GBK 字符集中 很多生僻字都无法显示,或者虽然能显示 但是使用正则表达式过滤之后,发现生僻字被过滤掉了。系统认为生僻字并非汉字。
先创建一个GBK 数据库
打开数据库后执行SQL
CREATE TABLE "SYSDBA" . "T1"
(
"A" VARCHAR2 ( 50 )) ;
insert into t1
values ( ' 于彬 ' );
SELECT A , regexp_replace ( A , '[[:punct:]]' ) FROM T1
将数据插入到表中并且使用正则进行筛选
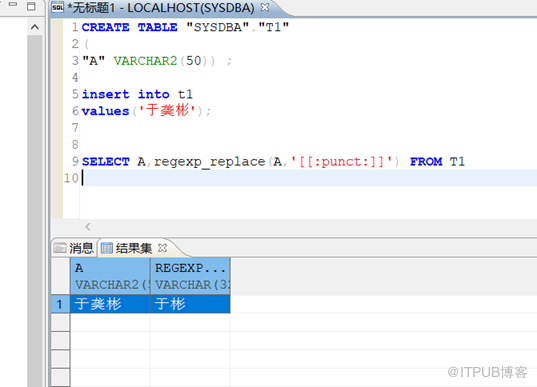
发现筛选后。中间的汉字没有了。现在创建一个 UTF-8 的数据库。
将这条数据使用DTS 迁移到新的UTF-8 库中
再次执行该正则表达式SQL

UTF-8 确实可以稍微减少生僻字过滤或者显示错误的问题,
但是这些只是部分补救办法。最好的办法还是在一开始沟通好需求,如果存在生僻字的情况直接使用UTF-8 字符集