本文根据赵子明老师在2018年5月12日【第九届中国数据库技术大会(DTCC)】现场演讲内容整理而成。
讲师简介:

赵子明,一个熟悉基础架构和应用架构的双料胖子,曾在大麦网、京东工作。设计开发过Zookeeper多活(跨机房双向复制)、分布式kv、API网关等组件,搞过几十个微服务组成的交易系统的梳理优化,有单应用到微服务的演化经历,有高并发下系统性能优化经验。
摘要:
随着互联网和大数据的发展,各种NoSQL数据库层出不穷,在不同的场景下衍生出了不同的产品,本次分享和大家聊聊饿了么分布式kv的设计架构与实践总结。主要内容:1.饿了么分布式kv的架构和实现;2.和其他NoSQL对比有什么异同;3.在哪些场景下使用以及遇到什么问题;4.思考与总结。
分享大纲:
-
背景介绍
-
饿了么分布式kv架构简介
-
使用场景&问题
-
总结&展望
正文演讲:
一.背景介绍

随着互联网的快速发展,数据量的极速增加,性能要求的提高……这些要求传统数据库往往会因扩展性和性能方面的制约而无法满足,NoSQL在此时大显神威,通过放弃表关联、多行事务等特性来追求性能、扩展性以及低成本。
举个例子,在关系型数据库中多表关联查询join是很容易做到,但在分布式场景下面,不同的表会分布在不同的机器上,中间的关联关系比较复杂,如果要把这么多机器里的不同数据片段做聚合成本太高了,同时性能也会下降。
随着开源数据库越来越多,NoSQL数据库也百花齐放,各种表格、kv在很多场景下都应用得很好。
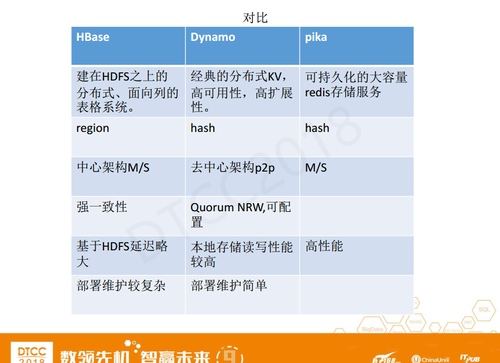
我挑选了三款比较典型的NoSQL数据库来做对比,首先是HBase,HBase是建在HDFS之上的分布式、面向列的表格系统,虽然它是半实时的,但更多面向的是数据分析场景,并在列存和行存之间取了个平衡。Dynamo是亚马逊大牛提出的,经典的分布式KV,应用了很多分布式的技术。Pika也是很好用的开源产品,可持久化的大容量Redis存储服务。
HBase数据分片方式是有顺序的region,Dynamo用的是Hash。HBase是中心架构,中间有主从,而Dynamo是去中心架构p2p,其应用的很多技术都有借鉴意义,例如集群管理、信息发现、向量时钟等等。Pika更像是一个单机Redis,主从、集群都需要自己做。
HBase支持强一致,如果更确切的来说是支持单行某个列族的强一致,Dynamo的一致性是可配置的,要在一致性和读写性能之间做一些取舍,Pika这里就不多谈了。
HBase基于HDFS,有些情况下会做远程调用,它在大数据读写分析的场景下表现很好,但如果用在线上,读写性能会稍微弱一点。Dynamo采用本地存储,读写性能较高,并且可以根据Quorum NRW做一些场景化配置优化来提高性能。Pika相对于内存级Redis来说性能会差一些,但是作为磁盘来说,它是一个高性能的存储。
HBase需要部署zookeeper、HDFS等等,部署维护比较复杂。Dynamo都是对等节点,部署维护比较简单。 把Pika类比成单机Redis,如果我们要做集群,相对来说成本会更大一些,需要自己处理数据分片规则、主从结构,数据复制,异常恢复等问题。

在饿了么数据量的快速增长,但内部没有专门的KV组件,很多同学都是按照自己的习惯选择存储组件,对于一些简单的数据,有人选择存MySQL、Redis,也有人会存MongoDB、Cassandra。
Redis这种内存级的组件是更适合超热的数据,性能很高。但在超大数据集的大数据场景下不可能把数据全部放入内存,需要将Redis结合其他磁盘存储组件一起使用,但很多时候没有整体的解决方案,成本较高,性能较差。
这样的背景下体现那些问题?扩展性差、性能不达标,其次就是运维成本比较高,以及无法满足某些场景下对于数据可靠的高要求。

我们对KV的要求:
-
首先因为我们这边大多是在线场景,所以要求高性能,延迟要在毫秒级别;
-
其次是大数据量,能达到几十TB;
-
第三是高可靠,一旦出现问题最好能通过自运维的方式自愈;
-
第四是在任何情况下都要实现高可用;
-
第五是易运维,系统实现的复杂一点,运维能够更方便;最后是强一致,无论集群怎么挂或者切换,数据都保证不丢失。
二.饿了么分布式kv架构简介
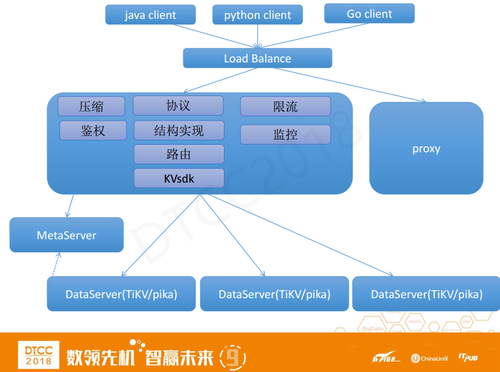
上图是整体架构,我们从去年下半年开始着手做这件事,两三个月之后上线。能用较短的时间地完成上线要感谢开源,我们基于开源产品做封装提供服务。在这个架构中,我们做了一个代理层,支持Java、Python、Go等客户端。
底层架构是一个中心化的架构,MetaServer存集群的元信息,会来处理一些心跳上报、集群管理命令等等。对于DataServer如果是要求强一致就使用TiKV,如果是要求低成本就使用Pika。
下面重点介绍一下proxy,proxy基于Go语言开发的,支持多种协议实现。现在支持KV和Redis协议以及结构实现。除此之外,还包括路由、KVsdk、限流、监控等模块。
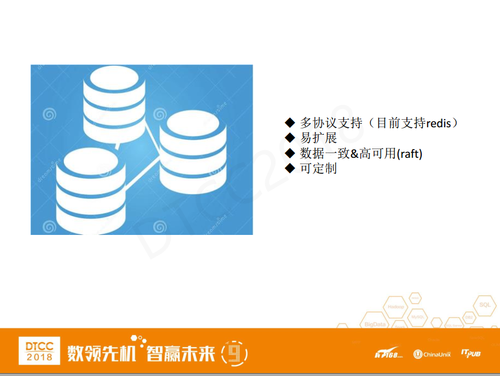
总体来说我们这个架构是基于开源,支持多协议,目前主要支持Redis协议;
易扩展,在底层采用TiKV时新节点加入集群,可以自动做到数据的均衡和数据的迁移;
数据一致性与高可用,采用Raft,能保证数据不丢;
可定制,我们可以根据不同的场景定制不同的功能需求和性能优化。

使用场景,主要使用在搜索、推荐,促销、智能调度,商品分类,排序等场景。从饿了么首页往下点,大概有80%的操作流程和KV有关,这些KV数据多是属性信息,比如用户画像、商品属性等等。

经过半年多的发展,我们现在有十几套集群分布在四个机房,线上数据已有几十TB,每天百亿级调用。某些集群高峰QPS大于10万,平均响应时间在1到2毫秒。
三.使用场景&问题

在这个过程中,我们遇到了很多问题,首先是上线之后,我们发现一些场景下key的Value特别大,达到几十K甚至上M,比如在用户画像。kv在这种value比较大的情况下性能损耗会比较大。我们的处理方式比较很简单,就是压缩。
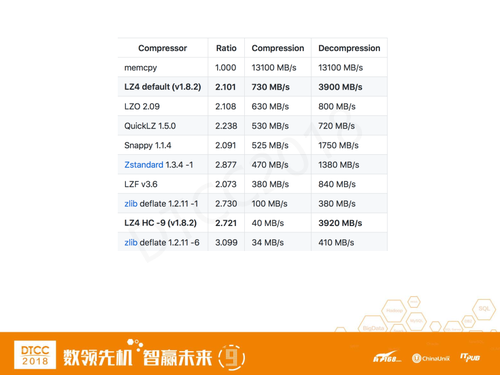
我们综合存储、IO、网络等因素做了一些测试,上图分别是高压缩比、低圧缩比和中压缩比的测试数据,通过对比,我们发现LZ4的效果最明显,虽然压缩率一般但是性能高。所以我们把它做到了proxy,从进入系统开始就压缩,使得整个链路包括中间Raft协议的几次传输,代价更小。 通过加压缩,一些场景性能提高了50%。

另一个问题是跨机房操作慢,饿了么已经做了异地多活,大多数情况下都是读本机房的数据,但个别场景需要跨机房来操作数据,延迟很大,比如北京上海之间延迟时间达到20到30毫秒。我们的解决方法是pipeline。
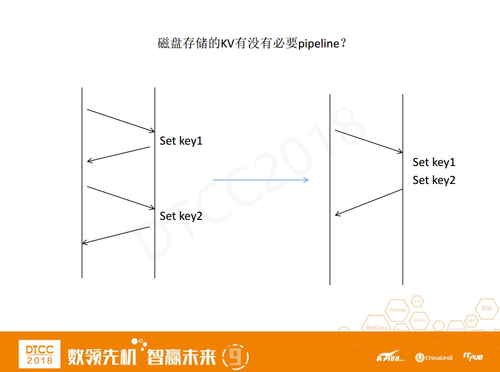
我们采用了批量加并行的优化手段,类似于Redis的pepiline,如图左边显示set key n次请求有2n次网络传输,我们将多个set 操作打成一个batch 只需2次网络传输。通过减少中间网络交互,性能提升效果明显,我们基于Go语言做的proxy,内部基于协程做了并行处理也提高了部分性能。

Hash多行操作超慢是实现方式的问题,我们将Hash结构分多行存储,原始Key和原始Feild拼成一个key,多个Field顺序存储。
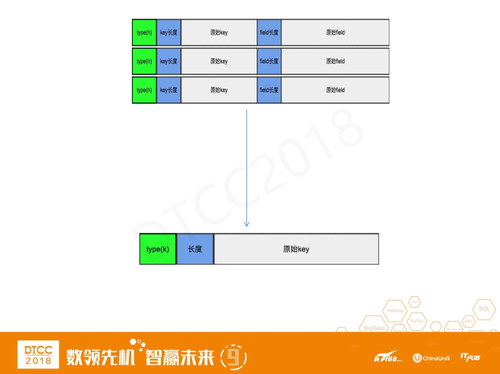
涉及成百上千行数据的多行操作,需要扫描很多行,性能损耗较大。我们做了取舍,把Hash只用一个Key来存储,这样只要这个Hash小于1M且Key的 数量不多的话,性能提高效果明显。

除此之外,还遇到一个问题——加ttl以后性能损耗比较大。加ttl其实就相当于Hash加了一个metakey,metakey里面存在Hash超出时间戳,读的时候拿时间戳做校验。(内部用定时任务清理过期Key)。但这样做会多一次读取校验影响性能。

其实,很多场景并不需要严格的ttl校验或类型校验。我们做了场景化的优化,针对某些场景单独做开关,避免了meta的ttl验证。通过这种方式,性能比之前提高了30%。
四.总结&展望

我们的KV规划支持多协议,目前主要支持Redis协议。大多数开发同学对Redis比较熟悉,学习成本低。为了迅速的推广,我们优先支持Redis协议。之后我们会支持更多其他的协议。
TiKV容错能力很强,因为它底层采用的是Raft,一台机器挂掉,其他机器会选主,继续提供服务。从软件层协议实现上去解决一致性问题以及高可用问题。运维成本会降低。
我们准备做资源池化加全自动化运维,比如每次用户申请接入,他们只要提交一个工单,然后我们就调一下脚本,自动化把集群创建出来,并根据需求特性做不同的配置。有一个资源池,如果需要申请服务自动从资源池里提取、部署,如果集群下线或数据缩容的情况,就把它退回资源池。
异地多活,为了适应饿了么整体架构,我们也规划做到异地多活,多地之间的双向同步。

最后为大家分享下个人的总结和思考。
第一个是分布和均衡,在存储里面的数据分布是需要得多方考虑权衡的事情,例如选择那种数据分布方式?Hash还是Region?Hash在数据分布上更均衡Region存储方式利于顺序扫描,但不利于分布均衡,如果某个Region数据量越来越大,那么就需要Region分裂,如果某Region数据量随着数据删除数据量变小就需要合并。除了数据分布的均衡,还要考虑流量均衡,Hash天然就比较均衡,而Region则需要做一些特殊处理来做到均衡,如果写顺序写入会存在热点写问题。总体来看,Region分布的成本更高一点。故障隔离,隔离有好多等级,比如节点级、机架级、机房级等。如果分布的越散,这个系统的可用性越高,如果越集中,性能越高,所以都得综合考量,在性能和高可用之间做选择。
实现成本和运维成本,在分布式存储里实现Raft,开发测试成本很大,但是运维成本降低,集群容忍单机故障,软件层面能自动容错。使用Pika等单机存储,我们需要自己做集群管理、主从,用哨兵等方式来做监控,这样的方式自己部署的组件较多,运维成本比较大。我们直接使用了比较牛的开源组件,效果不错。不过以后肯定会遇到更多底层问题,这就需要我们投入更大的成本来解决问题。
轮子这么多为什么还要造?我们拿到了一个开源组件,想要它适合我们的技术体系、业务场景,需要做很多打磨。一些开源产品在大规模商用场景下,运维成本比较高。自己造轮子能从中需积累专业底层经验,总结最佳实践,优化性能和资源。更大限度提高稳定性优化资源 。
最后我们要感谢开源,开源产品充实我们的技术力量,帮我们降低成本、提高效率。