PostgreSQL中的流复制是一种成熟的主从复制技术。设置简单、稳定、性能好。许多人在了解复制冲突时都感到惊讶,毕竟备用服务器是只读的。本文描述复制冲突并告诉您如何处理它们。
1.什么是复制冲突
每当恢复进程无法在备用服务器上应用从主服务器传递过来的WAL信息时,就会发生复制冲突,因为变更会中断正在执行的查询。这些冲突不会在主服务器上的查询中发生,但会在流复制中的备用服务器上发生,因为主服务器对备用服务器上发生的事情知之甚少。
2.有几种复制冲突
1)快照复制冲突
这是最常见的复制冲突。如果VACUUM处理一个表并且删除了死元组,可能会发生快照冲突。这一删除的动作也会在备用服务器上重放。备用服务器上的查询可能已经在主服务器上的VACUUM发生之前启动(它有一个较早的快照),因此它仍然可以看到应该删除的元组。这变会构成快照冲突。
2)锁复制冲突
在备用服务器上,对正在执行查询的表上,获得了ACCESS EXCLUSIVE的排他锁。因此,必须在备用服务器上回放主服务器上的任何获取ACCESS EXCLUSIVE锁的操作(与ACCESS SHARE冲突),以防止发生表上不兼容的操作。PostgreSQL在诸如DROP TABLE,TRUNCATE和大多数ALTER TABLE等操作会获取与SELECT相冲突的锁,如果备用服务器在正在查询使用的表上回放这样的锁,就会发生锁冲突。
3)Buffer pin replication conflicts
One way to reduce the need for VACUUM is to use HOT updates. Then any query on the primary that accesses a page with dead heap-only tuples and can get an exclusive lock on it will prune the HOT chains. PostgreSQL always holds such page locks for a short time, so there is no conflict with processing on the primary. There are other causes for page locks, but this is perhaps the most frequent one.When the standby server should replay such an exclusive page lock and a query is using the page (“has the page pinned” in PostgreSQL jargon), you get a buffer pin replication conflict. Pages can be pinned for a while, for example during a sequential scan of a table on the outer side of a nested loop join.HOT chain pruning can of course also lead to snapshot replication conflicts.
减少对VACUUM需求的一种方法便是使用HOT更新。
然后,任何在主数据库上访问具有仅堆堆已死的元组的页面并且可以对其进行独占锁定的查询都将修剪HOT链。
然后,任何在主数据库上访问仅包含死堆元组的页面并可以在该页面上获取exclusive锁的查询都将修剪HOT链。PostgreSQL总是在很短的时间内持有这种页面锁,因此与主数据库上的处理没有冲突。页面锁定还有其他原因,但这可能是最常见的原因。
当备用服务器回放此类的排它页面锁并且有查询正在使用该页面时(在PostgreSQL中的术语为“已将页面固定”),则会出现buffer pin复制冲突。页面可以被固定一段时间,例如在嵌套循环连接外侧的表的顺序扫描期间。
当然,HOT链剪枝也可能导致快照复制冲突。
3.罕见的复制冲突
以下类型的冲突很少见,不会困扰您:
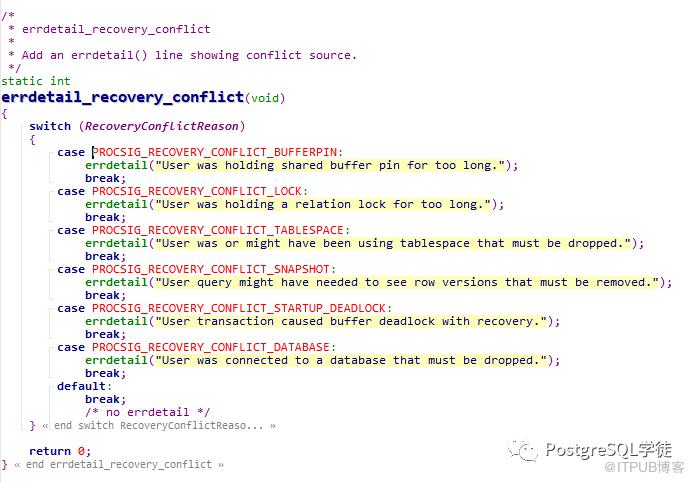
死锁复制冲突:A query on the standby blocks while using the shared buffer that is needed to replay WAL from the primary. PostgreSQL will cancel such a query immediately.在备用数据库上的查询使用到了回放WAL所需的共享缓冲区。PostgreSQL将立即取消此类查询。
表空间复制冲突:表空间位于备用服务器上的temp_tablespaces中,并且查询中具有临时文件。当主数据库出现DROP TABLESPACE时,会发生冲突。在这种情况下,PostgreSQL会取消备用数据库上的所有查询。
数据库复制冲突:如果备用数据库在数据库上具有活动会话,则复制DROP DATABASE会导致冲突。在这种情况下,PostgreSQL会终止备用数据库上的的所有连接。
4.监视复制冲突
统计信息视图pg_stat_database_conflicts包含自上次重置统计信息以来发生的所有复制冲突的详细说明。您必须在备用服务器(而不是主服务器)上查看该视图,因为这是发生复制冲突的地方。
请注意,该视图不会显示所有已发生的复制冲突,而仅显示导致备用数据库上的查询被取消的那些冲突(请参阅下一节)。
5.备用服务器如何解决复制冲突?
参数max_standby_streaming_delay决定了WAL回放时遇到复制冲突时会发生什么(存在类似的参数max_standby_archive_delay对归档恢复执行相同的操作)。PostgreSQL会暂停回放WAL,最多max_standby_streaming_delay毫秒。如果冲突的查询在那之后仍在运行,则PostgreSQL会取消查询,提示如下错误:
ERROR: canceling statement due to conflict with recovery
DETAIL: User query might have needed to see row versions that must be removed.
详细消息显示这是来自快照复制冲突。
max_standby_streaming_delay的默认值为30秒,因此如果备用数据库上的查询引起复制冲突,则在取消之前,该查询将获得半分钟的“宽限时间”以完成。这是介于0(极端设置(PostgreSQL立即取消查询,没有回放延迟)和特殊值-1(PostgreSQL从不取消查询,任意长的重放延迟)之间的中间设置。
要了解如何最好地配置PostgreSQL以处理复制冲突,我们必须看一下流复制的用例。
6.流复制的用例
1)高可用
流复制是大多数高可用性解决方案的基础。与管理故障转移的Patroni之类的软件一起,它提供了一个强大的shared-nothing架构来构建容错系统。
显然,具有高可用性的主要目标是使复制延迟尽可能小。这样,备用数据库提升为主的速度会很快,并且在故障转移期间几乎没有数据丢失。在这种情况下,您希望将max_standby_streaming_delay设置的低一点。
请注意,如果备用数据库落后于应用WAL,则在故障转移期间您无需丢失更多数据– WAL信息仍将流式传输到备用数据库并写入到pg_wal目录中。但是会导致备用数据库追赶数据所需的时间更长,因此故障转移的时间会增加。
2)卸载大查询
对于报表或数据分析的大查询可能使生产系统过载。最好的解决方案是专门为此类查询设计数仓。但通常备用服务器可以充当“穷人的数据仓库”。另一个减轻负载的示例是数据库备份:备份备用服务器不会对主系统造成压力。在这种情况下,主要目标是使查询(或备份)完成而不会中断。
在这种情况下,您希望将max_standby_streaming_delay设置为大于最长查询的执行时长的值,并且如果存在延迟回放WAL的问题也没问题。
3)水平扩展
您可以使用多台备用服务器,将数据库工作负载分布到多台机器上。在实践中,这种方法的有效性有几个限制
1.所有写入语句都必须转到主服务器,因此只能读可以扩展
2.该应用程序必须能够将查询和数据修改定向到不同的数据库
3.应用程序必须解决以下问题:查询可能无法立即看到数据的修改(同步复制避免了这种情况,但是对写入事务的性能影响是惊人的)
4.您面临的另一个困难是max_standby_streaming_delay没有好的设置:较低的值将使备用数据库上的查询失败,而较高的值将导致备用数据库上的查询看到陈旧的数据。
7.如何应对冲突需求
理想情况下,备用服务器仅用于一个目的,因此您可以相应地调整max_standby_streaming_delay或hot_standby。因此,最好的方式是拥有专用的备用服务器来进行故障转移和卸下负载。
但是有时您买不起第二个备用服务器,或者您可能陷入上述“水平扩展”方案中。那么您唯一的选择就是尽可能减少复制冲突的数量。
8.避免复制冲突
通过禁用hot standby来避免所有冲突
显然,如果备用服务器上没有查询,就不会有复制冲突。因此,如果在备用服务器上将hot_standby 设置为off,则无需担心复制冲突。
但是,尽管此方法简单有效,但只有将备用服务器专门用于高可用时才可行。如果您不在那个幸运的位置,请继续阅读。
9.避免锁冲突
避免锁冲突的明显方法是不执行需要获取相应表的ACCESS EXCLUSIVE锁的语句。语句包括:
1)DROP TABLE
2)TRUNCATE
3)LOCK
4)DROP INDEX
5)DROP TRIGGER
6)ALTER TABLE
但是有一种您无法避免的ACCESS EXCLUSIVE锁:VACUUM截断锁。当VACUUM完成对表的处理,并且表末尾的页面变为空时,它将尝试在表上获得一个简短的ACCESS EXCLUSIVE锁。如果成功,它将截断空白页并立即释放锁。尽管这样的锁不会扰乱主数据库上的处理,但会导致备用数据库上的复制冲突。
有两种方法可以避免VACUUM截断:
a.从PostgreSQL v12开始,您可以针对单个表的禁用此功能
ALTER TABLE some_table SET(vacuum_truncate = off);
b.您可以将主数据库上的old_snapshot_threshold设置为-1以外的值。这会禁用VACUUM截断,这是未被记录的副作用。
10.避免快照冲突
减少此类冲突的方法是防止主数据库删除可能在备用数据库上仍然可见的死元组。有两个参数对此有帮助:
1)将主服务器上的hot_standby_feedback设置为on。然后,从备用服务器到主服务器的反馈消息将包含备用服务器上最旧的活动事务的快照xmin,主服务器将不会删除该事务仍然可以看到的任何元组。这将消除大多数这些复制冲突,但是在备用数据库上长时间运行的查询可能导致主数据库上的表膨胀,这就是默认情况下未启用该设置的原因。仔细考虑风险。
2)将主数据库上的vacuum_defer_cleanup_age设置为大于0的值。然后,VACUUM不会立即清除无效的元组,除非超过了vacuum_defer_cleanup_age指定事务数量的旧数据。这不如hot_standby_feedback更具有明确性,并且还可能导致表膨胀。
请注意,尽管hot_standby_feedback = on将消除大多数快照复制冲突,但由于备用数据库使用的页面可能包含一些非常旧的元组,因此不一定消除buffer pin冲突。而且,即使打开hot_standby_feedback,我也看到了数据库中的快照冲突,尽管在咨询了之后也不知道为什么还会发生。也许读者可以启发我)
11.避免Buffer pin冲突
没有很好的方法来避免这些冲突。也许您可以减少HOT更新的数量,但这会损害主数据库的性能。
12.结论
避免复制冲突的最佳方法是拥有专用的备用服务器:一台用于高可用性,另一台用于卸载查询或备份。然后,您可以轻松地配置每个以避免复制冲突。
如果您负担不起这笔费用,或者想使用备用数据库进行水平扩展,则必须调整hot_standby_feedback,max_standby_streaming_delay和vacuum_truncate存储参数,以尽可能少的发生查询被取消的情况,同时避免过多的表膨胀和长时间的复制延迟。
13.译后感
1.Deadlock replication conflicts的冲突有点难以理解
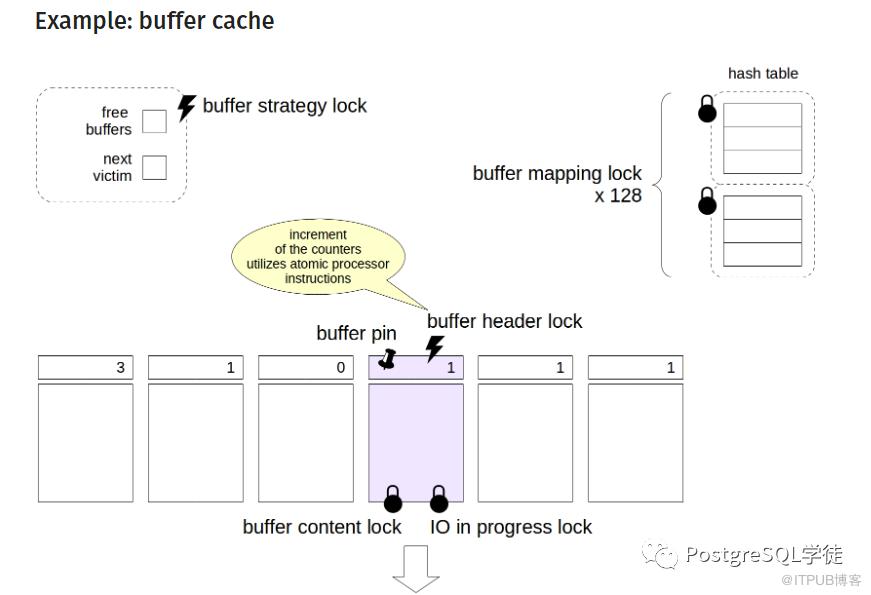
2.其中Buffer pin的conflict在源码中确实有注明:User was holding shared buffer pin for too long,Buffer pin在缓冲区管理里面有介绍,refcount holds the number of PostgreSQL processes currently accessing the associated stored page. It is also referred to as pin count. When a PostgreSQL process accesses the stored page, its refcount must be incremented by 1 (refcount++). After accessing the page, its refcount must be decreased by 1 (refcount--).,意思就是访问当前页面的PostgreSQL进程数,有一个就+1,会在页面淘汰算法中用到,德哥的一个帖子中有介绍https://github.com/digoal/blog/blob/master/201608/20160815_03.md
3.对于锁冲突,强烈建议在执行DDL前加上Lock_timeout,如set lock_time to xxx;
4.Vacuum的截断锁,在PG12里面引入了vacuum_truncate这个参数,也可以避免一定的锁冲突ALTER TABLE some_table SET(vacuum_truncate = off;这是一个不错的特性,根据场景可以选择关闭这个,old_snapshot_threshold原文说了也会禁止vacuum截断,这一点还需要试验
最后吐槽一下,也是PG一个一直以来的槽点,PG的MVCC由于实现机制,在update更新特别大且重的情况下,备库上的查询一旦复杂就会频繁提示conflict,绝大多数见到的都是User query might have needed to see row versions that must be removed.,需要花很多时间去调整,好在zheap的消息也越来越多,相信不久就能见到,让PG的AP能力再上一层楼。
原文链接:https://www.cybertec-postgresql.com/en/streaming-replication-conflicts-in-postgresql/
参考:
https://github.com/digoal/blog/blob/master/201608/20160815_03.md
http://www.interdb.jp/pg/pgsql08.html
https://habr.com/en/company/postgrespro/blog/507036/