优化总结:
虽然列有索引,但是由于基于该列查询出来的结果太多,如果再去回表的话消耗的资源比走全表还大,这里oracle选择了全表。分析测试发现通过对where条件的两个字段创建联合索引能够起到较好的效果,另外通过改写sql的方式(不等于改为大于小于),充分利用联合索引。
应用反馈中心资源库查询有价卡表时未走索引(其他节点查询时走索引),导致报表无法展示,引起投诉
两条sql如下:
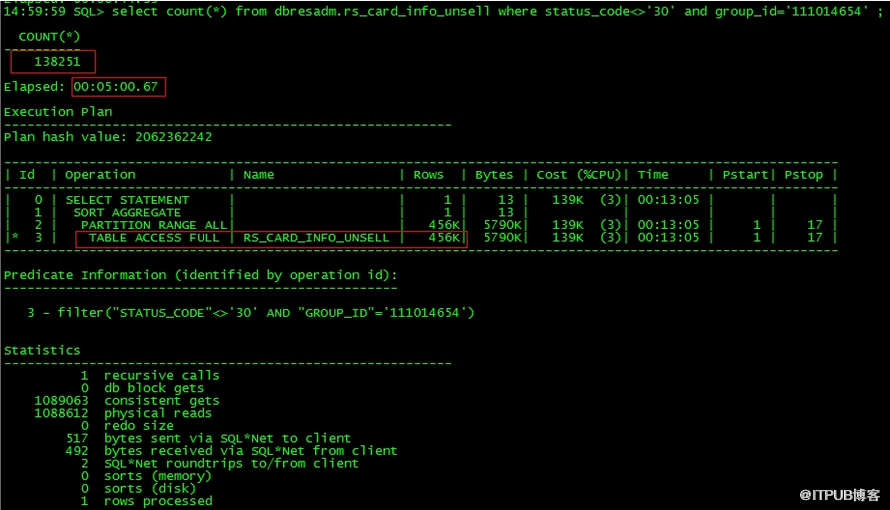
select * from dbresadm.rs_card_info_unsell where status_code<>'30' and group_id='111014654' ;
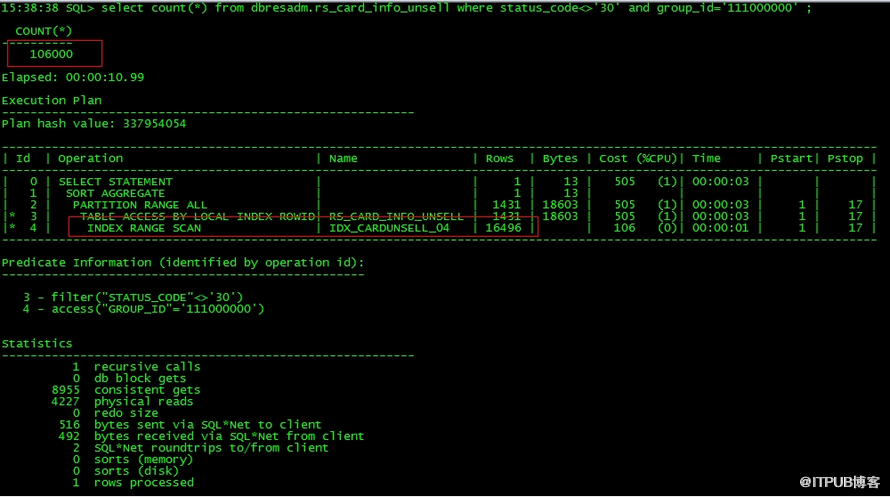
select * from dbresadm.rs_card_info_unsell where status_code<>'30' and group_id='111000000' ;
在bcv上查询,确实第一个走全表扫描,第二个走索引
给第一条sql加hint执行后发现还是很慢:
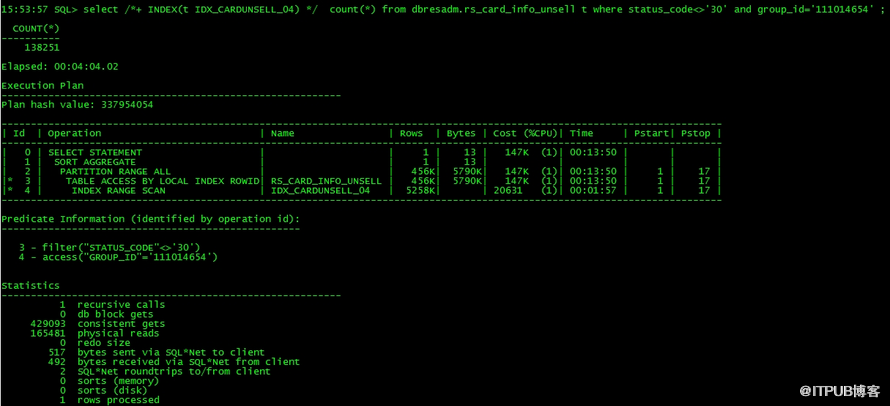
接下来分析如下:
SELECT COUNT(*) from dbresadm.rs_card_info_unsell a WHERE group_id='111000000' ;
只返回10几万行
SQL> SELECT COUNT(*) from dbresadm.rs_card_info_unsell a WHERE group_id='111014654' ;
COUNT(*)
----------
5283350
返回500多万行,总数据量5000多万行,原始语句是select * 访问完索引还需要回表,或者直接全表(oracle选择全表),表8G多,都会很慢。
解决方法:
1、由于status_code<>'30' and group_id='111014654' 联合查询结果10几万行,相比总行数5000多万比较少,如果建立联合索引应该有效果,见2
2、建立联合索引:
CREATE INDEX dbresadm.IDX_CARDUNSELL_05 ON dbresadm.rs_card_info_unsell(group_id,status_code) TABLESPACE TBS_PERSON NOLOGGING PARALLEL 16
;
ALTER INDEX dbresadm.IDX_CARDUNSELL_05 NOPARALLEL;
测试结果:
SELECT * from dbresadm.rs_card_info_unsell a where status_code<>'30' and group_id='111014654' ;
运行10s多,逻辑IO 58344 consistent gets
进一步改进(<>改写成< or >),改写SQL写法,充分利用联合索引效果:
SELECT * from dbresadm.rs_card_info_unsell a where (status_code>'30' OR status_code<'30') and group_id='111014654' ;
运行时间6s多,逻辑IO 38298 consistent gets