别手段之外,同步建立用户举报机制,收集用户关于内容质量的反馈,作为识别恶劣采集站的辅助手段
通过上述方法,可以有效地识别恶劣采集站,保护原创内容创作者的权益,提升搜索结果质量和用户浏览体验。但是随着对抗的深入,恶劣采集也呈现出新的形式,如
多源拼凑:不再局限于简单地从少数网站进行采集,而是从网站、论坛、社交媒体等多个渠道进行内容采集和智能化拼凑,导致文章风格、语言表达和观点与正常页面差异变小
内容改写:运用自然语言处理技术或文本替换工具,对采集内容进行同义词替换、语序调整等改写操作,使文本与原文有所不同,但核心内容并未改变,以此来逃避文本相似度检测
对于上述问题,需要同时结合页面排版特征和语义信息进行综合识别,将采集识别问题抽象成结合文本与布局信息实现视觉富文本文档理解(Visually-Rich Document Understanding,简称VRDU)的任务,同时考虑问题复杂度,采用预训练的MarkupLM模型识别恶劣采集页面。
02 MarkupLM模型
视觉富文本文档可以大致被分为两大类。
第一类是固定布局的文档,比如扫描件和电子pdf等文件,这类文档是预先渲染并且布局固定。通过基于布局(layout-based)预训练模型进行文档理解和下游任务,如Xu等人(2020)[1]提出的LayoutLM为代表的基于文本、布局和图像的多模态预训练模型。
第二类是标记语言文档(markup-language-based documents),如HTML、XML等,其布局和样式信息会动态地根据软件、硬件或操作系统来进行渲染可视化,这类无明确格式的布局信息不能直接用于预训练,使得基于布局的预训练模型难以应用。
不同于固定布局的文档,微软团队LI等人(2021)[2]提出一种针对基于标记(mark-up based)的VRDU任务的预训练模型-MarkupLM,利用基于树状结构的优势对文档中不同单元的关系进行建模,直接对网页类标记语言文档的源代码进行处理和学习。
在实际网页场景下,spammer通过一些手段隐藏和动态展现作弊内容。理论上,相较于渲染后的网页视觉信息,对网页html深度解析和建模也更能捕捉到一些潜在异常。
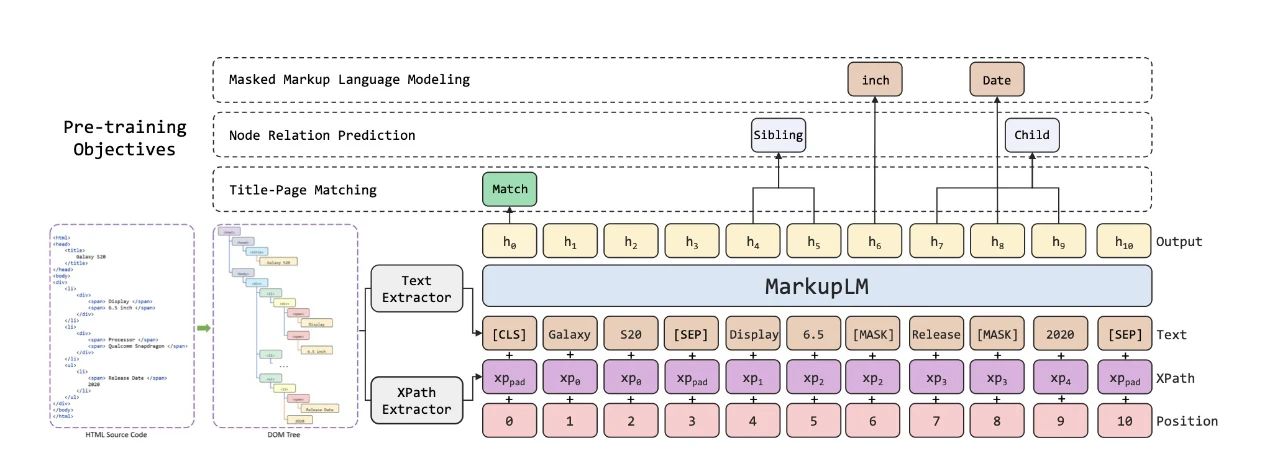
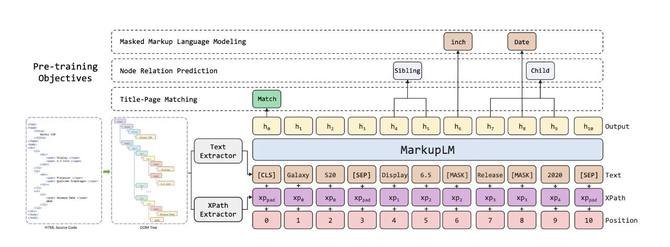
2.1 模型架构
模型整体采用BERT[3]架构作为编码器主干,为了在模型中加入基于标记语言的布局信息,在原有embedding layer上新增了一个XPath embedding模块。如图3所示,每个输入文本都对应一个XPath的嵌入表征向量。
△图3.MarkupLM模型架构及预训练任务示意图
2.2 结构建模
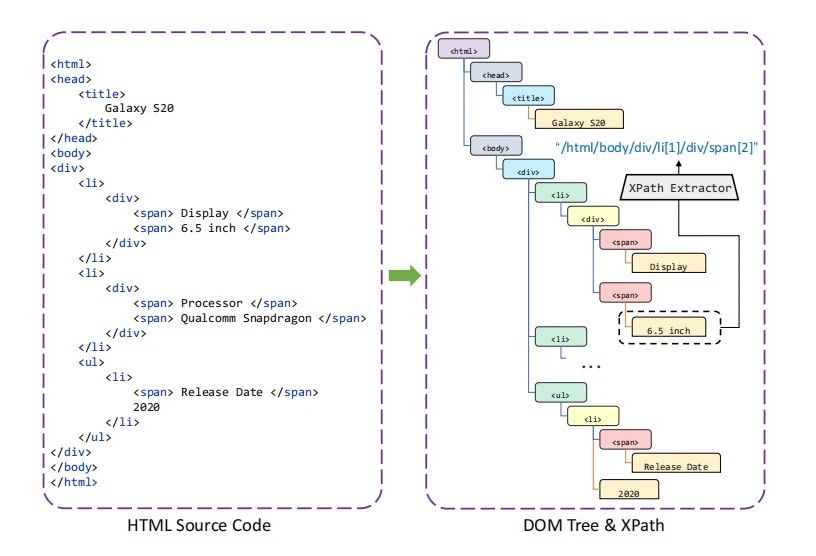
MarkupLM利用标记语言中的DOM树和XPath来获取文档中的标记路径和对应自然文本。XPath是一种能便于从基于Dom树的标记语言文档里定位节点的查询语言,可以理解为Dom树中以深度优先遍历方式抽取出的从根节点到一段文本所在节点经过的路径。
具体如图4例子所示,“6.5 inch” 文本对应XPath表达式为 “/html/body/div/li[1]/div/span[2]”。“span” 代表节点的标记名,“[2]” 下标代表当多个相同名为 “span” 的节点在同一个父节点下时节点的序号。由此可见,XPath embedding可以被视为 LayoutLM 中 2D-position embedding 的替代,能够表达文本在标记文档中的位置信息。
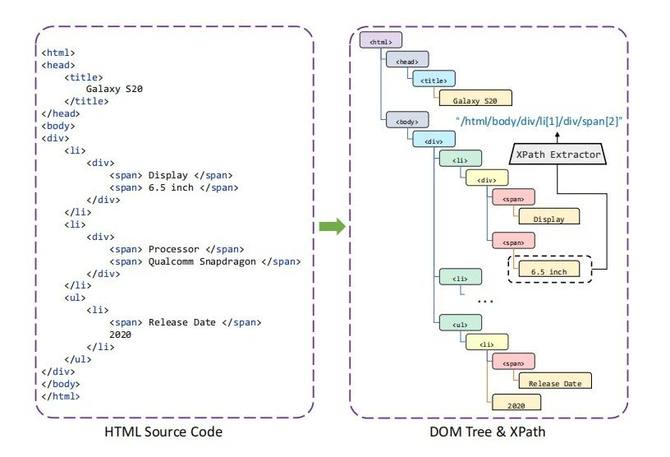
△图4.HTML源码转成Dom树和XPath的例子
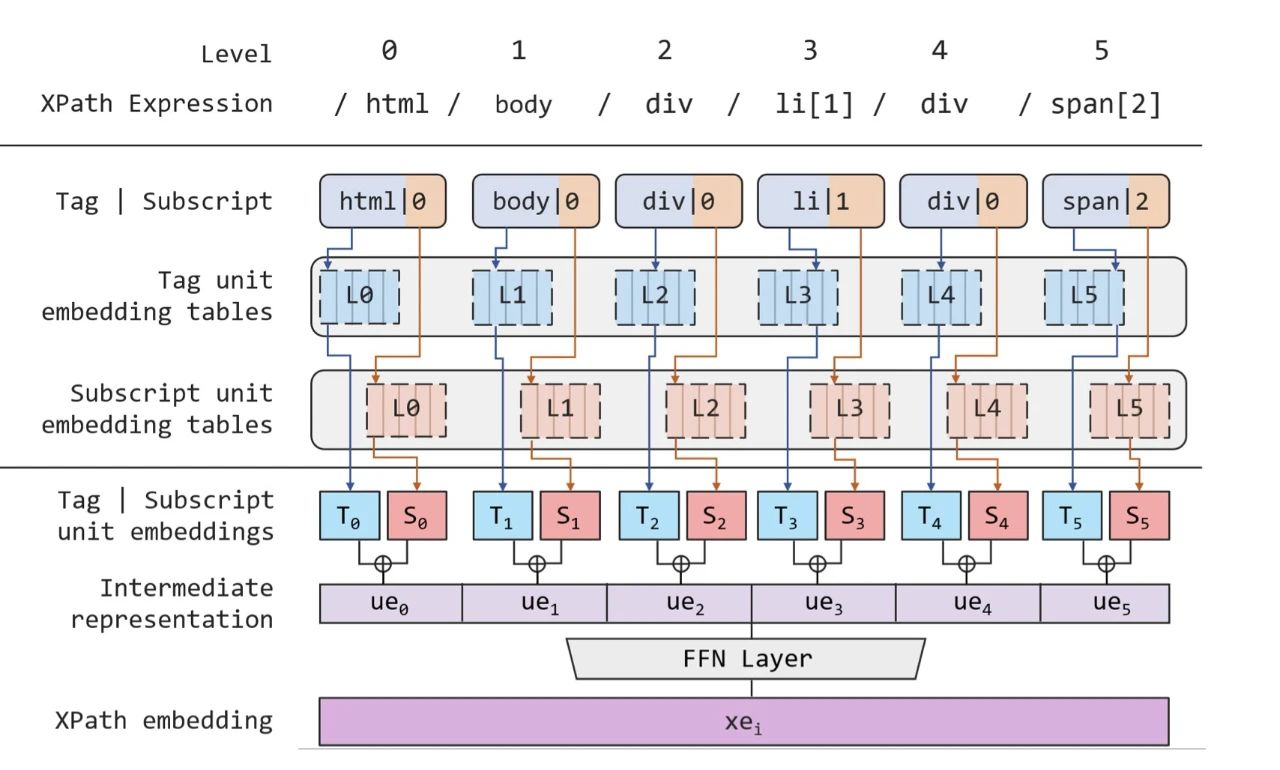
以图4的XPath表达为例,图5展示了如何得到其XPath嵌入表征网络结构。
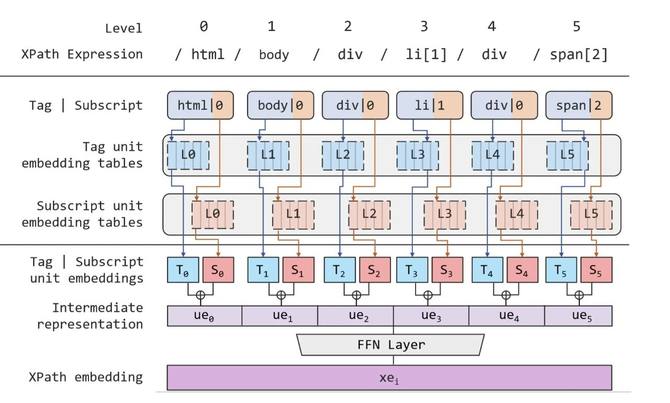
△图5.XPath embedding详细结构
对于第i个输入token$x_i$,首先将它对应的XPath表达式按层级切分,得到一个包含不同深度上的Xpath单元列表
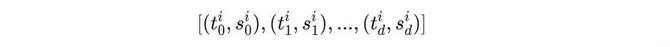
d为XPath的深度,每个单元$(t_{j}^{i}, s_{j}^{i})$的两个元素分别为深度j的XPath单元的标签名及下标,对于无下标的单元则统一设置为0。随后在每层深度里,XPath Embedding模块均含有一个独立的标签嵌入表与下标嵌入表。因此每个 XPath 单元均会产生两个向量,分别为标签名称与下标的嵌入表征,随后两个向量相加即可得到各 XPath 单元的表征,即单元$(t_{j}^{i}, s_{j}^{i})$的表征为
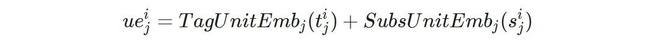
为了保留单元之间的层次信息,该模块将所有单元的表示按原有位置进行拼接操作,得到整个 XPath 表达式的表示向量$[ue_{0}^{i}; ue_{1}^{i};... ; ue_{d}^{i}]$。
最后,为了匹配上原有输入的embedding向量维度同时保证模型稳定性,采用了一个前馈神经网络(FFN)来进行维度转换,并引入非线性激活函数增强表达能力,最终得到
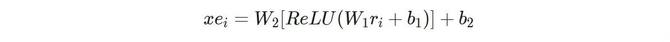
03 恶劣采集上的应用
在作弊网页识别的工作中,网页结构的多样化让规则性的策略难以识别,特定标签内容的提取需要人工手动参与。恶劣采集站点的识别更是如此,文不对题、段落拼凑等场景的识别都需要网页结构特征(标签、标签之间的关系等)和文本的共同参与。
对于文本采集的检测模型而言,需要具有理解节点间关系和对网页内容进行总结概括的能力来理解网页的上下文信息。为此,采集模型通过引入markuplm对于Xpath embedding表征部分来强化作弊识别能力。具体落地过程中,为了降低数据抽取、模型训练的时间和存储成本,采用ernie+XPath embedding结构,并在数据提取过程中只保留了文本标签(如
,
, ,
等)对应的XPath和文本,以及限制深度优先遍历提取文本时的XPath深度。
为了有效捕捉标记html页面的复杂结构,我们参考了markuplm从token-level、node-level和page-level不同层面的三个预训练任务:掩码标记语言模型、节点关系预测,以及标题-页面匹配。
掩码标记语言模型(Masked Markup Language Modeling, MMLM):任务用来提高模型根据标记线索对语言的建模能力,输入数据中文本的token会被随机按比例替换成[MASK], 同时会保留所有的XPath信息(包括被替换的token对应的XPath), 模型基于所有标记线索(XPath信息)来完成文本的“完形填空”的任务。
节点关系预测(Node Relation Prediction, NRP):为增强模型对Xpath embedding表征里Xpath语义信息的理解,MarkupLM通过节点级别的节点关系预测任务去显示地建模一对节点之间的关系。具体上,我们首先定义一个有向的节点关系集合,包括:自己,父,子,兄弟,祖先,子孙和其他。然后随机组合每个样本上的节点获得节点对,并根据节点关系集合分配相应的标签,模型需要用每个节点的第一个token的输出表征来预测分配的节点关系。模型对节点之间关系的理解非常有助于我们自动化地挖掘作弊页面中一些特殊结构特征,例如图6所示采集作弊页面html源码中具有的特征:同一个
下有多个由
和
组合成的段落,且互相为兄弟节点。再结合语言模型本身对文本的通顺度和相似性上的判别能力,模型就可以认为这一内容片段出现在的网页很可能是恶劣采集作弊页面。
标题-页面匹配(Ttile-Page Matching, TPM):除了文本标记带来的精细粒度信息,句子级别和主体级别的信息也对标记语言文档的学习有帮助。对于网页来说,元素
可以代表正文<body>内容的概括性总结,这就为较高级的语义提供了监督性。利用网页中这种天然的自监督特性,额外增加了一个页面级别的预训练任务:随机替换标记语言文档样本中<title>标签里的文本,让模型对每个输入根据输出序列中的[CLS]表示判断样本是否被替换。采集作弊页面中也不乏文不对题的案例,我们将这些页面加入预训练,提升模型判断页面title与正文内容是否匹配的能力,让模型在做恶劣采集识别的下游任务时,可以本能地提取到标题与正文不匹配这样的恶劣采集特征,对识别具有这部分特征的采集页面具有极大促进作用。 </p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">
<a href="http://sy0.img.it168.com/article/5/5076/5076041.jpg" target="_blank" style="margin: 0px; padding: 0px; color: rgb(0, 131, 235);">
<img alt="" src="http://sy0.img.it168.com/article/5/5076/5076041.jpg_i-730x550" style="border: none; overflow: hidden; display: inline-block; max-width: 100%; height: auto; margin: 0px auto;"/></a></p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">△图6. 采集页面html源码片段
<br/></p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 3.1 效果验证</p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 通过下面两个实验来验证采集模型引入XPath embedding后的效果增益</p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 实验1: 从黑白样本中提取text和XPath对并将其打乱。把黑text-白XPath、白text-黑xpath、黑text-黑xpath和白text-白XPath混合拼接并通过裁剪对齐生成一些新text-path对的样本,分别计算识别为作弊的比例。 </p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">
<a href="http://sy0.img.it168.com/article/5/5076/5076042.png" target="_blank" style="margin: 0px; padding: 0px; color: rgb(0, 131, 235);">
<img alt="" src="http://sy0.img.it168.com/article/5/5076/5076042.png_i-730x550" style="border: none; overflow: hidden; display: inline-block; max-width: 100%; height: auto; margin: 0px auto;"/></a></p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 实验2: mask掉XPath,将每个token对应的XPath embedding通过<pad>标签和下标为0对应的embedding替换掉,评估准召。测试集黑白比1:1情况下实验结果为:recall=0.121,precision=0.829,accuracy=0.548。</p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 由两个实验分析可得:</p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 实验1中白XPath+任意text识别为黑的比例都非常少,不足总量10%,而以黑xpath+任意text的组合识别为黑的比例比较多,当白text+黑xpath组合时模型识别作弊比例接近一半,全黑组合则几乎都被识别为作弊。</p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 实验2中模型单纯对文本进行预测时,会将几乎所有样本预测为非作弊,模型召回能力较差,效果类似在作弊与非作弊间做随机二选一</p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 3.2 采集模型新增识别页面</p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 相比规则性的策略,引入网页结构信息的模型能更加灵活地根据标签与标签之间的关系去做判别。当规则中只有针对<h2>或<h3>标签的段落进行采集特征捕获时,图7中的作弊页面会因为采集特征的段落在<h5>和<li>标签上(从图8中可知)被漏过,而基于页面结构和文本建模的采集模型则依然可以识别。 </p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">
<a href="http://sy0.img.it168.com/article/5/5076/5076043.jpg" target="_blank" style="margin: 0px; padding: 0px; color: rgb(0, 131, 235);">
<img alt="" src="http://sy0.img.it168.com/article/5/5076/5076043.jpg_i-730x550" style="border: none; overflow: hidden; display: inline-block; max-width: 100%; height: auto; margin: 0px auto;"/></a></p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">△图7. 采集示例(3) </p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">
<a href="http://sy0.img.it168.com/article/5/5076/5076044.jpg" target="_blank" style="margin: 0px; padding: 0px; color: rgb(0, 131, 235);">
<img alt="" src="http://sy0.img.it168.com/article/5/5076/5076044.jpg_i-730x550" style="border: none; overflow: hidden; display: inline-block; max-width: 100%; height: auto; margin: 0px auto;"/></a></p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">△图8. 采集示例(3)源码片段
<br/></p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 相比单纯基于文本的语言模型(如句子通顺度模型、文章拼接模型),融合网页结构的模型更容易从网站全局识别一些文章与网站主旨严重偏移的页面。如图9和图10中两个同样属于采集作弊站的页面,左图的页面标题与内容毫无关联,段落间也毫无相似处,会同时被文章级拼接模型(能够识别文章段落是否拼接、是否文不对题)和采集模型识别为采集作弊;而右图中标题与内容关联度高,段落间表达语义情感相似,文章拼接模型则无法识别作弊,采集模型能够根据页面里导航条和网页所属主题等方式进行判断识别为采集。 </p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">
<a href="http://sy0.img.it168.com/article/5/5076/5076045.jpg" target="_blank" style="margin: 0px; padding: 0px; color: rgb(0, 131, 235);">
<img alt="" src="http://sy0.img.it168.com/article/5/5076/5076045.jpg_i-730x550" style="border: none; overflow: hidden; display: inline-block; max-width: 100%; height: auto; margin: 0px auto;"/></a></p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">△图9. 采集示例(4) </p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">
<a href="http://sy0.img.it168.com/article/5/5076/5076047.jpg" target="_blank" style="margin: 0px; padding: 0px; color: rgb(0, 131, 235);">
<img alt="" src="http://sy0.img.it168.com/article/5/5076/5076047.jpg_i-730x550" style="border: none; overflow: hidden; display: inline-block; max-width: 100%; height: auto; margin: 0px auto;"/></a></p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255); text-align: center;">△图10. 采集示例(5)</p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);">
<strong>04 总结和展望</strong></p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 本文首先讨论了恶劣采集作弊站点的识别难点,以及利用网页结构信息进行辅助识别的必要性。然后介绍了MarkupLM对于内容文本和页面排版的优势。最后介绍反作弊方向将MarkupLM建模方法应用于恶劣采集站上的识别,并通过实验展示XPath embedding结构对于识别作弊站的效果。</p>
<p style="margin-top: 0px; margin-bottom: 0px; padding: 13px 0px; font-family: "Microsoft YaHei", "PingFang SC"; color: rgb(51, 51, 51); text-wrap: wrap; background-color: rgb(255, 255, 255);"> 除了应用在恶劣采集站的识别上,这样引入网页结构信息的建模方式还可以尝试扩展到其他的一些针对网页类型的作弊识别模型上,亦或是作为网页特征提取的基座对作弊页面实现多分类功能。</p> </div>
</div>
<!-- m3 END -->
<div class="page">
<ul class="clearfix m01">
<li>
<a href="/28285180/viewspace-3062297/">小红书数据一致性校验能力探索与实践</a> </li>
<li>
<a href="/28285180/viewspace-3062629/">抖音集团离线数仓血缘基础能力的构建与应用</a> </li>
</ul>
</div>
</div>
<footer>
<a href="http://www.itpub.net">ITPUB论坛</a> | <a href="http://blog.chinaunix.net/">chinaunix博客</a> | <a href="http://bbs.chinaunix.net/">chinaunix论坛</a><br>
北京皓辰网域网络信息技术有限公司. 版权所有
</footer>
<script>
$(function(){
$("#fenlei").click(function(){
$("#left_1").show();
$("#left_2").show();
});
})
</script>
</body>
</html>
<script language="javascript" src="http://stat.it168.com/pv.js"></script>
<script>
function sendPV(){
var pvTrack = new PvTrack();
pvTrack.type = 35; // 频道类别ID
pvTrack.channel = 532; // 频道ID
pvTrack.pageType = 0;
pvTrack.track();
}
window.setTimeout("sendPV()", 1000);
</script>
<div class="share_box">
<div class="share">
<div class="share_tit">分享到</div>
<div class="share_close"></div>
<ul class="share_list">
<a href="http://service.weibo.com/share/share.php?url=http://m.blog.itpub.net/28285180/viewspace-3062485&appkey=&title=网页结构建模在低质采集站上的识别应用&language=zh_cn"><li><span class="weibo">新浪微博</span></li></a>
<a href="http://sns.qzone.qq.com/cgi-bin/qzshare/cgi_qzshare_onekey?url=http://m.blog.itpub.net/28285180/viewspace-3062485&title=网页结构建模在低质采集站上的识别应用&desc=百度搜索拥有着几十亿级的流量,作弊团伙通过各种各样的手段妄想从巨大的流量中不劳而获。搜索反作弊团队维护百度搜索生态安全和质量,经过不断探索并利用前沿技术过滤低质作弊网页,保护真正付出劳动的站长的利益。本文介绍了基于MarkupLM的网页建模方式,引入XPath embedding自动化提取作弊页面结构特征,并与文本结合来进行采集站点识别。&summary=&site=&pics="><li><span class="qq"> QQ空间</span></li></a>
</ul>
<div class="weixin2"> <em></em> <i>请使用浏览器的分享功能分享到微信等</i></div>
</div>
</div>
<script>
$(".fenxiang").click(function(){
$(".share_box").show();
});
$(".share_close").click(function(){
$(".share_box").hide();
});
$(".backTop").click(function(){
$('html,body').animate({ scrollTop: 0 }, 300)
})
$('.content p br').parents('p').each(function (k,v) {
if ($(v).html() == '') {
$(v).css('display','none')
}
})
</script>
<script type="text/javascript" src="https://res.wx.qq.com/open/js/jweixin-1.0.0.js"></script>
<script>
var videoContainer = {};
$(document).delegate('.fake-video-btn', 'click', function () {
var width = $(this).parent('.video-container').width();
var height = $(this).parent('.video-container').height();
var $this = $(this);
var videoid = $(this).data('videoid');
var aliplayerid = $this.closest('.video-container').attr('id');
$.ajax({
url: 'http://blog.itpub.net/getvidoeinfo?videoid=' + videoid
, type: 'get'
, success: function (ret) {
if (ret.code == 200) {
videoContainer[videoid] = new Aliplayer({
id:aliplayerid,
autoplay:true,
width:width + 'px',
height:height + 'px',
format: "",
vid:videoid,
playauth:ret.data.PlayAuth,
cover:ret.data.VideoMeta.CoverURL,
skinLayout:[ //按钮UI
{name:"bigPlayButton","align":"cc","x":15,"y":12},//播放
{name: "H5Loading", align: "cc"},
{name: "errorDisplay", align: "tlabs", x: 0, y: 0},
{name: "infoDisplay"},
{name:"tooltip", align:"blabs",x: 0, y: 56},
{name: "thumbnail"},
{
name: "controlBar", align: "blabs", x: 0, y: 0,
children: [
{name: "progress", align: "blabs", x: 0, y: 44},
{name: "playButton", align: "tl", x: 15, y: 12},
{name: "timeDisplay", align: "tl", x: 10, y: 7},
{name: "fullScreenButton", align: "tr", x: 10, y: 12},
{name:"subtitle", align:"tr",x:15, y:12},
{name:"setting", align:"tr",x:15, y:12},
{name: "volume", align: "tr", x: 5, y: 10}
]
}
]
},function(player){
$this.siblings('img').remove();
$this.remove();
player.on('play',function(e) {
for (var key in videoContainer) {
if (videoid != key) {
videoContainer[key].pause();
}
}
});
});
} else {
alert(ret.msg);
}
}
})
});
wx.config({
debug: false, // 开启调试模式,调用的所有api的返回值会在客户端alert出来,若要查看传入的参数,可以在pc端打开,参数信息会通过log打出,仅在pc端时才会打印。
appId: 'wx4d058320abe98d01', // 必填,公众号的唯一标识
timestamp: 1775059534, // 必填,生成签名的时间戳
nonceStr: 'xLeQnigRg4PegsXS', // 必填,生成签名的随机串
signature: 'fa0ea15d462afc46b8468d6ca97a4794bcdf4301',// 必填,签名,见附录1
jsApiList: [
'onMenuShareTimeline',
'onMenuShareAppMessage'
] // 必填,需要使用的JS接口列表,所有JS接口列表见附录2
});
wx.ready(function(){
// config信息验证后会执行ready方法,所有接口调用都必须在config接口获得结果之后,config是一个客户端的异步操作,所以如果需要在页面加载时就调用相关接口,则须把相关接口放在ready函数中调用来确保正确执行。对于用户触发时才调用的接口,则可以直接调用,不需要放在ready函数中。
var title = '网页结构建模在低质采集站上的识别应用';
var desc = "";
var link = 'http://m.blog.itpub.net/28285180/viewspace-3062485/';
var imgUrl = $(".main img:first").attr('src');
if(!imgUrl){
imgUrl = 'http://m.blog.itpub.net/static/images/share.png?v1';
}
console.log(imgUrl);
wx.onMenuShareAppMessage({ //分享给朋友
title: title, // 分享标题,可在控制器端传递
desc: desc,//分享的描述,可在控制器端传递
link: link, // 分享链接,可在控制器端传递
imgUrl: imgUrl, // 分享图标 ,可在控制器端传递
success: function() {},
cancel: function() {}
});
wx.onMenuShareTimeline({ //分享到朋友圈
title: title, // 分享标题,可在控制器端传递
desc: desc,//分享的描述,可在控制器端传递
link: link, // 分享链接,可在控制器端传递
imgUrl: imgUrl, // 分享图标 ,可在控制器端传递
success: function() {},
cancel: function() {}
});
});
</script>
</body>
</html>