相信大家都对IT大厂的机器学习应用的建设很感兴趣,如果有技术大咖们能够从零开始和大家详细分享一下他们大规模机器学习实践,是不是一件再好不过的事情了。2017年10月19日-21日,由IT168主办的第九届系统架构师大会,就邀请到了vivo互联网算法团队负责人李珂和我们分享vivo从0到1再到无穷的机器学习实践。

▲vivo互联网算法团队负责人 李珂
机器学习算法在vivo落地的时候,李珂团队遇到了所有初创团队都会遇到的问题——人少坑多技术弱。当时整个vivo互联网算法团队只有李珂和应届毕业生两个人,但是他们克服了这些种种困难在2016年推出了第一代解决方案架构。

这个解决方案很好的利用了现有大数据架构,不仅对算法团队的技能要求单一,而且对于工程团队的要求也很低,出错的几率也较小。但是由于离线预测,很多实时特征用不了,而且离线训练,模型更新也较慢,使用Spark进行训练,可选模型少,效率低,训练数据的规模有瓶颈。
为了解决第一代离线使用的弊端,vivo互联网算法团队在2017年上半年推出了第二代解决方案。与第一代相比,第二代最显著的特点就是实现了实时预测和在线训练,不仅能够使用上下文,时间等场景信息,而且能够学习新广告,适应概念漂移。
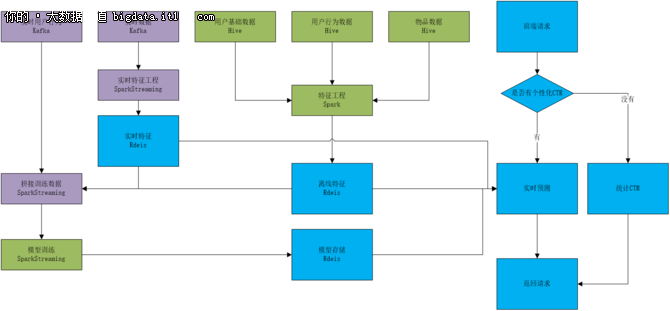
但是第二代解决方案大量使用实时数据,工程端承担线上预测部分开发,出错的可能性增大,而且算法迭代涉及大数据和工程改动,成本高周期长。李珂表示在第二代解决方案开发的过程中得到了重要的经验,实时特征工程一定要存原始数据,客户端上传日志的时候要透传预测的CTR和requestID,模型要先做线下验证,不光是整体的,还要单个item的。
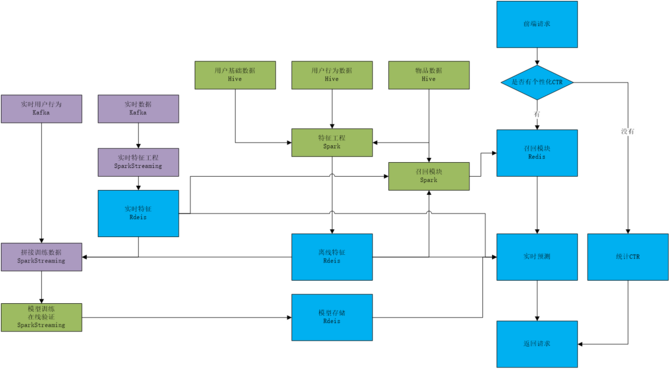
现在vivo使用的是第三代解决方案,这个方案主要增加了召回模块,支持多条拉链的并行召回,支持离线或者在线更新拉链,支持灰度拉链热拔插。据李珂介绍该解决方案主要应用在vivo信息流推荐、关联广告和搜索广告等业务中。
李珂认为现在的解决方案也不是完美的,还存在很多不足,主要问题还是出在Spark上,Spark不支持FM,DNN等业界较先进的模型,而且因为没有Parameter Server,executor的CPU利用率最多到30%。所以未来会考虑选择TensorFlow CPU Cluster来做替补,通过Kubernetes+Docker弹性部署。