

7 月 11 日, Moonshot AI 正式发布并开源了 Kimi K2 模型。作为基于 MoE 架构的基础模型,其以 “Agentic AI” 为核心定位,总参数达 1 万亿、激活参数 320 亿,并非简单的聊天工具,而是能理解复杂意图、拆解任务并自主调用工具的 “ 数字员工 ” ,可高效完成多步骤复杂流程。
核心性能:12 项 SOTA 横扫三大赛道,多项指标比肩闭源模型
Kimi K2 在多个关键领域展现出强大实力,一举获得 12 项开源 SOTA 。在代码、数学、工具调用这三大核心赛道上超越 DeepSeek - V3 、 DeepSeek - R1 等顶尖开源模型。
• 代码生成:高效理解编程需求,生成高质量、高可读性代码,显著提升开发效率;
• 数学推理:精准应对复杂运算与逻辑推理任务,输出可靠解答;
• 工具调用:快速稳定调用各类工具,实现复杂任务自动化处理。
在闭源模型对比中,其表现同样亮眼:
• 多轮对话全球第一。
• 硬提示、编程任务全球第二。
• 长查询全球第五。
• 数学、创意写作、指令遵循全球第七。
技术创新
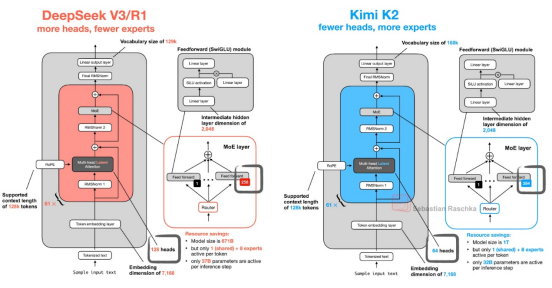
Kimi K2 采用稀疏 MoE 架构,通过动态激活专家模块提升参数利用率:总参数量 1 万亿,含 384 个专家,每个 token 动态选择 8 个专家计算,另设 1 个共享专家增强通用性,激活参数稳定在 320 亿。
训练层面,其采用改进的 MuonClip 优化器,有效解决大规模训练中梯度不稳定与收敛难题,支持模型在 15.5 万亿 tokens 的预训练规模下稳定运行,避免 “ 训练崩溃 ” ;同时, 128K 的最大上下文长度,使其在长文档理解、长对话及大规模检索任务中具备显著优势。
应用优势
• 编程领域:在 LiveCodeBench 互动式编程基准测试中准确率达 53.7% (超越 GPT-4.1 的 44.7% ), OJBench 竞赛题测试得分 27.1% ,印证对软件工程场景的深度适配;前端开发中,可生成含粒子系统、 3D 场景的交互性代码,兼具设计感与视觉表现力。
• Agent 工具调用:能稳定解析复杂指令并拆解为可执行的 ToolCall 结构,在 SWE-bench Verified 代码错误修复测试中单次尝试准确率 65.8% ,比肩部分专有模型;可处理 13 万行数据并生成带专业图表的分析报告。
• 多任务综合能力:Tau2-bench 加权值 66.1% (复杂 STEM 任务)、 AceBench (英文)准确率 80.1% (语言理解与生成)、 MMLU-Pro 多语言测试领先(跨学科能力), AIME 数学测评优于同类模型(深度建模潜力),同时登顶 EQ-Bench3 与 Creative Writing v3 (情商与创意写作)。

数据是 Kimi K2 能力的核心支撑: 15.5 万亿 tokens 的预训练数据奠定认知基础,而 Agentic Tool Use 合成数据则赋予其执行复杂现实任务的能力。二者的规模、质量与复杂性持续精进,推动模型在核心领域不断突破,向 “ 可信赖数字同事 ” 演进。
关于景联文
景联文科技为政府、企业客户提供高质量数据生产运营服务。结合市场AI 模型需求,提供从数据汇聚、数据治理、语料开发、语料沉淀、语料交易的全链条 “ 一站式数据服务 ” ,帮助客户释放数据价值。依托景联文 SolarSense 语料工程平台,解决数据价值落地 “ 最后一公里 ” 难题,赋能企业人工智能、政府人工智能、生成式人工智能使用语料。
公司将继续秉持 “ 成为人工智能的核心引擎,让每一比特数据释放 AI 的无限可能 ” 企业愿景,为中国 AI 崛起提供高质量数据集!