ORA-01555 快照太旧、Undo表空间、一致性读、延时块清除
回滚与撤销:
为了保证数据库中多个用户间的读一致性和能够回退事务,Oracle必须拥有一种机制,能够为变更的数据构造一种前镜像(before image)数据(保存修改之前的旧值),以保证那够回滚或撤销对数据库所作的修改,同时为数据恢复以及一致性读服务。
这就是回滚(或撤销)。在之前的日志中已经提到Redo,我们说Redo是用来保证在故障时事务可以被恢复,那么Undo则是用来保证事务可以被回滚或者撤销。
Oracle, 深入解析Oracle, 读书笔记十二月 23rd, 2009
什么是回滚和撤销:
首先来介绍一下什么是回滚和撤销。我们知道,从Oracle 6版本到Oracle 9i版本,Oracle用数据库中的回滚段(Rollback)来提供撤销数据(Undo Data);而从Oracle 9i开始,Oracle还提供了一种新的撤销数据(Undo Data)管理方式,就是使用Oracle自动管理的撤销(Undo)表空间(Automatic Undo Management,通常被缩写为AUM)。
事务使用回滚段来记录变化前的数据或者撤销信息,假定发出了一个更新语句:
update emp set sal=4000 where empno=7788;
下面看一下这个语句是怎样执行的(为了叙述方便,这里尽量简化了情况):
⑴ 检查empno=7788记录在Buffer Cache中是否存在,如果不存在则读取到Buffer Cache中;
⑵ 在回滚表空间的相应回滚段事务表上分配事务槽,这个操作需要记录Redo信息;
⑶ 从回滚段读入或者在Buffer Cache中创建sal=3000的前镜像,这需要产生Redo信息并记入Redo Log Buffer;
⑷ 修改sal=4000,这是update的数据变更,需要记入Redo Log Buffer;
⑸ 当用户提交时,会在Redo Log Buffer记录提交信息,并在回滚段标记事务为非激活(INACTIVE)。
在以上事务处理过程中,注意Redo和Undo是交替出现的,这两者对于数据库来说都非常重要。在以上步骤中,对于回滚段的操作存在多处,在事务开始时,首先需要在回滚表空间获得一个事务槽,分配空间,然后创建前镜像,此后事务的修改才能进行,Oracle必须以此来保证事务是可以回滚的。
如果用户提交(commit)了事务,Oracle会在日志文件记录提交,并且写出日志,同时会在回滚段中把该事务标记为已提交,提交事务在回滚段事务表的状态为INACTIVE,然后该事务所使用的回滚空间可以被重用,回滚段空间是循环使用的;如果用户回滚(Rollback)事务,则Oracle需要从回滚段中把前镜像数据读取出来,修改数据缓冲区,完成回滚,这个过程本身也要产生Redo,所以回退这个操作是很昂贵的。
在Oracle的性能优化中,有一个性能指标称为平均事务回滚率(Rollback per Transaction),用来衡量数据库的提交与回滚效率。
Statspack中计算Rollback per transaction的公式为:
Round(User rollbacks/(user commits + user rollbacks),4)×100%
其中user commits和user rollbacks数据来自系统的统计信息,可以从v$sysstat视图中得到,在Statspack中也包含着部分数据的输出:
Statistic Total per Second per Trans
--------------------------------- ------------------ -------------- ------------
user commits 508 0.2 1.0
user rollbacks 8 0.0 0.0
这个指标应该接近于0,如果该指标过高,则说明数据库的回滚过多。回滚过多不仅说明数据库经历了太多的无效操作,而且这些操作会极大影响数据库性能。
- The End -
在Oracle数据库中,undo主要有三大作用:提供一致性读(Consistent Read)、回滚事务(Rollback Transaction)以及实例恢复(Instance Recovery)。
? Roll back transactions when a ROLLBACK statement is issued
? Recover the database
? Provide read consistency
? Analyze data as of an earlier point in time by using Oracle Flashback Query
? Recover from logical corruptions using Oracle Flashback features
When a ROLLBACK statement is issued, undo records are used to undo changes that were made to the database by the uncommitted transaction. During database recovery, undo records are used to undo any uncommitted changes applied from the redo log to the datafiles. Undo records provide read consistency by maintaining the before image of the data for users who are accessing the data at the same time that another user is changing it.
回滚事务则是在执行DML以后,发出rollback命令撤销DML所作的变化。Oracle利用记录在ITL槽里记录的undo 块的地址找到该undo块,然后从中取出变化前的值,并放入数据块中,从而对事务所作的变化进行回滚。
实例恢复则是在SMON进程完成前滚并打开数据库以后发生。SMON进程会去查看undo segment头部(所谓头部就是undo segment里的第一个数据块)记录的事务表(每个事务在使用undo块时,首先要在该undo块所在的undo segment的头部记录一个条目,该条目里记录了该事务相关的信息,其中包括是否提交等),将其中既没有提交也没有回滚,而是在实例崩溃时被异常终止的事务全部回滚。
一致性读是相对于脏读(Dirty Read)而言的。假设某个表T中有10000条记录,获取所有记录需要15分钟时间。当前时间为9点整,某用户A发出一条查询语句:select * from T,该语句在9点15分时执行完毕。当用户A执行该SQL语句到9点10分的时候,另外一个用户B发出了一条delete命令,将T表中的最后一条记录删除并提交了。那么到9点15分时,A用户将返回多少条记录?
如果返回9999条记录,则说明发生了脏读;如果仍然返回10000条记录,则说明发生了一致性读。很明显,在 9点钟那个时间点发出查询语句时,表T中确实有10000条记录,只不过由于I/O的相对较慢,所以才会花15分钟完成所有记录的检索。
对于Oracle 数据库来说,没有办法实现脏读,必须提供一致性读,并且该一致性读是在没有阻塞用户的DML的前提下实现的。
那么undo数据是如何实现一致性读的呢?还是针对上面的例子。用户A在9点发出查询语句时,服务器进程会将9 点那个时间点上的SCN号记录下来,假设该SCN号为SCN9.00。那么9点整的时刻的SCN9.00一定大于等于记录在所有数据块头部的ITL槽中的 SCN号(如果有多个ITL槽,则为其中最大的那个SCN号)。
注:
ITL(Interested Transaction List)是 Oracle数据块内部的一个组成部分,用来记录该块所有发生的事务,一个itl可以看作是一个记录,在一个时间,可以记录一个事务(包括提交或者未提交 事务)。当然,如果这个事务已经提交,那么这个itl的位置就可以被反复使用了,因为itl类似记录,所以,有的时候也叫itl槽位。
服 务器进程在扫描表T的数据块时,会把扫描到的数据块头部的ITL槽中的SCN号与SCN9:00之间进行比较,哪个更大。如果数据块头部的SCN号比 SCN9.00要小,则说明该数据块在9点以后没有被更新,可以直接读取其中的数据;否则,如果数据块ITL槽的SCN号比SCN9.00要大,则说明该 数据块在9点以后被更新了,该块里的数据已经不是9点那个时间点的数据了,于是要借助undo块。
9点10分,B用户更新了表T的最后一 条记录并提交(注意,在这里,提交或者不提交并不是关键,只要用户B更新了表T,用户A就会去读undo数据块)。假设被更新记录属于N号数据块。那么这 个时候N号数据块头部的ITL槽的SCN号就被改为SCN9.10。当服务器进程扫描到被更新的数据块(也就是N号块)时,发现其ITL槽中的 SCN9.10大于发出查询时的SCN9.00,说明该数据块在9点以后被更新了。
于是服务器进程到N号块的头部,找到SCN9.10所在的ITL槽。由 于ITL槽中记录了对应的undo块的地址,于是根据该地址找到undo块,将 undo块中的被修改前的数据取出,再结合N号块里的数据行,从而构建出9点10分被更新之前的那个时间点的数据块内容,这样的数据块叫做CR块(Consistent Read)。
对于delete来说,其undo信息就是insert,也就是说该构建出来的CR块中就插入了被删除的那条记录。随后,服务器进程扫描该 CR块,从而返回正确的10000条记录。
让我们继续把问题复杂化。假设在9点10分B用户删除了最后一条记录并提交以后,紧跟着9点11分,C用户在同一个数据块里(也就是N号块)插入了2条记录。这个时候Oracle又是如何实现一致性读的呢(假设表T的initrans为1,也就是只有一个ITL 槽)?因为我们已经知道,事务需要使用ITL槽,只要该事务提交或回滚,该ITL槽就能够被重用。换句话说,该ITL槽里记录的已经是SCN9.11,而不是SCN9.10了。这时,ITL槽被覆盖了,Oracle的服务器进程又怎能找回最初的数据呢?
其中的秘密就在于,Oracle在记录undo数据的时候,不仅记录了改变前的数据,还记录了改变前的数据所在的数据块头部的ITL信息。因此,9点10分B用户删除记录时(位于N号块里,并假设该N号块的ITL信息为[Undo_block0 / SCN8.50]),则Oracle会将改变前的数据(也就是insert)放到undo块(假设该undo块地址为Undo_block1)里,同时在该undo块里记录删除前ITL槽的信息(也就是[Undo_block0 / SCN8.50])。
删除记录以后,该N号块的ITL信息变为 [Undo_block1 / SCN9.10]; 到了9点11分,C用户又在N号块里插入了两条记录,则Oracle将插入前的数据(也就是delete两条记录)放到undo块(假设该undo块的地 址为Undo_block2)里,并将9点11分时的ITL槽的信息(也就是[Undo_block1 / SCN9.10])也记录到该undo块里。插入两条记录以后,该N号块的ITL槽的信息改为 [Undo_block2 / SCN9.11]。
那么当执行查询的服务器进程扫描到N号块时,发现SCN9.11大于SCN9.00,于是到ITL槽中指定的 Undo_block2处找到该undo块。发现该undo块里记录的ITL信息为[Undo_block1 / SCN9.10],其中的SCN9.10仍然大于SCN9.00,于是服务器进程继续根据ITL中记录的Undo_block1,找到该undo块。
发现该undo块里记录的ITL信息为[Undo_block0 / SCN8.50], 这时ITL里的SCN8.50小于发出查询时的SCN9.00,说明这时undo块包含合适的undo信息,于是服务器进程不再找下去,而是将N号块、 Undo_block2以及Undo_block1的数据结合起来,构建CR块。将当前N号的数据复制到CR块里,然后在CR块里先回退9点11分的事 务,也就是在CR块里删除两条记录,然后再回退9点10分的事务,也就是在CR块里插入被删除的记录,从而构建出9点钟时的数据。
Oracle就是这样,以层层嵌套的方式,查找整个undo块的链表,直到发现ITL槽里的SCN号小于等于发出查询时的那个SCN号为止。正常来说,当前undo块里记录的SCN号要比上一个undo块里记录的SCN号要小。
但 是在查找的过程中,可能会发现当前undo块里记录的ITL槽的SCN号比上一个undo块里记录的SCN号还要大。这种情况说明由于事务被提交或回滚, 导致当前找到的undo块里的数据已经被其他事务覆盖了,于是我们无法再找出小于等于发出查询时的那个时间点的SCN号,这时Oracle就会抛出一个非 常经典的错误——ORA-1555,也就是snapshot too old的错误。
以上的描述可以用图来描述:

oracle通过undo保证一致性读和不发生脏读
1.不发生脏读
例如:用户A对表更新了,没有提交,用户B对进行查询,没有提交的更新不能出现在用户的查询结果中
举例并通个dump数据块说明避免脏读的原理
创建测试表,并插入两条记录,会话A执行更新但不提交
SQL> select * from test;
ID NAME
---------- ----------
1 A
2 B
SQL> update test set name='C' where id=2;
1 row updated.
会话B查询,数据没变
SQL> select * from test;
ID NAME
---------- ----------
1 A
2 B
通过下面sql语句查询数据所在的数据文件和块号,并进行dump
SQL> select id, rowid, dbms_rowid.rowid_relative_fno(rowid) fn,dbms_rowid.rowid_block_number(rowid) bk from test order by id;
ID ROWID FN BK
---------- ------------------ ---------- ----------
1 AAAzkeAAIAAAACDAAA 8 131
2 AAAzkeAAIAAAACDAAB 8 131
SQL> alter system dump datafile 8 block 139;
System altered.
未提交的数据块dump结果
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0002.001.000a90a2 0x00c00093.9f1d.16 C--- 0 scn 0x0000.395178de
0x02 0x0007.010.000a93c5 0x00c00f4b.9f5d.34 ---- 1 fsc 0x0000.00000000
---上面事务槽中Flag为 ---- 从0x00c00f4b undo地址中读取
bdba: 0x0200008b
data_block_dump,data header at 0x7fb742fc8a64
===============
tsiz: 0x1f98
hsiz: 0x16
pbl: 0x7fb742fc8a64
76543210
flag=--------
ntab=1
nrow=2
frre=-1
fsbo=0x16
fseo=0x1f88
avsp=0x1f70
tosp=0x1f70
0xe:pti[0] nrow=2 offs=0
0x12:pri[0] offs=0x1f90
0x14:pri[1] offs=0x1f88
block_row_dump: ---下面是表中数据行的dump
tab 0, row 0, @0x1f90
tl: 8 fb: --H-FL-- lb: 0x0 cc: 2
col 0: [ 2] c1 02
col 1: [ 1] 41 --第一行 A
tab 0, row 1, @0x1f88
tl: 8 fb: --H-FL-- lb: 0x2 cc: 2 ---lb为0x2 说明未提交
col 0: [ 2] c1 03
col 1: [ 1] 43 ---第二行 C
end_of_block_dump
说明:通过上面的dump文件发现,数据已经被修改成C(43),但是Oracle发现这条数据有lb: 0x2 对应的是ITL,从ltl为0x02的记录看到flag为——,表示有事务标记,数据被加锁,需要从undo段的uba(undo block address)中读取
undo段中对应的块信息为:0x00c00f4b,这里是十六进制,下面先转换成10进制
SQL> select to_number('00c00f4b','XXXXXXXXXXXXXXX') from dual;
TO_NUMBER('00C00F4B','XXXXXXXXXXXXXXX')
---------------------------------------
12586827
得到值为 12586827
对undo块进行dump
在通过下面的语句得到数据块信息:
SQL> select dbms_utility.data_block_address_file(12586827), dbms_utility.data_block_address_block(12586827) from dual;
DBMS_UTILITY.DATA_BLOCK_ADDRESS_FILE(12586827) DBMS_UTILITY.DATA_BLOCK_ADDRESS_BLOCK(12586827)
---------------------------------------------- -----------------------------------------------
3 3915
SQL> select file#,name from v$datafile where file#=3;
FILE# NAME
---------- --------------------------------------------------
3 /u01/app/oracle/oradata/FGLDB/undotbs01.dbf
SQL> alter system dump datafile 3 block 3915;
System altered.
dump内容如下:
*-----------------------------
* Rec #0x34 slt: 0x10 objn: 211231(0x0003391f) objd: 211231 tblspc: 4(0x00000004) --objd 为object id
* Layer: 11 (Row) opc: 1 rci 0x00
Undo type: Regular undo Begin trans Last buffer split: No
Temp Object: No
Tablespace Undo: No
rdba: 0x00000000Ext idx: 0
flg2: 0
*-----------------------------
uba: 0x00c00f4b.9f5d.25 ctl max scn: 0x0000.39516d48 prv tx scn: 0x0000.39516db3
txn start scn: scn: 0x0000.395178de logon user: 83
prev brb: 12586818 prev bcl: 0
KDO undo record:
KTB Redo
op: 0x03 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: Z
Array Update of 1 rows:
tabn: 0 slot: 1(0x1) flag: 0x2c lock: 0 ckix: 12
ncol: 2 nnew: 1 size: 0
KDO Op code: 21 row dependencies Disabled
xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x0200008b hdba: 0x0200008a
itli: 2 ispac: 0 maxfr: 4858
vect = 3
col 1: [ 1] 42 --- undo中数据为B
从undo块中发现值为B(42),故其他用户看到的是B,看不到C,避免了脏读
附:提交后的数据块dump结果
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0002.001.000a90a2 0x00c00093.9f1d.16 C--- 0 scn 0x0000.395178de
0x02 0x0007.010.000a93c5 0x00c00f4b.9f5d.34 C--- 0 scn 0x0000.39517d7a
---Flag为C---
bdba: 0x0200008b
data_block_dump,data header at 0x7fa3c77efa64
===============
tsiz: 0x1f98
hsiz: 0x16
pbl: 0x7fa3c77efa64
76543210
flag=--------
ntab=1
nrow=2
frre=-1
fsbo=0x16
fseo=0x1f88
avsp=0x1f70
tosp=0x1f70
0xe:pti[0] nrow=2 offs=0
0x12:pri[0] offs=0x1f90
0x14:pri[1] offs=0x1f88
block_row_dump:
tab 0, row 0, @0x1f90
tl: 8 fb: --H-FL-- lb: 0x0 cc: 2
col 0: [ 2] c1 02
col 1: [ 1] 41
tab 0, row 1, @0x1f88
tl: 8 fb: --H-FL-- lb: 0x0 cc: 2 --- lb为0x0
col 0: [ 2] c1 03
col 1: [ 1] 43
end_of_block_dump
总结:数据库通过判断数据块头部的ITL槽的信息来确定是否有未提交的事务,如果事务槽Flag为——,则通过事务槽中的undo块地址查询到原来的数据,进而达到数据隔离的效果,避免脏读。
2.一致性读
例如:假设某一个用户A在6点对某一个表发出了一个查询数据量很大的数据,需要15分钟才能把结果完全查询出来,在这期间,6点10分用户B对数据进行了更新并提交了,用户A查询的结果仍然是6点时候的表的数据,用户B更新的数据不出现在用户A的查询结果中,这就是一致性读。

-
用户A在执行开始的时候会记录当时的SCN号,如图中10021
-
在每次从数据块中读数据的时候会比较记录的SCN号和数据块事务槽中的SCN号(下一个事务的SCN号一定比当前的大)
a.如果数据块中的SCN比当前分配的SCN号小,则认为该数据没有被修改,直接读取;
b.如果数据块中的SCN号比当前分配的SCN大,则根据块中保存的地址去undo中读取当时分配SCN时间点的数据(根据undo数据块在内存中重新构造出该数据块,称为consistent read (CR)块)
一个查询如果耗费很长时间,而查询的结果在查询的阶段被更改了,而且对应着undo段的数据已经被清理了,就会发生Oracle中著名的ORA-01555: snapshot too old(快照太久)错误。
如果一条数据在查询期间被更新过多次并且提交,后放入undo段的块会记录相对的块上次放在undo段中的块地址,从而一路寻找到查询开始时间点在undo段中的数据块。
3. 事务槽(ITL)小解
ITL(Interested Transaction List)是Oracle数据块内部的一个组成部分,位于数据块头(block header),itl由xid,uba,flag,lck和scn/fsc组成,用来记录该块所有发生的事务,一个itl可以看作是一条事务记录。当然,如果这个事务已经提交,那么这个itl的位置就可以被反复使用了,因为itl类似记录,所以,有的时候也叫itl槽位。如果一个事务一直没有提交,那么,这个事务将一直占用一个itl槽位,itl里面记录了事务信息,回滚段的入口,事务类型等等。如果这个事务已经提交,那么,itl槽位中还保存的有这个事务提交时候的SCN号。

Xid:事务id,在回滚段事务表中有一条记录和这个事务对应
Uba:回滚段地址,该事务对应的回滚段地址
-
第一段地址:回滚数据块的地址,包括回滚段文件号和数据块号
-
第二段地址:回滚序列号
-
第三段地址:回滚记录号
—查看UBA
SELECT UBAFIL undo_file_id,UBABLK undo_blk_num,UBASQN undo_segment_num,UBAREC undo_recode_num FROM v$transaction;
Flag:事务标志位。这个标志位就记录了这个事务的操作,各个标志的含义分别是:
-
——- = 事务是活动的,或者在块清除前提交事务
-
C—- = 事务已经提交并且清除了行锁定。
-
-B— = this undo record contains the undo for this ITL entry
-
—U- = 事务已经提交(SCN已经是最大值),但是锁定还没有清除(快速清除)。
-
—-T = 当块清除的SCN被记录时,该事务仍然是活动的,块上如果有已经提交的事务,
那么在clean ount的时候,块会被进行清除,但是这个块里面的事务不会被清除。
Lck:影响的记录数
Scn/Fsc:快速提交(Fast Commit Fsc)的SCN或者Commit SCN。
每条记录中的行级锁对应于Itl列表中的序号,即哪个事务在该记录上产生的锁。
Oracle的块清除有两种:
1:快速块清除(fast commit cleanout)
2:延时块清除(delayed block cleanout)
数据库块的最前面有一个“开销”空间(overhead),这里会存放该块的一个事务表,对于锁定了该块中某些数据的各个“实际”事务,在这个事务表中都有一个相应的条目。
1)首先当一个事务开始时,需要在回滚段事务表上分配一个事务槽;
2)在数据块头部获得一个ITL事务槽,该事务槽指向回滚段段头的事务槽;
3)在修改数据之前,需要在回滚段中记录前镜像信息,回滚段头事务槽指向该记录;
4) 锁定修改行,修改行锁定位(lb-lock block)指向ITL事务槽;
5) 数据修改可以进行。
COMMIT时候Oracle需要将回滚段上的事务表信息标记为非活动,以便空间可以重用;此外所做的一个操作是块清除(Block cleanout),如果事务修改的某些块还在缓冲区缓存中,会清除块首部的ITL事务信息(包括提交标志、SCN等)和锁定信息。
在与我们的事务相关的提交列表中,Oracle会记录已修改的块列表(每个列表可以有20个块指针),Oracle会根据需要分配多个这样的列表,直至达到某个临界点。如果我们修改的块加起来超过了块缓冲区缓存大小的10%,Oracle 会停止为我们分配新的列表。例如,如果缓冲区缓存设置为可以缓存3,000个块,Oracle 会为我们维护最多300个块。
COMMIT时,Oracle会通过这些列表找到块,如果块仍在块缓冲区中,Oracle会执行一个很快的清理,这叫做 快速块清除(FAST BLOCK CLEANOUT)。
所以,只要我们修改的块数没有超过缓存中总块数的10%,而且块仍在块缓存区中(如果已经被写回到数据文件上再次读出该数据块进行修改成本过于昂贵),Oracle就会在COMMIT时清理这些块。否则,就会延迟块清除到下次访问该块的时候。通过延迟块清除(DELAYED BLOCK CLEANOUT)可以提高数据库的性能,加快提交操作。
所以如果执行一个大的INSERT、UPDATE或DELETE,影响数据库中的许多块,就有可能在此之后,第一个“接触”块的查询会需要修改某些块首部并把块弄脏,生成REDO日志,会导致DBWR把这些块写入磁盘。 (--所以说select 语句也有可能会产生redo日志)
如果Oracle不对块完成这种延迟清除,那么COMMIT的处理可能很长,COMMIT必须重新访问每一个块,可能还要从磁盘将块再次读入(它们可能已经刷新输出)。
在一个OLTP系统中,可能从来不会看到这种情况发生,因为OLTP系统的特点是事务都很短小,只会影响为数不多的一些块。
如果你有如下的处理,就会受到块清除的影响:
比较好的做法是:在批量加载了数据后,通过运行DBMS_STATS实用程序来收集统计信息,就能自然的完成块清除工作。

上面所述就是块清除的概念,下面介绍一下为什么延迟块清除会造成ORA-01555错误,ORA-01555错误的原因大概有几个:
首先要说明一点,oracle-01555错误是一个安全的错误,它不会造成数据丢失或者损坏,只是会让收到该错误的查询无法继续。
1、undo太小 如果在一个查询(时间较长的查询)开始后,对表进行了dml操作,因为oracle的一致性读,那么查询就需要用到相应的回滚数据。但是因为查询的时间较长,在我们需要用那些回滚段来构造cr块时发现回滚段已经被其他数据覆盖了。这样就会报oracle-01555错误!
比较直观的解决方法是DBA告诉数据库应用最长的查询需要多长时间,并把UNDO_RETENTION设为这个值,同时相应增大undo表空间大小。
在此我给大家稍微介绍一下orale中UNDO_RETENTION这个参数。oracle回滚段中区有四种状态active,inactive,expired,free
active表示事物还在活动;
inactive表示事物已提交(区可用但是尽量避免使用);
expired表示undo区可以被覆盖;
free表示空闲的区
这里我们主要关注一下inactive和expired两个状态的区别
inactive表示事物已经提交,理论上此时区已经可以被重新使用,但是因为oracle的一致性读,所以我们可能还需要把inactive区中的数据再保留一段时间,保留多长时间由UNDO_RETENTION参数决定。在保留了UNDO_RETENTION时间后,区的状态就改成expired。 (--注意如果一个事物需要用回滚段,而回滚表空间中此时已经没有free,和expired状态的区,那么就算inactive区没有被保留够UNDO_RETENTION时间,也是可以被使用的)
2、延迟块清除
是由于在执行块清除的时候找不到回滚段中块头的相关SCN等信息,导致的ORA-01555,跟上面造成的错误(数据库的查询)没关系,一直以来的错误理解是undo中的实际的数据被覆盖了
这种情况比较少见,特别是在OLTP系统里,在OLAP系统里可能会碰到,解决方法是在每次大量的insert或update之后,记得用DBMS_STATS包扫描相关对象。
前面我已经说了为什么会有延时块清除,主要是为了提高事物的效率!
延迟清除的块的下一个读者,首先根据块中的记录的回滚信息去查找回滚段中记录的commit时的SCN,但回滚段可能已回绕,找不到提交时的scn了,但是,从回滚段中可以得到一个最小的提交scn并且该事务已经提交肯定小于这个从回滚段中还存在的最小scn。那么oracle给这个块清除的事务分配一个从回滚段中找到的最小事务scn。这虽然不准确,但是是安全的,对于数据访问也不构成影响。所以叫 upper bound ,猜测的一个scn的上限。
延迟清除的块在被select 时,如果读的select 的scn 比这个回滚段里面最小的scn 还要小的话(回滚段已回绕),那么在回滚段里面找不到数据了,oracle 就没有办法判断select 的SCN 与被要清除的数据块的大小关系,于是ora-01555就出现了,这个时候oracle 就不知道数据块里面的数据是不是是查询时刻需要的数据.
如果select scn 大于回滚段里面最小的scn 的话,那么oracle 就使用这个最小的scn 来做为这个事务的 scn 来更新块的itl ,从而完成块的清除.
上面的描述有点绕,下面是我总结的一个非常直观的理解:

图 1
如上图所示,
(1)有事务大量修改了T表的数据,或者A表的数据虽然被事务少量修改,但是一部分(超过内存10%的块)修改过的块已经刷出内存并写到了磁盘上。随即事务提交,提交时刻为SCN1。而提交时写到磁盘的数据块上的事务没有被清除(延迟块清除)。

图 2
(2)在SCN2 时间点,开始了一个select查询语句,假如SCN2与SCN1之间间隔比较长,也就是关于T表之前的undo信息全部被重用,所以找不到commit时刻的准确SCN(SCN3<>SCN1),此时oracle会从undo段中找一个最小的SCN(如SCN3),因为undo已经重用,所以即使是undo中最小的SCN3也是大于SCN1的(如图),oracle会把SCN3分配给块清除事务进而完成块清除。这时有两种情形:
如图2中第一种情形,如果查询开始时的SCN(SCN2)大于undo中最小的SCN3(即SCN1), 这是没问题的,使用最小的SCN3完成块清除
如图2中第二种情形,如果SCN2错误。
【Undo】Oracle回滚机制的深入研究
回滚机制的深入研究:
如果大家有兴趣深入了解一下回滚段的机制,那么请跟随我将前面的例子进一步深化。
1. 从DML更新事务开始:
重新来看这个更新语句:
sys@TQGZS11G> conn scott/tiger
Connected.
scott@TQGZS11G> select * from emp;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- --------------- --------------- ---------- --------------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-DEC-80 800 20
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30
7521 WARD SALESMAN 7698 22-FEB-81 1250 500 30
7566 JONES MANAGER 7839 02-APR-81 2975 20
7654 MARTIN SALESMAN 7698 28-SEP-81 1250 1400 30
7698 BLAKE MANAGER 7839 01-MAY-81 2850 30
7782 CLARK MANAGER 7839 09-JUN-81 2450 10
7788 SCOTT ANALYST 7566 19-APR-87 3000 20
7839 KING PRESIDENT 17-NOV-81 5000 10
7844 TURNER SALESMAN 7698 08-SEP-81 1500 0 30
7876 ADAMS CLERK 7788 23-MAY-87 1100 20
7900 JAMES CLERK 7698 03-DEC-81 950 30
7902 FORD ANALYST 7566 03-DEC-81 3000 20
7934 MILLER CLERK 7782 23-JAN-82 1300 10
14 rows selected.
scott@TQGZS11G> update emp set sal=4000 where empno=7788;
1 row updated.
先不提交这个事务,在另外窗口新口Session,使用SYS用户查询相关信息,进行进一步分析研究。
2.获得事务信息:
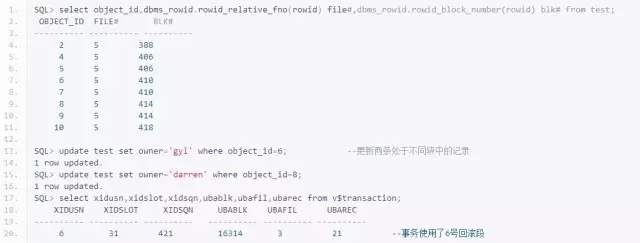
从事务表中可以获得关于这个事务的信息,该事务位于6号回滚段(XIDUSN),在6号回滚段上,该事务位于第0号事务槽(XIDSLOT):
sys@TQGZS11G> select xidusn,xidslot,xidsqn,ubablk,ubafil,ubarec from v$transaction;
XIDUSN XIDSLOT XIDSQN UBABLK UBAFIL UBAREC
---------- ---------- ---------- ---------- ---------- ----------
6 0 898 20650 3 23
从V$ROLLSTAT视图中也可以获得事务信息,XACTS字段代表的是活动事务的数量,同样看到该事务位于6号回滚段:
sys@TQGZS11G> select usn,writes,rssize,xacts,hwmsize,shrinks,wraps from v$rollstat;
USN WRITES RSSIZE XACTS HWMSIZE SHRINKS WRAPS
---------- ---------- ---------- ---------- ---------- ---------- ----------
0 5408 385024 0 385024 0 0
1 35358 52617216 0 52617216 0 0
2 59510 2285568 0 2285568 0 1
3 26232 61530112 0 61530112 0 0
4 46336 2220032 0 2220032 0 0
5 27252 38723584 0 38723584 0 0
6 23784 31580160 1 31580160 0 0
7 26116 3268608 0 3268608 0 0
8 29098 40689664 0 40689664 0 0
9 27214 1236992 0 1236992 0 0
10 31534 2285568 0 2285568 0 0
11 rows selected.
3. 获得回滚段名称并转储段头信息:
查询V$ROLLNAME视图获得回滚段名称,并转储回滚段头信息:
sys@TQGZS11G> select * from v$rollname where usn=6;
USN NAME
---------- --------------------------------------------------
6 _SYSSMU6_1186132793$
sys@TQGZS11G> alter system dump undo header '_SYSSMU6_1186132793$';
System altered.
生成的跟踪文件如下:
sys@TQGZS11G> @gettrcname.sql
TRACE_FILE
--------------------------------------------------------------------------------
/oracle/diag/rdbms/tqgzs11g/tqgzs11g/trace/tqgzs11g_ora_10642.trc
4. 获得跟踪文件信息:
注意这就是前边多次提到过的回滚段头的信息,其中包括事务表信息,从以下的跟踪文件中,可以清晰地看到这些内容:
********************************************************************************
Undo Segment: _SYSSMU6_1186132793$ (6)
********************************************************************************
Extent Control Header
-----------------------------------------------------------------
Extent Header:: spare1: 0 spare2: 0 #extents: 122 #blocks: 3855
last map 0x00000000 #maps: 0 offset: 4080
Highwater:: 0x00c050aa ext#: 116 blk#: 33 ext size: 128
#blocks in seg. hdr's freelists: 0
#blocks below: 0
mapblk 0x00000000 offset: 116
Unlocked
Map Header:: next 0x00000000 #extents: 122 obj#: 0 flag: 0x40000000
Extent Map
-----------------------------------------------------------------
0x00c0005a length: 7
0x00c07d01 length: 8
0x00c07f09 length: 8
<省略部分内容……>
0x00c06289 length: 128
0x00c06671 length: 8
0x00c06709 length: 128
Retention Table
-----------------------------------------------------------
Extent Number:0 Commit Time: 1248914085
Extent Number:1 Commit Time: 1248914087
Extent Number:2 Commit Time: 1248914087
Extent Number:3 Commit Time: 1248914087
<省略部分内容……>
Extent Number:119 Commit Time: 1248914063
Extent Number:120 Commit Time: 1248914069
Extent Number:121 Commit Time: 1248914085
TRN CTL:: seq: 0x02d5 chd: 0x0010 ctl: 0x0013 inc: 0x00000000 nfb: 0x0000
mgc: 0xb000 xts: 0x0068 flg: 0x0001 opt: 2147483646 (0x7ffffffe)
uba: 0x00c050aa.02d5.17 scn: 0x0000.0010603b
Version: 0x01
FREE BLOCK POOL::
uba: 0x00000000.02d5.16 ext: 0x74 spc: 0x14d6
uba: 0x00000000.02d5.05 ext: 0x74 spc: 0xc48
uba: 0x00000000.02d4.38 ext: 0x73 spc: 0x6f6
uba: 0x00000000.0000.00 ext: 0x0 spc: 0x0
uba: 0x00000000.0000.00 ext: 0x0 spc: 0x0
TRN TBL::
index state cflags wrap# uel scn dba parent-xid nub stmt_num cmt
------------------------------------------------------------------------------------------------
0x00 10 0x80 0x0382 0x0074 0x0000.0010633d 0x00c050aa 0x0000.000.00000000 0x00000001 0x00000000 0
0x01 9 0x00 0x0381 0x000b 0x0000.001061aa 0x00c050a9 0x0000.000.00000000 0x00000001 0x00000000 1
261838661
0x02 9 0x00 0x0381 0x001a 0x0000.00106276 0x00c050aa 0x0000.000.00000000 0x00000002 0x00000000 1
261838662
<省略后面内容……>
回顾前面的事务信息,该事务正好占用的是第0号事务槽(0x00),状态(state)为10代表是活动事务。
5. 转储前镜像信息:
再来看DBA(Data Block Address),这个DBA指向的就是包含这个事务的前镜像的数据地址0x00c050aa。看一下这个地址如何换算:DBA代表数据块的存储地址,由10位文件号+22位数据块(Block)组成。将0x00c050aa转换为二进制就是:0000 0000 1100 0000 0101 0000 1010 1010。
前10位代表文件号为3,后22位代表Block号为20650。经过转换后,该前镜像信息位于file 3 block 20650。这与从事务表中查询得到的数据完全一致:
sys@TQGZS11G> select xidusn,xidslot,xidsqn,ubablk,ubafil,ubarec from v$transaction;
XIDUSN XIDSLOT XIDSQN UBABLK UBAFIL UBAREC
---------- ---------- ---------- ---------- ---------- ----------
6 0 898 20650 3 23
提示:
很多深入研究的内容在数据库内部都有完整的体现,不过通常我们很少注意,只有将两者结合起来学习、研究和理解,我们才能深刻地理解到Oracle的本质。希望大家在阅读这部分内容的时候能够耐心、细致并有所收获。
为了同时说明一些其它内容,继续先前的SCOTT用户的事务,再更新2条记录:
scott@TQGZS11G> update emp set sal=4000 where empno=7788;
1 row updated.
scott@TQGZS11G> update emp set sal=4000 where empno=7782;
1 row updated.
scott@TQGZS11G> update emp set sal=4000 where empno=7698;
1 row updated.
然后将回滚段中的这个Block转储出来:
sys@TQGZS11G> alter system dump datafile 3 block 20650;
System altered.
这是跟踪文件开始部分的信息:
sys@TQGZS11G> @gettrcname.sql
TRACE_FILE
--------------------------------------------------------------------------------
/oracle/diag/rdbms/tqgzs11g/tqgzs11g/trace/tqgzs11g_ora_10642.trc
*** 2009-12-26 23:10:20.230
Start dump data blocks tsn: 2 file#:3 minblk 20650 maxblk 20650
Block dump from cache:
Dump of buffer cache at level 4 for tsn=2, rdba=12603562
BH (0x247e5adc) file#: 3 rdba: 0x00c050aa (3/20650) class: 28 ba: 0x24442000
set: 3 bsz: 8192 bsi: 0 sflg: 0 pwc: 0, 25 lid: 0x00000000,0x00000000
dbwrid: 0 obj: -1 objn: 0 tsn: 2 afn: 3
hash: [0x24bf433c,0x323ad5b4] lru: [0x247e50ac,0x247e4e3c]
obj-flags: object_ckpt_list
ckptq: [0x243f1380,0x25ff1d40] fileq: [0x327dc7cc,0x26ff4858] objq: [0x26ff480c,0x303aa140]
st: XCURRENT md: NULL tch: 8
flags: buffer_dirty block_written_once redo_since_read
gotten_in_current_mode
LRBA: [0x37.1378.0] LSCN: [0x0.106841] HSCN: [0x0.10684c] HSUB: [1]
cr pin refcnt: 0 sh pin refcnt: 0
buffer tsn: 2 rdba: 0x00c050aa (3/20650)
scn: 0x0000.0010684c seq: 0x01 flg: 0x00 tail: 0x684c0201
frmt: 0x02 chkval: 0x0000 type: 0x02=KTU UNDO BLOCK
Hex dump of block: st=0, typ_found=1
Dump of memory from 0x24442000 to 0x24444000
24442000 0000A202 00C050AA 0010684C 00010000 [.....P..Lh......]
24442010 00000000 00000006 00000382 191902D5 [................]
24442020 1FE80000 1EE81F74 1DDC1E74 1CF01D78 [....t...t...x...]
<中间部分内容省略……>
24443FD0 C5480C10 B4AF0FAE 891FD92E FC98F37F [..H.............]
24443FE0 1CA71084 28AEF9CD 11049EAA 5BB894EF [.......(.......[]
24443FF0 2001136C 0C6D7807 182D081A 684C0201 [l.. .xm...-...Lh]
********************************************************************************
UNDO BLK:
xid: 0x0006.000.00000382 seq: 0x2d5 cnt: 0x19 irb: 0x19 icl: 0x0 flg: 0x0000
注意这部分信息中有一个参数irb: 0x19,irb指的是回滚段中记录的最近未提交变更开始之处,如果开始回滚,这是起始的搜索点。
接下来是回滚信息的偏移量,最后一个地址正好0x19的信息:
Rec Offset Rec Offset Rec Offset Rec Offset Rec Offset
---------------------------------------------------------------------------
0x01 0x1f74 0x02 0x1ee8 0x03 0x1e74 0x04 0x1ddc 0x05 0x1d78
0x06 0x1cf0 0x07 0x1bcc 0x08 0x1b64 0x09 0x1b0c 0x0a 0x1ab8
0x0b 0x1a5c 0x0c 0x19e8 0x0d 0x198c 0x0e 0x1938 0x0f 0x189c
0x10 0x1814 0x11 0x1788 0x12 0x1720 0x13 0x1690 0x14 0x1608
0x15 0x157c 0x16 0x1514 0x17 0x1490 0x18 0x1434 0x19 0x13d8
从接下来的信息中找到0x19信息:
*-----------------------------
* Rec #0x19 slt: 0x00 objn: 69515(0x00010f8b) objd: 69515 tblspc: 4(0x00000004)
* Layer: 11 (Row) opc: 1 rci 0x18
Undo type: Regular undo Last buffer split: No
Temp Object: No
Tablespace Undo: No
rdba: 0x00000000
*-----------------------------
KDO undo record:
KTB Redo
op: 0x02 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: C uba: 0x00c050aa.02d5.18
KDO Op code: URP row dependencies Disabled
xtype: XA flags: 0x00000000 bdba: 0x0100001f hdba: 0x0100001b
itli: 2 ispac: 0 maxfr: 4858
tabn: 0 slot: 5(0x5) flag: 0x2c lock: 0 ckix: 0
ncol: 8 nnew: 1 size: 1
col 5: [ 3] c2 1d 33
c2 1d 33转换为十进制就是2850(关于数字值的内部存储及转换方式请参考前面日志)。这是最后更新记录的前镜像,Oracle就是这样通过回滚段保留前镜像信息的:
update emp set sal=4000 where empno=7698;
注意在这条UNDO记录上,还记录一个数据rci,该参数代表的就是UNDO Chain(同一事务中的多次修改,根据Chain链接关联)的下一个偏移量,此处为rci 0x18。找到0x18这条UNDO记录:
*-----------------------------
* Rec #0x18 slt: 0x00 objn: 69515(0x00010f8b) objd: 69515 tblspc: 4(0x00000004)
* Layer: 11 (Row) opc: 1 rci 0x17
Undo type: Regular undo Last buffer split: No
Temp Object: No
Tablespace Undo: No
rdba: 0x00000000
*-----------------------------
KDO undo record:
KTB Redo
op: 0x02 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: C uba: 0x00c050aa.02d5.17
KDO Op code: URP row dependencies Disabled
xtype: XA flags: 0x00000000 bdba: 0x0100001f hdba: 0x0100001b
itli: 2 ispac: 0 maxfr: 4858
tabn: 0 slot: 6(0x6) flag: 0x2c lock: 0 ckix: 0
ncol: 8 nnew: 1 size: 1
col 5: [ 3] c2 19 33
这里记录的c2 19 33转换为十进制就是2450,是第二条更新的前镜像数据:
update emp set sal=4000 where empno=7782;
这里的rci指向下一条记录rci 0x17,找到0x17:
*-----------------------------
* Rec #0x17 slt: 0x00 objn: 69515(0x00010f8b) objd: 69515 tblspc: 4(0x00000004)
* Layer: 11 (Row) opc: 1 rci 0x00
Undo type: Regular undo Begin trans Last buffer split: No
Temp Object: No
Tablespace Undo: No
rdba: 0x00000000Ext idx: 0
flg2: 0
*-----------------------------
uba: 0x00c050aa.02d5.14 ctl max scn: 0x0000.00106005 prv tx scn: 0x0000.0010603b
txn start scn: scn: 0x0000.00000000 logon user: 81
prev brb: 12603560 prev bcl: 0
KDO undo record:
KTB Redo
op: 0x03 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: Z
KDO Op code: URP row dependencies Disabled
xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x0100001f hdba: 0x0100001b
itli: 2 ispac: 0 maxfr: 4858
tabn: 0 slot: 7(0x7) flag: 0x2c lock: 0 ckix: 0
ncol: 8 nnew: 1 size: 0
Vector content:
col 5: [ 2] c2 1f
这里c2 1f转换为十进制是3000,正是第一条更新的前镜像记录:
update emp set sal=4000 where empno=7788;
这是这个事务中最老(远)一条更新的数据,所以其UNDO Chain的指针为rci 0x00,表示这是最后一条记录,也可以从x$bh中找到这些数据块:
sys@TQGZS11G> select b.segment_name,a.file#,a.dbarfil,a.dbablk,a.class,a.state
2 from x$bh a,dba_extents b where b.relative_fno=a.dbarfil
3 and b.block_id <= a.dbablk and b.block_id + b.blocks > a.dbablk
4 and b.owner='SCOTT' and b.segment_name='EMP';
SEGMENT_NAME FILE# DBARFIL DBABLK CLASS STATE
-------------------- ---------- ---------- ---------- ---------- ----------
EMP 4 4 31 1 1
EMP 4 4 28 1 1
EMP 4 4 30 1 1
EMP 4 4 27 4 1
EMP 4 4 32 1 1
EMP 4 4 29 1 1
6 rows selected.
注意class为4的是段头,class为1、块号为31的为数据块。如果此时在其他进程查询scott.emp表,Oracle需要构造一致性读,通过前镜像把变化前的数据展现给用户:
sys@TQGZS11G> select * from scott.emp;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- --------------- --------------- ---------- --------------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-DEC-80 800 20
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30
7521 WARD SALESMAN 7698 22-FEB-81 1250 500 30
7566 JONES MANAGER 7839 02-APR-81 2975 20
7654 MARTIN SALESMAN 7698 28-SEP-81 1250 1400 30
7698 BLAKE MANAGER 7839 01-MAY-81 2850 30
7782 CLARK MANAGER 7839 09-JUN-81 2450 10
7788 SCOTT ANALYST 7566 19-APR-87 3000 20
7839 KING PRESIDENT 17-NOV-81 5000 10
7844 TURNER SALESMAN 7698 08-SEP-81 1500 0 30
7876 ADAMS CLERK 7788 23-MAY-87 1100 20
7900 JAMES CLERK 7698 03-DEC-81 950 30
7902 FORD ANALYST 7566 03-DEC-81 3000 20
7934 MILLER CLERK 7782 23-JAN-82 1300 10
14 rows selected.
再来查询:
sys@TQGZS11G> select b.segment_name,a.file#,a.dbarfil,a.dbablk,a.class,a.state,
2 decode(bitand(flag,1),0,'N','Y') DIRTY
3 from x$bh a,dba_extents b where b.relative_fno=a.dbarfil
4 and b.block_id <= a.dbablk and b.block_id + b.blocks > a.dbablk
5 and b.owner='SCOTT' and b.segment_name='EMP';
SEGMENT_NAME FILE# DBARFIL DBABLK CLASS STATE DIR
-------------------- ---------- ---------- ---------- ---------- ---------- ---
EMP 4 4 31 1 3 N
EMP 4 4 31 1 3 N
EMP 4 4 31 1 1 Y
EMP 4 4 28 1 1 N
EMP 4 4 30 1 1 N
EMP 4 4 27 4 1 N
EMP 4 4 32 1 1 N
EMP 4 4 29 1 1 N
8 rows selected.
注意到此时,Buffer Cache中多出两个数据块,也就是31存在3份,其中STATE为3的就是一致性读构造的前镜像。
6. 转储数据块信息:
在前镜像信息中,Oracle还记录了前镜像对应的数据块地址,用户可以从bdba记录中获得这部分信息,以先前的一个数据为例,bdba: 0x0100001f记录了更改数据块的地址,0x0100001f经过转换为二进制就是:0000 0001 0000 0000 0000 0000 0001 1111,也正是file 4 block 31。
再将数据表中的Block转储出来,看看其中记录了什么样的信息:
sys@TQGZS11G> alter system dump datafile 4 block 31;
System altered.
检查跟踪文件,获取数据块信息:
Start dump data blocks tsn: 4 file#:4 minblk 31 maxblk 31
*** 2009-12-27 02:33:59.457
Block dump from cache:
Dump of buffer cache at level 4 for tsn=4, rdba=16777247
Block dump from disk:
buffer tsn: 4 rdba: 0x0100001f (4/31)
scn: 0x0000.0010982d seq: 0x01 flg: 0x04 tail: 0x982d0601
frmt: 0x02 chkval: 0x68eb type: 0x06=trans data
Hex dump of block: st=0, typ_found=1
Dump of memory from 0x00B34600 to 0x00B36600
B34600 0000A206 0100001F 0010982D 04010000 [........-.......]
B34610 000068EB 00010001 00010F8B 0010982D [.h..........-...]
B34620 1FE80000 00321F02 01000019 00120005 [......2.........]
B34630 00000223 00C05A9A 00410170 00008000 [#....Z..p.A.....]
<中间内容省略……>
B365D0 0204C202 002C1FC1 4AC20308 4D530546 [......,....JF.SM]
B365E0 05485449 52454C43 50C2034B B4770703 [ITH.CLERK..P..w.]
B365F0 0101110C 09C20201 15C102FF 982D0601 [..............-.]
Block header dump: 0x0100001f
Object id on Block? Y
seg/obj: 0x10f8b csc: 0x00.10982d itc: 2 flg: E typ: 1 - DATA
brn: 0 bdba: 0x1000019 ver: 0x01 opc: 0
inc: 0 exflg: 0
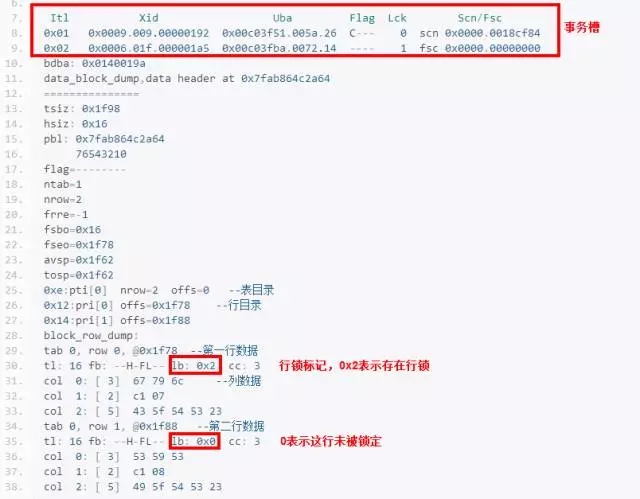
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0005.012.00000223 0x00c05a9a.0170.41 C--- 0 scn 0x0000.0007eab2
0x02 0x0006.000.00000382 0x00c050aa.02d5.19 ---- 3 fsc 0x0002.00000000
bdba: 0x0100001f
data_block_dump,data header at 0xb34664
这里存在ITL事务槽信息,ITL事务槽指Interested Transaction List(ITL),事务必须获得一个ITL事务槽才能够进行数据修改。ITL内容主要包括xid(Transaction ID)、Uba(Undo Block Address)和Lck(Lock Status)。
xid=Undo.Segment.Number+Transaction.Table.Slot.Number+Wrap
在以上输出中,看到Itl2(0x02)上存在活动事务。将xid=0x0006.000.00000382分解一下:该事务指向6号回滚段,Slot号为0x00(转换为十进制正好是0),wrap#为0x0382,正是dump回滚段看到的那个事务。
index state cflags wrap# uel scn dba parent-xid nub stmt_num cmt
------------------------------------------------------------------------------------------------
0x00 10 0x80 0x0382 0x0074 0x0000.0010633d 0x00c050aa 0x0000.000.00000000 0x00000001 0x00000000 0
可以看到,在数据块上同样存在指向回滚段的事务信息。UBA代表的是Undo Block Address,指向具体的回滚段,可以看到该ITL上Uba=0x00c050aa.02d5.19。将这个UBA进行分解,其中0x00c050aa正好是前镜像的地址,seq:02d5是顺序号,19是UNDO记录的开始地址(irb信息)。
UBA的内容和UNDO中的信息完全相符:
UNDO BLK:
xid: 0x0006.000.00000382 seq: 0x2d5 cnt: 0x19 irb: 0x19 icl: 0x0 flg: 0x0000
继续向下可以找到这3条被修改的记录,锁定位信息LB指向0x2号ITL事务槽:
tab 0, row 5, @0x1d11
tl: 40 fb: --H-FL-- lb: 0x2 cc: 8
col 0: [ 3] c2 4d 63
col 1: [ 5] 42 4c 41 4b 45
col 2: [ 7] 4d 41 4e 41 47 45 52
col 3: [ 3] c2 4f 28
col 4: [ 7] 77 b5 05 01 01 01 01
col 5: [ 2] c2 29
col 6: *NULL*
col 7: [ 2] c1 1f
tab 0, row 6, @0x1d39
tl: 40 fb: --H-FL-- lb: 0x2 cc: 8
col 0: [ 3] c2 4e 53
col 1: [ 5] 43 4c 41 52 4b
col 2: [ 7] 4d 41 4e 41 47 45 52
col 3: [ 3] c2 4f 28
col 4: [ 7] 77 b5 06 09 01 01 01
col 5: [ 2] c2 29
col 6: *NULL*
col 7: [ 2] c1 0b
tab 0, row 7, @0x1e4c
tl: 40 fb: --H-FL-- lb: 0x2 cc: 8
col 0: [ 3] c2 4e 59
col 1: [ 5] 53 43 4f 54 54
col 2: [ 7] 41 4e 41 4c 59 53 54
col 3: [ 3] c2 4c 43
col 4: [ 7] 77 bb 04 13 01 01 01
col 5: [ 2] c2 29
col 6: *NULL*
col 7: [ 2] c1 15
至此,整个事务过程被完全解析。最后总结一下这个事务的内部流程。
⑴ 首先当一个事务开始时,需要在回滚段事务表上分配一个事务槽。
⑵ 在数据块头部获取一个ITL事务槽,该事务槽指向回滚段头的事务槽。
⑶ 在修改数据之前,需要记录前镜像信息,这个信息以UNDO RECORD的形式存储在回滚段中,回滚段头事务槽指向该记录。
⑷ 锁定修改行,修改行锁定位(lb-lock byte)指向ITL事务槽。
⑸ 数据修改可以进行。
这就是一个事务的基本流程。
7. 块清除(Block Cleanouts):
当发出提交(commit)之后,Oracle怎样来处理。通过前面的日志可以知道,Oracle需要写出Redo来保证故障时数据可以被恢复;我们也知道Oracle并不需要在提交时就写出变更的数据块。那么在提交时,Oracle需要对数据块进行哪些操作呢?
回忆一下上文,可以知道,在事务需要修改数据时,必须分配ITL事务槽,必须锁定行,必须分配回滚段事务槽和回滚空间记录前镜像。当事务提交时,Oracle需要将回滚段上的事务表信息标记为非活动,以便空间可以重用;那么还有ITL事务信息和锁定信息需要清除,以记录提交。
由于Oracle在数据块上存储了ITL和锁定等事务信息,所以Oracle必须在事务提交之后清除这些事务数据。这就是块清除。块清除主要要清除的数据有行级锁和ITL信息(包括提交标志、SCN等)。
如果提交时修改过的数据块仍然在Buffer Cache之中,那么Oracle可以清除ITL信息,这叫作快速块清除(Fast Block Cleanout),快速块清除还有一个限制,当修改的块数量超过Buffer Cache约10%,则对超出部分不再进行快速块清除。
如果提交事务的时候,修改过的数据块已经被写回到数据文件上(或大量修改超出Buffer Cache 10%的部分),再次读出该数据块进行修改,显然成本过于高昂,对于这种情况,Oracle选择延迟块清除(Delayed Block Cleanout),等到下一次访问该Block时再来清除ITL锁定信息,这就是延迟块清除。Oracle通过延迟块清除来提高数据库性能,加快提交操作。
快速提交是最普遍的情况,来看一下延迟块清除的处理。继续前面的测试:
scott@TQGZS11G> update emp set sal=4000 where empno=7788;
1 row updated.
scott@TQGZS11G> update emp set sal=4000 where empno=7782;
1 row updated.
scott@TQGZS11G> update emp set sal=4000 where empno=7698;
1 row updated.
更新完成之后,强制刷新Buffer Cache,将Buffer Cache中的数据都写出到数据文件:
sys@TQGZS11G> alter session set events = 'immediate trace name flush_cache';
Session altered.
此时再提交事务:
scott@TQGZS11G> commit;
Commit complete.
由于此时更新过的数据已经写出到数据文件,Oracle将执行延迟块清除,将此时的数据块和回滚段转储出来:
sys@TQGZS11G> alter system dump datafile 4 block 31; --数据块
System altered.
sys@TQGZS11G> alter system dump undo header '_SYSSMU6_1186132793$'; --回滚段头
System altered.
sys@TQGZS11G> alter system dump datafile 3 block 20650; --回滚段块
System altered.
研究一下,查看数据块上的信息,ITL事务信息仍然存在:
Start dump data blocks tsn: 4 file#:4 minblk 31 maxblk 31
*** 2009-12-27 03:18:33.727
Block dump from cache:
Dump of buffer cache at level 4 for tsn=4, rdba=16777247
Block dump from disk:
buffer tsn: 4 rdba: 0x0100001f (4/31)
scn: 0x0000.0010982d seq: 0x01 flg: 0x04 tail: 0x982d0601
frmt: 0x02 chkval: 0x68eb type: 0x06=trans data
Hex dump of block: st=0, typ_found=1
Dump of memory from 0x00B34600 to 0x00B36600
B34600 0000A206 0100001F 0010982D 04010000 [........-.......]
B34610 000068EB 00010001 00010F8B 0010982D [.h..........-...]
B34620 1FE80000 00321F02 01000019 00120005 [......2.........]
<中间部分省略……>
B365D0 0204C202 002C1FC1 4AC20308 4D530546 [......,....JF.SM]
B365E0 05485449 52454C43 50C2034B B4770703 [ITH.CLERK..P..w.]
B365F0 0101110C 09C20201 15C102FF 982D0601 [..............-.]
Block header dump: 0x0100001f
Object id on Block? Y
seg/obj: 0x10f8b csc: 0x00.10982d itc: 2 flg: E typ: 1 - DATA
brn: 0 bdba: 0x1000019 ver: 0x01 opc: 0
inc: 0 exflg: 0
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0005.012.00000223 0x00c05a9a.0170.41 C--- 0 scn 0x0000.0007eab2
0x02 0x0006.000.00000382 0x00c050aa.02d5.19 ---- 3 fsc 0x0002.00000000
bdba: 0x0100001f
data_block_dump,data header at 0xb34664
数据块的锁定信息仍然存在:
tab 0, row 5, @0x1d11
tl: 40 fb: --H-FL-- lb: 0x2 cc: 8
col 0: [ 3] c2 4d 63
col 1: [ 5] 42 4c 41 4b 45
col 2: [ 7] 4d 41 4e 41 47 45 52
col 3: [ 3] c2 4f 28
col 4: [ 7] 77 b5 05 01 01 01 01
col 5: [ 2] c2 29
col 6: *NULL*
col 7: [ 2] c1 1f
tab 0, row 6, @0x1d39
tl: 40 fb: --H-FL-- lb: 0x2 cc: 8
col 0: [ 3] c2 4e 53
col 1: [ 5] 43 4c 41 52 4b
col 2: [ 7] 4d 41 4e 41 47 45 52
col 3: [ 3] c2 4f 28
col 4: [ 7] 77 b5 06 09 01 01 01
col 5: [ 2] c2 29
col 6: *NULL*
col 7: [ 2] c1 0b
tab 0, row 7, @0x1e4c
tl: 40 fb: --H-FL-- lb: 0x2 cc: 8
col 0: [ 3] c2 4e 59
col 1: [ 5] 53 43 4f 54 54
col 2: [ 7] 41 4e 41 4c 59 53 54
col 3: [ 3] c2 4c 43
col 4: [ 7] 77 bb 04 13 01 01 01
col 5: [ 2] c2 29
col 6: *NULL*
col 7: [ 2] c1 15
再来看回滚段的信息:
index state cflags wrap# uel scn dba parent-xid nub stmt_num cmt
------------------------------------------------------------------------------------------------
0x00 9 0x00 0x0382 0x0010 0x0000.0010b963 0x00c050aa 0x0000.000.00000000 0x00000001 0x00000000 1261854823
事务提交,事务表已经释放。如果此时查询SCOTT.EMP表,数据库将产生延迟块清除:
sys@TQGZS11G> set autotrace on
sys@TQGZS11G> select * from scott.emp;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- --------------- --------------- ---------- --------------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-DEC-80 800 20
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30
7521 WARD SALESMAN 7698 22-FEB-81 1250 500 30
7566 JONES MANAGER 7839 02-APR-81 2975 20
7654 MARTIN SALESMAN 7698 28-SEP-81 1250 1400 30
7698 BLAKE MANAGER 7839 01-MAY-81 4000 30
7782 CLARK MANAGER 7839 09-JUN-81 4000 10
7788 SCOTT ANALYST 7566 19-APR-87 4000 20
7839 KING PRESIDENT 17-NOV-81 5000 10
7844 TURNER SALESMAN 7698 08-SEP-81 1500 0 30
7876 ADAMS CLERK 7788 23-MAY-87 1100 20
7900 JAMES CLERK 7698 03-DEC-81 950 30
7902 FORD ANALYST 7566 03-DEC-81 3000 20
7934 MILLER CLERK 7782 23-JAN-82 1300 10
14 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 518 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| EMP | 14 | 518 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
9 consistent gets
6 physical reads
116 redo size
1420 bytes sent via SQL*Net to client
420 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
14 rows processed
注意到查询在此时产生了物理读和Redo,这个Redo就是因为延迟块清除导致的。再次查询,则不会继续生成Redo了:
sys@TQGZS11G> /
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- --------------- --------------- ---------- --------------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-DEC-80 800 20
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30
……
14 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 518 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| EMP | 14 | 518 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
8 consistent gets
0 physical reads
0 redo size
1420 bytes sent via SQL*Net to client
420 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
14 rows processed
再次转储一下该Block来看看此时数据库块上的信息:
sys@TQGZS11G> alter system dump datafile 4 block 31; --数据块
System altered.
看到此时ITL事务信息已经清除,但是注意,这里的Xid和Uba信息仍然存在:
Start dump data blocks tsn: 4 file#:4 minblk 31 maxblk 31
Block dump from cache:
Dump of buffer cache at level 4 for tsn=4, rdba=16777247
BH (0x25bf891c) file#: 4 rdba: 0x0100001f (4/31) class: 1 ba: 0x25b2a000
set: 3 bsz: 8192 bsi: 0 sflg: 0 pwc: 0, 25 lid: 0x00000000,0x00000000
dbwrid: 0 obj: 69515 objn: 69515 tsn: 4 afn: 4
hash: [0x323a7804,0x323a7804] lru: [0x257f64ec,0x253f60dc]
ckptq: [NULL] fileq: [NULL] objq: [0x253f613c,0x303c4140]
st: XCURRENT md: NULL tch: 2
flags: only_sequential_access block_written_once redo_since_read
LRBA: [0x0.0.0] LSCN: [0x0.0] HSCN: [0xffff.ffffffff] HSUB: [1]
cr pin refcnt: 0 sh pin refcnt: 0
buffer tsn: 4 rdba: 0x0100001f (4/31)
scn: 0x0000.0010bca8 seq: 0x01 flg: 0x04 tail: 0xbca80601
frmt: 0x02 chkval: 0x771a type: 0x06=trans data
Hex dump of block: st=0, typ_found=1
Dump of memory from 0x25B2A000 to 0x25B2C000
25B2A000 0000A206 0100001F 0010BCA8 04010000 [................]
25B2A010 0000771A 00010001 00010F8B 0010BCA8 [.w..............]
25B2A020 1FE80000 00321F02 01000019 00120005 [......2.........]
<中间部分省略……>
25B2BFD0 0204C202 002C1FC1 4AC20308 4D530546 [......,....JF.SM]
25B2BFE0 05485449 52454C43 50C2034B B4770703 [ITH.CLERK..P..w.]
25B2BFF0 0101110C 09C20201 15C102FF BCA80601 [................]
Block header dump: 0x0100001f
Object id on Block? Y
seg/obj: 0x10f8b csc: 0x00.10bca8 itc: 2 flg: E typ: 1 - DATA
brn: 0 bdba: 0x1000019 ver: 0x01 opc: 0
inc: 0 exflg: 0
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0005.012.00000223 0x00c05a9a.0170.41 C--- 0 scn 0x0000.0007eab2
0x02 0x0006.000.00000382 0x00c050aa.02d5.19 C--- 0 scn 0x0000.0010b963
bdba: 0x0100001f
data_block_dump,data header at 0x25b2a064
数据行的锁定位也已经清除:
sys@TQGZS11G> alter system dump undo header '_SYSSMU6_1186132793$'; --回滚段头
System altered.
tab 0, row 5, @0x1d11
tl: 40 fb: --H-FL-- lb: 0x0 cc: 8
col 0: [ 3] c2 4d 63
col 1: [ 5] 42 4c 41 4b 45
col 2: [ 7] 4d 41 4e 41 47 45 52
col 3: [ 3] c2 4f 28
col 4: [ 7] 77 b5 05 01 01 01 01
col 5: [ 2] c2 29
col 6: *NULL*
col 7: [ 2] c1 1f
tab 0, row 6, @0x1d39
tl: 40 fb: --H-FL-- lb: 0x0 cc: 8
col 0: [ 3] c2 4e 53
col 1: [ 5] 43 4c 41 52 4b
col 2: [ 7] 4d 41 4e 41 47 45 52
col 3: [ 3] c2 4f 28
col 4: [ 7] 77 b5 06 09 01 01 01
col 5: [ 2] c2 29
col 6: *NULL*
col 7: [ 2] c1 0b
tab 0, row 7, @0x1e4c
tl: 40 fb: --H-FL-- lb: 0x0 cc: 8
col 0: [ 3] c2 4e 59
col 1: [ 5] 53 43 4f 54 54
col 2: [ 7] 41 4e 41 4c 59 53 54
col 3: [ 3] c2 4c 43
col 4: [ 7] 77 bb 04 13 01 01 01
col 5: [ 2] c2 29
col 6: *NULL*
col 7: [ 2] c1 15
8. 提交之后的UNDO信息:
当提交事务之后,回滚段事务表标记事务为非活动,继续再来看一下回滚段数据块的信息。可以看到这里irb指向了0x3a,此前的事务已经不可回滚。
Start dump data blocks tsn: 2 file#:3 minblk 20650 maxblk 20650
Block dump from cache:
Dump of buffer cache at level 4 for tsn=2, rdba=12603562
BH (0x247e5adc) file#: 3 rdba: 0x00c050aa (3/20650) class: 28 ba: 0x24442000
set: 3 bsz: 8192 bsi: 0 sflg: 0 pwc: 0, 25 lid: 0x00000000,0x00000000
dbwrid: 0 obj: -1 objn: 0 tsn: 2 afn: 3
hash: [0x323ad5b4,0x323ad5b4] lru: [0x257e7aec,0x24bf30ec]
lru-flags: on_auxiliary_list
ckptq: [NULL] fileq: [NULL] objq: [NULL]
st: FREE md: NULL tch: 0 lfb: 33
flags:
cr pin refcnt: 0 sh pin refcnt: 0
Buffer contents not dumped
Block dump from disk:
buffer tsn: 2 rdba: 0x00c050aa (3/20650)
scn: 0x0000.0010bb59 seq: 0x03 flg: 0x04 tail: 0xbb590203
frmt: 0x02 chkval: 0xc30c type: 0x02=KTU UNDO BLOCK
Hex dump of block: st=0, typ_found=1
Dump of memory from 0x00BEA600 to 0x00BEC600
BEA600 0000A202 00C050AA 0010BB59 04030000 [.....P..Y.......]
BEA610 0000C30C 00010006 00000382 3A3A02D5 [..............::]
BEA620 1FE80000 1EE81F74 1DDC1E74 1CF01D78 [....t...t...x...]
<中间部分省略……>
********************************************************************************
UNDO BLK:
xid: 0x0006.001.00000382 seq: 0x2d5 cnt: 0x3a irb: 0x3a icl: 0x0 flg: 0x0000
偏移量列表也已经新增到信息0x3a 0x0198:
Rec Offset Rec Offset Rec Offset Rec Offset Rec Offset
---------------------------------------------------------------------------
0x01 0x1f74 0x02 0x1ee8 0x03 0x1e74 0x04 0x1ddc 0x05 0x1d78
0x06 0x1cf0 0x07 0x1bcc 0x08 0x1b64 0x09 0x1b0c 0x0a 0x1ab8
0x0b 0x1a5c 0x0c 0x19e8 0x0d 0x198c 0x0e 0x1938 0x0f 0x189c
0x10 0x1814 0x11 0x1788 0x12 0x1720 0x13 0x1690 0x14 0x1608
0x15 0x157c 0x16 0x1514 0x17 0x1490 0x18 0x1434 0x19 0x13d8
0x1a 0x1350 0x1b 0x12f4 0x1c 0x126c 0x1d 0x11f0 0x1e 0x1188
0x1f 0x1100 0x20 0x1084 0x21 0x101c 0x22 0x0f34 0x23 0x0ecc
0x24 0x0e74 0x25 0x0de4 0x26 0x0d90 0x27 0x0cf4 0x28 0x0c48
0x29 0x0b9c 0x2a 0x0af0 0x2b 0x0a44 0x2c 0x0998 0x2d 0x08ec
0x2e 0x0840 0x2f 0x0790 0x30 0x06e0 0x31 0x0630 0x32 0x05c4
0x33 0x0558 0x34 0x04a8 0x35 0x043c 0x36 0x03d0 0x37 0x0340
0x38 0x0258 0x39 0x01f0 0x3a 0x0198
至于前镜像0x17、0x18、0x19的信息,仍然存在:
*-----------------------------
* Rec #0x17 slt: 0x00 objn: 69515(0x00010f8b) objd: 69515 tblspc: 4(0x00000004)
* Layer: 11 (Row) opc: 1 rci 0x00
Undo type: Regular undo Begin trans Last buffer split: No
Temp Object: No
Tablespace Undo: No
rdba: 0x00000000Ext idx: 0
flg2: 0
*-----------------------------
uba: 0x00c050aa.02d5.14 ctl max scn: 0x0000.00106005 prv tx scn: 0x0000.0010603b
txn start scn: scn: 0x0000.00000000 logon user: 81
prev brb: 12603560 prev bcl: 0
KDO undo record:
KTB Redo
op: 0x03 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: Z
KDO Op code: URP row dependencies Disabled
xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x0100001f hdba: 0x0100001b
itli: 2 ispac: 0 maxfr: 4858
tabn: 0 slot: 7(0x7) flag: 0x2c lock: 0 ckix: 0
ncol: 8 nnew: 1 size: 0
Vector content:
col 5: [ 2] c2 1f
*-----------------------------
* Rec #0x18 slt: 0x00 objn: 69515(0x00010f8b) objd: 69515 tblspc: 4(0x00000004)
* Layer: 11 (Row) opc: 1 rci 0x17
Undo type: Regular undo Last buffer split: No
Temp Object: No
Tablespace Undo: No
rdba: 0x00000000
*-----------------------------
KDO undo record:
KTB Redo
op: 0x02 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: C uba: 0x00c050aa.02d5.17
KDO Op code: URP row dependencies Disabled
xtype: XA flags: 0x00000000 bdba: 0x0100001f hdba: 0x0100001b
itli: 2 ispac: 0 maxfr: 4858
tabn: 0 slot: 6(0x6) flag: 0x2c lock: 0 ckix: 0
ncol: 8 nnew: 1 size: 1
col 5: [ 3] c2 19 33
*-----------------------------
* Rec #0x19 slt: 0x00 objn: 69515(0x00010f8b) objd: 69515 tblspc: 4(0x00000004)
* Layer: 11 (Row) opc: 1 rci 0x18
Undo type: Regular undo Last buffer split: No
Temp Object: No
Tablespace Undo: No
rdba: 0x00000000
*-----------------------------
KDO undo record:
KTB Redo
op: 0x02 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: C uba: 0x00c050aa.02d5.18
KDO Op code: URP row dependencies Disabled
xtype: XA flags: 0x00000000 bdba: 0x0100001f hdba: 0x0100001b
itli: 2 ispac: 0 maxfr: 4858
tabn: 0 slot: 5(0x5) flag: 0x2c lock: 0 ckix: 0
ncol: 8 nnew: 1 size: 1
col 5: [ 3] c2 1d 33
可以猜想,虽然这个事务已经提交,不可以回滚了,但是在覆盖之前,这个前镜像信息仍然存在,通过某种手段,我们应该仍然可以获得这个信息。这个猜想显然是成立的。
DBAplus社群 | 2016-02-24 06:47
不论你的工作是管理Oracle数据库,还是开发、维护Oracle上的应用程序,通常来讲你都遇到过ORA-01555:snapshot too old这样的错误。本文为你详解错误产生的原因以及最佳解决方案。
ORA-01555产生的过程
我们先来看看ORA-01555是怎样产生的:

错误记录在哪?
通常,这个错误可能会在以下文件中出现:
1Alert 告警日志文件
报错信息类似:
ORA-01555: snapshot too old: rollback segment number 107 with name "_SYSSMU107_1253191395$" too small
2问题发生时的跟踪日志文件
默认情况,ORA-01555错误发生时不会自动生成跟踪日志文件。但是可以在系统里设置下面的事件,让它在错误发生时同时生成:
alter system set events '1555 trace name errorstack level 3';
设置了1555事件后,一旦错误发生,就会生成相应的日志文件,类似如下:

错误因何而来?
产生ORA-01555错误的根本原因是由于UNDO块被覆盖,查询语句不能获取到查询语句发起时刻所构造的数据副本。
已知的一些原因如下:
1相应行数据的UNDO记录已经过期了
这里说的过期是当前时间(指错误发生时)离数据提交时间已经超过UNDO_RETENTION设定的值。一旦已提交的记录对应的UNDO记录是“expired”状态,就表明这部分空间可以重用,数据可以被覆盖了。
你可能会问,为什么有时候我们遇到ORA-01555错误时,查询语句运行时间比UNDO_RETENTION要长很多,有时候却短很多呢?这没什么明确的答案。
要看具体问题发生时UNDO表空间有多忙,系统负载有多大。
提示:一个活动或者未提交的事务对应的UNDO记录会被标记为“ACTIVE”状态。一旦事务被提交,相应的UNDO记录被标记为“UNEXPIRED”,它将持续一段时间(这段时间由UNDO_RETENTION参数决定,如果使用了自动还原段管理,那是由TUNED_UNDORETENTION决定,该参数的值系统自动评估),过了这一时间后,这一UNDO记录被标记为“EXPIRED”,该空间可被重用。
2相应行数据的UNDO记录状态并非过期,但仍然被覆盖了
发生这种情况有2个必要条件:
对UNDO表空间没有设置RETENTION GUARANTEE
UNDO表空间满了
这个时候,“UNEXPIRED”状态的UNDO记录就可能被覆盖了。
3LOB段的LOB段的读一致性副本不再可用
依赖于LOB字段是怎样配置的,in-row还是out-of-row,in-row方式的LOB字段在UNDO表空间中采用跟普通行一样的UNDO算法。
Out-of-row方式的LOB字段不一样,它的读一致性副本有下面2种控制方式:
1)老的方式:PCTVERSIOIN
这个参数关系到LOB数据的一致读,指的是表lob字段所在的表空间需要预留给lob的前映象使用的最大百分比,默认值是10。也就是说,只要使用不超过10%,LOB字段的前映像的数据是不会被覆盖的。
2) 新的方式(自动还原段管理使用):RETENTION
Oracle用UNDO_RETENTION参数来决定在数据库中保留多少已经提交的UNDO数据。这种方式LOB段跟普通段使用相同的过期策略。
在这种方式中,用LOB字段的语句发生ORA-1555的话,意味着:
LOB字段的前映像的使用已经超过PCTVERSION,读一致性数据被覆盖。
或者,LOB字段前映像超过了RETENTION的值,在查询发生时一些行的LOB字段前映像已经被覆盖,于是ORA-1555触发。
解决方案
1检查错误日志信息
通过检查告警日志,或者包含ORA-1555错误信息的跟踪日志,可以更详细的看到具体的错误类型:
1)提示回滚段太小
错误提示:
ORA-01555: snapshot too old: rollback segment number with name "" too small(注意!!!这里的回滚段名字是空的)
或者,
ORA-22924: snapshot too old
这种错误说明是访问的UNDO数据是LOB字段类型。LOB字段访问遇到ORA-1555错误通常是下面几个原因导致的:
LOB段损坏
参考MOS文档检查是不是这个问题:
Document 452341.1 ORA-01555 And Other Errors while Exporting Table With LOBs, How To Detect Lob Corruption
如果没有LOB损坏,检查Retention/Pctversion值是不是合适
参考MOS文档,确认是不是需要调高Retention/Pctversion:
Document 846079.1 LOBs and ORA-01555 troubleshooting
ORA-01555: snapshot too old: rollback segment number 107 with name "_SYSSMU107_1253191395$" too small
注意,这个错误提示跟上面不一样。"_SYSSMU107_1253191395$"表示UNDO数据是在UNDO表空间的。
这个ORA-1555错误报告是在访问UNDO表空间的UNDO数据时发生错误的,用后续的方法来诊断问题。
2)查询耗时太长
在一些ORA-1555错误发生时,会在alert日志或者是应用日志中出现查询失败时耗时(Duration)的秒数:
ORA-01555 caused by SQL statement below (Query Duration=1974 sec, SCN: 0x0002.bc30bcf7):
如果发现错误日志中,duration=0或者耗时很短,查看下面的文档:
Document 1131474.1 ORA-01555 When Max Query Length Is Less Than Undo Retention, small or 0 Seconds
如果查询耗时超过UNDO_RETENTION值,可以考虑加大UNDO_RETETION,同时要记得调整UNDO表空间大小。
如果查询耗时等于或者接近UNDO_RETENTION,继续看后面的文字。
2检查UNDO数据文件

如果UNDO数据文件没有关闭自动扩展功能,可能会导致TUNED_UNDORETENTION值被计算得很高,因此UNDO空间分配是偏向于更多的空间。那怎么破呢?使用UNDO数据文件自动扩展功能,即使存储可用空间足够的时候也带上MAXSIZE。
注意:强烈建议,不要让UNDO表空间里同时存在关闭自动扩展功能的UNDO数据文件和打开自动扩展功能的UNDO数据文件,因为这会导致TUNED_UNDORETENTION计算错乱。
3检查 TUNED_UNDORETENTION

1)TUNED_UNDORETENTION比MAXQUERYLEN小
这种情况表明UNDO表空间有空间上的压力,实际保留的UNDO记录比理论上的要少。
解决办法是扩大UNDO表空间。
2)TUNED_UNDORETENTION比MAXQUERYLEN大很多
通常发生在UNDO表空间的数据文件关闭自动扩展选项的情况下。内部的算法是尽可能久的保持UNDO记录,因此TUNED_RETENTION的值就会比较高。
解决办法是把所有的UNDO数据文件设置为自动扩展,并且加上MAXSIZE选项。
长时间运行的查询语句也会把TUNED_RETENTION的值搞得很高。这种情况。就要优化SQL语句来避免保留过多UNDO数据在UNDO表空间了。
通过下面的语句来识别哪些查询语句耗时较久:

3)状态为ACTIVE/UNEXPIRED的UNDO占比很高

下面的几种情况可能会产生大量ACTIVE/UNEXPIRED状态的UNDO:
UNDO_RETENTION或TUNED_UNDORETENTION值很大
在某个特定时间点产生了大量UNDO数据。用下面的语句诊断:

大量的死事务回滚
使用了闪回数据查询
关于状态为ACTIVE的UNDO的信息,可以参阅:
Document 1337335.1 How To Check the Usage of Active Undo Segments in AUM
4UNDO_RETENTION
建议将UNDO_RETENTION的值至少设置为MAXQUERYLEN的一半。如果发生了ORA-1555错误,则适当调大。
到此,基本上涉及ORA-01555错误的原理和诊断就说完了。
ORA-01555 原因与解决:
前面提到了ORA-01555错误,那么现在来看一下ORA-01555错误是怎样产生的。由于回滚段是循环使用的,当事务提交以后,该事务占用的回滚段事务会被标记为非活动,回滚段空间可以被覆盖重用。那么一个问题就出现了,如果一个查询需要使用被覆盖的回滚段构造前镜像实现一致性读,那么此时就会出现Oracle著名的ORA-01555错误。
ORA-01555错误的另外一个原因是因为延迟块清除(Delayed Block Cleanout)。当一个查询触发延迟块清除时,Oracle需要去查询回滚段获得该事务的提交SCN,如果事务的前镜像信息已经被覆盖,并且查询SCN也小于回滚段中记录的最小提交SCN,那么Oracle将无从判断查询SCN和事务提交SCN的大小,此时出现延迟块清除导致的ORA-01555错误。
另外一种导致ORA-01555错误的情况出现在使用sqlldr直接方式加载(direct=true)数据时。当通过sqlldr direct=true 方式加载数据时,由于不产生重做和回滚信息,Oracle直接指定Cached Commit SCN 给加载数据,在访问这些数据时,有时会产生ORA-01555错误。
看下图的描述:假定在时间T用户A发出一条更新语句,更新SCOTT用户的SAL;用户B在Ty时间发出查询语句,查询SCOTT用户的SAL;用户A的更新在Tx时间提交,提交可能为快速提交块清除,也可能是延迟块清除;用户B的查询在Tz时间输出。

来看一下数据库在不同情况下的内部处理:
·如果 Ty < T < Tz < Tx ,那么查询需要构造一致性读,由于事务尚未提交,可以通过回滚段构造前镜像,完成一致性读取。
·如果 Ty < T < Tx < Tz ,由于Ty查询时间小于T事务更新时间,那么数据库需要构造一致性读取,而Tz查询完成时间大于Tx提交时间,那么前镜像就有可能被覆盖,不可获取。
如果Tx的提交方式为Fast Block Cleanout,那么回滚段信息不可用时就会出现一致性读ORA-01555错误。
如果Tx的提交方式为Delayed Block Cleanout,那么回滚段信息不可用时Oracle将无法判断Ty和Tx的时间先后关系。如果 Ty > Tx ,那么Oracle可以正常进行块清除,并将块清除后的数据返回给用户B;如果 Ty < T ,那么Oracle需要继续构造一致性读返回给用户B;Oracle无法判断这两种情况,就会出现延迟块清除ORA-01555错误。
ORA-01555的直观解释是“snapshot too old”,也就是快照太旧,其根本含义就是查询需要的前镜像过于“久远”,已经无法找到了。可以想象,如果一个历时数个小时或十几个小时的查询,如果最后遭遇ORA-01555错误而失败,会是多么令人沮丧的一件事。一直以来,ORA-01555都是ORACLE最为头痛的问题之一。
在Oracle 9i的文档中这样描述ORA-01555错误:
01555, 00000, "snapshot too old: rollback segment number %s with name \"%s\" too small"
// *Cause: rollback records needed by a reader for consistent read are
// overwritten by other writers
// *Action: If in Automatic Undo Management mode, increase undo_retention
// setting. Otherwise, use larger rollback segments
可以看到,在Oracle 9i自动管理UNDO表空间模式下,UNDO_RETENTION参数的引入正是为了减少ORA-01555错误的出现。这个参数设置当事务提交之后(回滚段变得非活跃),回滚段中的前镜像数据在被覆盖前保留的时间,该参数以秒为单位,9iR1初始值为900秒,在Oracle 9iR2增加为10800秒。
显然该参数设置的越高就越能减少ORA-01555错误的出现,但是保留时间和存储空间是紧密相关的,如果UNDO表空间的存储空间有限,那么Oracle就会选择回收已提交事务占用的空间,置UNDO_RETENTION参数于不顾。
在Oracle 9i的AUM模式下,UNDO_RETENTION实际上是一个非担保(NO Guaranteed)限制。也就是说,如果有其他事务需要回滚空间,而空间出现不足时,这些信息仍然会被覆盖;从Oracle 10g开始,Oracle对于UNDO增加了Guarantee控制,也就是说,可以指定UNDO表空间必须满足UNDO_RETENTION的限制。当UNDO表空间设置为Guarantee,那么提交事务的回滚空间必须被保留足够的时间,如果UNDO表空间的空间不足,那么新的事务会因空间不足而失败,而不是选择之前的覆盖。
从各个不同版本回滚段的管理变迁,我们可以看出Oracle一直在进步。
Oracle提供了一个内部事件(10203事件)可以用来跟踪数据库的块清除操作,10203事件可以通过以下命令设置,设置后需要重新启动数据库该参数方能生效:
alter system set event="10203 trace name context forever" scope=spfile;
需要注意的是,可能存在另外一种情况,就是当执行延迟块清除时,回滚段或原回滚表空间已经被删除,此时Oracle仍然可以通过字典表UNDO$来获得SCN信息,执行块清除。
关于Oracle的提交处理及块清除机制是一个极其复杂的过程,本文对这部分内容进行了适当简化说明,旨在使大家能够对Oracle的回滚机制、块清除机制有所了解。
- The End -
假事务之名,深入研究UNDO与REDO
郭耀龙 2015-11-20 09:39:50 446
“有道无术,术尚可求;有术无道,止于术”。今天让我们一起来看看DBA+社群联合发起人郭耀龙大师如何布道。
专家简介

郭耀龙
DBA+社群联合发起人
超过5年Oracle数据库经验,服务于大型制造业、银行、政府、电信、电力等行业,曾主导某大型制造业的16核心系统从10g向11g平稳演进,擅长Oracle数据库架构规划、性能调整、故障诊断、SQL优化,熟悉Oracle RAC及MAA架构,对大型IT系统的Oracle数据库运维有较丰富的经验。

本文主要讲述关于undo、redo的一些内容。由于undo、redo内容非常多,短时间内难以讲诉清楚,故若水三千,我们只取一瓢,我将从Oracle事务切入,分析undo、redo在事务中的作用。
分享一句出自《道德经》里的话,我做了一个曲解,即:“道”理解为原理;“术”理解为实践、操作,就是说如果我们懂得了事物的原理,那么实践性的东西我们是可以培养和训练的,但是如果我们只懂得表面的操作,而不懂原理,那我们就只能停留在事物的表层,如果遇到新的情况,就难以应对。我认为做DBA也是一样,要能够理解Oracle的原理,才能处理一些深层次的问题,而不是在google无结果后就缴械投降。本篇文章的主要内容就是布道。
目录
1、Undo在事务中的作用
-
解析undo段头结构
-
解析undo块、undo chain结构
2、Redo在事务中的作用
最近连续遇到3个由于ORA-600错误导致数据库无法启动的情况,其中两个都是由于异常关机后导致无法启动,这种错误大部分情况是与redo、undo相关,但是怎样来定位问题,怎样解决?这就需要了解Oracle redo、undo的原理,定位问题的方向一般都是解读alert日志、trace日志、或者在mount阶段使用一些跟踪事件,比如10013、10015、10046等进行辅助分析。
当然还有最主要的一招,查MOS,MOS上有专门针对600错误的搜索入口,在这里根据错误代码的第一个参数进行匹配查找:
但如果这里匹配不上,或者MOS上给出的解决办法无效,就还是得回到使用trace日志等分析定位问题,但是这里的trace的解读可能会是拦路虎,怎样去解读trace不是今晚的主题,不做深入,当然不同的trace解读的方法也不尽相同,但是我自己有个体验,就是对Oracle的一些原理和数据结构理解越透彻,就越能读懂trace文件,我们只需要读懂其中的一些关键点,其余可以进行猜测,就足以解决问题,就像英语的阅读理解,只需要读懂1/3的内容,就能解答2/3的问题。这里扯的有点远了,我们回到今晚主题,希望通过今晚的分享能够让大家对undo、redo在Oracle事务中的作用有一定了解,并通过对undo、redo的部分结构的解析,让大家深入Oracle内部,在后续处理相关问题时能够有所帮助。
首先,先说下我对事务的理解。Oracle数据库根本上是一个程序,跟其他的应用系统程序无差别,应用系统的程序如果没有业务,那程序代码就无意义,Oracle如果没有事务运行,那Oracle代码也就无意义,所以,事务对于Oracle就像业务对于应用系统一样,是Oracle的灵魂,从这个意义上看,Oracle实例可以看做是用一段代码在维护很多事务运行,事务是oracle实例运行的核心任务,事务产生的数据就是db(控制文件、system文件等可看作内部事务产生)。个人理解,仅供参考。
下面描述一下oracle事务的一个简单过程:
1、在事务开始前,会申请redo资源、undo资源; redo的申请主要是要获取记录redo的内存资源,会涉及到redo allocation latch等资源的申请, undo资源申请是要获取到一个undo段用来存储undo数据(IMU机制会稍有不同);
2、在undo段头的事务表中申请一个槽位,记录事务信息,这些相关信息也会以xid等形式写入到数据块的事务槽中;
3、undo段头的事务表指向可用的undo块,undo块用于存储具体的undo信息;
4、事务开始,进行增、删、改、查等操作,redo记录相关信息、undo也记录相关信息,在事务涉及到的行头还会设置行锁标记;
5、事务提交或回滚,结束事务。修改undo段头事务表信息,尽可能的修改相关数据块的事务槽信息、行锁信息,将相关事务信息写入redo log文件。
上面只是粗略的一个描述,其中涉及到很多概念,比如undo段头、unod块、事务槽、行锁标记、redo记录等,这些东西具体长什么样?是怎样工作的呢?这里让我想起了一句话:爱情就像鬼一样,谁都听过,但谁也没见过。下面我们就通过实验来解析上面提到的这些概念,看一看是否真的有爱情。
1 Undo在事务中的作用
1.1 解析undo段头结构
上面的实验修改了表中的两条记录,且这两条记录是存放在不同的块中先dump被修改的两个数据块进行观察
另外一个数据块
前面提到的事务槽和行锁标记都出现了,我们看到爱情了!!!
事务槽中涉及到几个重要的结构,下面进行下解释:
xid=Undo.Segment.Number+Transaction.Table.Slot.Number+Wrap
uba = Address of the last undo block used + Sequence + Last Entry in UNDO record map
这两个重要结构简单的理解就是,xid指向了事务使用的undo段号、事务表中的槽位号、以及槽位被覆盖的次数;uba指向事务使用的最后一个undo块、seq值、以及最后一条undo记录。
事务槽中还有一个flag段,这个段有不同的取值,代表事务的不同状态,可以通过修改这个标志实现手工提交事务,常见的取值有以下几种:
---- 事务是活动的,或者在块清除前提交事务
C--- 事务已经提交并且清除了行锁定
--U- 快速提交
再回到前面的两个块的dump数据可以发现,两个数据块的事务槽中都有一个未提交的事务,都是使用了第二个事务槽,两个块的xid完全相同,即两个块使用的是同一个undo段中的同一个事务表槽位,uba的前两部分也完全相同,即使用的是同一个undo块,第三部分不一样,说明两个块的前镜像使用了两个条undo record进行记录。
从xid信息可以知道,事务使用的是第6号回滚段,下面dump 6号undo段头进行观察:
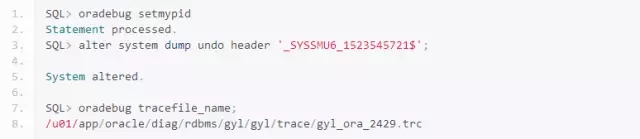
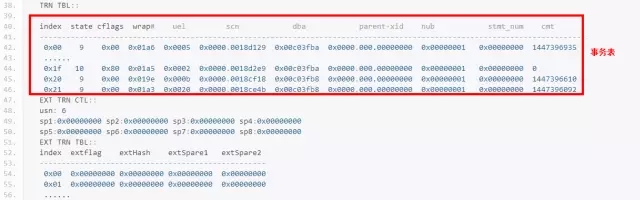
上图就是undo段头中的事务表,又看到爱情了!!!
下面对其中的几个重要列进行解释:
index:表示slot 编号
state:表示状态,9 表示事务inactive,10表示active.
Uel:跟提交列表有关
Dba:表示该事务对应的undo block dba地址
1.2 解析undo块、undo chain结构
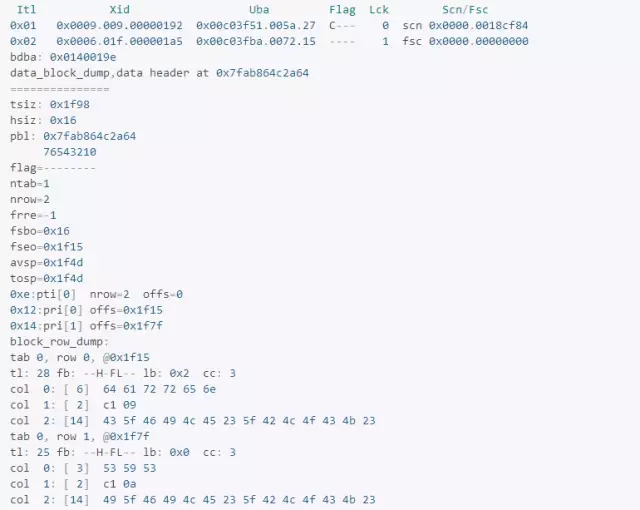
根据前面两个块的xid(0x0006.01f.000001a5)可知,事务使用的是1f号槽位,从前面事务表的图中可以看出,该槽位的state列为10,即事务未提交,其对应的undo block的地址为c03fba。
将该dba地址进行转换:

使用的undo块是3号文件的16314号块,下面dump该块进行观察:
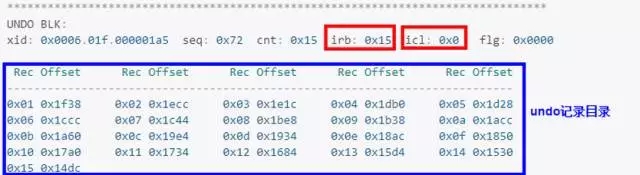
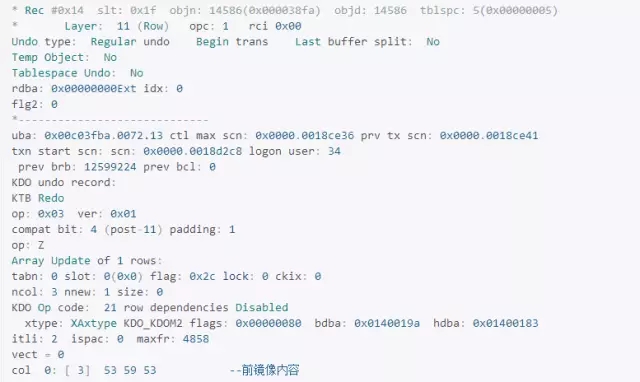
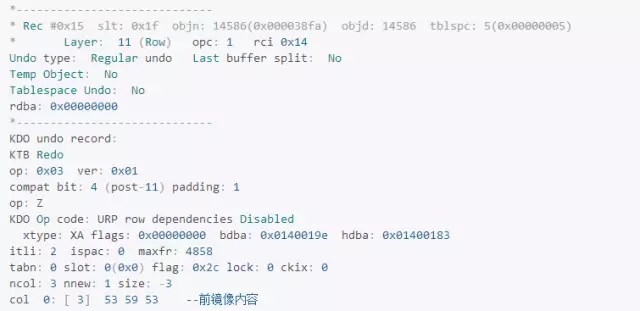
这里有两个重要结构,irb指向事务的最后一条undo记录,即回滚的起点,icl指向事务的第一条undo记录,即回滚的终点。
从前面数据块dump的uba(0x00c03fba.0072.15、0x00c03fba.0072.14)的第三部分可知,事务对应的undo记录为14、15,观察这两条记录:
这里需要注意三点:

这就是undo chain的一部分,与事务的混滚操作有关,undo块的irb指向事务undo record的最后一条记录 ,该记录中的rci指向前一个undo record记录,以此类推,最后一个undo record的ric为空,表示事务的起点,也是回滚的终点。
下图是完整的undo chain:
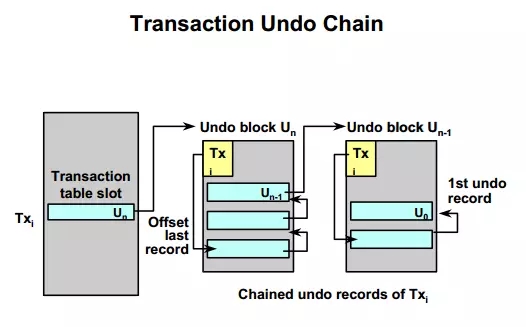
这里大家可以扩展思考一下,oracle的save point是如何实现的,是不是会与undo chain有关?如果修改rci值是不是可以实现回滚部分事务?
下面我们来看一个网上流传比较广的一个图:
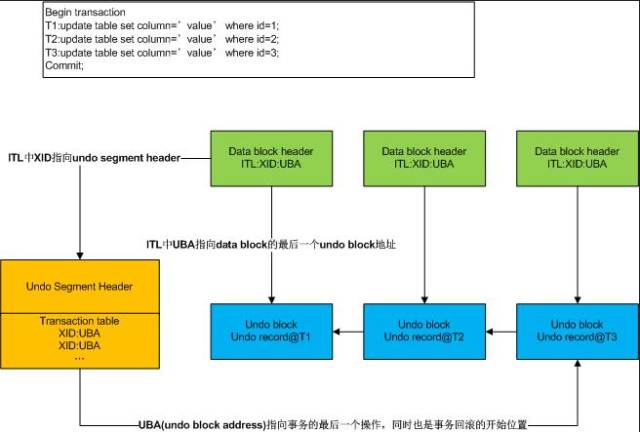
从前面我们的实验可以看出,这个图是有歧义的,undo镜像不是块级别的,所以不是一个数据块对应一个undo块,undo镜像其实是列级别的,只有被更改的列才会被记录。
Undo在事务中的工作方式我们就先分析到这。
2 Redo在事务中的作用
2.1 解析redo结构、undo受redo保护的实质、CV对数据块的作用
下面来看一看redo是如何工作的:
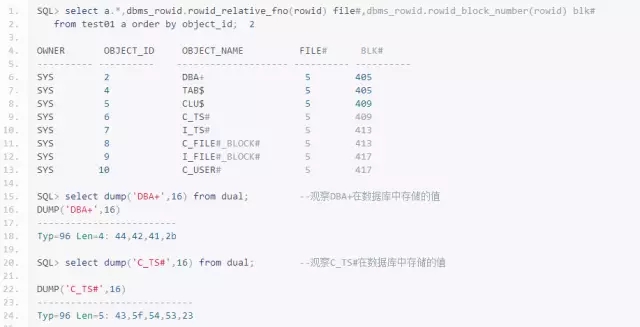
接下来dump 405号块进行观察(这里只选取表数据部分)
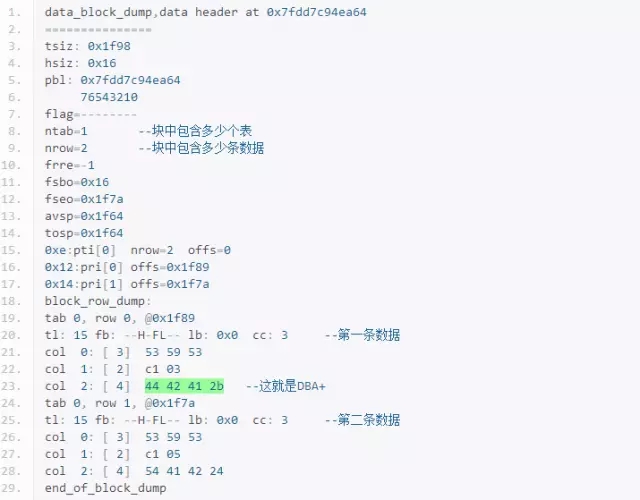
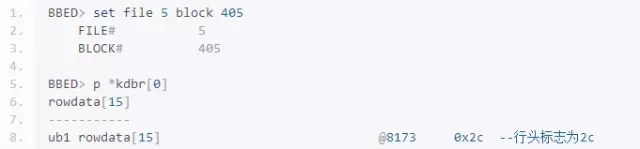
使用BBED观察DBA+这列的行头信息
下面删除其中的两条数据(这两条数据是位于不同的块中)

Dump上面两个scn之间的redo进行观察
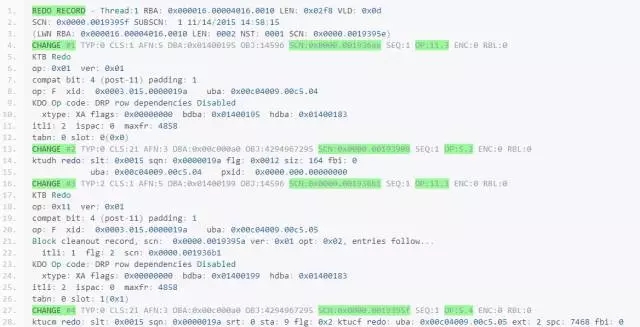
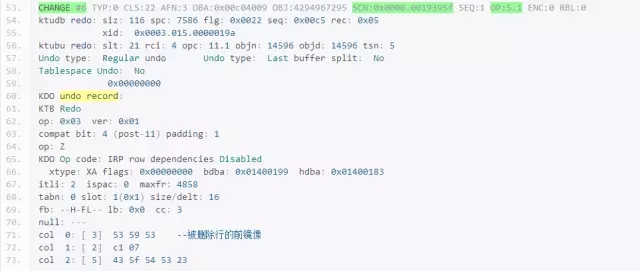
下面对redo dump进行分析:
1、 redo log是以CHANGE VECTOR为最小单位构成的,就是上面的CHANGE #n部分;
2、 一个REDO RECORD包含多个CV(CHANGE VECTOR);
3、 OP表示操作类型,不同的值表示不同的操作类型;
4、 redo中包含了前镜像,这就是redo保护undo的实质;
5、 上面的操作涉及两个块,但是只有一条redo record,所以redo record是可以包含多个块的,但是一个CV只能针对一个块,CV是一个数据块块版本演进的结果,CV只能向前推进数据块的版本,不能后退,对于回滚操作,会由于undo的应用而生成新的CV,这个CV依然是推进数据块版本,要使数据块版本回退的唯一方法是介质恢复。
2.2 理解快速提价机制、delete实质
下面再次dump 405号块(包含DBA+的数据块)
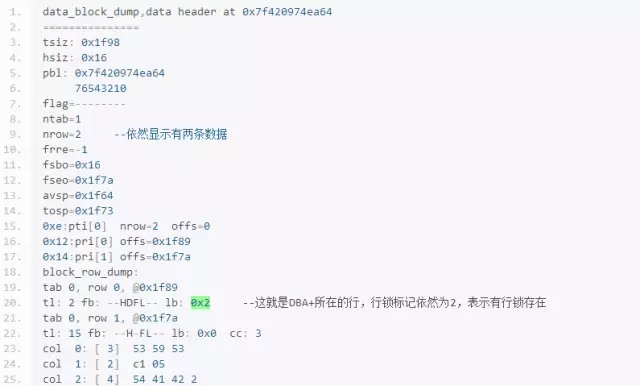
注意,这里nrow显示还有两行数据,但是删除行的数据没有在dump中显示;行锁标记也未释放,但是事务已经提交了,这就是Oracle的快速提交、和延迟块清除机制,只是保证修改undo段头事务表信息,块头和行头信息不一定进行修改。
那么delete到底发生了什么?下面用bbed进行观察:

发现被删除的数据依然在块中,只是行头标记被修改,这就是delete的实质。所以在数据被覆盖之前是可以通过修改行头标记恢复被delete的数据的。
还记得我们开始的那句话吗?爱情就像鬼一样,谁都听过,但谁也没见过。通过上面的实验,我们应该看到了一些东西。真爱还是有的!
时间,教会了我们很多东西。有些我们曾经认为根本没有的,后来发现,它确确实实存在着,而有些我们深信不疑的,后来却明白,根本就没有。比如,爱情…
从ITL到Undo前镜像提取实验
原文地址:从ITL到Undo前镜像提取实验 作者:realkid4
多版本一致读”是Oracle数据库的一个重要特性。Oracle中,一个数据行,如果正在进行数据块修改操作,而且尚未提交。其他会话的用户select的数据是该事务修改之前的数据行数据,也就是其“前镜像”。这样,Oracle中的Select操作是不会被DML事务所阻塞。
读取数据块的前镜像,是基于Oracle Undo机制完成的。当一个数据块要发生事务修改时,会将当前的数据信息复制到Undo Segment的相应位置中。并且作为发生的事务transaction,也会关联上对应Undo Segment中特定的位置信息。
上面的过程有一个重要细节:Undo Segment的前镜像写入操作,同样是有Redo Log Entry生成,记录入Redo Log的。只有这样,才能保证在进行Instance Recovery的过程中,Oracle进行事务前滚、后滚操作时,可以完全Replay Transaction。
当Select操作要检索一个正在进行事务的数据行时,Oracle会根据该行上对应的事务对应的Undo Block Address(UBA)定位到该数据行的前镜像信息。再到Undo Tablespace中找前镜像数据。
本文计划从数据块ITL(Interest Transaction List)事务槽入手,层层定位,演示找到事务数据行对应前镜像的过程。
1、环境准备
我们选择10gR2数据库,使用的环境和数据表同笔者上文《从Dump数据块看ITL》(http://space.itpub.net/17203031/viewspace-716353)。
SQL> select * from v$version;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Prod
PL/SQL Release 10.2.0.1.0 - Production
CORE 10.2.0.1.0 Production
TNS for 32-bit Windows: Version 10.2.0.1.0 - Production
NLSRTL Version 10.2.0.1.0 - Production
此时实验数据和Trace跟踪文件位置如下:
SQL> select * from t;
ID VNAME
---------- ----------
1 id
2 iddf
SQL> select id, dbms_rowid.rowid_relative_fno(rowid) fno, dbms_rowid.rowid_block_number(rowid) bno, dbms_rowid.rowid_row_number(rowid) rowno from t;
ID FNO BNO ROWNO
---------- ---------- ---------- ----------
1 1 65266 0
2 1 65266 1
SQL> select f_get_trace_name from dual;
F_GET_TRACE_NAME
--------------------------------------------------------------------------------
C:\TOOL\ORACLE\ORACLE\PRODUCT\10.2.0\ADMIN\OTS\UDUMP\ots_ora_4524.trc
我们Dump出初始的事务ITL列表,如下:
--此时ITL情况
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0007.02a.000085d4 0x00800ca8.35fc.09 C--- 0 scn 0x078c.7f2ddad3
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
注意:默认情况下,Oracle数据块的ITL事务槽初始数目是2。但是在上篇的实验中,我们实验过三个会话事务,用于测试ITL自动延展。现在发现,拓展的ITL列表对象并没有收缩。这说明:ITL一旦拓展,是不会回收缩减的。
2、事务信息定位解析
首先,我们开启一个会话进行实验。
SQL> update t set vname='d' where id=1;
1 row updated
SQL> select addr, xidusn, xidslot, xidsqn, ubafil, ubablk, ubasqn, ubarec, xid from v$transaction;
ADDR XIDUSN XIDSLOT XIDSQN UBAFIL UBABLK UBASQN UBAREC XID
-------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------------
27F8EDCC 6 9 34214 2 1762 13420 40 06000900A6850000
注意,在v$transcation中,我们是可以方便的定位到事务标记信息和对应的Undo Segment Block信息的。一个Oracle事务,在定位上是通过usn, slot和sqn唯一确定事务。注意上面代码中的三个标记,我们可以从Dump出的ITL中定位到这些信息。
使用dump命令将对应数据块的信息dump出。
--将数据块DUMP出
SQL> alter system dump datafile 1 block 65266;
System altered
--ITL片段
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0007.02a.000085d4 0x00800ca8.35fc.09 C--- 0 scn 0x078c.7f2ddad3
0x02 0x0006.009.000085a6 0x008006e2.346c.28 ---- 1 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
注意ITL02的槽位,从LCK信息上看,正在进行一个事务。对应的xid为“0x0006.009.000085a6”。这三个十六进制组成的代码,正好标注出事务的ID编号。
我们可以使用to_number函数将三个片段数据进行十六进制解析。
SQL> select to_number('0006','xxxxx') from dual;
TO_NUMBER('0006','XXXXX')
-------------------------
6 -–与v$transaction中的xidusn对应
SQL> select to_number('009','xxxxx') from dual;
TO_NUMBER('009','XXXXX')
------------------------
9 -–与v$transaction中的xidslot对应
SQL> select to_number('85a6','xxxxx') from dual;
TO_NUMBER('85A6','XXXXX')
-------------------------
34214 -–与v$transaction中的xidsqn对应
说明ITL02的确是对应我们会话事务。
从事务槽中,我们看到了UBA(Undo Block Address)信息,为“0x008006e2.346c.28”。UBA的格式解析为:dba+seq#+rec#。其中的dba为对应的数据文件和数据块的地址。
下面我们需要做的,就是定位到Undo片段的位置。
3、Undo位置确定和前镜像导出
我们需要从UBA地址找到前镜像保存的物理位置,也就是Undo块上的特定片段。首先从DBA中分析出地址。
--将16进制DBA翻译为十进制格式;
SQL> select to_number('8006e2','xxxxxxxx') from dual;
TO_NUMBER('8006E2','XXXXXXXX')
------------------------------
8390370
--使用dbms_utility方法实现转换;
SQL> select dbms_utility.data_block_address_file(8390370) file_no, dbms_utility.data_block_address_block(8390370) block_no from dual;
FILE_NO BLOCK_NO
---------- ----------
2 1762
定位到Undo Block的编号是在fno=2,blockno=1762的位置上。下面需要将其dump出。
SQL> alter system dump datafile 2 block 1762;
System altered
导出的Undo Block格式和一般数据块的Dump结果格式完全不相同。需要说明,一个Undo Block内部的内容可能很多,但是针对需要的前镜像信息,需要通过UBA中的seq#和rec#来确定。
我们首先可以从dump文件中,根据xid编号,找到事务片段。
**************************************************************
UNDO BLK:
xid: 0x0006.009.000085a6 seq: 0x346c cnt: 0x28 irb: 0x28 icl: 0x0 flg: 0x0000
cnt对应的就是UBA中的rec#,而seq对应UBA中的Seq。找到片段如下:
*-----------------------------
* Rec #0x28 slt: 0x09 objn: 112888(0x0001b8f8) objd: 112888 tblspc: 0(0x00000000)
* Layer: 11 (Row) opc: 1 rci 0x00
Undo type: Regular undo Begin trans Last buffer split: No
Temp Object: No
Tablespace Undo: No
rdba: 0x00000000
*-----------------------------
uba: 0x008006e2.346c.27 ctl max scn: 0x078c.7f2eae5b prv tx scn: 0x078c.7f2eae65
txn start scn: scn: 0x078c.7f2eb238 logon user: 0
prev brb: 8390369 prev bcl: 0
KDO undo record:
KTB Redo
op: 0x03 ver: 0x01
op: Z
KDO Op code: URP row dependencies Disabled
xtype: XA flags: 0x00000000 bdba: 0x0040fef2 hdba: 0x0040fef1
itli: 2 ispac: 0 maxfr: 4863
tabn: 0 slot: 0(0x0) flag: 0x2c lock: 0 ckix: 10
ncol: 2 nnew: 1 size: 1
col 1: [ 2] 69 64
对应的col,就是前镜像数据的体现。我们的update语句修改的是vname列,与col 1相对应。
我们可以将”69 64”翻译为可读格式,判断我们的想法。
set serveroutput on;
declare
n varchar2(10);
begin
dbms_stats.convert_raw_value('6964',n);
dbms_output.put_line(n);
end;
/
SQL>
id
PL/SQL procedure successfully completed
前镜像取值为id,与预想相同。
4、结论
本文简单介绍了如何从一个事务入手,找到前镜像数据的基本方法。我们文中是从itl入手进行研究的,还有可以从v$transaction视图中进行查询UNDO地址信息,效果相同。
自动undo管理(AUM,Automatic Undo Management)
手动undo管理(MUM,Manual Undo Management)
show parameter undo_management 两个取值auto,manual。
alter system set undo_tablespace=undoabc;
如果不指定某个UNDO表空间做默认的undo表空间,则系统会查找第一个undo表空间。数据库可以同时存在多个undo表空间,但一个时间点只能用一个undo表空间,切换时,如果旧的Undo表空间还有事务在执行,则变pending offline状态。新事务在新的undo表空间执行,旧的表空间会等到事务都提交以后,就变成Offline状态。
至于undo segment,AUM采用的是事务绑定segment的算法。(尽量一个事务一个undo segment)
首先尝试每个undo segment绑定一个事务,每个undo segment只被一个事务使用。
如果发现undo segment都用了,则会尝试使脱机的undo segment联机以使用。
如果发现没有可用的undo segment联机,则会尝试创建一个新的undo segment。
如果都不成功,比如没有可用空间了,这种情况下,不同的事务才会在一个undo segment里同时运行。
既然有undo segment的扩张,就有undo segment的收缩
SMON负责
每12小时收缩一次,删除那些idle状态的extents;
当DML需要用到UNDO时,发现不够空间,会唤醒SMON进行一次收缩,也就是说将其他undo segment里暂时没被使用的extents拿来用。
为避免ORA-1555快照太旧的错误,出现了undo_retention参数,表示当事务提交或回滚后,该事务所使用的undo块里的数据需要保留多长时间,秒为单位。当保留的时间超过undo_retention所指定的时间以后,该undo块才能被其他事务覆盖。
默认情况下,ORACLE10g会每隔30秒就收集统计信息来自动调整undo retention,如果我们设定undo_retention为0,或不设定,则启动此种模式,900秒为最低值;如果我们手动设定了undo_retention,则用我们指定的时间为undo保留的时间;
alter tablespace undoabc retention guarantee;
就保证了undo块一定能保留那么多时间。
alter tablespace undoabc retention noguarantee;
取消。
监控和管理Oracle UNDO表空间的使用
对Oracle数据库UNDO表空间的监控和管理是我们日常最重要的工作之一,UNDO表空间通常都是Oracle自动化管理(通过undo_management初始化参数确定);UNDO表空间是用于存储DML操作的前镜像数据,它是实例恢复,数据回滚,一致性查询功能的重要组件;我们常常会忽略对它的监控,这会导致UNDO表空间可能出现以下问题:
1).空间使用率100%,导致DML操作无法进行。
2).告警日志中出现大量的ORA-01555告警错误。
3).实例恢复失败,数据库无法正常打开。
一.对Oracle自动化管理UNDO进行干预。
由于UNDO是自动化管理,可干预的地方非常的少,更多的是监控,通过以下几个地方可对UNDO表空间实施一定的干预:
1).初始化参数
undo_management=AUTO 表示实例自动化管理UNDO表空间,从Oracle 9i开始,Oracle引进了AUM(Automatic Undo Management)。
undo_retention=900 事务提交后,相应的UNDO数据保留的时间,单位:秒。
undo_tablespace=UNDOTBS1 活动的UNDO表空间。
_smu_debug_mode=33554432
_undo_autotune=TRUE
2).Automatic UNDO Retention
Automatic UNDO Retention是10g的新特性,在10g和之后的版本的数据库,这个特性是默认启用的。
在Oracle Database 10g中当自动undo管理被启用,总是存在一个当前的undo retention,Oracle Database尝试至少保留旧的undo信息到该时间。数据库收集使用情况统计信息,基于这些统计信息和UNDO表空间大小来调整undo retention的时间。
Oracle Database基于undo表空间大小和系统活动自动调整undo retention,通过设置UNDO_RETENTION初始化参数指定undo retention的最小值。
查看Oracle自动调整UNDO RETENTION的值可以通过以下查询获得:
SELECT TO_CHAR(BEGIN_TIME, 'MM/DD/YYYY HH24:MI:SS') BEGIN_TIME,
TUNED_UNDORETENTION FROM V$UNDOSTAT;
针对自动扩展的UNDO表空间,系统至少保留UNDO到参数指定的时间,自动调整UNDO RETENTION以满足查询对UNDO的要求,这可能导致UNDO急剧扩张,可以考虑不设置UNDO RETENTION值。
针对固定的UNDO表空间,系统根据最大可能的undo retention进行自动调整,参考基于UNDO表空间大小和使用历史进行调整,这将忽略UNDO_RETENTION,除非表空间启用了RETENTION GUARANTEE。
自动调整undo retention不支持LOB,因为不能在undo表空间中存储任何有关LOBs事务的UNDO信息。
可以通过设置_undo_autotune=FALSE显示的关闭Automatic UNDO Retention功能。
3).TUNED_UNDORETENTION计算的值很大导致UNDO表空间增长很快?
当使用的UNDO表空间非自动增长,tuned_undoretention是基于UNDO表空间大小的使用率计算出来的,在一些情况下,特别是较大的UNDO表空间时,这将计算出较大的值。
为了解决此行为,设置以下的实例参数:
_smu_debug_mode=33554432
设置该参数,TUNED_UNDORETENTION就不基于undo表空间大小的使用率计算,代替的是设置(MAXQUERYLEN +300)和UNDO_RETENTION的最大值。
4).UNDO表空间数据文件自动扩展
如果UNDO表空间是一个自动扩展的表空间,那么很有可能UNDO表空间状态为EXPIRED的EXTENT不会被使用(这是为了减少报ORA-01555错误的几率),这将导致UNDO表空间变得很大;如果将UNDO表空间设置为非自动扩展,那么状态为EXPIRED的EXTENT就能被利用,这样可以一定程度控制UNDO表空间的大小,但这样会增加ORA-01555报错和UNDO空间不足报错的风险。合理的非自动扩展的UNDO表空间大小,以及合理的UNDO_RETENTION设置可以确保稳定的UNDO空间使用。
5).UNDO表空间guarantee属性
如果UNDO表空间是noguarantee状态,Oracle不确保提交后的事务对应的UNDO表空间中的数据会保留UNDO_RETENTION指定的时长,如果UNDO表空间不足,其他事务将可能偷盗相应的未过期的空间;将UNDO表空间设置为guarantee能够确保提交后的事务对应UNDO表空间中的数据在任何情况下都将保留UNDO_RETENTION指定的时长。
SQL> SELECT tablespace_name, retention FROM dba_tablespaces where tablespace_name='UNDOTBS1';
TABLESPACE_NAME RETENTION
------------------------------------------------------------ ----------------------
UNDOTBS1 NOGUARANTEE
SQL> alter tablespace undotbs1 retention guarantee;
表空间已更改。
SQL> SELECT tablespace_name, retention FROM dba_tablespaces where tablespace_name='UNDOTBS1';
TABLESPACE_NAME RETENTION
------------------------------------------------------------ ----------------------
UNDOTBS1 GUARANTEE
6).UNDO表空间大小
针对不同类型的业务系统,需要有充足的UNDO表空间,确保系统能够正常的运行。UNDO空间的大小跟业务系统有关系,也跟UNDO_RETENTION和UNDO表空间的GUARANTEE属性有关系,通常我们可以通过V$UNDOSTAT的统计信息估算出需要的UNDO表空间大小。
二.监控UNDO表空间使用情况。
作为管理员来说,针对UNDO表空间更重要的是日常的监控工作,监控常用到以下的视图:
a).DBA_ROLLBACK_SEGS
DBA_ROLLBACK_SEGS describes rollback segments.
b).V$ROLLSTAT
V$ROLLSTAT contains rollback segment statistics.
c).V$TRANSACTION
V$TRANSACTION lists the active transactions in the system.
d).V$UNDOSTAT
V$UNDOSTAT displays a histogram of statistical data to show how well the system is working. The available statistics include undo space consumption, transaction concurrency, and length of queries executed in the instance. You can use this view to estimate the amount of undo space required for the current workload. Oracle uses this view to tune undo usage in the system. The view returns NULL values if the system is in manual undo management mode.
Each row in the view keeps statistics collected in the instance for a 10-minute interval. The rows are in descending order by the BEGIN_TIME column value. Each row belongs to the time interval marked by (BEGIN_TIME, END_TIME). Each column represents the data collected for the particular statistic in that time interval. The first row of the view contains statistics for the (partial) current time period. The view contains a total of 576 rows, spanning a 4 day cycle.
e).DBA_UNDO_EXTENTS
DBA_UNDO_EXTENTS describes the extents comprising the segments in all undo tablespaces in the database. This view shows the status and size of each extent in the undo tablespace.
DBA_UNDO_EXTENTS.STATUS有三个值:
ACTIVE 表示未提交事务还在使用的UNDO EXTENT,该值对应的UNDO SEGMENT的DBA_ROLL_SEGMENTS.STATUS一定是ONLINE或PENDING OFFLINE状态,一旦没有活动的事务在使用UNDO SEGMENT,那么对应的UNDO SEGMENT就变成OFFLINE状态。
EXPIRED 表示已经提交且超过了UNDO_RETENTION指定时间的UNDO EXTENT。
UNEXPIRED 表示已经提交但是还没有超过UNDO_RETENTION指定时间的UNDO EXTENT。
Oracle重复使用UNDO EXTENT的原则如下:
1).ACTIVE状态的EXTENT在任何情况下都不会被占用。
2).如果是自动扩展的UNDO表空间,Oracle会保证EXTENT至少保留UNDO_RETENTION指定的时间。
3).如果自动扩展空间不足或者UNDO表空间是非自动扩展,Oracle会尝试重复使用同一个段下面EXPIRED状态的EXTENT,如果本段中没有这样的EXTENT,就会去偷别的段下面EXPIRED状态的EXTENT,如果依然没有这样的EXTENT,就会使用本段UNEXPIRED的EXTENT,如果还是没有,那么会去偷别的段的UNEXPIRED的EXTENT,这个都没有,就会报错。
1.UNDO表空间空间使用情况。
1).UNDO表空间总大小。
UNDO表空间下也以段的形式存储数据,每个事务对应一个段,这种类型的段通常被称为回滚段,或者UNDO段。默认情况下,数据库实例会初始化10个UNDO段,这主要是为了避免新生成的事务对UNDO段的争用。
UNDO表空间的总大小就是UNDO表空间下的所有数据文件大小的总和:
SQL> select tablespace_name,contents from dba_tablespaces where tablespace_name='UNDOTBS1';
TABLESPACE_NAME CONTENTS
------------------------------------------------------------ ------------------
UNDOTBS1 UNDO
SQL> select tablespace_name,sum(bytes)/1024/1024 mb from dba_data_files where tablespace_name='UNDOTBS1' group by tablespace_name;
TABLESPACE_NAME MB
------------------------------------------------------------ ----------
UNDOTBS1 90
2).查看UNDO表空间的使用情况。
该使用情况可以通过两个视图来查看:
SQL> select owner,segment_name,bytes/1024/1024 mb from dba_segments where tablespace_name='UNDOTBS1';
OWNER SEGMENT_NAME MB
---------- ------------------------------ ----------
SYS _SYSSMU12_2867006942$ .125
SYS _SYSSMU11_3120896088$ .125
SYS _SYSSMU10_1735367849$ 2.125
SYS _SYSSMU9_3051513041$ 2.125
SYS _SYSSMU8_2280151962$ 2.125
SYS _SYSSMU7_825858386$ .9375
SYS _SYSSMU6_2597279618$ 3.125
SYS _SYSSMU5_247215464$ 3.125
SYS _SYSSMU4_437228663$ 2.125
SYS _SYSSMU3_3104504842$ 5.125
SYS _SYSSMU2_2464850095$ 2.125
SYS _SYSSMU1_2523538120$ 3.125
已选择12行。
SQL> select segment_name, v.rssize/1024/1024 mb
2 From dba_rollback_segs r, v$rollstat v
3 Where r.segment_id = v.usn(+)
4 order by segment_name ;
SEGMENT_NAME MB
------------------------------ ----------
SYSTEM .3671875
_SYSSMU10_1735367849$ 2.1171875
_SYSSMU11_3120896088$
_SYSSMU12_2867006942$
_SYSSMU1_2523538120$ 3.1171875
_SYSSMU2_2464850095$ 2.1171875
_SYSSMU3_3104504842$ 5.1171875
_SYSSMU4_437228663$ 2.1171875
_SYSSMU5_247215464$ 3.1171875
_SYSSMU6_2597279618$ 3.1171875
_SYSSMU7_825858386$ .9296875
_SYSSMU8_2280151962$ 2.1171875
_SYSSMU9_3051513041$ 2.1171875
已选择13行。
通过上面的两个查询可以看出,两个视图查询的值几乎一致,通常在巡检的时候,我们习惯查询dba_segments视图来确定UNDO表空间的使用情况,但查询V$ROLLSTAT数据更加准确。
3).查询事务使用的UNDO段及大小。
很多客户想知道,我的UNDO表空间超过了90%,是哪些会话的事务占用了这些空间:
SQL> select s.sid,s.serial#,s.sql_id,v.usn,segment_name,r.status, v.rssize/1024/1024 mb
2 From dba_rollback_segs r, v$rollstat v,v$transaction t,v$session s
3 Where r.segment_id = v.usn and v.usn=t.xidusn and t.addr=s.taddr
4 order by segment_name ;
SID SERIAL# SQL_ID USN SEGMENT_NAME STATUS MB
---------- ---------- -------------------------- ---------- ------------------------------------------------------------ -------------------------------- ----------
8 163 5 _SYSSMU5_247215464$ ONLINE 3.1171875
通过这个SQL语句可以查询到会话对应的活动事务使用的UNDO段名称,以及该段占用的UNDO空间大小,对于非活动事务占用了UNDO空间是由Oracle实例根据参数配置自动化管理的。
2.根据Oracle对UNDO表空间的统计信息调整UNDO参数及大小。
最后我们要谈谈V$UNDOSTAT视图,该视图的作用是用于指导管理员调整UNDO表空间的参数及表空间大小,每行表示的是10分钟的数据,最多可保留576行,4天一个周期,如果该视图没有数据,那么UNDO可能是手动管理方式。下面对该视图字段的含义进行说明:
下面是查询V$UNDOSTAT的例子:
SELECT TO_CHAR(BEGIN_TIME, 'MM/DD/YYYY HH24:MI:SS') BEGIN_TIME,
TO_CHAR(END_TIME, 'MM/DD/YYYY HH24:MI:SS') END_TIME,
UNDOTSN, UNDOBLKS, TXNCOUNT, MAXCONCURRENCY AS "MAXCON",
MAXQUERYLEN, TUNED_UNDORETENTION
FROM v$UNDOSTAT;
通常当字段UNXPSTEALCNT和EXPBLKREUCNT是非零值,表示有空间压力。
如果字段SSOLDERRCNT是非零值,表示UNDO_RETENTION设置不合理。
如果字段NOSPACEERRCNT是非零值,表示有一系列空间问题。
在10g DBA_HIST_UNDOSTAT视图包括了V$UNDOSTAT快照统计信息。
注意:如果参数_undo_autotune=FALSE,X$KTUSMST2将没有数据生成,该表是DBA_HIST_UNDOSTATS视图的源表。
三.释放UNDO表空间。
UNDO表空间被撑得过大,有些时候我们需要释放这些空间,通常的做法是新建一个UNDO,然后设置使用新建的UNDO表空间,最后DROP原有UNDO表空间。下面通过一个例子来演示这个过程:
SQL> col segment_name format a30
SQL> col tablespace_name format a30
SQL>
SQL> select segment_name, tablespace_name, r.status,
2 (initial_extent/1024) InitialExtent,(next_extent/1024) NextExtent,
3 max_extents, v.curext CurExtent
4 From dba_rollback_segs r, v$rollstat v
5 Where r.segment_id = v.usn(+)
6 order by segment_name ;
SEGMENT_NAME TABLESPACE_NAME STATUS INITIALEXTENT NEXTEXTENT MAX_EXTENTS CUREXTENT
------------------------------ ------------------------------ -------------------------------- ------------- ---------- ----------- ----------
SYSTEM SYSTEM ONLINE 112 56 32765 4
_SYSSMU10_1735367849$ UNDOTBS1 ONLINE 128 64 32765 2
_SYSSMU11_3120896088$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU12_2867006942$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU1_2523538120$ UNDOTBS1 ONLINE 128 64 32765 2
_SYSSMU2_2464850095$ UNDOTBS1 ONLINE 128 64 32765 2
_SYSSMU3_3104504842$ UNDOTBS1 ONLINE 128 64 32765 2
_SYSSMU4_437228663$ UNDOTBS1 ONLINE 128 64 32765 2
_SYSSMU5_247215464$ UNDOTBS1 ONLINE 128 64 32765 3
_SYSSMU6_2597279618$ UNDOTBS1 ONLINE 128 64 32765 3
_SYSSMU7_825858386$ UNDOTBS1 ONLINE 128 64 32765 9
_SYSSMU8_2280151962$ UNDOTBS1 ONLINE 128 64 32765 3
_SYSSMU9_3051513041$ UNDOTBS1 ONLINE 128 64 32765 2
已选择13行。
当前所有的回滚段在属于UNDOTBS1表空间。
SQL> create undo tablespace undotbs2 datafile 'E:\APP\ORADATA\ORCL3\undotbs02.dbf' size 20m autoextend on next 100m;
表空间已创建。
SQL> show parameter undo
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
undo_management string AUTO
undo_retention integer 900
undo_tablespace string UNDOTBS1
SQL> alter system set undo_tablespace='UNDOTBS2';
系统已更改。
SQL> show parameter undo
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
undo_management string AUTO
undo_retention integer 900
undo_tablespace string UNDOTBS2
SQL> select segment_name, tablespace_name, r.status,
2 (initial_extent/1024) InitialExtent,(next_extent/1024) NextExtent,
3 max_extents, v.curext CurExtent
4 From dba_rollback_segs r, v$rollstat v
5 Where r.segment_id = v.usn(+)
6 order by segment_name ;
SEGMENT_NAME TABLESPACE_NAME STATUS INITIALEXTENT NEXTEXTENT MAX_EXTENTS CUREXTENT
------------------------------ ------------------------------ -------------------------------- ------------- ---------- ----------- ----------
SYSTEM SYSTEM ONLINE 112 56 32765 5
_SYSSMU10_1735367849$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU11_3120896088$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU12_2867006942$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU13_3398750080$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU14_3208386744$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU15_2082453576$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU16_2746861185$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU17_3752120760$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU18_3475721077$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU19_1407063349$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU1_2523538120$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU20_910603223$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU21_1261247597$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU22_1117177365$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU2_2464850095$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU3_3104504842$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU4_437228663$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU5_247215464$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU6_2597279618$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU7_825858386$ UNDOTBS1 ONLINE 128 64 32765 9
_SYSSMU8_2280151962$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU9_3051513041$ UNDOTBS1 OFFLINE 128 64 32765
已选择23行。
虽然将数据库实例使用的UNDO表空间指向了新表空间,但是依然有过去的事务在使用UNDOTBS1表空间下面的段,这个时候不能直接DROP UNDOTBS1(执行DROP命令也会报错),必须等待UNDOTBS1表空间下的所有段状态变成OFFLINE才能DROP。
SQL> r
1 select segment_name, tablespace_name, r.status,
2 (initial_extent/1024) InitialExtent,(next_extent/1024) NextExtent,
3 max_extents, v.curext CurExtent
4 From dba_rollback_segs r, v$rollstat v
5 Where r.segment_id = v.usn(+)
6* order by segment_name
SEGMENT_NAME TABLESPACE_NAME STATUS INITIALEXTENT NEXTEXTENT MAX_EXTENTS CUREXTENT
------------------------------ ------------------------------ -------------------------------- ------------- ---------- ----------- ----------
SYSTEM SYSTEM ONLINE 112 56 32765 5
_SYSSMU10_1735367849$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU11_3120896088$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU12_2867006942$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU13_3398750080$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU14_3208386744$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU15_2082453576$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU16_2746861185$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU17_3752120760$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU18_3475721077$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU19_1407063349$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU1_2523538120$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU20_910603223$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU21_1261247597$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU22_1117177365$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU2_2464850095$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU3_3104504842$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU4_437228663$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU5_247215464$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU6_2597279618$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU7_825858386$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU8_2280151962$ UNDOTBS1 OFFLINE 128 64 32765
_SYSSMU9_3051513041$ UNDOTBS1 OFFLINE 128 64 32765
已选择23行。
UNDOTBS1表空间下的所有段状态都变成了OFFLINE,这个时候可以DROP UNDOTBS1来释放空间。
SQL> drop tablespace undotbs1 including contents and datafiles;
表空间已删除。
虽然能DROP,只是说明没有事务在使用旧的UNDO表空间,这并不表示所有的UNDO EXTENT已经过期(DBA_UNDO_EXTENTS.STATUS),如果有某些查询需要用到这些存储在旧UNDO表空间上过期或未过期的EXTENT时,将收到ORA-01555的报错。
SQL> select segment_name, tablespace_name, r.status,
2 (initial_extent/1024) InitialExtent,(next_extent/1024) NextExtent,
3 max_extents, v.curext CurExtent
4 From dba_rollback_segs r, v$rollstat v
5 Where r.segment_id = v.usn(+)
6 order by segment_name ;
SEGMENT_NAME TABLESPACE_NAME STATUS INITIALEXTENT NEXTEXTENT MAX_EXTENTS CUREXTENT
------------------------------ ------------------------------ -------------------------------- ------------- ---------- ----------- ----------
SYSTEM SYSTEM ONLINE 112 56 32765 5
_SYSSMU13_3398750080$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU14_3208386744$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU15_2082453576$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU16_2746861185$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU17_3752120760$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU18_3475721077$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU19_1407063349$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU20_910603223$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU21_1261247597$ UNDOTBS2 ONLINE 128 64 32765 0
_SYSSMU22_1117177365$ UNDOTBS2 ONLINE 128 64 32765 0
已选择11行。
有益的补充《Oracle 11gR2 Database UNDO表空间使用率居高不下》:http://blog.itpub.net/23135684/viewspace-1406011/
有关AUM更多详细的信息,请参考文章:
《FAQ – Automatic Undo Management (AUM) / System Managed Undo (SMU) (文档 ID 461480.1)》
《AUM 常用分析/诊断脚本 (文档 ID 1526122.1)》
--end--
Oracle 11gR2 Database UNDO表空间使用率居高不下
客户的数据库是Oracle Database 11.2.0.3.0 for AIX 6.1 64bit的单机数据库。客户查询DBA_FREE_SPACE发现UNDO表空间的使用率高达98%以上。客户的UNDO表空间已经手动扩展到了25GB,且一直在增加,为了UNDO表空间能及时的被释放,UNDO表空间对应的所有数据文件自动扩展都被关闭。查询DBA_UNDO_EXTENTS发现在UNDO表空间中当前没有ACTIVE的EXTENT存在,UNEXPIRED的占到总空间的60%,有30%是EXPIRED,但Oracle并没有及时的释放这些空间。
客户的UNDO表空间并没有设置成GUARANTEE模式,所以根据我们的知识都明白UNDO表空间中的EXPIRED和UNEXPIRED都是可能被重用的,但是这么高的UNDO表空间使用率看着让人不踏实。
虽然我们在初始化参数中设置了UNDO_RETENTION等参数,但从Oracle 10gR2开始,默认Oracle都开启了UNDO表空间的自动调整功能,查找V$UNDOSTAT.TUNED_UNDORETENTION发现最近一段时间该值都被自动调整到了3500多分钟,也就是说UNDO表空间中的数据要保留接近3天才会过期,正是因为这么长的数据未过期时间,且表空间又足够的大,才导致了UNDO表空间的空间一致未被释放,同时也找到了Oracle下面的一段解释:
Why TUNED_UNDORETENTION is calculated so high making undo space grow fast ?
When non-autoextensible undo space is used, tuned_undoretention is calculated based on a percentage of the undo tablespace size. In some cases especially with large undo tablespace, This will make it to be calculated so large.
To fix this behaviour, Set the following instance parameter:
_smu_debug_mode=33554432
With this setting, TUNED_UNDORETENTION is not calculated based on a percentage of the fixed size undo tablespace. Instead it is set to the maximum of (MAXQUERYLEN secs + 300) and UNDO_RETENTION.
简单的说,就是当UNDO表空间对应的数据文件非自动扩展,且UNDO表空间又比较大的时候,tuned_undoretention的值是根据UNDO表空间大小的百分比来计算的,在一些情况下会将tuned_undoretention的值调整得特别大。
解决办法,如果设置_smu_debug_mode=33554432,那么Oracle的UNDO RETENTION自动调整功能依然被开启,但是计算tuned_undoretention是根据MAXQUERYLEN secs +300来计算,而不是根据UNDO表空间大小的百分比来计算,这样就可以避免TUNED_UNTORETENTION出现特别大的值。
以上内容摘自:《FAQ – Automatic Undo Management (AUM) / System Managed Undo (SMU) (Doc ID 461480.1)》。
同样我们还参考了另一篇文章:
Automatic Tuning of Undo_retention Causes Space Problems (Doc ID 420525.1)
In this Document
Applies to:
Oracle Database - Enterprise Edition - Version 10.2.0.4 to 10.2.0.4 [Release 10.2]
Information in this document applies to any platform.
Oracle Server Enterprise Edition - Version: 10.2.0.1 to 10.2.0.3 -- fixed by patchset 10.2.0.4 and no issues on this at 11g
*** Checked for currency: 13-SEP-2012 ***
Symptoms
You have verified that Document 413732.1 is not applicable and the problem is not a misunderstanding in the way EXPIRED/UNEXPIRED are used and reused over time.
Look for:
-
Whether the undo is automatically managed by the database by checking the following instance parameter:
UNDO_MANAGEMENT=AUTO
-
Whether the undo tablespace is fixed in size:
SQL> SELECT autoextensible
FROM dba_data_files
WHERE tablespace_name=''
This returns "NO" for all the undo tablespace datafiles.
-
The undo tablespace is already sized such that it always has more than enough space to store all the undo generated within the undo_retention time, and the in-use undo space never exceeds the undo tablespace warning alert threshold (see below for the query to show the thresholds).
-
The tablespace threshold alerts recommend that the DBA add more space to the undo tablespace:
SQL> SELECT creation_time, metric_value, message_type, reason, suggested_action
FROM dba_outstanding_alerts
WHERE object_name='';
This returns a suggested action of: "Add space to the tablespace".
Or,
This recommendation has been reported in the past but the condition has now cleared:
SQL> SELECT creation_time, metric_value, message_type, reason, suggested_action, resolution
FROM dba_alert_history
WHERE object_name='';
-
The undo tablespace in-use space exceeded the warning alert threshold at some point in time. To see the warning alert percentage threshold, issue:
SQL> SELECT object_type, object_name, warning_value, critical_value
FROM dba_thresholds
WHERE object_type='TABLESPACE';
To see the (current) undo tablespace percent of space in use:
SQL> SELECT
((SELECT (NVL(SUM(bytes),0))
FROM dba_undo_extents
WHERE tablespace_name=''
AND status IN ('ACTIVE','UNEXPIRED')) * 100)/
(SELECT SUM(bytes)
FROM dba_data_files
WHERE tablespace_name='')
"PCT_INUSE"
FROM dual;
Cause
The cause of this problem has been identified in:
Bug:5387030 - AUTOMATIC TUNING OF UNDO_RETENTION CAUSING SPACE PROBLEMS
It is caused by a wrong calculation of the tuned undo retention value.
Bug:5387030 is fixed in RDBMS 11.1.
Solution
To implement a solution for Bug:5387030, please execute any of the below alternative solutions:
-
Upgrade to 11.1 in which Bug:5387030 is fixed
OR
-
Apply patchset release 10.2.0.4 or higher in which Bug:5387030 is fixed.
OR
-
Download and apply interim Patch:5387030, if available for your platform and RDBMS release. To check for conflicting patches, please use the MOS Patch Planner Tool. If no patch is available, file a Service Request through My Oracle Support for your specific Oracle version and platform.
OR
References
BUG:5387030 - AUTOMATIC TUNING OF UNDO_RETENTION CAUSING SPACE PROBLEMS
NOTE:413732.1 - Full UNDO Tablespace In 10gR2 and above
这篇文章本来是用来解决10gR2中的bug,但是在11gR2中同样适用,说明在11gR2中同样存在该bug。在文章提供了3种解决方案:
1).将UNDO表空间对应的数据文件调整为自动扩展,并为其设定一个最大值。
SQL> ALTER DATABASE DATAFILE '' AUTOEXTEND ON MAXSIZE
客户正是通过这种方式解决了问题,调整之后空间很快得到释放,V$UNDOSTAT.TUNED_UNDORETENTION值立即变小,这和文章前面的解释是完全吻合的,当UNDO表空间对应的数据文件是自动扩展的,那么V$UNDOSTAT.TUNED_UNDORETENTION值的计算就不再依赖于UNDO表空间的百分比(UNDO表空间本身较大)。
2).设置_smu_debug_mode隐藏参数。
_smu_debug_mode=33554432
前面我们已经对这个参数进行了解释,这里再次验证。
3).设置_undo_autotune隐藏参数。
_undo_autotune = false
前面的两种方法没有关闭Oracle的UNDO自动调整RETENTION的功能,将_undo_autotune设置为false,就彻底关闭了自动调整UNDO RETENTION的功能,那么UNDO的RETENTION时间完全依赖于初始化参数UNDO_RETENTION的值,默认值为900秒。
以上三种方法的任意一种方法都可以解决客户面临的该问题。
这篇文章是对我另一篇文章有益的补充:《监控和管理Oracle UNDO表空间的使用》:http://blog.itpub.net/23135684/viewspace-1065601/
我们学习的很多知识点过一段时间都可能忘记,但通过具体的案例我们更容易的记住。
--end--
About Me















