随着企业容器规模的不断扩大,企业面临的最大挑战之一是怎样高效地调度容器。Kubernetes是Google基于多年产品化经验而推出的容器编排调度工具,目前已经成为容器编排调度领域的事实标准。作为Kubernetes的调度器,Scheduler的主要工作就是为容器寻找一个最优的工作节点,调度过程可以看作是一个黑盒,黑盒的输入是待调度容器及全部工作节点,在经过调度决策后,输出最优的工作节点,随之容器就会被调度至该工作节点上运行(如图1所示)。这个流程看起来似乎非常简单,但在实际生产环境中调度决策有很多需要考虑的问题:
公平性——如何保证每个工作节点的工作负载能够均衡?
可用性——如何最大化地利用所有工作节点资源?
时效性——如何能够快速高效率地完成大批量的容器调度工作?
灵活性——是否能够保证调度决策能够按照业务需求进行扩展?
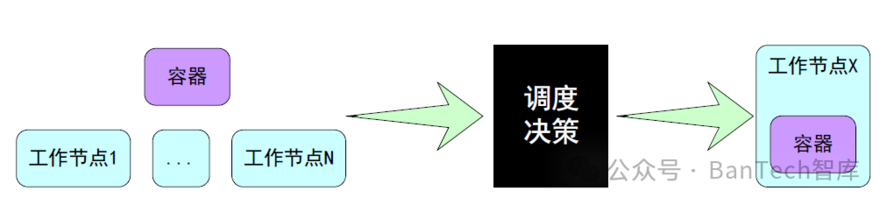
图1 容器调度流程
一、调度流程
Kubernetes Scheduler默认调度器以预选、优选、选定机制将每个新的Pod绑定至调度器选出的目标节点上(如图2所示)。
第一步:预选阶段,遍历所有工作节点,筛选出符合要求的候选节点,通过Kubernetes内置的预选策略来进行决策。
第二步:优选阶段,在第一步筛选出的符合要求的节点中,通过Kubernetes内置的优选策略来对每个节点进行打分。
第三步:选定阶段,在第二步得到的打分中选择得分最高的节点作为运行节点,如果得分最高的节点有多个,就会从中随机选择一个节点作为运行节点。
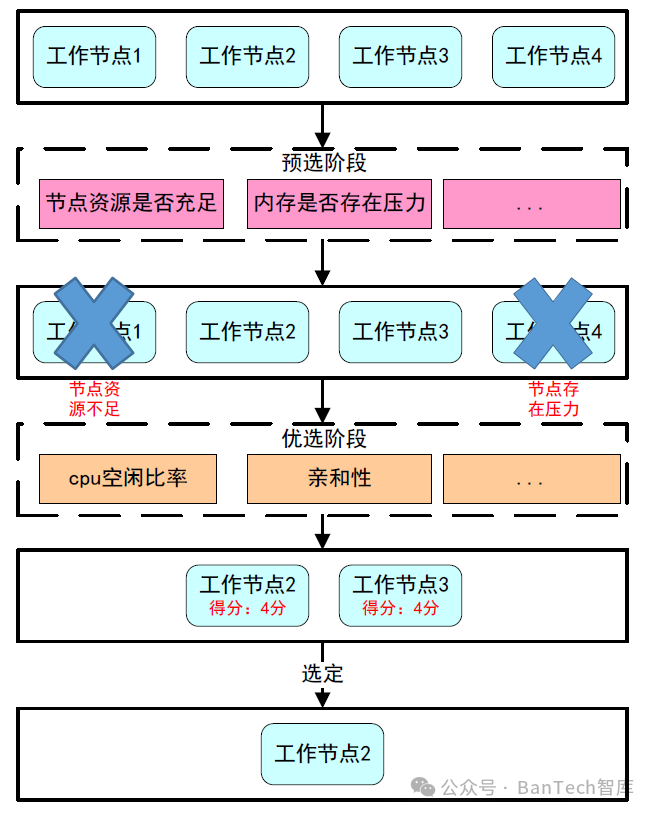
图2 Scheduler调度流程
1
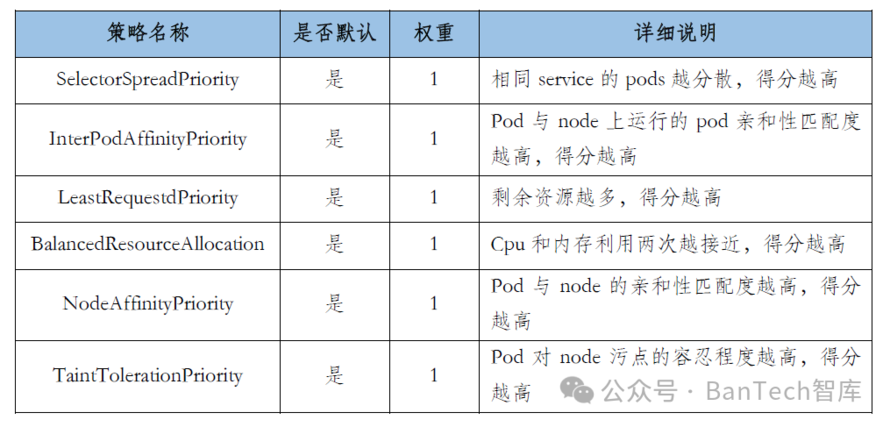
预选策略
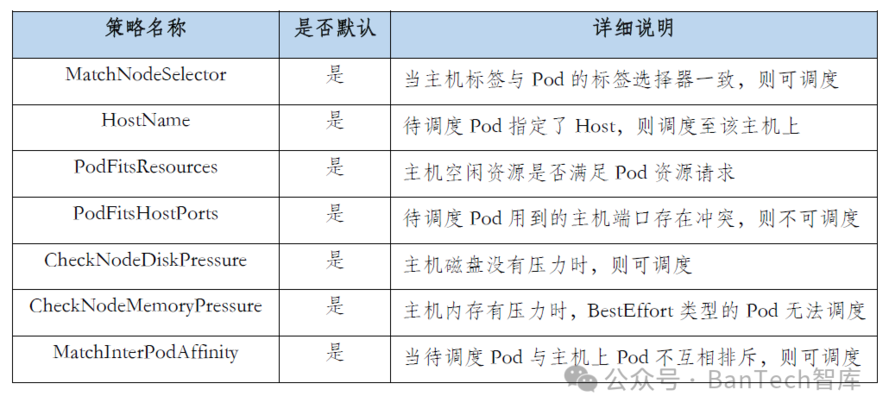
预选策略是预选阶段的核心功能,通过组合多个预选策略可以完成一条可扩展的过滤器链,目前Kubernetes常用的预选策略见表1。
表1 预选策略详细说明
如果在预选阶段过程中没有合适的节点,即找不到满足所有预选策略的节点,Pod会一直保持Pending(等待)状态,并不断尝试重新调度,直到有节点满足条件为止。经过预选阶段,如果有多个节点满足条件,则会继续进行优选阶段的打分。
2
优选策略
优选阶段是用一组优先级函数处理每一个通过预选阶段的节点,常用的优选策略见表2,每一个优先级函数会返回一个0~10的分数,分数越高,表示优先级越优,同时每一个函数也会对应一个表示权重的值。最终得分是将每个优选函数的计算得分乘以权重,然后再将所有优选函数的得分相加,从而得出节点的最终优先级分值:
节点最终分数=(函数1权重*函数1得分)+(函数2权重*函数2得分)+...
表2 优选策略详细说明
二、高级调度
1
亲和性调度
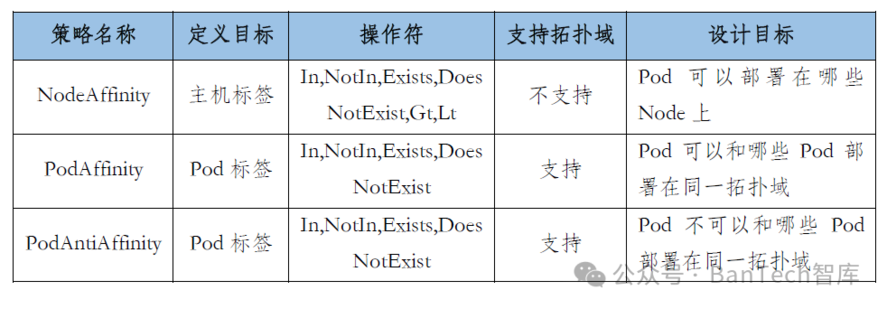
一般情况下,Pod按照集群默认调度流程实现自动部署,但在实际生产中,会有一些特殊的调度需求:比如两个Pod的交互比较频繁,希望这两个Pod调度至同一节点;有时候为了保障高可用,应用的多个副本要求不能调度到同一节点。这种情况下,就涉及到Kubernetes另一个重要概念:亲和性调度,主要分为三类:节点亲和性(NodeAffinity)、Pod亲和性(PodAffinity)和Pod反亲和性(PodAntiAffinity),三种策略的说明见表3。
表3 亲和性调度策略比较说明
2
污点与容忍
污点(taints)与节点亲和性恰好相反,它使节点能够排斥一类特定的Pod。每个污点的基本组成为:key=value:effect,每个污点都有一个key和value作为污点的标签,其中value可以为空,effect用于描述污点的作用,支持如下三个选项:
一是NoSchedule,K8s不会将Pod调度到具有污点的节点上。
二是PreferNoSchedule,K8s尽量避免将Pod调度至具有污点的节点上。
三是NoExecute,K8s不会将Pod调度到具有污点的节点上,同时驱逐Node上已有Pod。
容忍(tolerations)是应用于Pod上的允许Pod调度到带有特定污点的节点。如果一个节点标记为taints,除非Pod也被标记为可以容忍污点节点,否则该节点不会被调度Pod。
污点和容忍相互配合,可以用来避免Pod被分配到不合适的节点上。最常用的场景比如用户希望把Master节点保留给Kubernetes系统组件使用,或者把一组具有特殊资源预留给某些Pod,就可以给Master打上污点标记,Pod就不会再被调度至Master节点。
三、自定义调度器
Kubernetes内置的默认调度器kube-scheduler,包含很多节点预选策略和优选策略,虽然可以满足大多数场景下的调度需求,但是在一些特殊场景下,比如elasticsearch容器化后,两个data实例不能在同一节点上,redis容器化后,两主不能在同一节点上,一对主从不能在同一节点上,默认调度器并不能满足需求。这时就需要对调度器进行扩展,以达到调度策略可控的目的。一般来说,有3种扩展Kubernetes调度器的思路:
一是Scheduler源码修改,修改后重新编译并替换原生Scheduler组件,这种方式对Kubernetes有很强的侵入性,后续也需要花费大量的时间和精力来维护,对于现有方式的影响和后续版本升级有很大的影响,所以这种方式不建议使用。
二是Scheduler Extender,是Kubernetes外部的调度进程,实质上就是一个可配置的Webhook而已,里面包含过滤器和优先级两个部分,分别对应调度周期中的预选节点和优选阶段,用户需要根据需求实现特定的预选和优选方法。这个方案目前是一个可行的方案,可以和上游调度程序兼容,但是存在扩展点有限、通信成本较大等局限性,所以这种方式亦不推荐使用。
三是Scheduling Framework,是Kubernetes v1.15版本中引入的可插拔架构的调度框架,在原有的调度流程中,定义了丰富扩展点接口,可以通过实现扩展点所定义的接口来实现个性化插件,在执行调度流程时,执行到响应的扩展点时,实际上是调用用户注册的插件来影响调度决策的结果。这种扩展方式基本上可以满足所有的调度需求,目前是官方推荐的方式,也将是以后主流的调度扩展方式。
四、集群间调度
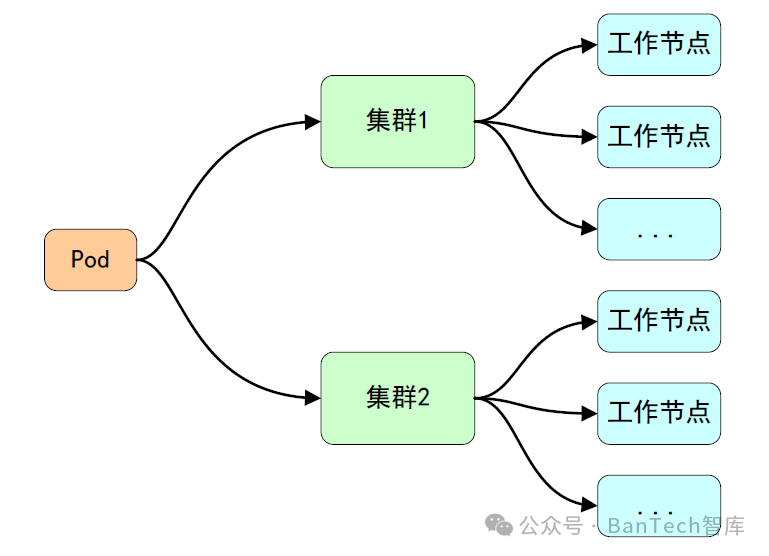
随着Kubernetes集群的广泛应用,企业往往需要运行和管理多个Kubernetes集群,由此就会带来多集群资源的调度的问题,Kubernetes社区也在关注这个问题,并在很早之前就实现了Federation(V1)机制,但是随着Kubernetes发展,Federation v1发展越来越缓慢,在Kubernetes v1.11被正式弃用后,由SIG Multi-CLuster团队提出的新架构Federation v2(KubeFed)所取代。KubeFed(如图3所示)提供了一种自动化机制来将工作负载实例分散到不同的集群中,且能够基于总副本数与集群的定义策略来将Deployment或ReplicaSet资源进行编排。
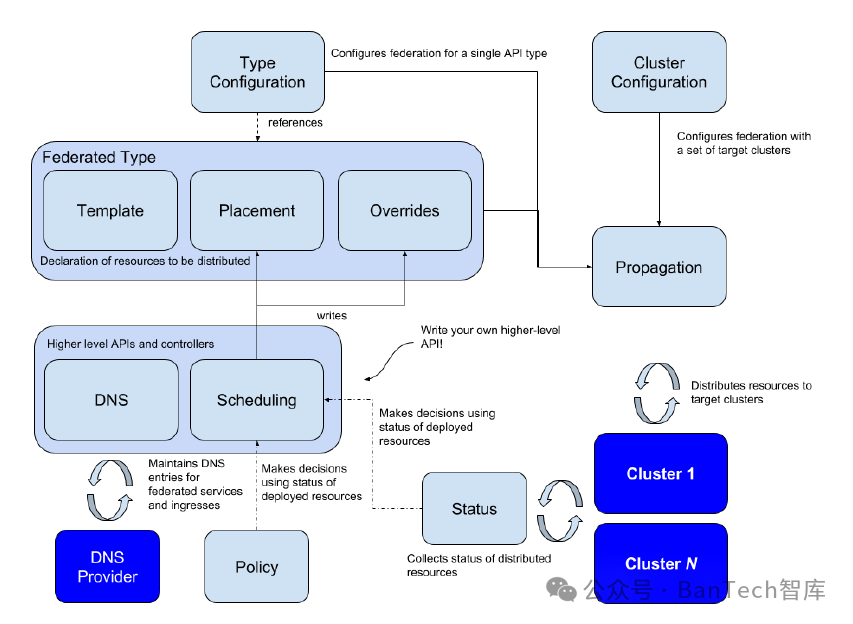
图3 KubeFed架构
五、总结与展望
调度器作为Kubernetes的核心组件之一,能够根据预选、优选、选定,将Pod调度至最优节点,从而保证集群计算资源的尽量充分地利用。Kubernetes原生的调度能力目前仍停留在单集群级别,每一个集群可以高效、稳定地自行调度,但是缺乏横贯多个集群的统筹调度能力。例如部署有状态容器(MySQL、Redis等),具体流程(如图4所示)是先选择一个合适的集群,再在集群内选择合适的工作节点,如此就涉及集群内、集群间两层调度策略,集群内可以通过第三章自定义调度器按需进行扩展,以保障容器在集群内的最优调度。比如将应用打散至不同Region、AZ,提升应用高可用能力、容灾能力。集群间则需要通过一个统一的集群管理平台实现,集群间的调度算法要考虑到资源余量、主节点密度、节点倍率等多个维度,以保障容器在集群间的最优调度。