OceanBase v4.2 及以上版本拥有简洁、高性能、批量、随机数据 的插入功能。
背景
在实践中发现,功能测试、压力测试、PoC 等场景下都会涉及到随机数据生成,OceanBasev4.2 之前的版本存在两类问题!
- 随机函数种类少,不支持数据分布控制,需要手写 UDF 或 PL 包。
- 多行数据生成时,需要用 CONNECT BY 或 CTE,它们不仅语法复杂,而且数据行数较多时存在性能问题
下面用两个场景来说明我们亟需更好用的接口。
场景一:OceanBase 测试
OceanBase 拥有大量的 mysqltest 测试用例,但这些用例中创建的表一般都不超过百行数据,导致一些潜在场景覆盖不到。为了增加覆盖率,需要给表中灌入更多数据,但在 v4.2 版之前这并不是一件容易事:
- insert into values 方法手工构造 values 很费劲,有多少行数据就要构造多少组值。
- insert into select 方法构造多行数据需要使用复杂的语法,并且性能不高,导致很少有工程师使用。
- 需要测试数据倾斜场景时,必须手工构造倾斜值,最后设计出来的 case 倾斜值的 NDV 大部分都是1、2 或者3,测试效果大打折扣。
- 需要测试长字符串场景时,只能使用repeat、lpad、rpad 这类函数来构造长字符串,这些方法构造出来的字符串很有规律,通过存储层1z、zstd 等压缩算法处理后占用空间会很小,也可能导致测试效果不尽人意。
场景二:OceanBasePoC
通过 CTE 法和 CONNECT BY 法生成 1000 万行数据插入到数据库中,性能都不理想,只能通过“手工倍增法”

为了让传统 MySQL 客户快速的体验 OceanBase 极速的性能,可以在 QuickStart 中让他构建一个十万行的表来体验极速查询性能。构建十万行数据,无论是insert into values 方法,还是“手工倍增法”,体验都很糟糕。
OceanBase v4.2 提供了全新的多行数据导入功能,彻底解决了上述痛点。它包含如下特性:
1.简洁易记的导数语法。
2.支持任意长度的随机字符串生成函数。
3.支持分布函数,轻松构造倾斜数据。
4.Oracle 模式下引入原生内置随机函数,解决 PL 包性能不足问题。
OceanBase v4.2 随机行数据生成方法
随机数
为 MVSQL 和 Oracle 模式统一增加了一套原生函数,提供完善的功能和最好的性能。
1.无论 MySQL 还是 Oracle 模式,都增加同名函数,丰富了函数种类。
2.无论 MySQL 还是 Oracle 模式,都提供原生内置函数,性能最优。
3.随机函数支持传入种子值,使得随机序列可复现,对测试友好。
随机函数部分,在已有的 rand()浮点随机数函数基础上,引入了直接生成整数值的random()函数,直接生成随机字符串的 randstr()函数。同时,还引入了normal、unifomm、zipf 等几个分布控制函数,这使得能轻松控制生成数据的分布规律。
关于生成器表达式是一个比较新的概念,特别说明如下:
每个随机分布函数都需要一个生成器表达式(gen)作为其最后一个参数。生成器表达式可以是常量或变量:
。如果是常量,则随机分布函数的结果是常量。
。如果是变量,则随机分布函数的结果是可变的。任何可转换为64位整数的表达式都可以用作生成器表达式
。任何随机分布函数的随机性都直接与其生成器表达式的随机性相关。对于大多数实际目的random()函数是随机生成整数值的最佳选择。
由数据生成函数生成的序列不能保证有序且没有间隙。这是因为数字可能会以并行的方式、不同步地生成。
行数据生成
Table function 是一种在 SQL 语言中使用的函数,它能够返回一张数据表作为结果。与传统的 SQL 函数只能返回标量值不同,table function 可以返回多行、多列的数据集。新增 generator 函数,并允许在 table function 中调用它,最终返回 N 行数据。语法为:table(qenerator(N));
N 是一个大于等于 0的 64 位正整数。

table generator 也可以和其它表做 join:


性能评测
在 OceanBase 中,对比了 Connect By、Recursive CTE 和 Table Generator 生成行数据性能,每行包含一列整数。生成 1000 万行数据,Table Generator 只需 2 秒,完全满足日常需求。

生成数据示例
有主键表随机数据生成
推荐搭配 sequence 对象(OB 的 MySQL 模式也支持 Sequence 功能)

Note:为了尽可能提高生成数据的性能,sequence cache 大小不要低于 100 万。
千万行级别的随机数据生成
推荐配合使用 OceanBase 4.1推出“旁路导入”功能,以获得最高的性能。只需要添加 append enable parallel dml parallel(8)的 hint 即可,此处使用了并行度 8:

Note:考虑到 OceanBase 4.2 版本旁路导入的最佳实践,建议用一条 insert 语句完成单表全部数据插入,不要拆成多条 insert 来做。
生成包含多个宏块的数据
为了测试包含多个宏块的场景,需要插入大量的数据。但是偶尔会发现,即使插入了大量行OceanBase 凭借其强大的压缩能力,把这些数据都给压缩没了。即使插入了数十万行,还装不满一个宏块。
Oracle 模式下为了解决这个问题,可以在建表时加上 NOCOMPRESS 属性,这样,插入很少的数据就能装满一个宏块。例如:
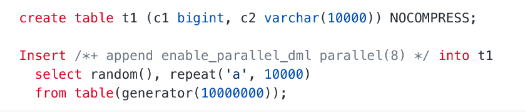
MySQL 模式下没有 NOCOMPRESS 选项,可以使用 randstr() 来生成足够长的随机串避免压缩,

测试并行执行场景推荐使用本方法,有助于提前暴露数据切分相关问题。
倾斜数据生成
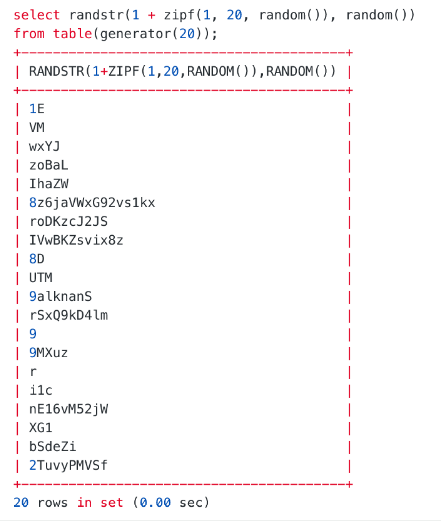
让数据符合正态分布或 zipf 分布,能构造出数据倾斜。例如下面随机生成 20 行数据zipf 分布可以让小数字出现的频率更高:

Note: zipf 生成的数字的分布的特点是小数字出现频率高,大数字出现频率低。
长短不一的字符串生成
批量插入单词
一些场景下,希望插入的字符串有一定规律,不要长得像乱码。比如,插入的内容是字典里的单词。可以通过预先构造一个单词表解决这个问题:

插入部分 null 值
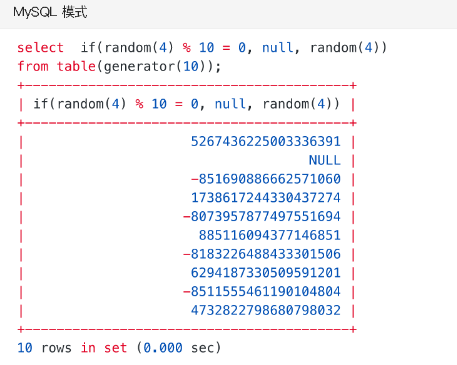
在数据集中掺入 null 值,常能有效暴露一些潜在 bug。MySQL 模式中可以用 if 来实现在随机数中掺null,Oracle 模式下,可以用 decode 来实现。下面的例子里,都以10% 的概率生成 null 值:

在回归测试生成稳定的随机数据
一些测试要求数据必须稳定,否则每次回归的结果都不一样。只需要传入一个常数种子(seed)到随机函数中就可以保证每次插入到表中的数据是一样的。所谓 seed 就是给random() 函数传入一个任意的常量值,seed 相同,每次执行输出的结果都相同。例如下面的例子中,3就是 seed。

加速数据插入
配合并行DML(PDML)可以加速数据插入速度:

如果没有事务要求,也可以搭配上旁路导入功能,导数性能可以更高:

Note:OceanBase v4.2 版本的旁路导入功能还不支持事务,在未来版本里会添加事务支持。
附录:OceanBase 老版本随机数据生成方法
随机数
随机数生成提供了下列方法:

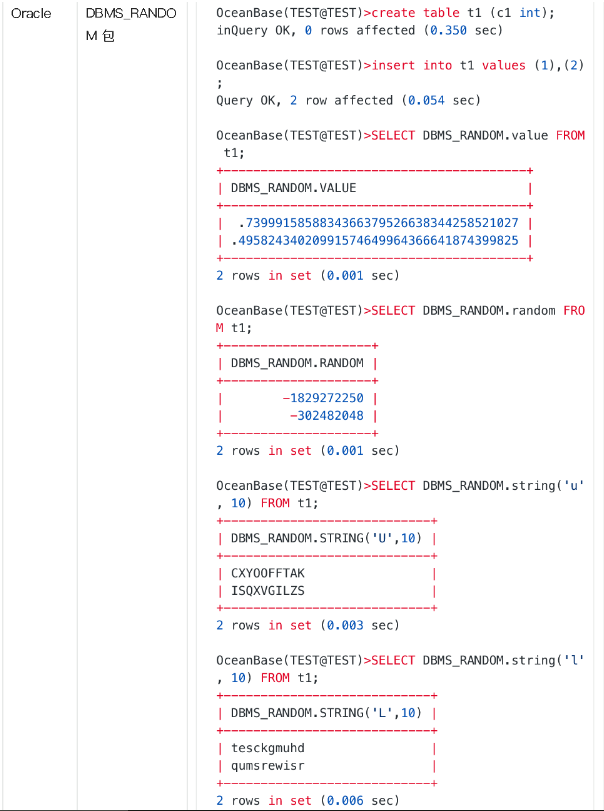
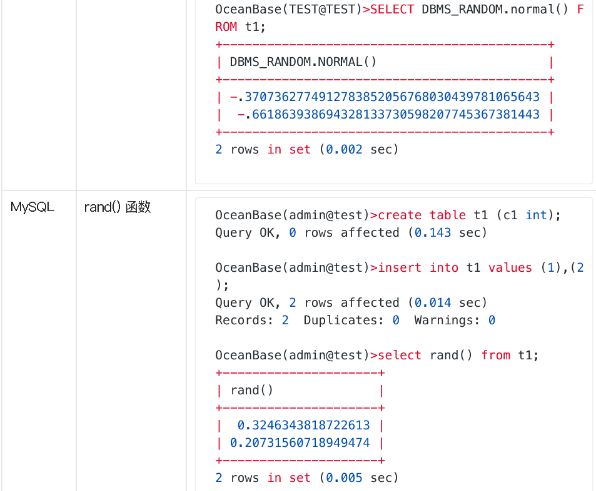
可以看到:
1.MySQL 模式下随机函数种类太少(云平台客户大部分使用的是 MySQL 模式)
2.虽然 Oracle 包提供的随机函数是比较丰富的,但是目前因为实现缘故,在大批量数据插入场景使用 DBMS RANDOM 包有比较大的性能开销。
行数据生成
为了生成 1000 行数据,老版本的 OceanBase 使用如下方法:


可以看到:
1.语法的确是比较复杂,记起来不容易。
2.两个方法的实现性能目前都不太好。
实验: 使用随机数据快速生成测试数据
OceanBase 数据库 V4.2.1
随机函数、Table generator 语法同时适用于 MySQL 模式和 Oracle 模式。
随机数
OceanBase V4.2 版本增加了一套内置函数,提供完善的功能和最好的性能。
随机函数
|
函数名称 |
描述 |
|
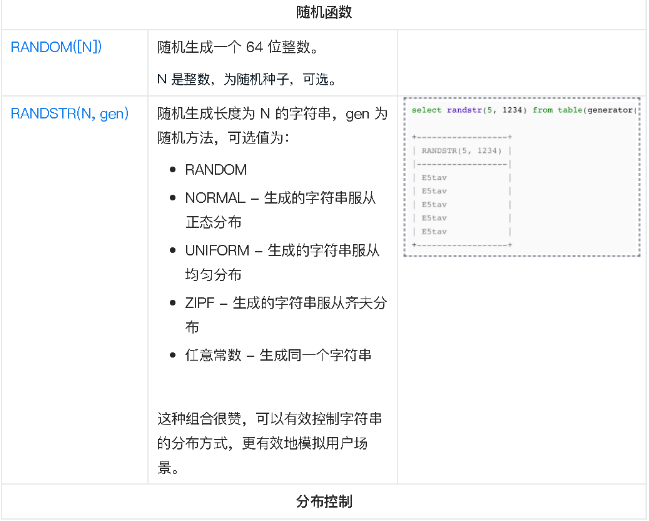
RANDOM([N]) |
随机生成一个 64 位整数。N 是整数,为随机种子,可选。 |
|
RANDSTR(N, gen) |
随机生成长度为 N 的字符串,gen 为随机方法,可选值为:
此种组合可以有效控制字符串的分布方式,更有效地模拟用户场景。 |
分布控制
|
函数名称 |
描述 |
|
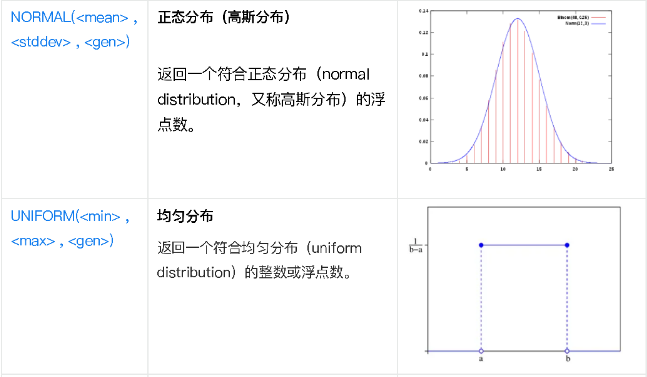
NORMAL( |
正态分布(高斯分布),返回一个符合正态分布(normal distribution,又称高斯分布)的浮点数。 |
|
UNIFORM( |
均匀分布,返回一个符合均匀分布(uniform distribution)的整数或浮点数。 |
|
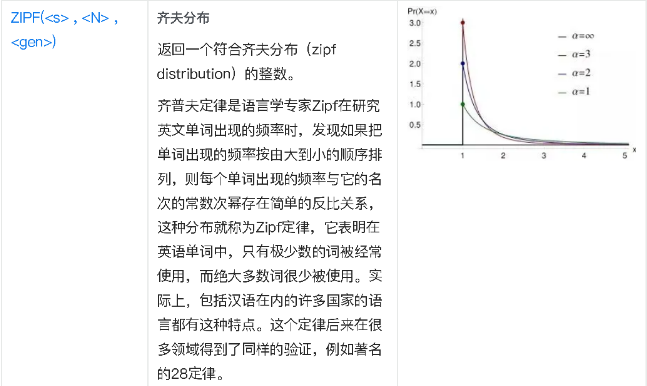
ZIPF( |
齐夫分布,返回一个符合齐夫分布(zipf distribution)的整数。 |
行数据生成
Table function
是一种在 SQL 语言中使用的函数,它能够返回一张数据表作为结果。与传统的 SQL 函数只能返回标量值不同,
table function
可以返回多行、多列的数据集。新增
generator
函数,并允许在
table function
中调用它,最终返回 N 行数据。
函数语法为:
table(generator(N));
说明: N 是一个大于等于 0 的 64 位正整数。
语法结构:
select [随机函数] from table(generator(N));
连接数据库
使用 test 用户登录
obclient -h127.0.0.1 -utest@sys -P2881 -Dtestdb -A --参数说明 testdb 数据库已预建完成,不需要手动创建。 test 用户拥有管理权限,已预授权。
生成有主键表随机数据
推荐搭配 sequence 对象一起使用:
创建测试表 t1
obclient [testdb]> create table t1 (c1 bigint primary key, c2 bigint);
创建 sequence 对象
create sequence s1 cache 1000000 noorder; 说明:为了尽可能提高生成数据的性能,sequence cache 大小不要低于 100 万。
插入随机数
insert into t1 select s1.nextval, random() from table(generator(1000));
查看所生成的随机数
select * from t1;
返回结果如下:
+------+----------------------+ | c1 | c2 | +------+----------------------+ | 1 | -7631875434627638408 | | 2 | 4008152446477750061 | | 3 | -2275109593681479463 | | ... | ...... | | 998 | 4165316234861708796 | | 999 | 114129515204635614 | | 1000 | -3607988344825280313 | +------+----------------------+ 1000 rows in set
千万行级别的随机数据生成
推荐配合使用 OceanBase V4.1 推出
旁路导入功能
,以获得最高的性能。只需要添加
append enable_parallel_dml parallel(8)
hint 即可,此处使用了并行度 8:
设置
ob_query_timeout
的值
set ob_query_timeout = 1000000000;
创建表 t1
drop table if exists t1; create table t1 (c1 bigint, c2 varchar(10));
生成千万行级别的随机数据
insert /*+ append enable_parallel_dml parallel(8) */ into t1 select random(), randstr(10, random()) from table(generator(10000000));
注意: 考虑到 OceanBase V4.2 版本旁路导入的最佳实践,建议用一条 insert 语句完成单表全部数据插入,不要拆成多条 insert 来做。
查看所生成的随机数
obclient [testdb]> select count(*) from t1;
返回结果如下:
+----------+ | count(*) | +----------+ | 10000000 | +----------+ 1 row in set
生成包含多个宏块的数据
为了测试包含多个宏块的场景,需要插入大量的数据。但是偶尔会发现,即使插入了大量行,OceanBase 凭借其强大的压缩能力,把这些数据都给压缩没了。即使插入了数十万行,还装不满一个宏块。 MySQL 模式下可以使用
randstr()
来生成足够长的随机串避免压缩后数据量过少。
创建表 t1
drop table if exists t1; create table t1 (c1 bigint, c2 varchar(10000));
生成宏块数据
insert into t1 select random(), randstr(1000, random()) from table(generator(1));
查看所生成的随机数
select * from t1;
返回结果如下:
+---------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | c1 | c2 | +---------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | 5727839101725986866 | l6X09KVyJmFWHeFSv4d4R8p0p0Je3gTQ3sFKJsrqNm18rkfA9sbahGxOvuBEjwJo92pqD0tsP6zyFgZOpMrcxCd2NMlgbuRIfOBKXmBi9EtEDUFchKniliZ6TGhYnitUNe36hYh8ZONoBUPWbMdyNm5spIf09s94JKF4p6vupi18LOJmdsd6nqriByFk9I9odoPklQp0N8TCbAbGBAzOhc38be1678LarIJE3ynQnUHeZETulOtkXCJeJcX01wZMZqbAzUjIvMxibKVeBYXgP0nyjsL0VaFChMtub6vorI3CjQneNOxGDo1oXKt81K9ELYpKXCHGpYzUj0x4ZeJAVi52dmd8hkbgl2vsJc12NOFa7oxEDodgZEVa5m1KPkLyZElc3SveBkB85sLWtCxeT4HUHmRYfadSTQrEbADgBWDGXi1OX2FYvSpqh4FKns9gRkf0beZmXQfkB2TSDMTQLq5u9klipa5Gf6diJyBidyr0JybKB2bwv4V0bqHORy3wbMBspgfO1Y5y50lo1qVIbItYD65c7gBWp8jSpe5iXSbEFypkPI3Mt4byRCPEzi3sBwZAr25kDibuNy34Lq5YDGRyveRkxOf0n63A1MdeHIHmfYFqziPuZ2fAVoN8dMZ0tmTKJYHcDsnC5WfCj2n2jy1KFqL4Jgl41252Hmz2fAJ2L21MDkz8ByjQToTo3efSri7GJeBKbYtupgVeDcj07GTKhWp8b0BYNYlgR4ny5ObsdKlSpKf2TSLAbmRUPmlmh4DSTIBaTkRgb8vMJKRGrQ1496NsjKBmFeZKvuDuJgTcJiZs9uhEhSZIXsZuTSr6dcvkxqDgPyfczwjm3I181CXC9OzoDCVabyPeZQxsjItAh6zqxSxkbYvCZkbMLwR0Fi1cLEhQVC7M5iLuzG3Q1sFqdsFwtUNIpYlojGBOB2DsbmD0VMl8ToTmNWnWjwVWlAd0nsZ0Ny10PYZC7MbStI1i5K5iHkVmnwZULeXW | +---------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.002 sec)
倾斜数据生成
可以让数据符合正态分布或 zipf 分布,这样就能构造出数据倾斜。
例如下面随机生成 20 行数据,zipf 分布可以让小数字出现的频率更高:
创建表 t1
drop table if exists t1; create table t1 (c1 bigint);
生成倾斜数据的随机数据
insert into t1 select zipf(1, 20, random()) from table(generator(20));
查看所生成的随机数
select * from t1;
返回结果如下:
+------+ | c1 | +------+ | 8 | | 5 | | 18 | | 14 | | 0 | | 0 | | 0 | | 2 | | 17 | | 9 | | 6 | | 0 | | 1 | | 5 | | 1 | | 4 | | 12 | | 12 | | 1 | | 19 | +------+ 20 rows in set (0.004 sec)
注意: zipf 生成的数字的分布的特点是小数字出现频率高,大数字出现频率低。
长短不一的字符串生成
创建表 t1
drop table if exists t1; create table t1 (c1 varchar(100));
生成长短不一的随机数据
insert into t1 select randstr(1+zipf(1, 20, random()), random()) from table(generator(20));
查看所生成的随机数
select * from t1;
返回结果如下:
+----------------------+ | c1 | +----------------------+ | A | | nm | | 9WH6 | | tK7m72 | | Q | | fs | | 3kN2bOdeZsrGJGt | | for | | Z21Kj | | BEB | | XqBON | | Lc5 | | e | | i | | 5YjkDI | | P | | pi1gfUvaHyj | | nyJWX | | 5QlYlMlIv | | FmxqZgVUtUZ8V05kP4Tg | +----------------------+ 20 rows in set (0.002 sec)
批量插入单词
一些场景下,希望插入的字符串有一定规律,不要长得像乱码。
比如,插入的内容是字典里的单词。可以通过预先构造一个单词表解决这个问题:
创建表 t1,t2
drop table if exists t1; create table t1 (c1 int, c2 varchar(10)); create table t2 (c1 varchar(10));
构建单词表 t1
insert into t1 values (0, 'hello'), (1, 'world'), (2, 'movie');
插入单词
insert /*+ parallel(3) enable_parallel_dml */ into t2 select b.c2 from table(generator(1000)) a, t1 b where b.c1 = random() % 3;
说明:
由于上一步中插入单词时使用了动态随机筛选条件(
random() % 3
),导致查询出的表数据行数可能会有差异,请以实际查询结果为准。
查询所生成的数据
select * from t2;
返回结果如下:
+-------+ | c1 | +-------+ | hello | | hello | | hello | | ..... | | movie | | movie | | movie | +-------+ 664 rows in set
插入部分 NULL 值
在数据集中掺入 NULL 值,常能有效暴露一些潜在 bug。MySQL 模式中可以用 if 来实现在随机数中掺 NULL,Oracle 模式下,可以用 decode 来实现。下面的例子里,都以 10% 的概率生成 NULL 值:
创建表 t1
drop table if exists t1; create table t1 (c1 varchar(100));
生成随机数据
insert into t1 select if(random(4) % 10 = 0, null, random(4)) from table(generator(10));
查看所生成的随机数
select * from t1;
返回结果如下:
+----------------------+ | c1 | +----------------------+ | 5267436225003336391 | | NULL | | -851690886662571060 | | 1738617244330437274 | | -8073957877497551694 | | 885116094377146851 | | -8183226488433301506 | | 6294187330509591201 | | -8511555461190104804 | | 4732822798680798032 | +----------------------+ 10 rows in set (0.002 sec)
Mysqltest 中如何生成稳定的随机数据
Mysqltest 要求数据必须稳定,否则每次回归的结果都不一样。只需要传入一个常数种子(seed)到随机函数中就可以保证每次插入到表中的数据是一样的。所谓 seed 就是给 random() 函数传入一个任意的常量值,seed 相同,每次执行输出的结果都相同。例如下面的例子中,3 就是 seed。
创建表 t1
drop table if exists t1; create table t1 (c1 bigint);
创建表 t2
drop table if exists t2; create table t2 (c1 bigint);
往 t1,t2 表内生成随机数据
insert into t1 select random(3) from table(generator(10)); insert into t2 select random(3) from table(generator(10));
查看 t1 表数据
select * from t1;
返回结果如下:
+----------------------+ | c1 | +----------------------+ | 1084041170817055659 | | -5612168153867183641 | | 1664657641377715667 | | -2833993413536137579 | | 1103034804049852293 | | -2558513787582595740 | | 4376380862814081111 | | -1426722524934308120 | | 3776508982995411530 | | -6158710767394100221 | +----------------------+ 10 rows in set (0.002 sec)
查看 t2 表数据
select * from t2;
返回结果如下:
+----------------------+ | c1 | +----------------------+ | 1084041170817055659 | | -5612168153867183641 | | 1664657641377715667 | | -2833993413536137579 | | 1103034804049852293 | | -2558513787582595740 | | 4376380862814081111 | | -1426722524934308120 | | 3776508982995411530 | | -6158710767394100221 | +----------------------+ 10 rows in set (0.002 sec)
参考链接: https://open.oceanbase.com/course/detail/11979