硬件介绍

本项目使用到的硬件设备分别为:香橙派AIPro开发板、USB接口音响、USB接口麦克风。
• 本次用到的香橙派AIPro开发板是一款接口丰富、功能齐全、性能强大的AI开发板,搭载四核ARM64处理器和华为昇腾310B4计算加速单元(NPU),具有16GB共享内存、千兆以太网接口、蓝牙、Type-C接口、双USB接口、双HDMI接口、音频接口、GPIO接口等,支持NVME/MSATA协议的m.2接口硬盘。
• 本项目的USB音响和麦克风使用可插USB的蓝牙头戴式耳机代替。
项目介绍
使用香橙派AI Pro开发板,实现语音对话功能。实现一个AI智能助手,可以与我们进行语音对话,知识问答,作为一个基于大模型的语音助手,一方面可以为我们提供更多的知识,也是一个娱乐的玩具。
香橙派AI Pro开发板,有一定的本地AI能力,可以将一部分AI助手的运算放在本地,减少网络的要求,而且其功耗不高,可以长时间开启也不会过于费电。基于此,我们在开发板上运行实时语音识别程序与文字转语音程序,通过文本与大模型服务器API对接,实现端云结合的的AI智能助手。
软件结构
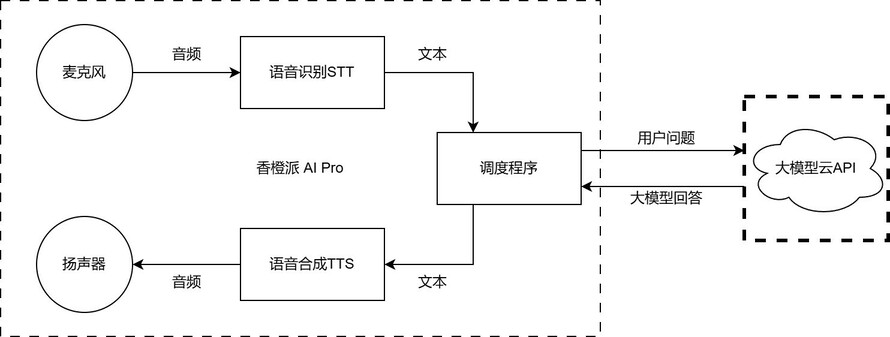
软件主要分为三个部分“语音识别STT”、“语音合成TTS”、“调度程序”。
语音识别模块会在没有输出的时候监听麦克风的信息,如果获取到人声,就会将说话的内容转换为文本传递给调度程序、调度程序接收到语音识别的文本后,会将文本信息发送到云上的大语言模型API进行分析,并等待其回答。
当调度程序接收到大模型的回答后,会拆分语句并发送给语音合成模块,由语音合成模块将文本转化为语音发送给扬声器。
模块适配
• 语音识别STT:语音识别使用了识别使用了昇腾开发板演示样例的ASR模块,对ASR模块进行了恰当修改,使其可以接受numpy.int16格式的语音输入。调度时通过soundData.py中的listen()函数实时监听外界语音,并将语音通过ASR的WeNet模型经由NPU推理计算得到对应的文字输出。
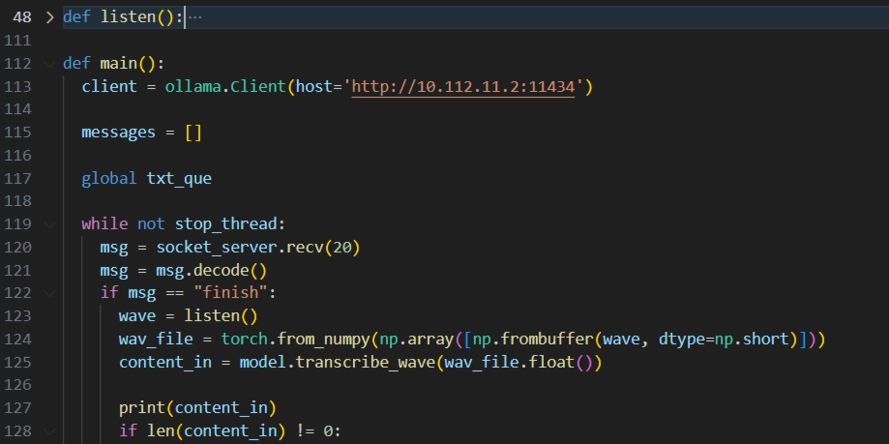
• 调度程序:调度程序使用了Ollama框架,首先使用Ollama在云端启动一个大语言模型(本项目使用的语言模型为Qwen1.5-72B),然后在端侧建立连接云端大语言模型的客户端,再之后就可以使用使用Ollama api 进行调用了,调用方式采用流式,云端以单个字符的方式发送给端侧推理结果,在接收到推理结果后,为了方便音频输出,我们需要对结果进行断句。本项目使用一个全局的队列,将生成的每个句子放到队列里供语音合成模块使用。

• 语音合成模TTS:语音合成模块使用了SummerTTS。SummerTTS是一个基于C++的开源项目,基于Vits并使用Eigen提供的矩阵库实现了神经网络的算子,仅使用CPU即可快速完成语音合成,我们在其基础上进行了类封装并将其通过Swig编译为python可调用的动态链接库(SummerTTS-python)。调用SummerTTS可以将文字输出为numpy.int16格式的数组,通过pyaudio或sounddevice可以直接播放。由于在播放过程中会产生阻塞,我们将其放到另外一个python程序中执行音频播放,并通过socket做音频数据的传输。
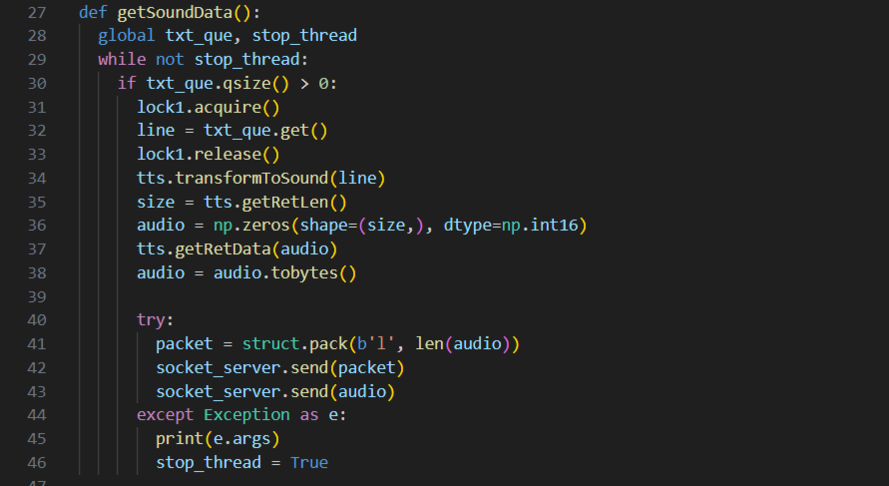
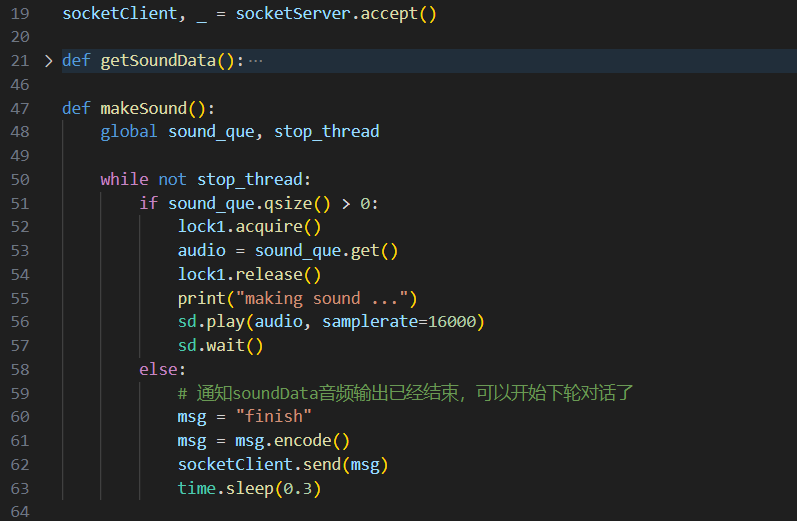
问题与解决
1. 端侧大模型尝试
在项目开始时,我们计划尝试在开发板上直接运行本地的大模型,在经过查找后,我们首先发现了万祖涛的Tinyllama适配了香橙派AI Pro,但经过试用后,我们发现AI Pro目前运行大模型推理的速度不能够满足我们的需求,其目前只能推理1.1B规模的模型,其效果也不尽如人意。
在之后的研究中,我们也尝试适配更大规模的模型,可惜并没有成功。
最终我们选择端云结合的部署方案,借助另一台GPU服务器最为大语言模型的服务器进行推理,并通过AI Pro的千兆网口进行通信。
2. 原生音频接口存在问题
在我们使用的过程中,使用pyaudio和sounddevice库都不能正确的使用3.5mm音频接口,目前结果与驱动的兼容性还存在一些问题,最终我们选择使用USB接口的免驱音频设备绕过了这个问题。
测试运行