本文转载自微信公众号“ 标哥说天下”(ID:bgstx001),作者:李宗标。
本文仅仅涉及 IPv4 和MPLS 网络(以下简称 IP/MPLS)的 QoS,不会涉及其他网络。另外,本文期望从基本概念与原理入手,而不是深入到具体的网络协议细节和算法细节,能给出一个浅显易懂而又不失其本质的 QoS 讲述,使您能比较轻松地掌握 QoS 基本知识。
由于笔者水平有限,难免挂一漏万,即使限定在 IP/MPLS,笔者仍然觉得本篇文章不够全面。笔者争取后面再写两篇文章,一篇是 QoS 综述,另一篇是QoS 的网络协议和算法,分别从宽度和深度两个角度来探讨 IP/MPLS 的QoS 体系。
这一篇,就让我们 Happy 一下吧——希望能给您带来快乐!
一、从用户体验看 QoS
网络不生产内容,它只是内容的搬运工。网络的运营者,比如中国移动等,称为互联网服务提供商(ISP,Internet Service Provider)。既然是服务提供商,那就得讲究服务质量。在这个层面,DaaS(东莞就是服务)曾经是服务行业中的质量的典型代表。非常遗憾,这个典型代表已经被当作典型给那啥了。
在网络从业人员的口中,QoS(Quality of Service,服务质量)专指网络的服务质量。
在早期,网络上传输的一般是数据业务,比如文件传输,email等,这些业务对 QoS 的要求一般就是网络带宽(更专业一点的术语叫网络“吞吐量”)和可用性(不能动不动就断网)。
现在网络上传输的业务是丰富多彩,比如语音、视频、网游等等,这些业务除了对带宽、可用性有要求以外,还对网络的时延、丢包、抖动有严格的要求。
对于语音而言,当时延超过300毫秒时,交互式会话(双方打电话)会变得非常麻烦,一方会以为另一方没有说话。

延时太大,接听方会以为说话方没有说话
抖动是时延的变化。A 匀速对 B 说“XYZ”三个字母,如果三个字母的时延相同,比如都是100ms,那么 B 听到的声音也是匀速连贯的,虽然有时延。但是如果三个字母的时延分别是50ms、200ms、150ms,B 所听到的声音就会产生不连贯的效果。

由于抖动,说话者和接听者所感受到的断句是不同的。丢包对于语音来说,也不可接受,比如“XYZ”传到 B 那里,由于丢包的原因,夸张点说,会变成“XZ”,中间漏了一个“Y”。对于视频来说,丢包会产生马赛克,非常影响视频体验。
总的来说,各种应用对于 QoS 的要求,可以总结为表1所示:
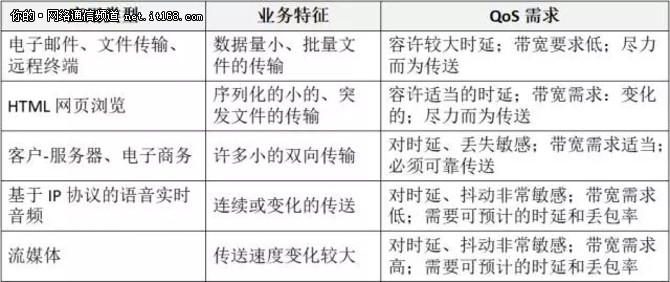
表1:各种应用对 QoS 的要求
表1仅仅是一个概括性的表述,不能当做绝对真理。比如文件传输,当然也是希望带宽越大越好啊。

永远不要忽略一辆卡车的带宽
产生时延的因素很多,主要包括编码、包化、队列、串行化、和传播时延等。模拟信号(比如声音)要被编码成数字信号,需要时间,这就是编码时延。数字化以后,还需要打成 IP 报文,这个时间就是包化时延。路由器在传输 IP 报文时,需要将报文放置到各个队列中然后调度,这其中所花费的时间就称为队列时延。报文被调度发送时,可能会等待上一个大报文先发送出去,这个等待时间就是串行化时延。这些时延,可以随着技术的进步而优化减少,但是传输时延则是无论如何也无法减少的,因为传输速度不能超过光速。光速1秒钟30万公里,那么300公里1ms的时延,是无论如何也减少不了的。

传输时延是无法避免的
本文讲述的是 IP/MPLS 的 QoS,所以下文会重点讲述队列时延。实际上,丢包也与队列有着密切的关系,下文会一并讲述。
二、IP/MPLS 协议对 QoS 的标记
如果网络带宽无限大,网络转发无限快,那么抛开前文所说的“编码、包化”不谈(不是本文主题),网络的时延(包括丢包、抖动)除去无法克服的传输时延以外,就会等于0,一切都很美好。
可是,这是不可能的,最起码目前来看,是不可能的。这就存在竞争的问题:不同的业务流对有限的网络资源的竞争问题。
在这个竞争中,网络对于各个业务流是否公平对待呢?答案是否定的。既然不是公平对待,那么网络是如何做到厚此薄彼的呢?这就涉及到网络整体的QoS 解决方案。本小节首先讲述这个解决方案中很重要的一环:IP/MPLS 协议对 QoS 的标记。
所谓标记,就是让网络知道一个业务流是重要还是不重要。在人类社会,要想被别人喜欢,男人靠事业,女人靠事业线。在网络社会,却没有这一套,要想让路由器知道你很重要,必须得有所标记。IP/MPLS 中不同的协议,对QoS 的标记有所不同,下面我们逐一讲述。
1、IP 报文对 QoS 的标记:IP 优先级(IP Precedence)
在 IP 报文里,IP 优先级(IP Precedence)位于 IP 报文头中的 ToS 字段,如图1所示:
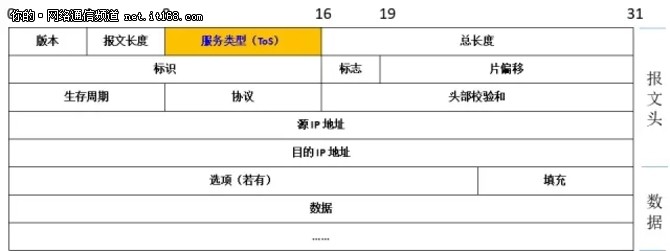
图1:ToS 在 IP 报文头中的位置
ToS 的字段长度是8 bits。根据RFC1122的定义,IP优先级(IP Precedence)使用最高3比特,可以定义8个服务等级。第3到第5比特由RFC791定义,后来RFC1349又扩展到第6位,3~6为比特被称为称为DTRC(Delay,Throughput,Reliability,Cost)位,。最后1比特必须为0(Must Be Zero)。如图2所示:

图2:ToS 字段的定义
IP优先级占用 ToS 最高的3个bit,一共可以取8个值,这8个值的含义,如表2所示:
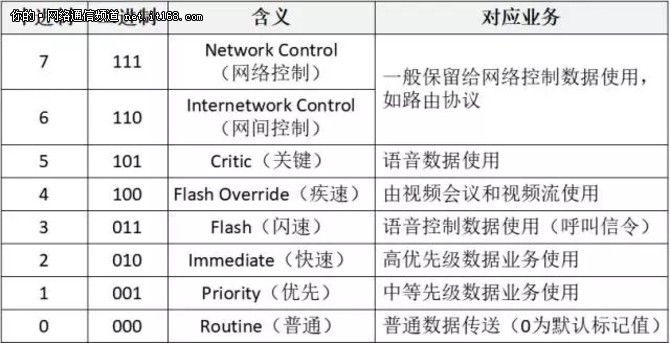
表2:IP 优先级的含义
DTRC(Delay,Throughput,Reliability,Cost)位,忙活了半天,一会3个bit,一会4个bit,但是并没有什么卵用,QoS 并没有采用它,不过我们还是列举一下它的含义吧。第3到6比特的含义如下:
0000--normal service
1000--minimize delay
0100--maximize throughput
0010--maximize reliability
0001--minimize monetary cost
2、IP 报文对 QoS 的标记:DSCP(Diffserve Codepoint)
ToS 字段一共8个bit,IP 优先级只使用了其中3个bit,一共只能定义8个优先级(QoS 没有采用 DTR),这似乎少了一点。RFC2474重新定义 IPv4报头中ToS 字段,它使用了高6为bit,后2位保留,如图3所示:

图3:DSCP 的定义
RFC2474 把高6为称为差分服务代码点(DSCP,Differentiated Services Code Point)。简单理解,DSCP 也是表示优先级,由于使用了6个bit,可以表达64个优先级。
64个优先级,是对原来的8个优先级的一种细化,不是颠覆,所以它们之间有一定的对应关系,如表3所示:
表3:IP 优先级与 DSCP 的对应关系

当然,提出 DSCP 的概念,绝不是为了与 IP 优先级有一个对应关系,而是为了对 IP 优先级的细化。由于 DSCP 优先级有64个,数字太多,不好记忆,于是 DSCP 还有另外一种表达方法,方便人的阅读和理解。(个人观点,64个其实不多,多一种表达方法,多一种概念,增加了人们的学习成本,其实不太好)
DSCP 的数值 0~63,分为四类,如表4所示:
表4:DSCP 的含义
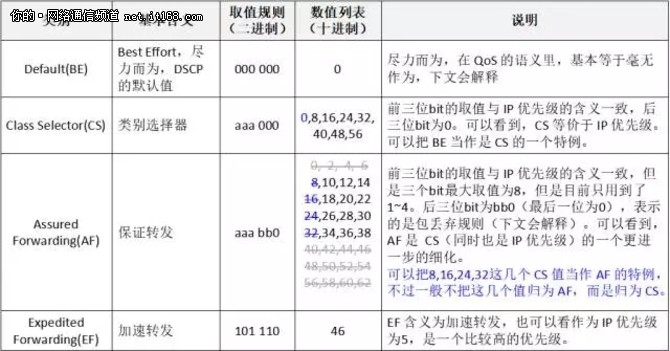
可以看到,DSCP 虽然取值范围是0~63,但是实际上只使用了24个值。
有一个快速理解 DSCP 的方法:(虽然是快速理解,但是还需要仔细阅读)
(1)如果 DSCP 为0,则为 BE;如果为46,则为 EF。
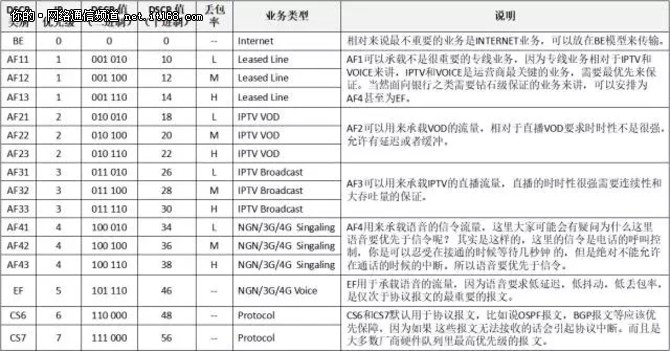
(2)将 DSCP 的值,除以8,其商为服务优先级(对应IP 优先级),如果其余数为0,则为 CS,记作 CSn(n为商),比如24,记作CS3。
(3)将 DSCP 的值,除以8,其商服务优先级(对应IP 优先级),如果其余数不为0,则为 AF。余数为2、4、6,分别表示丢包优先级为Low、Middle、High,用数字1、2、3表示。整体记作 AFmn(m为服务优先级,n为丢包优先级)。比如 DSCP = 34,记作 AF41。
DSCP 的数值与 IP 优先级以及其所适用的业务类型,如表5所示:
表5:DSCP 与 IP 优先级的对应关系及适用的业务类型
3、802.1P 对 QoS 的标记:Priority
IEEE 802.1P 是一个有关 LAN 二层的流量优先级的 QoS/CoS() 的协议(LAN Layer 2 QoS/CoS Protocol for Traffic Prioritization )。802.1P 是 IEEE 802.1Q (VLAN 标签技术)标准的扩充协议,它们协同工作。IEEE 802.1Q 标准定义了为以太网 MAC 帧添加的标签。VLAN 标签有两部分:VLAN ID (12比特)和优先级(3比特)。 IEEE 802.1Q VLAN 标准中没有定义和使用优先级字段,而 802.1P 中则定义了该字段,如图4所示:
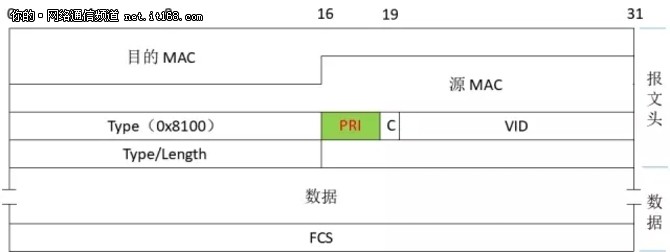
图4:802.1P 中的优先级
802.1P 定义的优先级(Priority)位于 802.1P 的报文头中,占用3个bit,一共可以表示8个优先级。最高优先级为7,应用于关键性网络流量,如路由选择信息协议(RIP)和开放最短路径优先(OSPF)协议的路由表更新。优先级6和5主要用于延迟敏感(delay-sensitive)应用程序,如交互式视频和语音。优先级4到1主要用于受控负载(controlled-load)应用程序,如流式多媒体(streaming multimedia)和关键性业务流量(business-critical traffic)。优先级0是缺省值。
我们可以把802.1P 定义的优先级简单理解为 IP 协议中的 IP优先级(IP Precedence)。另外,以太网(比如 802.1P)中一般说CoS(Class of Service,服务等级),这个与 QoS 还是有所不同,这里我们不做这个方面的细究,也简单理解为一个意思。
4、MPLS 对 QoS 的标记:Experimental
MPLS 对 QoS 的标记,使用的是 MPLS 头部的 Experimental 字段,这个字段占有3个 bit,虽然号称是实验字段,但是一般被 MPLS 用作 QoS/Cos 的标记,如图5所示:
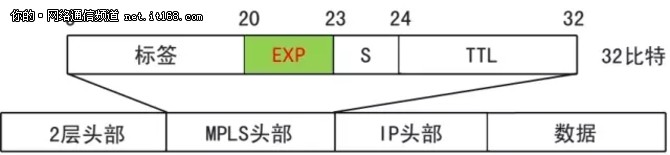
图5:MPLS 中的 Experimental 字段
MPLS 的 EXP 字段占用3个 bit,能够表达8个优先级,我们也可以将其简单理解为与 IP优先级(IP Precedence)是对等的。但是这样不够准确,更准确的理解应该是与 IP 的 DSCP 相对应。不过 DSCP 最多等表达64个优先级(实际使用了24个),而 MPLS 的 EXP 却只能表达8个优先级,这是 MPLS 的退化还是另有玄机呢?答案是后者(另有玄机),具体的描述我们放在后面再介绍。
5、IP/MPLS 协议对 QoS 的标记的小结
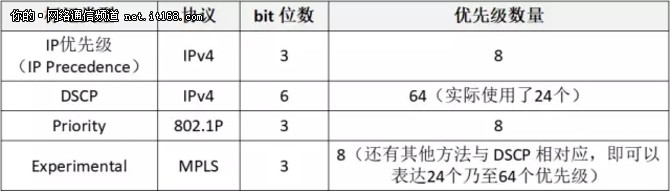
我们介绍了 IP/MPLS 协议对 QoS 的标记,由于 VLAN 是一个非常普遍使用的协议,所以我们也介绍了 802.1P 对 QoS 的标记。它们的小结,如表6所示:
表6:IP/MPLS 协议对 QoS 的标记的小结
通过以上介绍,我们知道:从 A 发往同一个地方(比如 B)的两条流,由于两者的业务类型不同,赋予它们的优先级也会不同。网路针对这两条流,会采取不同的转发策略,从而有可能使两者的 QoS 会有很大的不同。优先级低的流,不仅有可能时延会相对变大,还有可能会丢包。网络中的流如果有感情的话,不知道它们会怎么想!
说好一起到白头,你却偷偷焗了油!网络偏爱焗了油的流,那么它是怎么偏爱的呢?
三、路由器的 QoS 模型
网络作为一个整体,它有一整套的 QoS 解决方案,在这个解决方案中,每一个路由器都有它的角色和行为。本节我们先介绍单个路由器的 QoS 模型,下一节再整体介绍网络的解决方案。
对于单个路由器而言,它针对 QoS 的行为包括如下几个方面:
(1)流的队列机制(含流分类与丢包机制)
(2)流的监管和整形机制
下面我们分别展开讲述。
1、流的队列机制
路由器并不是一根管子,业务流从这端流入,从那段流出,它总要做一些处理(具体是哪些处理,与本文主题无关,就不描述了)。为了做这些处理,业务流需要在路由器里呆一小段时间(很不幸,这一小段时间就产生了时延)。业务流在路由器所呆的空间,就是内存。把内存按照一定的规则分块,这些分块就称为队列。
什么样的流进入什么样的队列,不同队列中的流谁先被发送出去,如果队列满了,新来的流该如何处理,这些问题的答案都与路由器的流队列机制相关,也与 QoS 密切相关。一个路由器抽象的流队列机制,如图6所示:
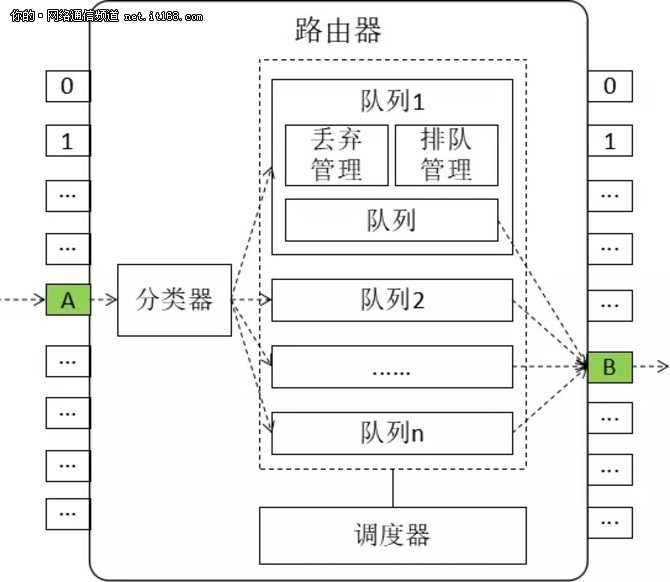
图6:路由器的抽象队列机制
为了易于描述和理解,图6简化了模型,仅仅是表达了从一个入口(A)到一个出口(B)的队列机制。
一个流从入口进入路由器后,在队列机制层面,会经过如下过程:
(1)首先经过流分类器。流分类器根据一定的规则,将流分配到不同的队列中。
(2)队列也不是无条件接收流分类器转过来的流,因为它自己如果队列满的话,也是无能无力。如果能够接纳流,则流还存在一个在队列中如何排队的问题(排队靠前的,会被先转发出去)。
(3)流进入队列以后,还得等待队列调度器调度。调度器也根据一定的规则,决定各个队列的流先后转发顺序。
(4)队列被调度以后,队列中的流会被从出口转发出去。
根据流分类规则、丢弃规则、调度规则等的不同,IP/MPLS 网络有FIFO、PQ、CQ、WFQ、CBWFQ、LLQ、IP RTP Priority 等几种队列,下面分别展开描述。
1.1、FIFO 机制
FIFO,First In First Out,先入先出队列。顾名思义,FIFO 队列就是“六亲不认”,管你是什么类型的流,管你有没有焗油,它根本就没有流分类器,它的调度器就是只管按照流到达的先后顺序,谁先来,谁先走,挥一挥衣袖,不挽留。FIFO 队列的示意图,如图7所示:
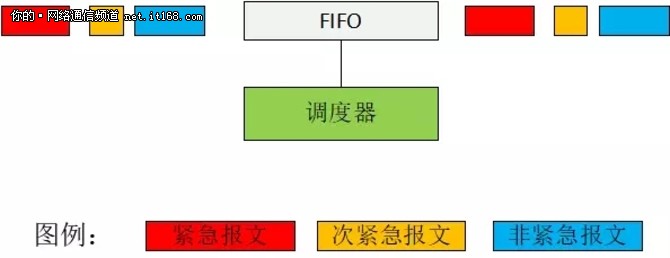
图7:FIFO 队列示意图
从图7可以看到,即使是紧急报文,它只要来晚了,也得老老实实在那排队,干着急也没用。
FIFO 队列采用尾丢弃策略(Tail-Drop polocy),即如果队列满了,那么后来的报文将被丢弃。
FIFO 非常简单,它的缺点,表面上看也是很明显的,对于时延敏感的报文,它并不能提供有效的保障。不过如此简单的 FIFO 却能给我们很多思考:(1)FIFO 在 QoS 层面,并不是一无是处,正是因为省略了流分类机制以及它的极简的调度机制,它反而还节省了处理时间,减少了时延。如果能在一个局域网内保证网络的能力,FIFO 反而有可能时最佳选择。
(2)公平从来不是简单的问题。表面上看,FIFO 讲究先来后到,好像很公平。但是即使不做深入探讨,即使只考虑现实生活中的“女士优先”、“紧急通道”等场景,我们就会发现如果只考虑先来后到,并不意味着就是公平。
不过无论如何,FIFO 这种六亲不认的表现,还是高度体现了一种二杆子精神。哥不扶墙,舅扶你!
1.2、PQ 机制
PQ,Priority Queuing,优先队列,从某种意义上说是对 FIFO 的一种纠正,不过好像有点用力过猛,矫枉过正。通过 FIFO 的描述我们知道,在当前网络的能力下(能力不足),FIFO 对于时延敏感的业务流,是不能提供有效的保障的。PQ 的使命,好像就是为了保证某些流的时延而生的。
PQ 的原理示意图,如图8所示:
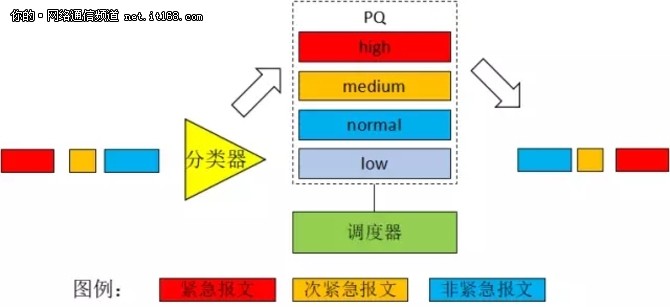
图8:PQ 原理示意图
PQ 将队列分为4种类型,分别是:high、medium、normal、low,优先级是由高到低。
PQ 的队列调度算法是:先从最高优先级队列 high 队列调度,待 high 队列里面的报文发送完毕以后,再调度 medium 队列,以此类推,最后调度 low队列里的报文。(如果在调度低级队列时,高级队列如果有报文来到,高级队列会抢占低级队列,先被转发出去)。
PQ 的队列分类算法,相对固定,而又有一定的灵活性。相对固定的意思是:如果是 IP 报文,无非是根据流的五元组(源IP地址、源端口、目的IP地址、目的端口、传输层协议)和 IP 优先级/DSCP 等字段将流进行分类;如果是MPLS 报文,就是根据 EXP 字段将流进行分类。有一定的灵活性是指:在这些分类条件中,用户可以选择其中一个或多个进行组合。
PQ 有4个队列,针对每一个队列内部,它仍然采取 FIFO 策略和尾丢弃策略。
可以看到,PQ 对于时延敏感的业务流,有着非常好的保障,只须把该类型业务流分类到 high 队列,它们就有着无法比拟的优势得到先发。但是,PQ 也有着非常明显的缺点,对于那些不幸排在 low 队列的流来说,可能永无机会被发送出去,产生所谓的“饿死”现象。这就是网络世界的“朱门酒肉臭,路有冻死骨”吧。
1.3、CQ 机制
CQ,Custom Queuing,定制队列。也许是觉得 PQ 有点过分吧,CQ 是对PQ 的一种改进。它的流分类机制,与 PQ 一样,只不过它提供了17个队列,可以分得更细。CQ 的原理示意图,如图9所示:
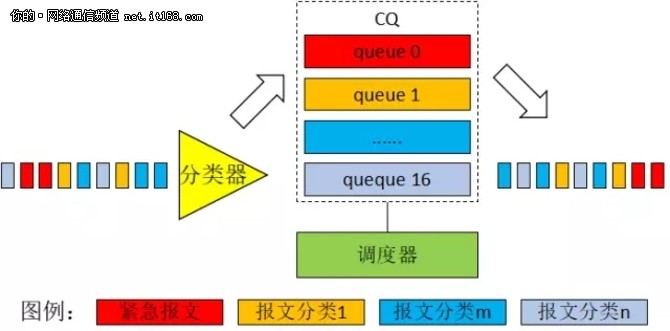
图9:CQ 原理示意图
CQ 是绝对优先调度队列0,待队列0调度发送完以后,再调度其他16个队列。所以,流分类时,一般是将路由协议报文分类到队列0。
对于其他16个队列,CQ 是按顺序按比例循环调度发送。按比例的意思是将每个队列分配一定的带宽比例(严格地说,不是带宽,而是字节数。这里用带宽来类比,是为了易于描述和理解),比如队列1分配2M,队列2分配3M......,那么队列1调度发送1M的报文后,就会转而调度队列2......以此类推。
CQ 有17个队列,针对每一个队列内部,它仍然采取 FIFO 策略和尾丢弃策略。
CQ 从某种意义上说,解决了 PQ 的极端不公平的“饿死”现象,不过这不是绝对的。因为 CQ 中每个队列的比例,是可以自由配置的,比如把队列1配置为1000,队列16配置为1,其他队列配置为100,那么队列16也是很大概率会“饿死”。
可以这么理解,CQ 比 PQ 的分类更细,调度原则更灵活一点,但是仍然可能会存在“分配不公”的现象。当然,所谓分配不公,是人类对网络业务流的一种“拟人”的说法,在实际应用中,如果网络资源不够,必须有所取舍的时候,那就不是所谓的公平的问题,而是丢卒保车的问题。如何丢卒保车?你的地盘你做主!
1.4、WFQ 机制
WFQ,Weight Fair Queuing,加权公平队列。WFQ 最大的特点还不是“加权公平”这几个字,而是它不允许用户通过 ACL 对流进行分类(前文介绍的几个队列机制,都是由用户自己对流进行分类),而是它自己分类。
当然,WFQ 的流分类原则,也没有什么特殊的,无非还是五元组之类的内容。但是,WFQ 是将一个流归结到一个队列,所以 WFQ 所需要的队列数量很多,它最多可以有4096 个队列。
WFQ 关于队列的调度策略,正如其名字所暗示的:Fair,公平;Weight,加权。首先不考虑加权,WFQ 对于每个队列(其实也就是每条流)的调度是公平的,也就是循环平等调度。然后再考虑加权,WFQ 考虑的是每个流的 IP 优先级的权重。它的计算方法是:
一条流的权重 = (该流的 IP 优先级 + 1)/ sum(所有流的优先级 + 1)。
正是这种加权、公平的思路,对 IP 优先级高的业务的时延有一定的保证,也能对优先级较低的业务,不至于“饿死”。
为了实现这个思路,WFQ 有一个算法,这个算法不复杂,不过笔者犹豫了半天,决定还是不介绍了,这对综合理解 QoS 没有多少帮助,反而还有点陷入细节。
WFQ 最多可以有4096 个队列,针对每一个队列内部,它仍然采取 FIFO策略。但是它的丢弃策略,所采用的不是尾丢弃策略,而是对尾丢弃的一种改进,我们称之为 WFQ 丢弃策略吧。WFQ 丢弃策略的算法与 WFQ 的调度算法强相关,这里也不再详细介绍,只须这么简单理解:当一个队列满的时候,它可以丢弃其他队列的报文(从而抢占该队列的内存空间)。这也是为了保证高优先级的业务质量。
1.5、CBWFQ 机制
CBWFQ,Class-Based WFQ。其实基于这个这个名字,反而不好理解。更直观,更好的理解方法是:把 CBWFQ 当作前面介绍的 CQ(Custom Queuing)的扩展版本。CBWFQ 的原理示意图,如图10所示:
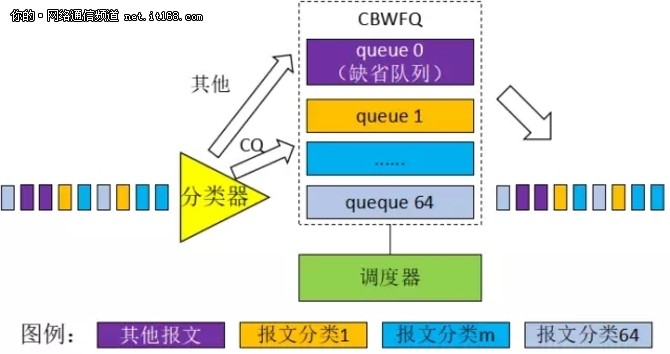
图10:CBWFQ 示意图
说 CBWFQ 是 CQ 的扩展版,是因为:
(1)两者的流分类方法是一样的,只不过 CQ 只有17个队列,而 CBWFQ有 65 个队列。CBWFQ 可以将流明确地分为64类,分别归入到队列1~队列64,然后再将其他所有的流归为队列0。
(2)CBWFQ 的65个队列,与 CQ 的16 个队列(队列1~队列16)的调度策略几乎是一样的:CQ 给每个队列分配字节数,CBWFQ 给每个队列分配带宽比。不看细节的话,这其实没有什么不同,两者都是给每个队列分配一定的比例。
不过,两者还是有一定的不同:
(1)针对每一个队列,CQ 都是 FIFO 和尾丢弃策略。CBWFQ 的 1~64 队列,必须是 FIFO,而队列0却可以是 FIFO 或者 WFQ。如果是 FIFO 的话,CBWFQ 的每一个队列都可以选择尾丢弃策略或者是 WRED 策略(WRED:Weighted Random Early Detection,先记住这个词,下文会解释其含义,这里暂时不纠结)。队列0如果选择 WFQ 的话,那么它的丢弃策略,当然也是 WFQ 丢弃策略。
(2)CQ 有一个队列0,一个绝对优先级的队列,可以为路由协议(也可以包括语音视频等)的转发服务,而 CBWFQ 没有这样一个明确的队列。
可以看到,CBWFQ 花了不少心思,将 CQ 和 WFQ 做了叠加,并且在丢弃机制上还引入了 WRED,但是好像失去了 CQ 和 WFQ 的精髓:
(1)CQ 有队列0,可以保证相关业务流的时延,CBWFQ 丢失了这个特性
(2)WFQ 是基于 IP 优先级的加权,也能在一定程度上保证相关业务流的时延,CBWFQ 也失去了,虽然它的队列0可以采用 WFQ 机制,但是相对于一共65个队列而言,那毫无意义。
1.6、LLQ 机制
LLQ,Low Latency Queuing,低时延队列。如果说不知道 CBWFQ 想干嘛,那么 LLQ 则用它的名字明确地告诉你它想干嘛!
严格来说,LLQ 并不是一个独立的队列机制,它是对 CBWFQ 的一种增强——是的,增强!
前文说过,CBWFQ 费了半天劲,吃力没讨好,逻辑复杂,却不能保证时延敏感的业务。LLQ 则是在 CBWFQ 的基础上增加了1个或多个优先级队列。这几个优先级队列之间,不再区分优先级,而是采用循环调度的方式。但是这几个队列相对于其他队列而言,则有绝对的优先级,与 PQ 类似,这几个优先级队列必须先调度转发。与 PQ 不同的是,LLQ 的这几个优先级队列设置了阈值,也就是说优先调度这几个队列,但也不是无限优先,它们被调度转发一定的数据包以后,就可以转发其他队列。这样能防止 PQ 机制所产生的“饿死”现象。
天下没有免费的午餐,如果要想保证其他队列不饿死,那么优先级队列就可能发送能力不足,从而产生丢包现象,这又与 LLQ 的初衷相违背。纠结......
1.7、IP RTP Priority 机制
IP RTP Priority 与 LLQ 一样,它的目的也是明确地写在名字上。为了解释这个机制,首先稍微解释一下 RTP。
RTP 全名是Real-time Transport Protocol(实时传输协议)。它是IETF提出的一个标准,对应的RFC文档为RFC3550(RFC1889为其过期版本)。RTP用来为IP网上的语音、图像、传真等多种需要实时传输的多媒体数据提供端到端的实时传输服务。RTP位于UDP之上,UDP虽然没有TCP那么可靠,并且无法保证实时业务的服务质量,需要RTCP(Real-time Transport Control Protocol,实时传输控制协议)实时监控数据传输和服务质量,但是,由于UDP的传输时延低于TCP,能与视频和音频很好匹配。因此,在实际应用中,RTP/RTCP/UDP用于音频/视频媒体,而TCP用于数据和控制信令的传输。RTP在端口号1025到65535之间选择一个未使用的偶数UDP端口号(端口号5004和5005则分别用作RTP和RTCP的默认端口号)。
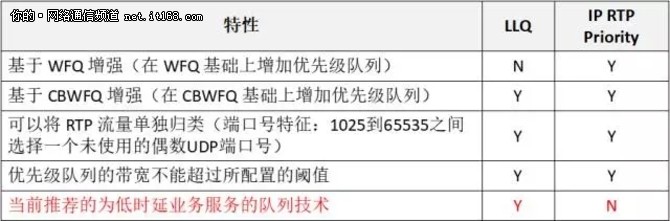
IP RTP Prioritization 与 LLQ 的机制也基本一样,有所不同的是,LLQ是基于 CBWFQ 的增强,而 IP RTP Priority 既可以基于 CBWFQ,还可以基于WFQ 进行增强。两者的对比情况,如表7所示:
表7:IP RTP Prioritization 与 LLQ 的对比
1.8、流的队列机制小结
前文一共介绍了7种流的队列机制,总结如表8所示:
表8:流的队列机制小结

可以看到,这些队列机制,除了 FIFO 有王之蔑视根本不管什么优先级不优先级的、CBWFQ 忙活了半天不知道干嘛的二哈之谜以外,其余的队列机制,基本上是为低时延业务操碎了心!
不过在网络资源有限的情况下,这些队列机制告诉我们:
公平是没有的,兼顾是不可能的!网络的世界,也是人类的世界!人类争夺有限的资源时,会有战争,会有杀戮!网络世界一样有杀戮。当网络拥塞时,报文就会被丢弃。
2、网络防拥塞机制:报文的丢弃
在前文讲述流的队列机制时,提到了丢弃策略,有的是尾丢弃(Tail Drop),有的是 WRED。
路由器丢弃过多的报文,是一个很正常的行为。队列,归根结底是一块块内存,总是有一定的大小范围,不可能无限大。当报文流入的速度大于流出的速度时,路由器的内存充满时,要么丢弃,要么内存溢出——造成死机。我想路由器只能选择丢弃。
唉,这么说,一下子把报文丢弃的逼格降低到地板以下了。高逼格的说法是:网络防拥塞机制。
不过,无论是低逼格说法还是高逼格说法,网络防拥塞的本质是丢弃报文。丢弃报文主要有几种策略:尾丢弃(Tail Drop)、WFQ 改进、RED(Random Early Detection)、WRED(Weighted Random Early Detection)。
尾丢弃策略比较简单和直观,就是队列满了以后,期望再进入队列的报文将被丢弃。WFQ 改进的丢包策略,前文说过,与 IP 优先级的加权有关,不过涉及到一点数学公式,本文不打算涉及到这些细节,只须简单理解为它是尾丢弃策略的一种改进,如果一个队列满了,它有可能丢弃其他队列的报文。WFQ改进的丢包策略,不是重点,我们点到为止。
本节重点介绍 RED 和 WRED。WRED 是对 RED 的一种改进,也是引入了IP 优先级作为一种加权。所以我们需要首先介绍 RED。
RED,Random Early Detection,直译为随机早检测。要想理解 RED,就得首先理解尾丢弃策略的问题。
网络中存在很多的TCP连接,这些连接中的报文段通常是复用路由路径。若发生路由器的尾部丢弃,可能影响到很多条TCP连接,如图11所示:
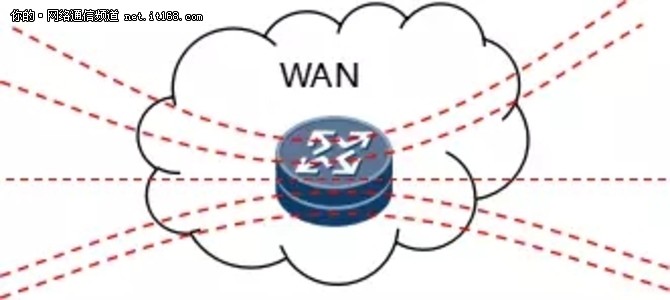
图11:多条 TCP 经过同一个路由器的示意图
尾丢弃策略所造成的结果就是这许多的TCP连接在同一时间进入慢开始状态。这在术语中称为全局同步。全局同步会使得网络的通信量突然下降很多,而在网络恢复正常之后,其通信量又突然增大很多。突然增大很多后,很有可能再次造成网络拥塞,然后再引发全局同步......周而复始,恶性循环。
RED 丢弃策略,就是为了解决尾丢弃策略所产生的“全局同步”问题而做的一种改进。简单地说,它不是等到队列满以后才开始丢弃,而是队列差不多的时候,就开始随机丢弃,这也是 RED -- Random Early Detection 这个名字的由来:提早检测、随机丢弃。
什么叫队列差不多呢?就是将队列设置两个门限(threshold):THmin、THmax。当队列的平均长度低于 THmin 时,所有报文都不丢球;当报文平均长度大于 THmax 时,所有新来的报文都丢弃;当报文平均长度介于 THmin 和 THmax 之间时,则概率性地随机丢弃一些报文,如图12所示:
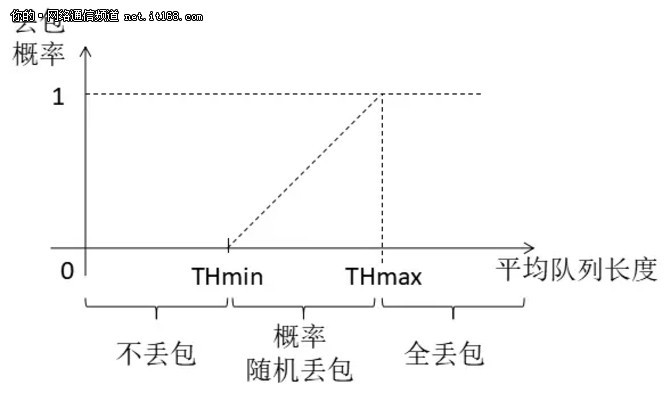
图12:RED 丢包策略示意图
前文提到了平均队列长度,这里我们只给出一个公式,而不再深究:
平均队列长度 =(以前的平均队列长度×(1-1/(2的n次方)))+(当前队列长度×(1/(2的n次方)))
其中n可以通过命令配置。队列平均长度既反映了队列的变化趋势,又对队列长度的突发变化不敏感,避免了对突发性数据流的不公正待遇。
RED 的精髓是“随机”,因为这个随机丢包,从而避免网络的全局同步。为了做到“随机”,则必须要提前。如果是等到队列满,那就不是随机了,而是全体相关的 TCP 连接同时被丢包了。
RED 比较有效地解决了网络全局同步的问题,但是它的随机丢包仍然是丢包,这对于语音、视频等业务流,仍然是会产生不好的影响。为了解决这个问题,一个是要慎重考虑是否要引入 RED 机制,另一个是对 RED 做改进(当然改进以后,仍然要慎重考虑,毕竟有些东西失去了,就再也回不来了)。
对 RED 的改进方法,就是引入权重,这也是 WRED 名称的由来。引入什么权重呢?IP 优先级(或者 DSCP)!
RED 为了避免网络的全局同步而引入了随机丢包,随机不是目的,目的是使多个 TCP 连接错开时段丢包,而不是同时丢包。如果能先丢低优先级报文的包,后丢高优先级的包,一个是能缓解高优先级丢包的概率,还有一个很可能由于低优先级的包丢过以后,网络拥塞程度缓解了,高优先级的报文就不需要丢弃了。
所谓 WRED,其实也很简单直接,那就是将高优先级报文的 THmin 设置的比低优先级报文的 THmin 要大,让低优先级的报文先被丢弃,如果13所示:
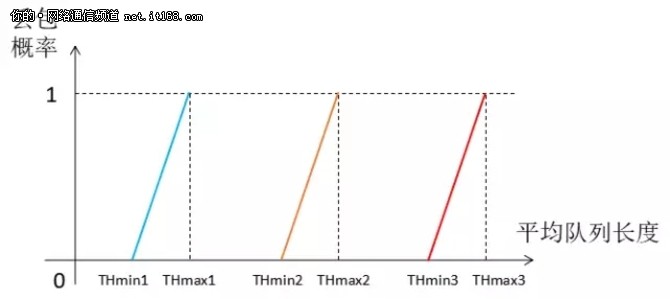
图13:WRED 原理示意图
WRED,总结为一句话就是:你丑你先睡,我美无所谓!
3、流量监管和流量整形
报文的丢弃机制,无论是为丢弃,还是 RED,或者是 WRED,都是在网络拥塞时,一种队列丢弃机制,但是这种丢弃是不是有点憋屈?为什么这么讲?因为为了丢弃一个报文,做了太多的工作,最后不过是丢弃报文而已。有没有一些场景可以简单粗暴地直接将报文丢弃呢?
一种场景是:明知不可为,那就不为!如果一个路由器的处理能力是 2M/秒(只是打个比方,不必纠结这个数字),而入口带宽是 3M,那还纠结个啥,直接先丢掉 1M 再说。
当然,还有一种情况更加直接。你花了100元钱购买了 100M的带宽,结果发送速率是 200M/秒,那不丢你丢谁?你真是想得美,你当运营商是傻子啊?
当然网络中报文的发送并不能保证是匀速的,有时候也会突发。如果偶尔的突发,都会被丢弃,那么这个网络显得有点不太友好。所以网络也需要具有容忍短时突发报文的能力。
在报文进入流分类器之前,对带宽过大的报文进行丢弃(或者打标记)的行为成为流量监管,对报文进行一定的缓冲和平滑处理,叫作流量整形。当然,在报文流出路由器时,也可以做流量监管和流量整形,这没有绝对应该在哪里做,不应该在哪里做。
从命运把握在自己手里的角度来讲,不管别的路由器有没有做,只要是进入自己的流量都做一下流量监管或者整形,乃是一个完全之策。
不过需要澄清的是,并不是每一个路由器都需要这么做,一般在网络的边界路由器上做如此动作即可。网络边界上的路由器,像一个个门神,把好网络的大门,限制好进入网络的流量,网络内的路由器就可以安心地做个美男子了。当然,这也不绝对。具体如何配置,还需要看实际网络的情况。
无论是流量监管还是流量整形,都用到了令牌桶算法,本文一如既往,不深究算法本身,点到为止,只要能把监管和整形基本讲明白即可。
3.1 流量监管
流量监管(traffic policing)的典型作用是限制进入或流出某一网络的某一连接的流量与突发。在报文满足一定的条件时,如果某个连接的报文流量过大,流量监管就可以对报文采取不同的处理动作,如丢弃报文或者重新设置报文的优先级等。通常的用法是使用 CAR 来限制某类报文的流量。
CAR(Committed Access Rate,承诺访问速率),首先对报文进行分类,然后:
(1)有的报文不需要监管(哪种报文需要监管,是由用户配置),那就直接转发(中间还会经过入队列、调度,然后才是转发);
(2)有的报文需要监管,则会分为3种情形:
(A)直接转发——对评估为“符合”流量规定的报文继续正常转发。
(B)直接丢弃——丢弃“不符合”流量规定的报文。
(C)修改报文优先级后再转发——对评估结果为“部分符合”的报文,将之标记为更低优先级别的流后再进行转发。
CAR 的基本原理图,如图14所示:
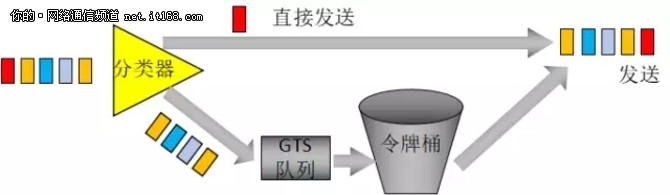
图14:CAR 基本原理示意图
报文做了 CAR 以后,其流量效果,如图15所示:
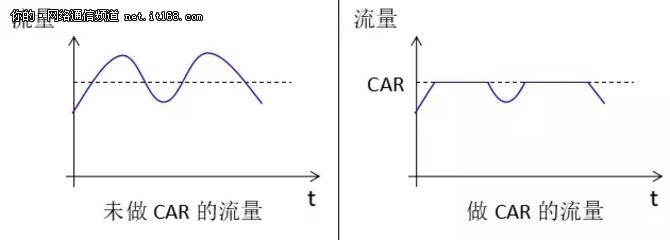
图15:CAR 的效果示意图
3.2 流量整形
流量整形(traffic shaping)的典型作用是限制流出某一网络的某一连接的流量与突发,使这类报文以比较均匀的速度向外发送。流量整形通常使用缓冲区和令牌桶来完成,当报文的发送速度过快时,首先在缓冲区进行缓存,在令牌桶的控制下,再均匀地发送这些被缓冲的报文。
流量整形的效果,如图16所示:
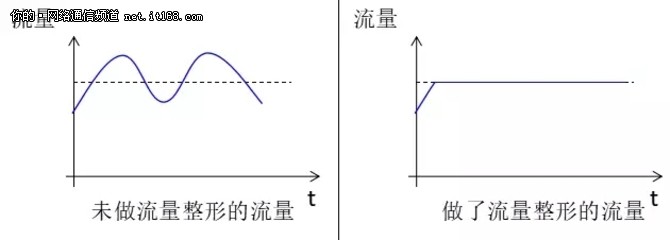
图16:流量整形效果示意图
流量整形通常采用的技术是 GTS(Generic Traffic Shaping,通用流量整形),GTS 的基本原理示意图,如图17所示:
图17:GTS 的基本原理示意图
4、物理接口总速率限制
物理接口总速率限制,英语是 Line Rate,简称 LR。严格来说,LR 也是流量整形的一种技术。不过,无论是 CAR 还是 GTS,都是在 IP 层实现(也说明了,不是 IP 的报文,这两者也不起作用),而 LR 则是在物理接口层面进行限制。
LR 可以在一个路由器的物理接口层面限制接口发送报文的总速率(包括紧急报文)。LR 的处理过程仍然采用令牌桶进行流量控制。如果用户在路由器的某个接口上配置了 LR,规定了流量特性,则所有经由该接口发送的报文首先要经过 LR 的令牌桶处理。如果令牌桶中有足够的令牌可以用来发送报文,则报文可以发送。如果令牌桶中的令牌不足,则报文进入 QoS 队列等待下一次发送机会。
LR 相较于 GTS 的区别是,LR 进入的等待队列是 QoS 队列,所以队列调度机制更加灵活。LR 的基本原理,如图18所示:
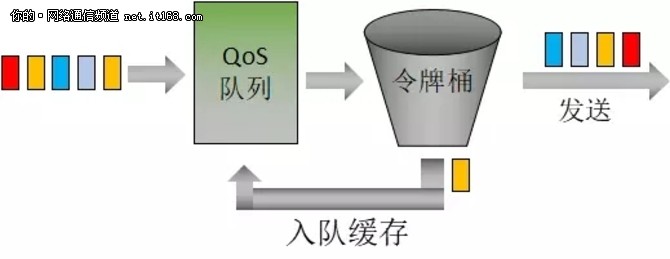
图18:LR 基本原理示意图
5、路由器 QoS 模型的小结
哎呀,终于写到小结了,可把我累坏了,有点瞌睡了,赶紧照照镜子。
对于单个路由器来说,实施 QoS 的方法,有如下几点:
(1)基于业务的分析与报文标记:QoS中的几乎所有控制手段都是基于对业务的分类,及不同业务流的标记。
(2)多种方法结合使用:预防策略——LR、CAR、GTS、RED、WRED;调度策略:各种队列调度方案。
路由器的 QoS 模型,如图19所示:
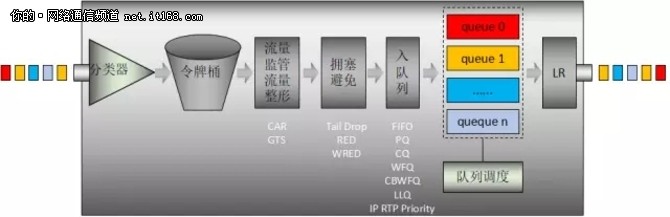
图19:路由器的 QoS 模型
路由器的 QoS 模型比较复杂而且全面,但是同时我们也必须要认识到QoS 策略的局限性和副作用:每一种策略都会消耗设备的系统资源,导致设备的总体性能下降;并非使用了QoS就可以高枕无忧,可能设备异常繁忙导致无法处理配置的各种策略。
天下武功,唯富不破。最有效的QoS手段是增加带宽和提高设备的处理能力。
四、IP 网络 QoS 解决方案
上一节介绍了单个路由器的 QoS 模型,那么网络作为一个由多个路由器(也包括交换机等其他设备),它是如何构建一个端到端的解决方案呢?
提到端到端,忽然间开始想念一位印度朋友。在过去的一年,我们一起做开源工作,我用蹩脚的英语教会了他流利地说出中文“端到端”。当然,不是我教的好,而是他的语言天赋比较高。
好吧,不感慨了,回到本文主题。网络的 QoS 解决方案,有三种模型:
(1)Best-Effort service,尽力而为服务模型。
(2)Integrated service,综合服务模型,简称Intserv。
(3)Differentiated service ,区分服务模型(有时候也翻译为差分服务模型,这个翻译显得逼格高一点,^_^),简称Diffserv。
下面我们分别介绍这三种模型。
1、Best-Effort service
Best-Effort service 是一个单一的服务模型,也是最简单的服务模型,应用程序可以在任何时候发出任意数量的报文,而且不需要事先获得批准,也不需要通知网络。对 Best-Effort 服务,网络尽最大的可能性来发送报文,但对时延、可靠性等性能不提供任何保证。 Best-Effort 服务是现在Internet的缺省服务模型,它适用于绝大多数网络应用,如 FTP、 E-Mail 等。其实Best-Effort 并非是什么 QOS,就是互联网的简单数据传输方式而已,有什么传什么,阻塞也就阻塞了,丢且也就丢弃了。
写到这里,免不了有感慨一下。一个人会不会说话,真的很重要。Best-Effort,明明是啥也没干,却说自己是尽力而为!唉,这逼装得也是没谁了!
2、Integrated service
Intserv,集成服务模型,可以满足多种 QoS 需求。这种服务模型在发送报文前,需要向网络申请特定的服务。应用程序首先通知网络它自己的流量参数和需要的特定服务质量请求:包括带宽、时延等。应用程序一般在收到网络的确认信息,即确认网络已经为这个应用程序的报文预留了资源后,才开始发送报文,同时应用程序发出的报文应该控制在流量参数描述的范围以内。
网络在收到应用程序的资源请求后,执行资源分配检查,即基于应用程序的资源申请和网络现有的资源情况,判断是否为应用程序分配资源,一旦网络确认为应用程序的报文分配了资源,则只要应用程序的报文控制在流量参数描述的范围内,网络将承诺满足应用程序的 QoS 需求。
在IntServ服务模型中,负责传送 QoS 请求的信令是RSVP(Resource Reservation Protocol,资源预留协议),它通知路由器应用程序的 QoS 需求。RSVP 是在应用程序开始发送报文之前来为该应用申请网络资源的。
Intserv 实际上是一种对服务的预定机制,通过申请来获取相应得服务,这里面主要依靠的就是RSVP。
RSVP,我们不深入介绍它的协议细节(那又是洋洋洒洒一大篇文章,以后有时间再写吧),只是简单画个示意图吧,如图20所示:

图20:RSVP 示意图
图20中,发送方沿着发送路径请求网络资源(带宽2M),从接收方开始,沿着路径回去,沿途各个路由器表示同意(它们通过计算,发现自己可以满足这个带宽需求),一直传递到发送方。这样发送方就可以愉快地玩耍了:按照2M的带宽约定,进行报文发送。
Intserv/RSVP 看起来很美好,然并没有什么卵用。因为 Intserv 是基于每条流的。想一想 WAN 网络上有多少条流,再想一想 WAN 网络上这些流是动态变化的......Intserv 所面临的是一个不可能的任务。
所以虽然 Intserv/RSVP 发展迅速,但是到目前为止,并没有在任何一种网络上得到证实,它的应用只局限在小的测试的 Intranet 上。
3、Differentiated service
看到 Differentiated service,很自然地就会想到DSCP(Differentiated Services Code Point)。没错,DSCP 就是为Diffserv(Differentiated service)服务的。不过我们暂时先忘记 DSCP,先看看Diffserv 的架构,如图21所示:

图21:Diffserv 架构示意图
图21中,由于执行策略的不同,整个网络被划分为不同多个 Diffserv 域(DS 域,图中画出了2个)。为了简化模型和易于理解,关于 DS 域我们点到为止,不再描述也不再纠结这个概念,就当作只有一个 DS 域。
在 DS 域中,路由器分为两种角色,一种是边缘节点(图中的A、B、C、D),另一种是内部节点(图中的 X、Y、Z),也叫核心节点。两种角色的行为是不一样的,这个下文会描述。
要想实施 Diffserv,首先需要运营商和用户之前签订一定 SLA 合同,这既是商业的基础,也是 Diffserv 的技术基础。这里我们不谈商业,只谈技术。从技术角度来说,意味着不同的类型的业务,其所对应的 IP 报文的 DSCP 就可以定义下来。
这个非常关键。当用户的业务流发送到 DS 的边缘路由器时,边界路由器的行为有:流量监管、整形、分类标记、队列调度(含丢弃)。其中流量的监管和整形,就是我们前文介绍的内容,可以采取 CAR、GTS 等技术完成。流量的分类标记,就是根据 SLA 协议,给 IP 报文的 DSCP 赋值!给 IP 报文的DSCP 赋值!给 IP 报文的 DSCP 赋值!重要的事情讲三遍。分类标记以后,就是前文讲述过的队列调度(含丢弃)和转发,因为它总得转发出去。
当报文转发到 DS 的核心路由器时,它就不需要那么复杂,只需要按照报文的 DSCP 值做相应的动作即可。Diffserv 把这个相应的动作称为 PHB(Per Hop Behavior,每一跳行为)。PHB 并不神秘,它其实是与 DSCP 是一一对应的。重点不是 PHB 与 DSCP 的一一对应,而是每一个 PHB,需要有合适的队列调度机制(含丢弃)能够承载。队列调度机制就是我们前文介绍的 PQ、CQ等7种,具体选择哪一种,是一种综合考虑的结果。
可以看到,Diffserv 不存在 Intserv 的那些问题,在工程上,在 Internet的范畴内,还是可以实施的。当然,它也必须能够实施,因为网络一共就三种模型,第一种说的好听是尽力而为,其实是无所作为,第二种理想很丰满,现实很骨感,根本没法实施。这第三种如果再不能实施,那......
五、MPLS 网络 QoS 解决方案
在谈 MPLS 网络 QoS 解决方案之前,我们首先要思考一个问题,MPLS 专线为什么比 Internet 专线贵?是因为转发技术的不同,应该不是,用户管你是用什么技术转发呢,你如果牛逼,你用顺丰都行。是因为专线技术的不同,应该也不是。MPLS 技术虽然天生适合做专线(VPN),但是 Internet 在 IP 技术上叠加 IPSec,也差不到哪去。
思来想去,应该还是因为 QoS!MPLS 的 QoS 解决方案,有两种模型:Diffserv 和 MPLS-TE。
1、MPLS 的 Diffserv
MPLS 的转发模型与 IP 网络的 Diffserv 模型非常的想象。MPLS 的转发角色分为边缘路由器与核心路由器,IP 网络的 Diffserv 模型分为边缘路由器与核心路由器。所以,MPLS 如果要提供 QoS 的 Diffserv,那是有天然优势的。
所要解决的问题是,IP 报文的 DSCP,到了 MPLS 网络的核心路由器就不可见了。前文说过,MPLS 报文中能够表达 QoS 等级的只有 EXP 字段。不幸的是,EXP 字段只有3个bit,只能表达8个优先级,而 DSCP 有6个bit,可以表达64个优先级(当前只使用了24个),这里面存在一个映射的问题。
如果运营商与用户签订的 SLA 中,只有8个(甚至少于8个)业务等级,那么很简单,只需要将这些业务等级(也即 DSCP/PHB 实际只取8个值)一一映射到 EXP 字段即可。
如果运营商与用户签订的 SLA 中,多于8个和业务等级,那么没有办法,MPLS 只能用不同的路径(LSP,Label Switch Path,标签交换路径)来表示不同的 DSCP/PHB。
这也没什么,反正能表达 SLA 就行。解决了 SLA 的标识方法以后,再看MPLS 的 Diffserv 就非常简单了。与 IP Diffserv 的边缘路由器一样,MPLS 的边缘路由器的 QoS 行为也是包括:流量监管、整形、分类标记、队列调度(含丢弃)。只不过分类标记是标记 MPLS 报文头的 EXP 字段或者选择不同的 LSP而已。同理,MPLS 的核心路由器,也仅仅是负责 PHB。
应该说,MPLS 的 Diffserv 与 IP 的 Diffserv,没有本质的不同,两者达到的 QoS 效果也是一样的。
2、MPLS 的 TE
MPLS 的 TE(Traffic Engineering,流量工程)的概念超出了本文的范围,我们不谈它。这里只须知道,MPLS TE 通过流量工程扩展的资源预留协议(RSVP-TE)、基于约束的标签分配协议(CR-LDP)、基于约束的路由协议(QoS路由技术)等技术,为流量提供带宽保证,通过MPLS TE技术传输的流量不会由于链路带宽不够而被丢弃。
从效果上来讲,这其实就是 IP 的 Intserv。现在有一个小问题,为什么IP 网络的 Intserv 无法实施,而 MPLS 网络就可以实施了呢。这里面要看到本质的不同:IP 的 Intserv,是为每一条流预留资源,保证带宽及其他 QoS 属性,而 MPLS 是为路径(LSP)预留资源,这两者的差距不可同日而语!
MPLS TE 同时还带来了另外一种好处,那就是利用 MPLS TE,可以实现FRR(Fast Reroute,快速重路由)。在发现链路或者路由器故障以后,MPLS TE通过硬件直接切换链路,可以做到从链路故障到快速重路由切换成功的延时小于50ms。
3、MPLS 与 IP 的 QoS 解决方案比较
在进行两者比较之前,让我们再回忆一下本文开头所说的 QoS 所包含的属性:带宽、可用性、时延、抖动、丢包。
基于这些属性,以及网络的 QoS 模型,两者的比较,如表9所示:
表9:MPLS 与 IP 的 QoS 解决方案比较
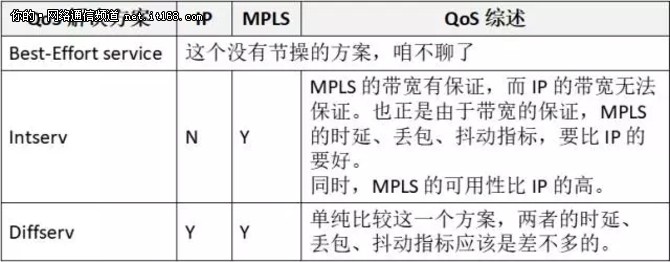
通过表9,我们可以看到,MPLS 的 QoS 与 IP 相比,有着非常大的优势,MPLS 线路比 IP 线路(Internet)价格贵,那是有道理的!