400 Bad Request是一种HTTP错误状态码。HTTP/1.1对400 Bad Request的定义主要是:1、语义有误,当前请求无法被服务器理解。除非进行修改,否则客户端不应该重复提交这个请求。2、请求参数有误。
在这段时间笔者遇到了好几次生产问题Nginx报400异常,且原因细究下来各不相同,有些甚至在网上没有搜到类似案例。遂产生了兴趣,做了本次梳理,希望会对大家有一定帮助!
1. 一般导致400异常的场景
一般使用Nginx在以下场景会报400 Bad Request:
1.1 请求头过大
nginx 400 Bad request是request header过大所引起,request过大,通常是由于cookie中写入了较大的值所引起。在nginx.conf中,调整client_header_buffer_size和large_client_header_buffer参数大小可以解决问题(ps,网上很多博客只片面强调调大两个参数的值,并未研究参数区别和用法,真正大规模应用明显是不合适的)。
那么这两个参数是如何定义的呢?
- 1
- 2
- 3
设置用于读取客户端请求头的缓冲区大小。对于多数请求缓冲1K字节是足够的。然而,如果一个请求包括Cookie,或来自一个WAP客户端,它可能远不止1K。如果request line或者request header超过1K,则由large_client_header_buffers指令配置分配。
- 1
- 2
- 3
设置用于读取大型客户端请求头的缓冲区的最大数量和大小。request line不能超过一个缓冲区的大小,否则将返回414(请求URI太大)错误给客户端。request header不能超过一个缓冲区的大小,否则将返回400(错误请求)错误给客户端。缓冲区只能按需分配。默认情况下,缓冲区的大小为8K字节。如果一个连接请求处理结束后转变为保持状态,这些缓冲区被释放。
所以nginx处理header的方法是:
- 先处理请求的request_line,之后才是request_header。
- 这两者的buffer分配策略相同。
- 先根据client_header_buffer_size配置的值分配一个buffer,如果分配的buffer无法容纳 request_line/request_header,那么就会再次根据large_client_header_buffers配置的参数分配large_buffer,如果large_buffer还是无法容纳,那么就会返回414(处理request_line)/400(处理request_header)错误。
综上所述,网上的很多调整是不合适的。要按具体业务需求调整参数大小。
- 如果你的请求中的header都很大,那么应该使用client_header_buffer_size,这样能减少一次内存分配。
- 如果你的请求中只有少量请求header很大,那么应该使用large_client_header_buffers,因为这样就仅需在处理大header时才会分配更多的空间,从而减少无谓的内存空间浪费。
1.1 空请求
0.7.12以前版本的nginx收到一个空请求,nginx不会去与任何虚拟主机匹配,直接返回400错误,之后的新版本nginx可以用server_name _;匹配空请求头来处理。
- 1
- 2
- 3
- 4
- 5
- 6
当然以上情况在网上都很普遍,下面是本文重点想说的两种特殊场景。
2. 特殊问题场景一:URLConnection发起HTTPS请求经过代理400异常
我们有某个系统A,在和系统B之间通信时使用的是HTTPS协议,在系统B的nginx代理层有大量400错误抛出。经过我们排查,不存在上述请求头部过大或者空请求的情况。那么400问题因何而起呢?我们根据问题症状浏览了大量国外技术网站,终于定位到这是JDK的一个bug:
JDK-6687282 : URLConnection for HTTPS connection through Proxy w/ Digest Authentication gives 400 Bad Request
A系统的JDK版本比较老java version "1.6.0_05",同时使用的是JDK原生的 URLConnection,在通信的过程中我们是这样做的:
1.- Create an HTTPS URL.
2.- Obtain an URLConnection with url.openConnection() providing a Proxy
3.- Setup the SSLSocketFactory.
4.- Setup the default Authenticator.
5.- Read result from connection
问题出现在身份验证上,身份验证在生成响应hash时使用request-URI作为其算法的一部分。request-URI通常取的是uri的绝对路径(abs_path )。但也不全是,比如,在建立隧道请求(tunneling)时,需要用主机+端口号作为request-URI,例如。
- 1
而sun.net.www.protocol.http.digestauthentication 只考虑了通过绝对路径作为request-URI的场景(abs_path )。这显然是有问题的,在建立隧道时,需要使用主机+端口号方式。所以导致在身份验证时产生400 Bad Request:
1.- Send CONNECT HTTP Request to the Proxy
2.- Receive a 407 Proxy Authentication Required
3.- Send new CONNECT with authentication credentials.
4.- Receive 400 Bad Request
解决问题的方案有多种:
1.升级JDK版本,如下图
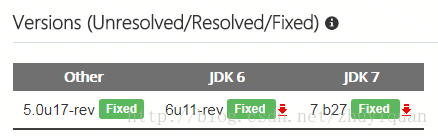
2.使用Apache HttpClient代替URLConnection
3. 特殊问题场景二:网络传输丢包导致的400异常
这个场景困扰我们时间比较长,某个和交易相关的核心系统每天有0.01~0.03%的400错误,全部都是用户端过来的post请求。
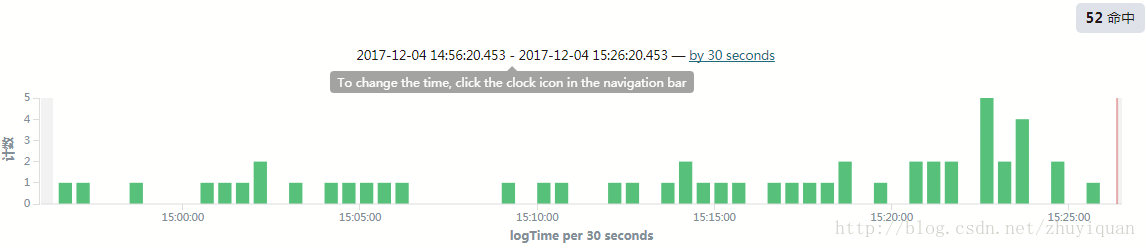
如上图,nginx有零星的400错误,然而tcp dump抓包发现并没有对应的400包。潜意识里我们认为所有的400 Bad Request不可能不被tcp dump所记录,所以我们纠结了很久。最终发现,是因为客户端Post请求Packet在网络传输过程中部分丢失导致到服务端无法正常响应,客户端30s超时断开连接,这时候nginx记录了400。这种情况下,nginx实际未反馈400的response,只是在连接断开时记录了400的日志。
如下图所示,
将上述报文转码后可以更直观发现,POST请求报文不全:



综上所述,这种400错误实际上是因为网络传输过程中POST请求部分Packet丢失,导致服务端无法正常响应,超时后RST导致的。
4. 参考文献
http://www.jianshu.com/p/d028a37890b7 nginx的client_header_buffer_size和large_client_header_buffers学习 ligang1109
http://bugs.java.com/bugdatabase/view_bug.do?bug_id=6687282 JDK-6687282 : URLConnection for HTTPS connection through Proxy w/ Digest Authentication gives 400 Bad Request