项目背景
基于统一化平台建设背景,某银行构建了一个统一的标签画像平台,实现了全行标签数据的统一加工和应用,使数据在业务流转中发挥精准性、完整性、规范性、实效性的业务价值,满足了在营销、风控、运营、内部管理等标签数据方面的需求。
但是,该项目上线后,随着数据不断增长,企业面临一些性能瓶颈,比如业务混合使用,传统的数据处理方案存在局限性,数据安全管理等方面也在面临着全新的挑战。
项目需求
本次大数据基础平台升级是结合各数据应用系统建设情况,从技术领先、灵活扩展、保证安全、产品性价比等方面统筹考虑数据存储、数据加工、数据查询、数据服务、数据应用、数据安全等多个层面的需求进行的升级。平台升级后,技术架构领先、计算能力的动态灵活扩展,能够形成算力更强、架构更完善的全行级数据中台服务体系。实现数据的统一管理控制、统一调度配置、资源集约共享,并通过专业的大数据同步及脱敏工具搭建大数据灾备体系及准生产环境,强化数据使用安全。
本篇文章将为读者解析 ArgoDB 如何针对该项目所面临的实际业务指标查询下的场景进行优化。希望能为读者在后续遇到相似场景下的优化问题时提供思路,更高效高质量的解决问题,如果对您有所帮助,欢迎多多点赞支持~

添加图片注释,不超过 140 字(可选)
优化点解析
针对该银行的不同指标查询业务,星环统一采取了以下四个方面的措施进行优化,本节将详细为读者介绍具体的优化措施及操作步骤,以帮助读者更好的理解和操作。
概览
-
读写分离功能,改建双数据中心,独立建设一个数据中心专门用于高并发指标查询业务,为批处理与高并发查询实现高效的资源隔离;
-
开启 Linac-Localfast 模式,实现 Quark Server 本地读, 点查性能最高提升 40 倍+(毫秒级);
-
优化表结构,根据表数据分布情况修改分区分桶信息,并添加细粒度索引;
-
升级补丁,并设置优化参数。
一、多数据中心(读写分离)
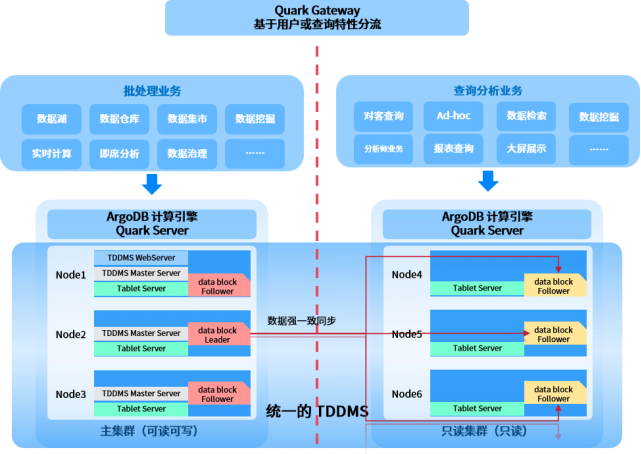
在传统部署中,ArgoDB 的 TDDMS 组件通常承担着为大数据处理平台提供统一的数据存储服务。
TDDMS 是星环自研的一个分布式数据管理系统,该系统搭建了一个通用的分布式存储处理框架, 提供了数据的分布管理、元信息管理、分布式事务、分布式一致性协议以及数据高可用保障。TDDMS 支持多种不同的数据模型,并为不同的数据模型提供了格式化的数据读写接口,便于分布式计算引擎进行数据读写等操作,真正实现了多源数据的高效融合。
但是,在企业日常生产运行过程中,伴随着多样化的数据类型以及业务的不断扩展和数据量的激增,单一集群往往需要同时处理日常的批量数据处理任务和即时查询业务,可能引发计算和存储资源的抢占,进而影响业务的执行效率。
添加图片注释,不超过 140 字(可选)
用户可以在统一的存储基础上划分出多个逻辑上独立的集群,专注于各自的业务,实现存储和计算资源的隔离。例如,我们可以单独为查询业务划分出只读集群中,该集群中仅存储表的副本数据,同时按需分配计算资源,从而保证日常的批处理业务和查询业务能够高效、无干扰地运行。
此案例的方案实施概述:
将 16 个计算节点改建为 13+3 双数据中心,其中主数据中心(DC1)用于执行跑批以及大部分业务,高并发查询数据中心(DC2)用于专门执行高并发的指标查询业务。
二、远程读和本地读
Holodesk 中,事务是以一批文件的方式提交的,每次 Quark 执行 SQL 任务生成的数据文件,会被提交给 TDDMS。如果存在
分桶,则会根据每个分桶对应的 tablet 存储位置,将数据保存对应 tablet 副本的磁盘上。
在这之后,Quark 在读取 Holodesk 数据时,有两种方式:
-
本地读:Quark Executor 直接读取 TDDMS Tablet Server 数据目录中的数据文件进行计算;
-
远程读:Quark Executor 与 TDDMS Tablet Server 通信,由 TDDMS Tablet Server 读取文件,将数据文件直接/解压缩(过滤下推)后发送给 Quark Executor。
而 Quark Executor 能直接读到 Holodesk 数据文件,也是因为在配置服务时,就将 TDDMS 的数据目录挂载进 Quark Executor 的容器中了。如果进入到 Quark Executor 的容器中,可以看到只挂载了 ngmr.localdir 和 tabletserver.store.datadirs 配置的数据目录。
综上所述,本地读对比远程读二者的性能差异主要源于以下维度:
-
本地文件访问无网络开销,延迟低,吞吐高
-
计算引擎直接读取文件,能够更好的发挥性能优势
-
减轻 TDDMS Tablet Server 负载,支持更高的读写并发
因为远程读数据是需要 TDDMS Tablet Server 读数据文件,因此 TDDMS Tablet Server 也会有较高的内存占用。
而针对此案例,由于使用了 Linac-Localfast 执行模式将结果集
缓存在了 Quark Server 中,所以区别于传统的是使用 Quark Executor 进行本地读,业务上可以直接使用 Quark Server 读取存储在 Server 本地的数据,进一步提高了指标查询性能。
三、Linac-Localfast 模式
-
ArgoDB 5.2 推出了新的 Linac 计算引擎,相比较原来的 Java 引擎, Linac 引擎能够 显著提高对点查的响应速度(2~5 倍),适用于需要频繁访问特定数据项的指标查询场景;
-
Localfast 通过在 Quark Server 生成与 Cluster 模式接近的分布式执行计划,并在 Quark Server 内多线程执行,因此能实现更快的响应速度,但也要求数据量不能过多。Localfast 在表扫描阶段支持并发多个 task,利用多线程和并行处理的优势,使得单机执行效率更高,适用于 OLAP 及高并发查询场景;
-
Linac 引擎支持对接 Localfast 执行模式,若要开启 Linac-Localfast 模式,必须同时设置以下三个参数:
set use.linac=true; set ngmr.local.fast.enabled=true; set ngmr.windrunner.enabled=true;
四、添加细粒度索引
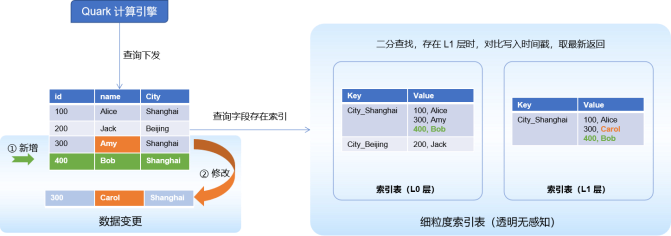
在 ArgoDB 5.2 中,我们推出了细粒度索引功能,使用更宽泛的条件来返回比常规索引更多行数据的存储引擎技术。ArgoDB 中的细粒度索引是基于 KV(key-value)的索引,提供高速的 KV 服务,索引文件的 Key 存储索引键,Value 存储相同索引键的值。它类似于一种聚簇索引,可以把大量相似的数据细分成更小的边界,从而使文件的查找变得更快更有效率。
添加图片注释,不超过 140 字(可选)
在这个指标查询案例中,都涉及到对表以及表中字段的等值查询,添加细粒度索引可以把数据分割成更小的单元,通过扫描小批量数据实现高效数据检索。
效果对比