1、原理解释
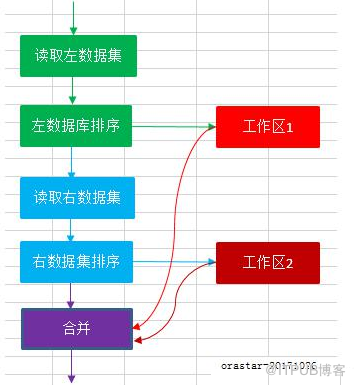
2、Merge Join特点
1、每个子节点只会执行一次
2、每个输入数据集都必须按照连接条件的字段进行排序
3、由于排序操作,在返回第一条结果前,两个数据集都必须被完全读出并排序。
3、 适用场景
Merge Join将两个表排序,然后将两个表合并。通常情况下,只有在以下情况发生时,才会使用此种JOIN方式:
1.RBO模式
2.不等价关联(>,<,>=,<=,<>)
3.HASH_JOIN_ENABLED=false
4.数据源已排序
4、Merge Join示例
SQL> select /*+ ordered use_merge(a)*/c.cons_no,c.cons_name,a.AMT_YM,a.amt
from ht.c_cons_hash c,ht.a_amt_hash a
where c.cons_no=a.cons_no
and c.cons_name='Hash_Join'
order by 1; 2 3 4 5
Execution Plan
----------------------------------------------------------
Plan hash value: 1313733800
--------------------------------------------------------------------------------------------------------------
| Id | Operation
| Name
| Rows | Bytes |TempSpc| Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT
|
|
12 |
360 |
|
401 (1)| 00:00:05 |
| 1 | MERGE JOIN
|
|
12 |
360 |
|
401 (1)| 00:00:05 |
| 2 | SORT JOIN
|
|
2 |
26 |
|
4 (25)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| C_CONS_HASH
|
2 |
26 |
|
3 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN
| IDX_C_CONS_HASH_NAME |
2 |
|
|
1 (0)| 00:00:01 |
|* 5 | SORT JOIN
|
| 59968 |
995K|
3320K|
397 (1)| 00:00:05 |
| 6 | TABLE ACCESS FULL
| A_AMT_HASH
| 59968 |
995K|
|
65 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("C"."CONS_NAME"='Hash_Join')
5 - access("C"."CONS_NO"="A"."CONS_NO")
filter("C"."CONS_NO"="A"."CONS_NO")
5、三种连接方式比较
NL: 从一张表中读取数据,访问另一张表(通常是索引)来做匹配,nested loops适用的场合是驱动表行数较小时,效率会更高。
Hash join: 将一个表(通常是小一点的那个表)对连接键做hash运算,将Hash结果做为索引值和行信息存储到Hash表中,从另一个表中抽取记录,对连接键做hash运算,到Hash表中查找匹配的行。
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配,因为merge join需要做更多的排序,所以消耗的资源更多。 通常情况下,Hash Join会比
Merge Join性能更好。
6、参数文档
《Oracle? Database Performance Tuning Guide 11g Release 2 (11.2)》
《Troubleshooting Oracle Performance》