LSM 的原理已经有很多答主写得非常详细了。目前,在实践上,RocksDB 是 LSM 的典型代表乃至事实标准,围绕 RocksDB 的各种系统与应用,已经形成了一个巨大的生态:
- · MySQL 的 MyRocks 存储引擎
- · TiDB/CockroachDB
- · MongoDB 的 MongoRocks
- · 各种外存版 Redis: ssdb, pika, kvrocks, tendis, tair....
- · 举不胜数的各种其他系统……
然而,RocksDB 其实是有很多缺陷的,可改进的空间非常大, ToplingDB 就是一个脱胎换骨的 RocksDB:
- 兼容性:与 RocksDB API 100% 兼容
- 现有使用 RocksDB 的代码不用任何修改,就可以直接使用 ToplingDB
- 如果要完全迁移到 ToplingDB,只需要 修改 DB Open/Close 相关的 代码
- 增加了很多改进,修改了一些 bug,并且 已向上游 RocksDB 提交了几十个 Pull Request
- 旁路插件化 SidePlugin:ToplingDB 的骨架与灵魂
- 配置方式
- RocksDB:需要通过代码来控制复杂的配置项
- ToplingDB:所有配置项都使用 json/yaml 来控制,无需修改代码
- 插件机制,不管是内置组件还是第三方组件
- RocksDB 需要在代码中引入对具体组件代码( 头文件)的依赖
- ToplingDB 无需引入这种依赖,甚至可以透明地 通过动态库使用外来组件
- ToplingDB 内置 Web Service,实现 诸多可视化及引擎操纵功能
- 在线 查看配置参数、 LSM 树形态、 SST 文件等等,可观测实时变化……
- 在线修改配置参数,不仅仅是修改 DBOptions/CFOptions,所有的组件参数均可修改
- 可以通过 http 导出 Prometheus 格式的 metrics,再用 grafana 展示
- 在线执行 Compact/Flush ……
- Topling 特有的性能组件,通过 SidePlugin 提供,使用 json/ yaml 配置,用户代码无需改动
- 更快的 MemTab: 单线程快 8 倍、多线程线性 scale、内存消耗更低
- WriteOnly 负载中,逆天到比 RocksDB 的 VectorMemTab 还要快
- 更快的 SST:不压缩、速度快、无需 BlockCache、毫秒级加载,一般用于 L0 & L1
- 压缩的 SST:高压缩、速度快、无需 BlockCache、毫秒级加载,一般用于 L2 及更下层
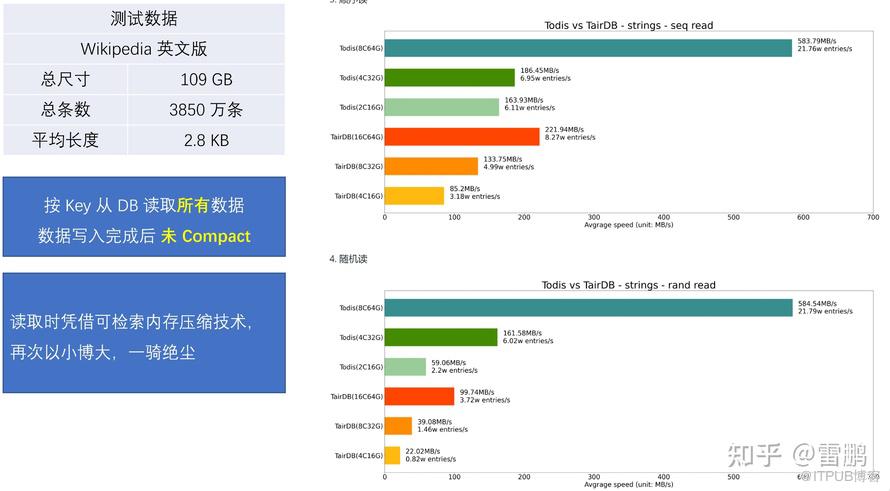
- 使用的是 可检索内存压缩算法,压缩率更高,数据在内存中的形态是压缩的,直接在压缩的数据上执行搜索和访问
- 无需 BlockCache,内存利用率提升 5 倍以上,并且大幅降低 CPU 消耗
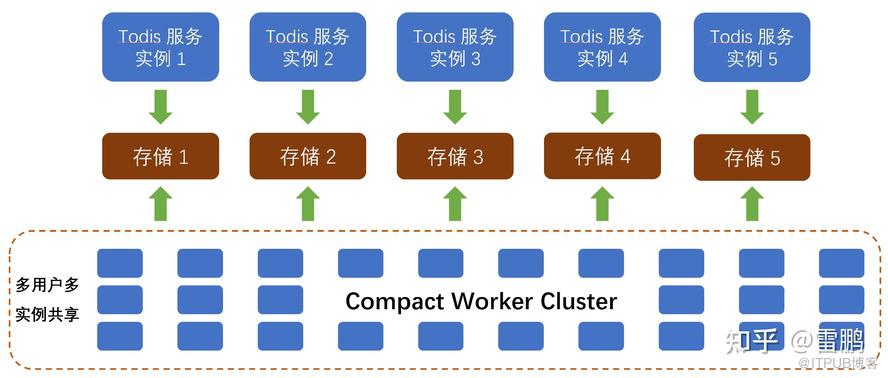
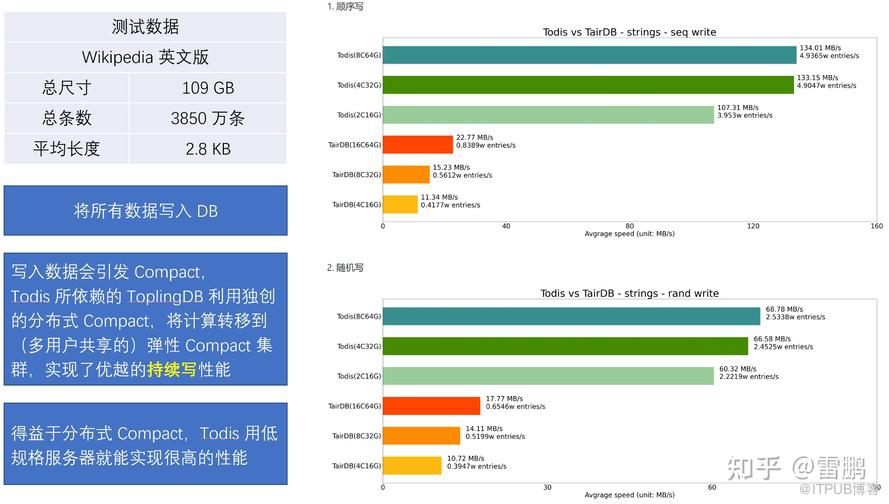
- 分布式 Compact,将 Compact 转移到专用的 Compact 服务器集群,
Todis(外存版 Redis) 使用 ToplingDB 存储引擎,是真正的云原生 DB,充分发挥云平台弹性伸缩优势,性能优异, 价格低廉,人性化( 监控& 观测)功能丰富