作者:杨琴1
原文链接:https://blog.csdn.net/2301_77888392/article/details/148206931
“KWDB创作者计划产品测评活动”是由KWDB联合 CSDN 推出的针对时序数据库产品测评及产品体验活动,本次活动主要面向KWDB开源版本2.2.0版本。
本次体验可以涵盖不同技术层面的用户,可以针对KWDB产品的分布式、多模融合、支持原生 AI 的数据库产品、兼容性、安全、并发、可靠性等多方面进行时序数据库产品的体验和测评,参与的同时既可以收获相关技术领域的实战经验同时也增加不同技术栈的实现方案。
一、前言:
本人接触并从事互联网开发工作有近7年了,从最开始的PHP和Swoole,到后面逐渐接触到的语言,如java、go、python、Node等,一直是与数据库(如:Mysql、MariaDB、PostgreSQL)进行打交道,从事的行业最多的是与电商项目系统开发。

 如上是公司从0到1电商系统的迭代演进过程,在考量自身的业务特性,以及所拥有或可调配的资源。只有明确了这些之后才能适度设计合适的架构,以确保可以为应用提供稳定的服务。从单机架构、动静分离架构、应用与数据分离架构、数据库主从架构、负载均衡架构都会大量使用到MySQL,无论是多复杂的架构,基本都会用到MySQL。
如上是公司从0到1电商系统的迭代演进过程,在考量自身的业务特性,以及所拥有或可调配的资源。只有明确了这些之后才能适度设计合适的架构,以确保可以为应用提供稳定的服务。从单机架构、动静分离架构、应用与数据分离架构、数据库主从架构、负载均衡架构都会大量使用到MySQL,无论是多复杂的架构,基本都会用到MySQL。

 最近通过CSDN的活动接触KWDB时序多模分布式数据库的产品,之前在工作中,一直是在使用关系型数据库为主导,偶尔使用一下Redis缓存来解决问题,今天来了解一下,KWDB 是一款面向 AIoT 场景的分布式、多模融合、支持原生 AI 的数据库产品。
最近通过CSDN的活动接触KWDB时序多模分布式数据库的产品,之前在工作中,一直是在使用关系型数据库为主导,偶尔使用一下Redis缓存来解决问题,今天来了解一下,KWDB 是一款面向 AIoT 场景的分布式、多模融合、支持原生 AI 的数据库产品。
①. 支持同一实例同时建立时序库和关系库并融合处理多模数据,具备时序数据高效处理能力,具有稳定安全、高可用、易运维等特点。
②. 面向工业物联网、数字能源、车联网、智慧产业等领域.
③. KWDB 提供一站式数据存储、管理与分析的基座。
综合以上的特点:思考一下,我们的回溯系统就是类似多个设备上传回溯相关的系统到服务器,而且同一个设备也不会在同一时间上传多个数据,分析符合以下的场景:

 ①. 数据量基数大:时序数据体量庞大,用户下单的所有轨迹流程都需要记录下来。
①. 数据量基数大:时序数据体量庞大,用户下单的所有轨迹流程都需要记录下来。
②. 同一个下单的数据具有连续性和相关性:在用户下单时,rrweb会产生很多DOM节点记录的数据,这些时序数据点之间存在时间上的连续性和相关性。
③. 高频数据写入:公众号的用户数据很大,特别在双11、双12、618等时序数据通常具有高频采样的特点,所以,数据写入操作非常频繁。
那么,即然时序数据库可以很好的解决这些问题的话,现在让我们来了解并动手实践KWDB时序多模分布式数据库。
二、KWDB分布式、多模融合数据库简介:
注意:KaiwuDB是企业版本,KWDB是基于KaiwuDB开源出来的社区版本,本文中所有涉及到的产品体验都是KWDB社区开源版本。
2.1 KWDB简介:
KWDB 是一款面向 AIoT 场景的分布式、多模融合、支持原生 AI 的数据库产品,支持同一实例同时建立时序库和关系库并融合处理多模数据,具备时序数据高效处理能力,具有稳定安全、高可用、易运维等特点。面向工业物联网、数字能源、车联网、智慧产业等领域,KWDB 提供一站式数据存储、管理与分析的基座。




2.2 KWDB适合的应用场景:
目前,KWDB 在工业物联网、数字能源、数字政务、金融等领域均已成功完成落地实践。未来,KWDB 能够赋能工业物联网、数字能源、车联网、智慧矿山等各大行业领域,助力企业从数据中挖掘更大的商业价值。

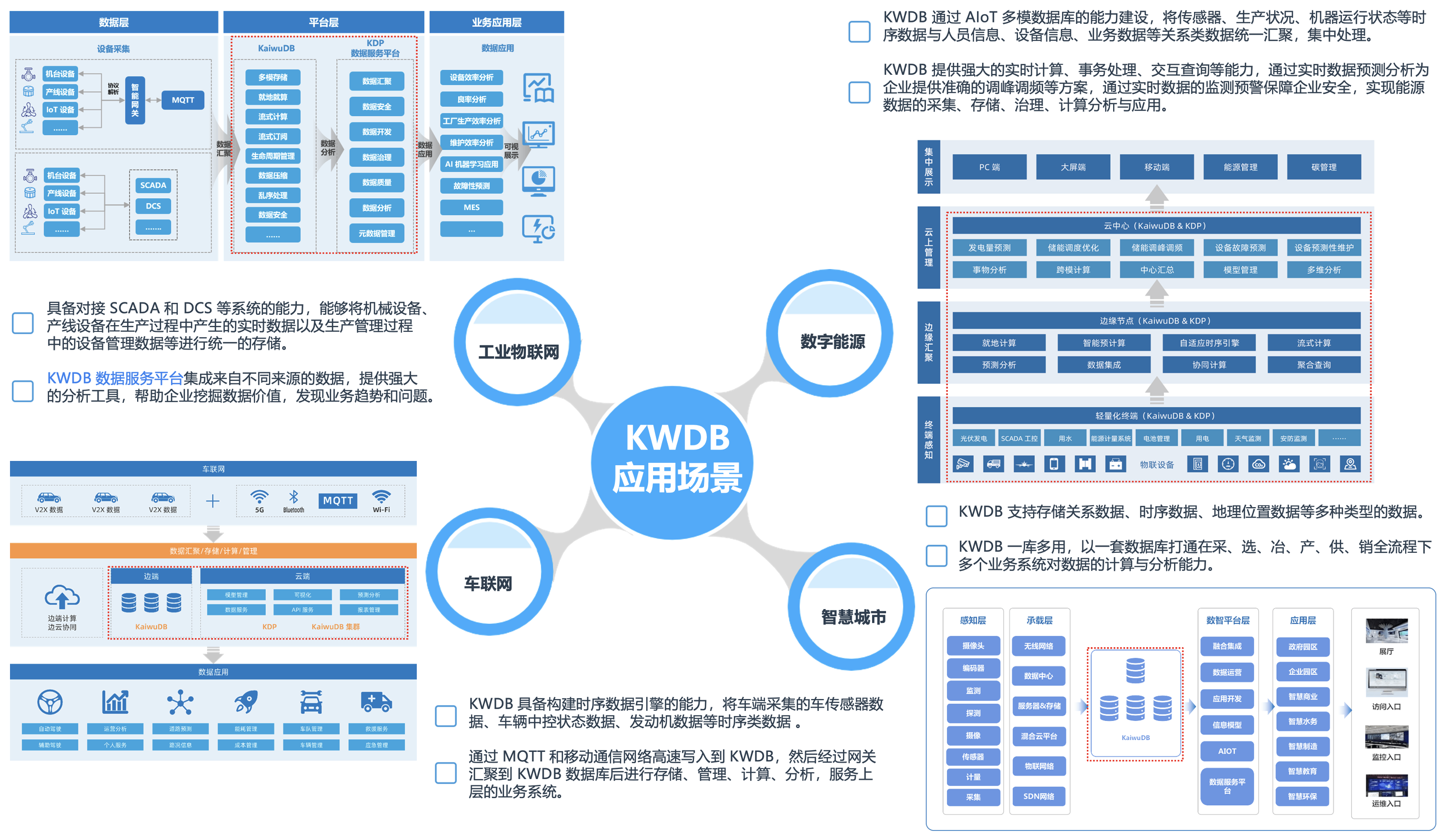 在多个KWDB应用场景,通过使用KWDB数据库解决了高可靠性、实时性、大规模、高并发、高精度、易扩展等在内的各种要求。同时,也解决了其它的数据库管理“难点”,如数据安全、数据质量、数据管理等:
在多个KWDB应用场景,通过使用KWDB数据库解决了高可靠性、实时性、大规模、高并发、高精度、易扩展等在内的各种要求。同时,也解决了其它的数据库管理“难点”,如数据安全、数据质量、数据管理等:
①. KWDB 支持毫秒级数据快速入库,单节点每秒百万级,通过“就地计算”重点技术,能极大提升数据读写性能;支持多种聚合查询,针对千万级数据可实现毫秒级的响应。
②. KWDB 具备超过 10 倍的数据压缩能力,完善的数据生命周期管理及降采样查询能力可将存储成本降低 90%,支持多模,可实现一套数据库应对多种数据存储和计算场景,构建统一数据共享存储;云边端一体化建设,降低系统的复杂度和冗余度,降低系统建设和人工成本。
三、 KWDB分布式、多模融合数据库安装与部署:
由于KWDB社区开源版本没有像云厂商,比如,阿里云直接提供MySQL、TDSQL直接在云上支持实例购买的方式。那么,我们只能通过手动来搭建KWDB数据库实例,这里支持2种模式的搭建:
①. KWDB 单节点裸机部署,所有计算任务和数据都在一台计算机上处理,受限于单台机器的计算能力、内存和存储空间等资源,容易出现性能瓶颈,且一旦服务器故障,整个系统可能完全不可用,只适合中小型项目规模的部署方式。
②. KWDB 集群部署,数据存储在多台服务器上,每台服务器都有数据的完整副本,实现了数据的冗余和高可用性,数据访问请求会被分发到不同的服务器上进行处理,实现了负载均衡,适合中大型项目,特别是大型物联网IoT场景,强烈推荐。
3.1 KWDB分布式、多模融合数据库部署的方式:
对于KWDB数据库构建,官方提供了3种方式,可以选择您比较擅长的任意一种方式进行本地或云上服务器部署 KWDB 数据库:
①. 单节点/集群裸机部署,本人擅长这种模式。
②. 单节点/集群容器部署。
③. 单节点/集群开源版本源码编译部署。
3.2 环境准备以及准备工作:
在安装KWDB单节点裸机数据库前,有一些硬件和软件的要求,硬件最好单节点配置建议不低于 4 核 8G,另外,有一些必须要安装软件libprotobuf也需要安装一下。

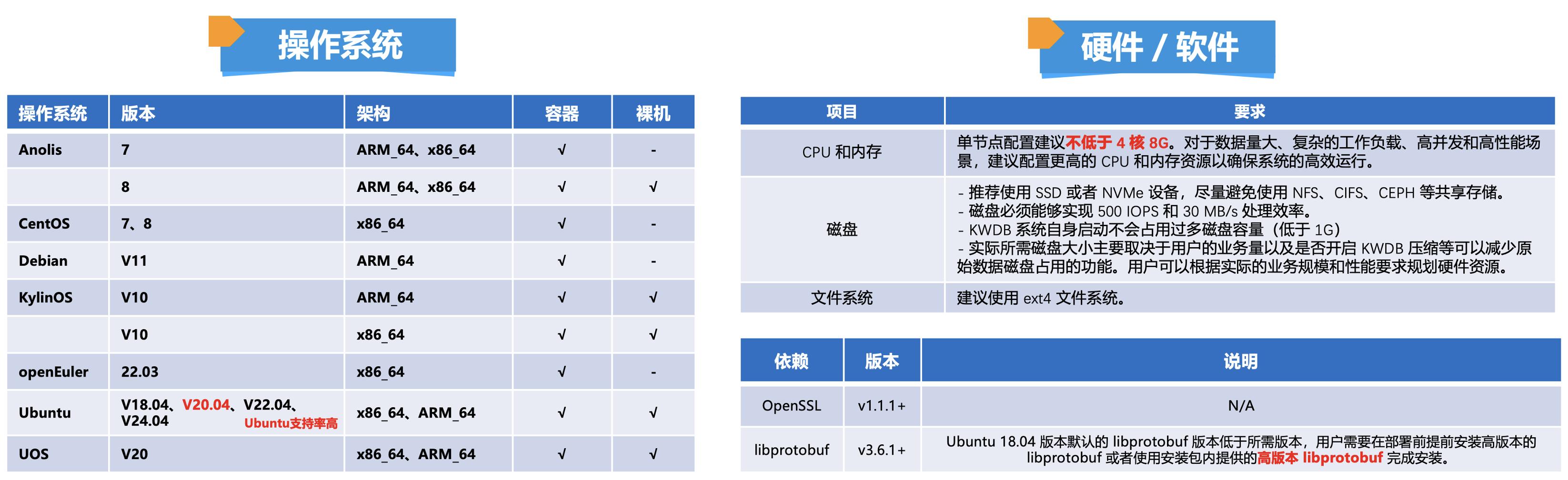 可以看到Ubuntu对版本与CPU的架构支持还是比较高的,不管是容器和裸机都是可以进行安装测试的,那么我们这里就以Ubuntu 20.04.1 LTS (GNU/Linux 5.4.0-216-generic x86_64)来进行实验。
可以看到Ubuntu对版本与CPU的架构支持还是比较高的,不管是容器和裸机都是可以进行安装测试的,那么我们这里就以Ubuntu 20.04.1 LTS (GNU/Linux 5.4.0-216-generic x86_64)来进行实验。
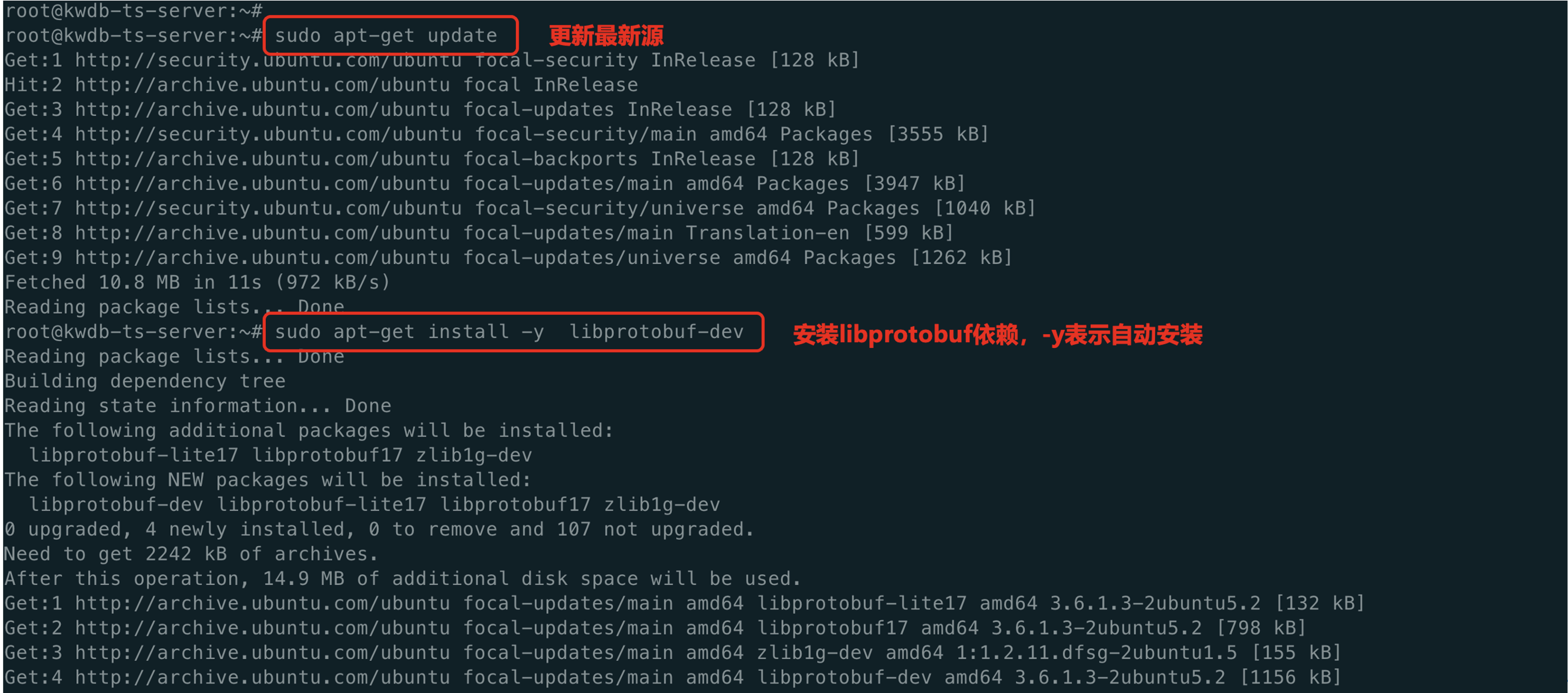
# sudo apt-get update
# sudo apt-get install -y libprotobuf-dev

3.3 单节点裸机KWDB数据库部署:
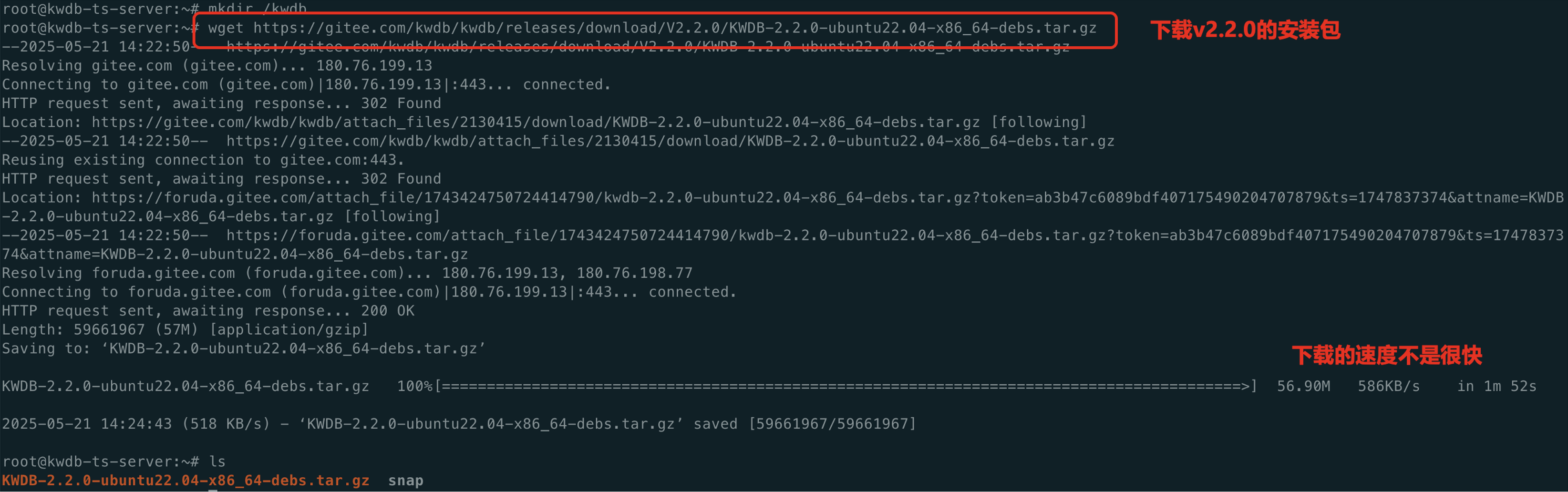
打开官网https://gitee.com/kwdb/kwdb/releases,这次我们进行测试的是V2.2.0的版本,所以,直接下载对应的Ubuntu x86的安装包即可,也可以使用wget命令来进行安装。
# mkdir /kwdb
# cd /kwdb
# wget
https:
//gitee.com/kwdb/kwdb/releases/download/V2.2.0/KWDB-2.2.0-ubuntu22.04-x86_64-debs.tar.gz

# tar zxvf KWDB-2.2.0-ubuntu22.04-x86_64-debs.tar.gz

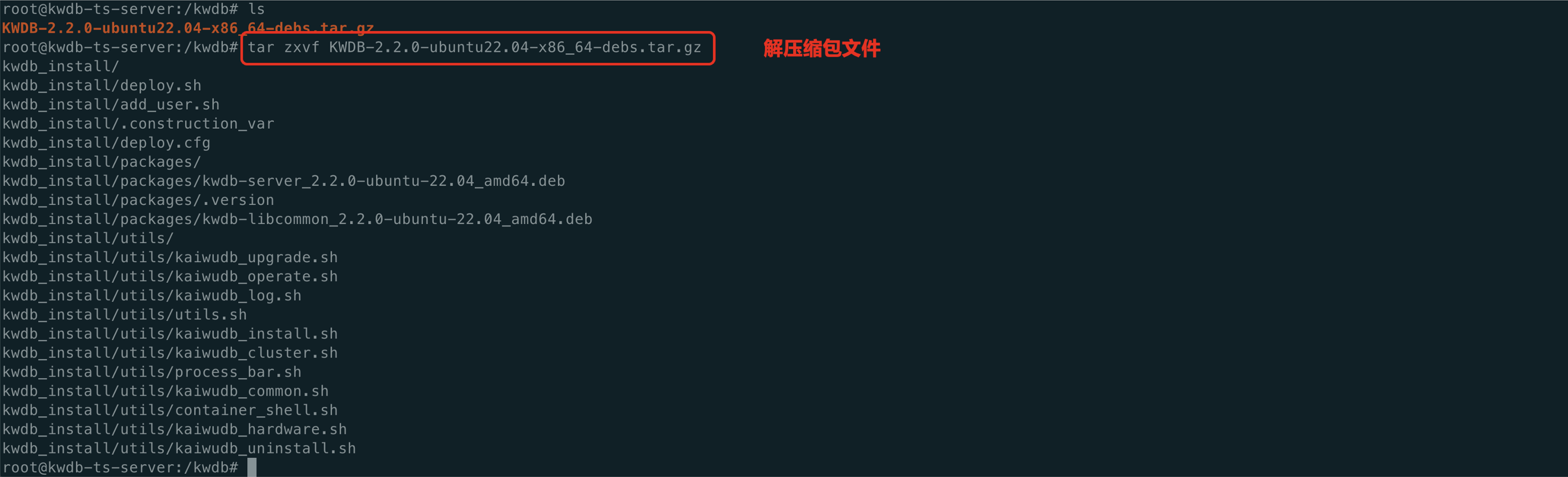 ①. 修改一下deploy.cfg配置文件,将node_addr修改为自己本面的IP地址,并且将cluster属性注释掉,因为目前是先试一下单节点裸机KWDB数据库部署,所以不需要使用这块。
①. 修改一下deploy.cfg配置文件,将node_addr修改为自己本面的IP地址,并且将cluster属性注释掉,因为目前是先试一下单节点裸机KWDB数据库部署,所以不需要使用这块。
②. 在安装时,需要提示输入密码,我输入了1234也通过了,建议密码可以做一下校验,符合一定的密码复杂度要求,最后即可安装成功。
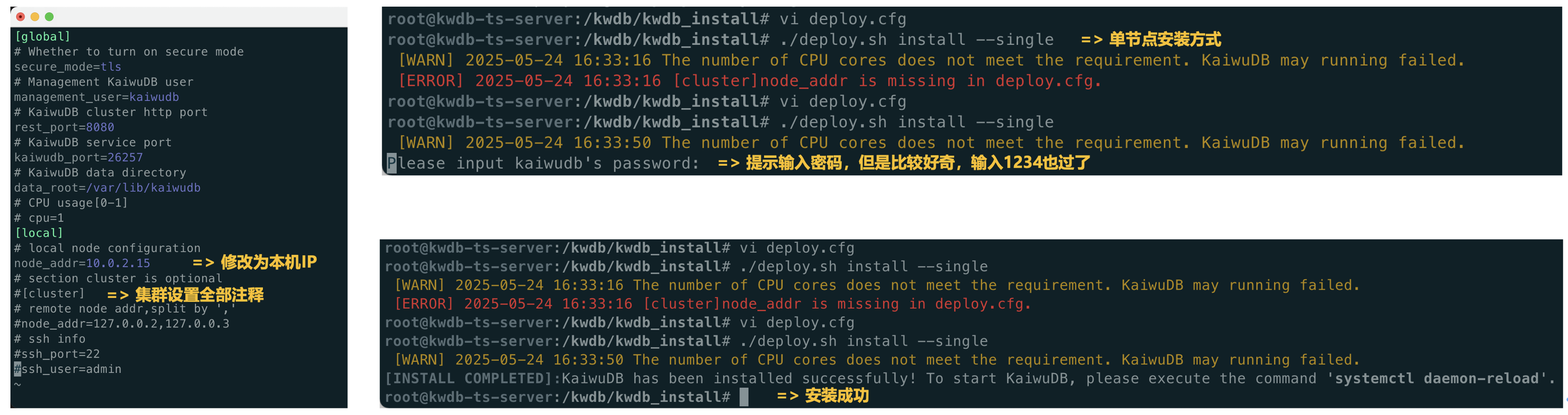
# ./deploy.
sh install --single
# systemctl daemon-reload
# systemctl start kaiwudb.
service
# systemctl status kaiwudb

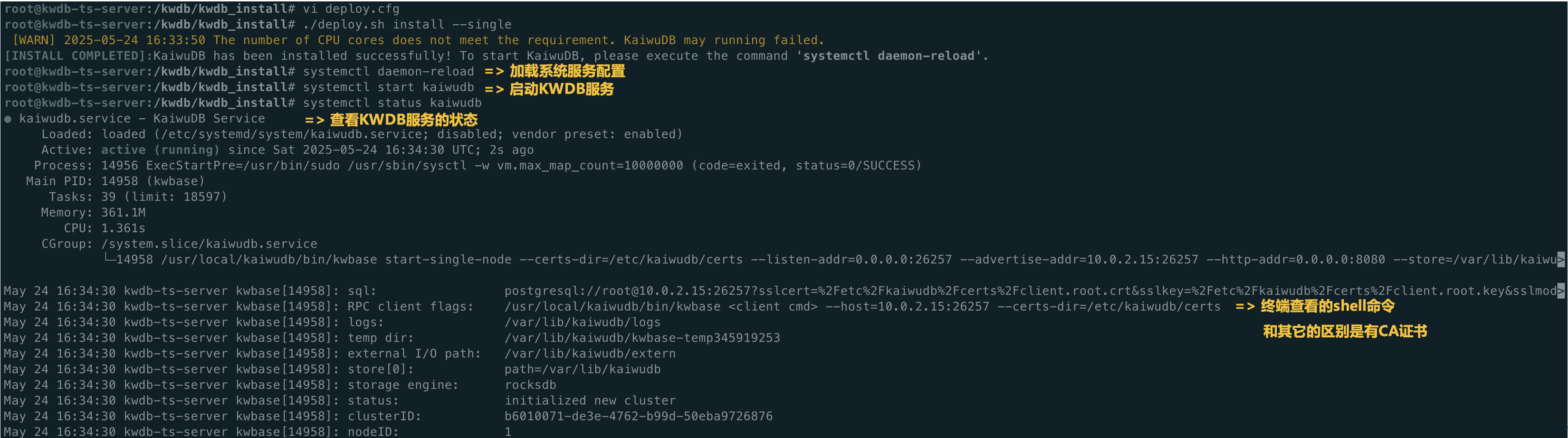 这里有一个问题是,当我第二天启动机器,发现昨天明明启动的服务,就暂停服务了,为了解决这个问题,可以使用开机自动启动的系统管理服务,这样后面在机器开机或者重启后,就不需要手动再次进行启动服务。
这里有一个问题是,当我第二天启动机器,发现昨天明明启动的服务,就暂停服务了,为了解决这个问题,可以使用开机自动启动的系统管理服务,这样后面在机器开机或者重启后,就不需要手动再次进行启动服务。
# systemctl enable kaiwudb

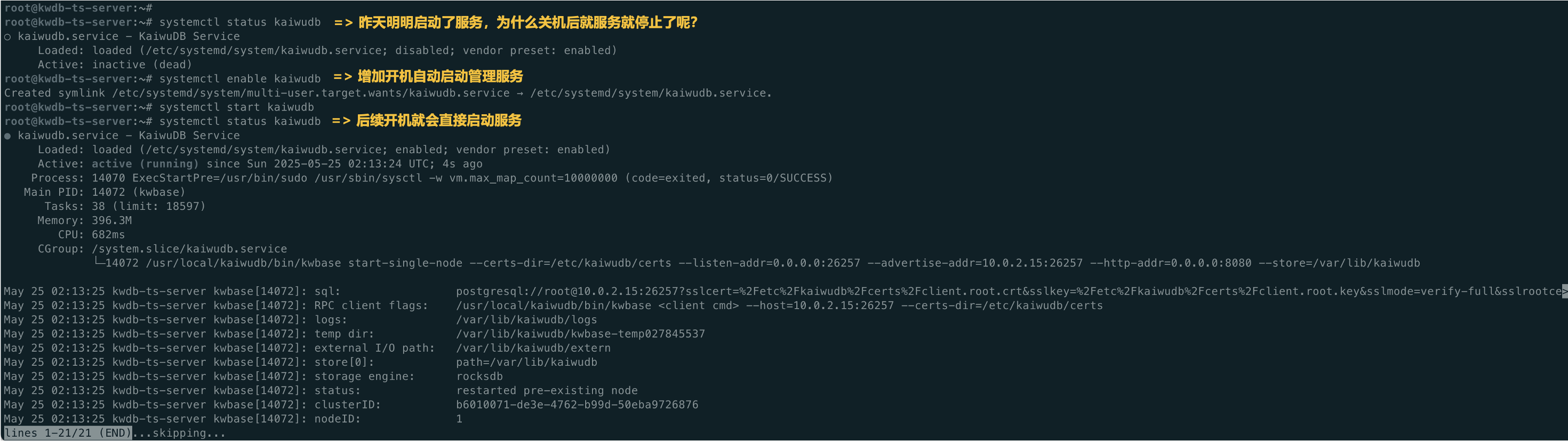 以下表示KWDB数据库已成功安装,可以看到,步骤也是比较简单,没有太多复杂的操作,接下来可以来对时序数据库进行操作。
以下表示KWDB数据库已成功安装,可以看到,步骤也是比较简单,没有太多复杂的操作,接下来可以来对时序数据库进行操作。
四、KWDB分布式、多模融合数据库管理 - 新零售可视化回溯系统搭建:
上面通过安装程序包的方式已经安装了KWDB单节点裸机时序数据库,接下来,我们来进行“新零售可视化回溯系统”的搭建,以下是相关思路:

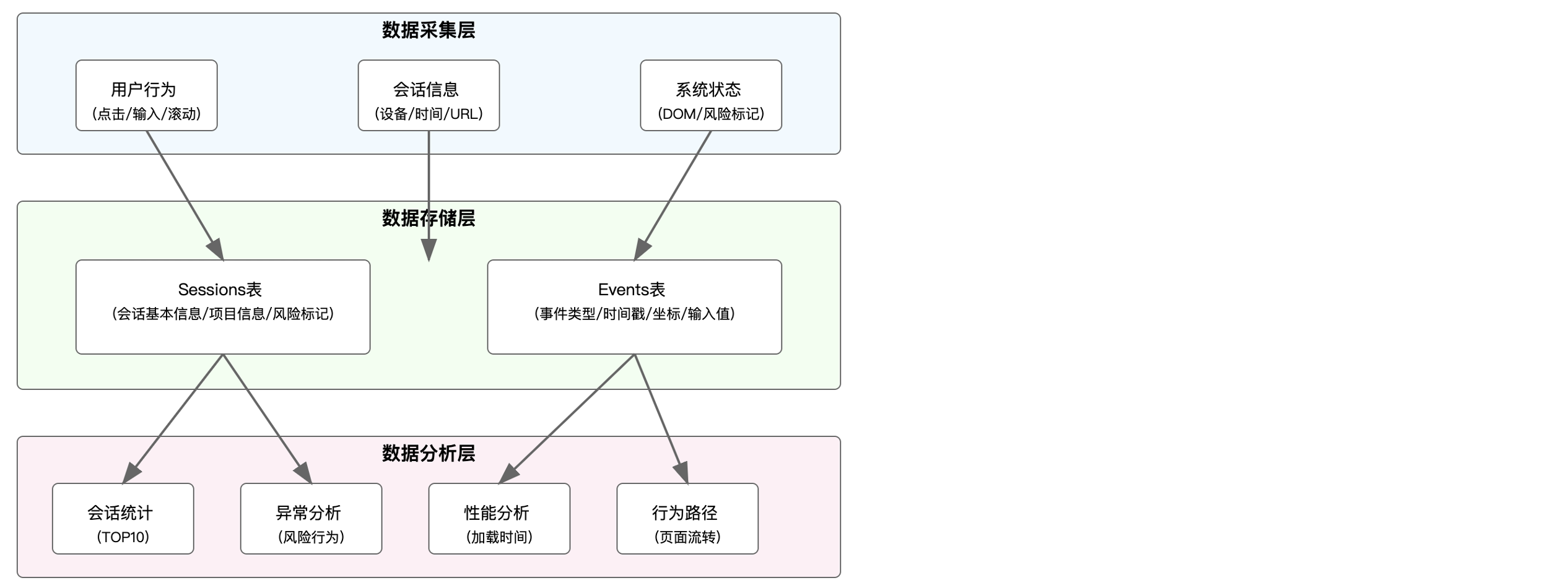 ①. 分析“新零售可视化回溯系统”的需求评审,了解业务的相关需求。
①. 分析“新零售可视化回溯系统”的需求评审,了解业务的相关需求。
②. 创建时序数据表、设计数据表结构。
③. 写代码实现功能。


4.1 TLS安全模式下操作KWDB客户端Shell控制台连接数据库实例:
可以通过以下命令来连接KWDB客户端Shell控制台中,不过,KWDB也提供了其它的可视化连接工具,可以去官网文档(https://www.kaiwudb.com/template_version/pc/doc/)中自行探索使用。
# /usr/local/kaiwudb/bin/kwbase sql --host=10.0.2.15:26257 --certs-dir=/etc/kaiwudb/certs
连接之后,大多数的SQL DLL命令是比较通用的,但是,由于之前也没有接触过时序数据库,在创建的过程中,也会发现一些问题:
①. 有些关系型的字段是不支持的,比如jsonb字段、text字段.
②. 在时序数据库中是不可以进行创建关系型数据表的。
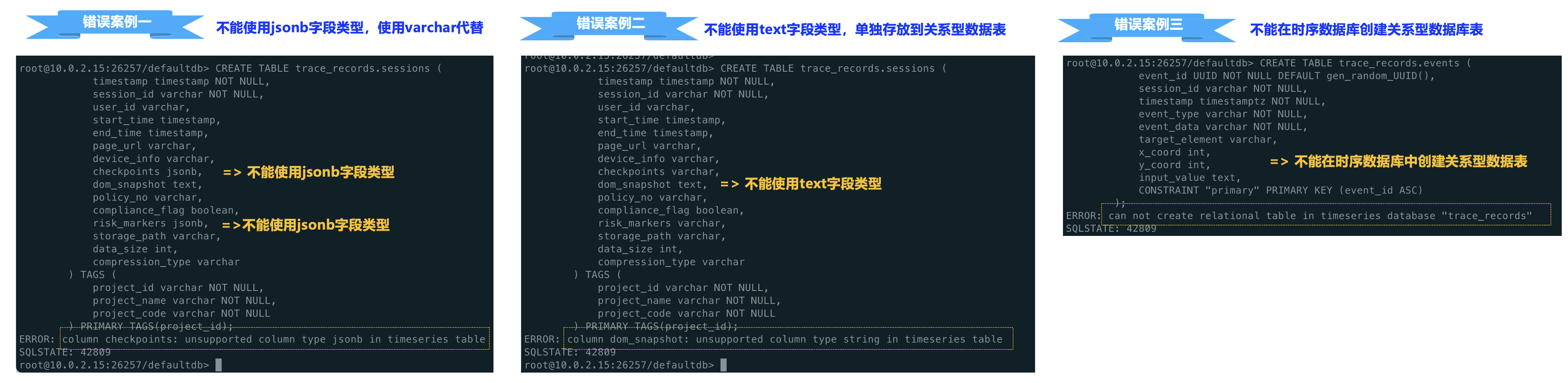

因为回溯的数据是一大段文本,在几百kb左右,但是时序数据库又不支持,所以,只能拆成两张表,一张存放时序数据,一张存放关系型数据:
时序数据表trace_records.sessions:
REATE
TABLE trace_records.
sessions (
timestamp timestamptz
NOT
NULL,
session_id varchar
NOT
NULL,
user_id varchar,
start_time timestamptz,
end_time timestamptz,
page_url varchar,
device_info varchar,
checkpoints varchar,
dom_snapshot varchar,
policy_no varchar,
compliance_flag boolean,
risk_markers varchar,
storage_path varchar,
data_size int,
compression_type varchar
)
TAGS (
project_id varchar
NOT
NULL,
project_name varchar
NOT
NULL,
project_code varchar
NOT
NULL
)
PRIMARY
TAGS(project_id);
关系数据表re_trace_records.events:
CREATE
TABLE re_trace_records.
events (
event_id
UUID
NOT
NULL
DEFAULT
gen_random_UUID(),
session_id varchar
NOT
NULL,
timestamp timestamptz
NOT
NULL,
event_type varchar
NOT
NULL,
event_data varchar
NOT
NULL,
target_element varchar,
x_coord int,
y_coord int,
input_value text,
CONSTRAINT
"primary"
PRIMARY
KEY (event_id
ASC)
);
4.2 代码实现过程 – 数据插入部分:
开放数据库连接(Open Database Connectivity,ODBC)是一种应用程序编程接口(Application Programming Interface,API),为应用程序访问数据库存储的信息提供了一种标准。ODBC 为异构数据库访问提供统一接口,实现异构数据库间的数据共享。使用 ODBC API 的应用程序可以访问任何符合 ODBC 标准的数据库中的数据,通常无需修改应用程序代码。
通过代码连接KWDB数据库实例,这里演示的代码是Goland,当然,还有其它很多的语言也是可以支持的,比如Java、Node.js、Python、PHP等语言,甚至Rust语言也是支持的。
数据库连接代码:

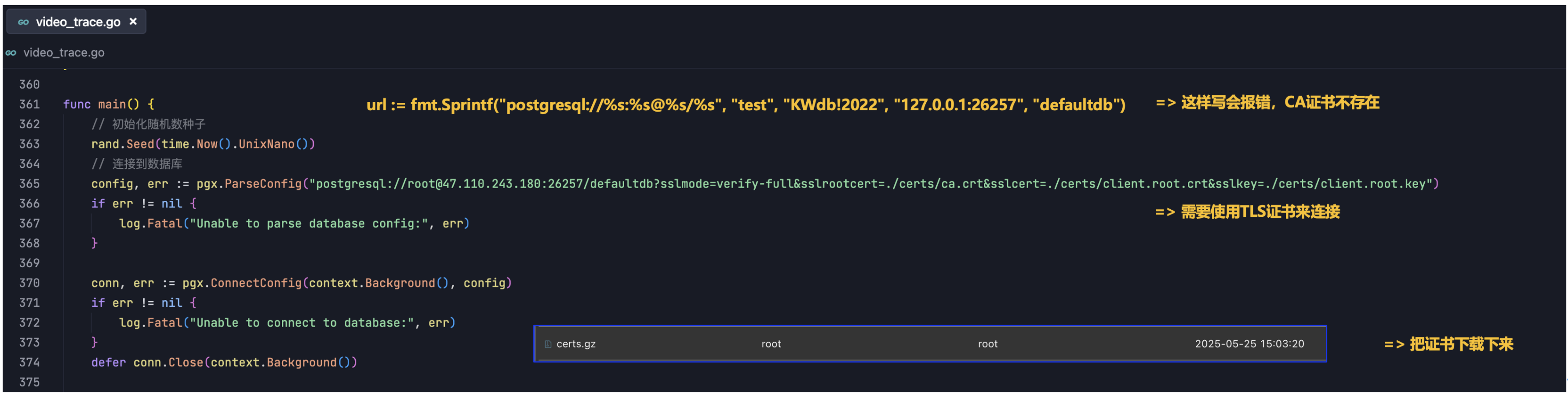 默认情况下,KaiwuDB 采用 TLS 安全模式部署 KaiwuDB 集群。用户可以编辑 KaiwuDB 安装包目录下的 deploy.cfg 配置文件,选择启用 TLCP 安全模式或禁用安全模式。
默认情况下,KaiwuDB 采用 TLS 安全模式部署 KaiwuDB 集群。用户可以编辑 KaiwuDB 安装包目录下的 deploy.cfg 配置文件,选择启用 TLCP 安全模式或禁用安全模式。
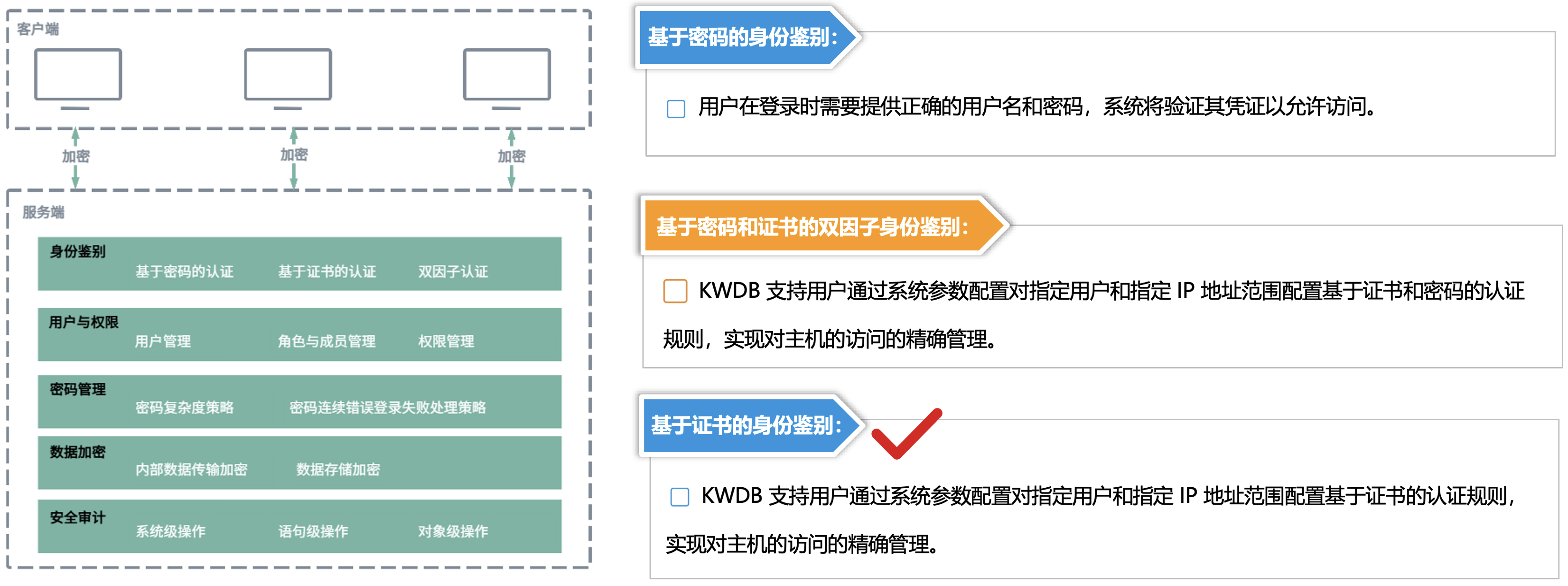

如果没有使用证书,这里会报一个错,因为我们当时安装的时候,是选择的是TLS模式,KWDB 支持用户通过系统参数配置对指定用户和指定 IP 地址范围配置基于证书的认证规则,实现对主机的访问的精确管理。
2025/
05/
25
14:
44:
51
Unable to connect to
database:failed to connect to
`host=47.110.243.180 user=root database=trace_records`: server
error (
ERROR: password authentication failed
for user
root (
SQLSTATE
XXUUU))
exit status
1
CA证书一般默认情况下,部署完 KWDB 后,生成的相关 TLS 或 TLCP 证书存放在 /etc/kaiwudb/certs 目录。
时序数据表seesion数据生成:
为了方便验证KWDB数据库实例的并发性、高性能、数据插入的时效性,这里只能模拟大批量的数据进行并发请求,数据生成的部分可以分为三块:数据随机生成、数据字段映射、数据插入:
①. 使用rand.Intn产生随机数去匹配数组中的枚举值,达到随机抽取功能,使用now.Add(-time.Duration(30+rand.Intn(60)) * time.Minute)函数可以达到进行减去30-60分钟的一个随机时间。
②. 通过构造会话数据,将上面字段随机生成的值与字段进行映射绑定。
③. 使用db.Exec(context.Background())来执行批量的SQL语句。
使用 InsertSampleData函数模拟了数据插入的过程,在实际应用中,这里可以添加将数据插入数据库或其他存储系统的代码。

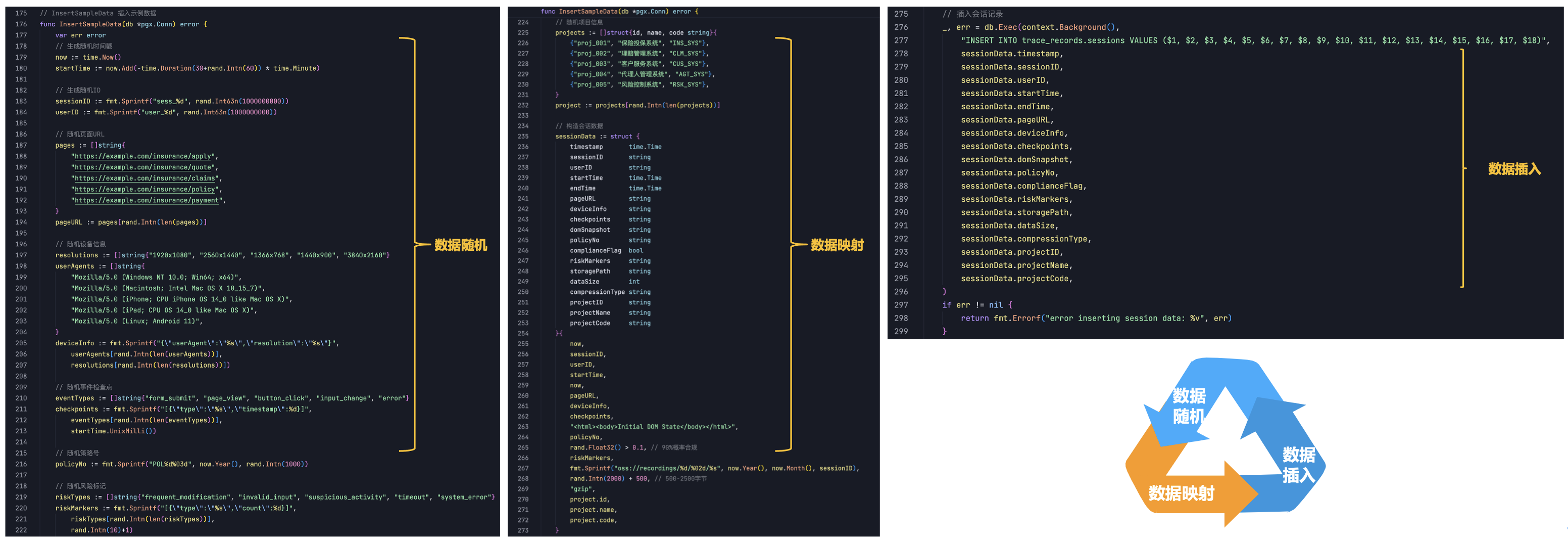 当运行上述代码时,可以生成一批随机的数据,将对这些数据进行字段映射。最后,将模拟插入数据的过程,打印出插入的数据信息。这样,整个数据生成、字段映射和数据插入的过程就完成了。
当运行上述代码时,可以生成一批随机的数据,将对这些数据进行字段映射。最后,将模拟插入数据的过程,打印出插入的数据信息。这样,整个数据生成、字段映射和数据插入的过程就完成了。
events数据生成:
同理,这是events回溯数据存放到关联数据库,所以,可以使用text字段。
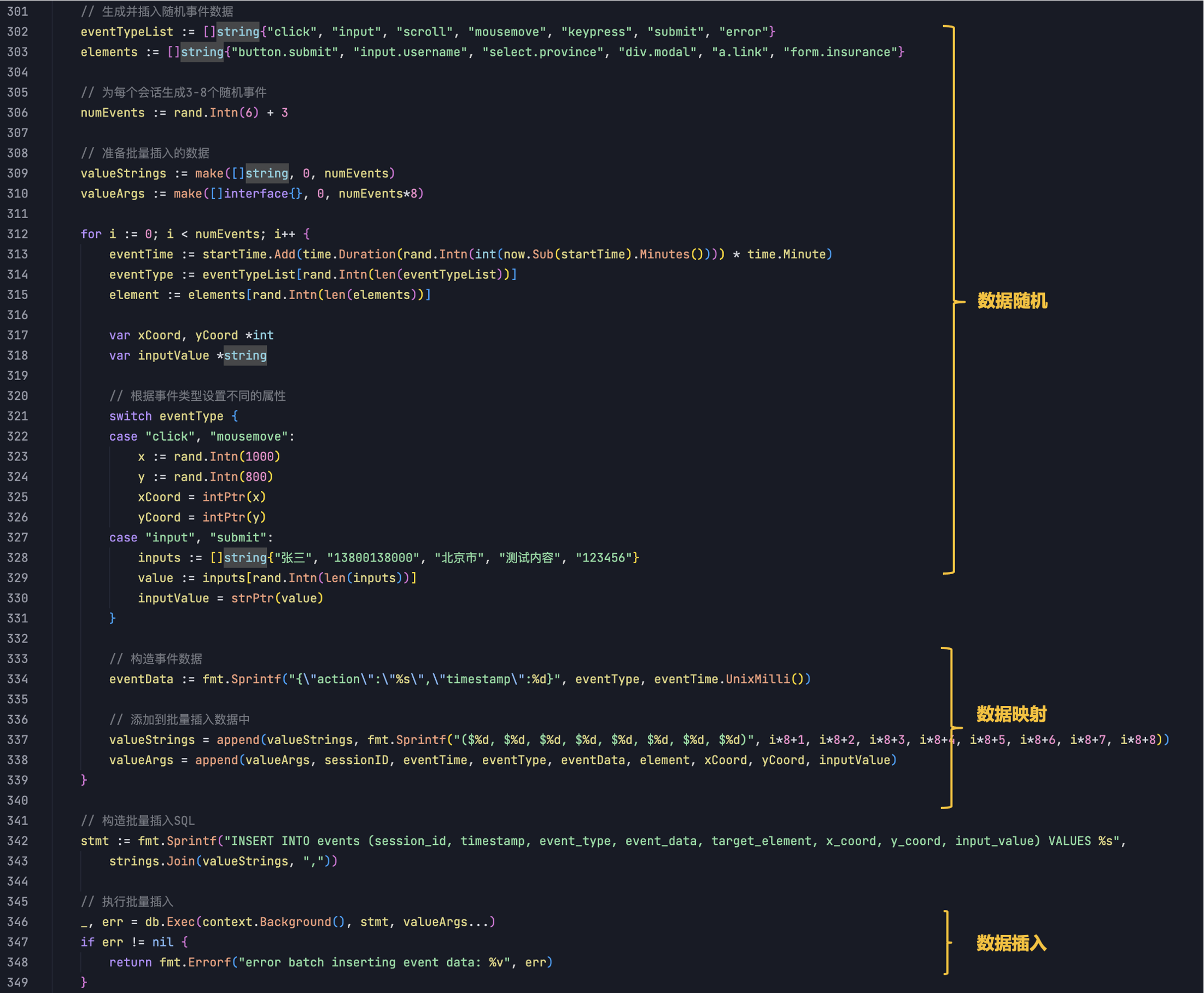

思考?
因为是2种数据库类型,思考怎么样在一个脚本,同时,操作2个数据库呢?这样可以模拟在数据产生的时候,来看看2种数据库的插入数据性能表现一致吗?哪个库有性能瓶颈问题呢?持续数据库插入对数据库的多模是否稳定呢?

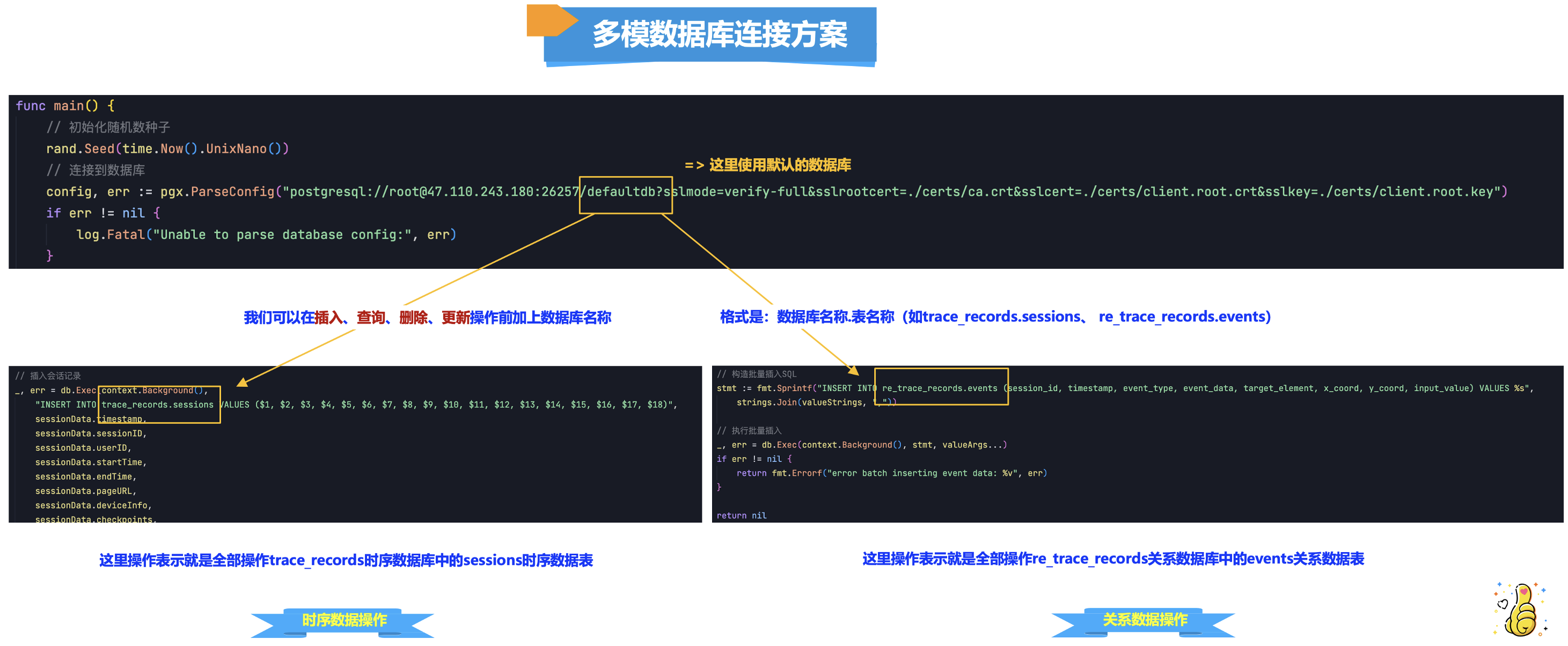 这样的话,该方案就可以通过明确区分数据库名称与表名称,来进行读写操作路由区分开来,这种场景非常的普遍,对于KWDB多模分布式数据库的话,不仅仅是为了使用时序数据库,更能灵活的使用。
这样的话,该方案就可以通过明确区分数据库名称与表名称,来进行读写操作路由区分开来,这种场景非常的普遍,对于KWDB多模分布式数据库的话,不仅仅是为了使用时序数据库,更能灵活的使用。


最后,可以看到运行脚本,数据嘎嘎的往上噌,这里可以看到因为是1对多的关系,所以,events的数据量要多余sessions的数据量,那么这里就是后端代码基本上完成了,接下来,我们可以进行前端的代码编写。
4.3 前端代码回溯events代码收集:
rrweb是一个用于记录和回放网页DOM变化的库,由rrweb、rrweb-player和rrweb-snapshot组成。它通过MutationObserver监听DOM变化,使用增量快照记录并序列化DOM,然后在回放时根据时间戳还原。回放过程在沙箱环境中进行,采用自定义计时器实现帧同步。rrweb适用于用户行为回溯、错误监控等场景。


基于 rrweb 去实现录屏,emit 回调方法可以拿到 DOM 变化对应所有 event,可以根据业务需求去做处理在 emit 内部做处理,可以看到是通过limitCount和limitSize这2个参数来控制时序数据上传的周期,上传的主要数据就是右边的events DOM节点数据,其实就是将DOM节点元素,将样式(如颜色、字体大小)这些东西记录下来。

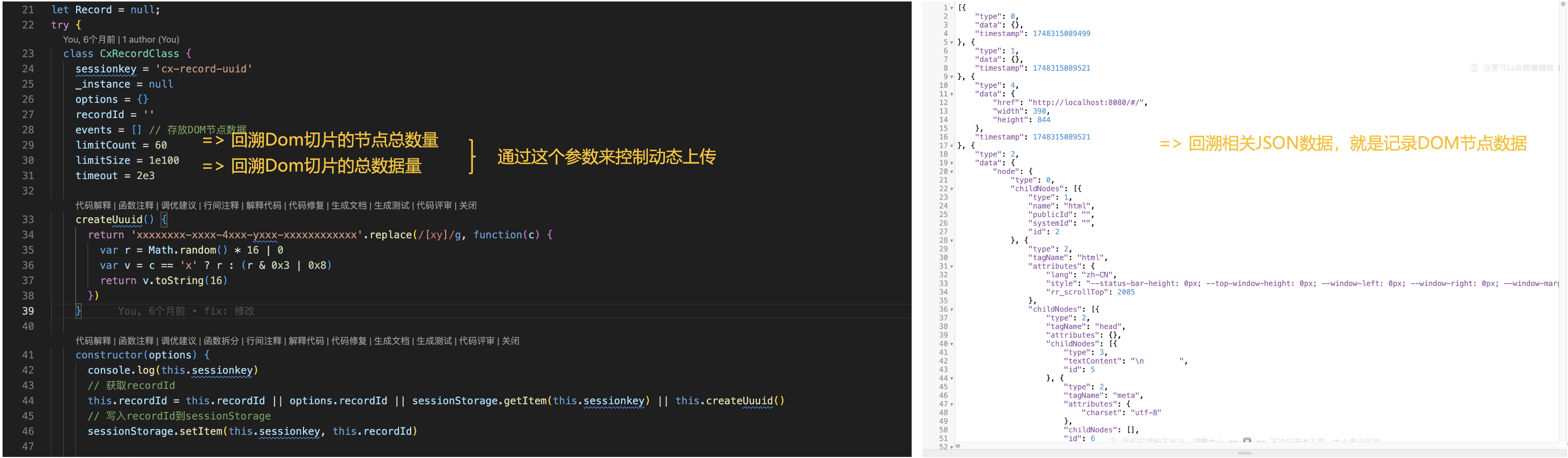
import { record }
from
'rrweb'
let
Record =
null;
try {
class
CxRecordClass {
sessionkey =
'cx-record-uuid'
_instance =
null
options = {}
recordId =
''
events = []
// 存放DOM节点数据
limitCount =
10
limitSize =
1e100
timeout =
2e3
createUuuid(
) {
return
'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.
replace(
/[xy]/g,
function(
c) {
var r =
Math.
random() *
16 |
0
var v = c ==
'x' ? r : (r &
0x3 |
0x8)
return v.
toString(
16)
})
}
constructor(
options) {
console.
log(
this.
sessionkey)
// 获取recordId
this.
recordId =
this.
recordId || options.
recordId ||
sessionStorage.
getItem(
this.
sessionkey) ||
this.
createUuuid()
// 写入recordId到sessionStorage
sessionStorage.
setItem(
this.
sessionkey,
this.
recordId)
// 参数初始化
this.
options.
limitCount = options.
limitCount ||
this.
limitCount
this.
options.
limitSize = options.
limitSize ||
this.
limitSize
// 单例模式
if (
new.
target !==
CxRecordClass) {
return
}
if (!
CxRecordClass.
_instance) {
this.
name =
'xm'
CxRecordClass.
_instance =
this
}
return
CxRecordClass.
_instance
}
record(
) {
const self =
this
record({
// emit会监听所有的DOM的动作, 鼠标等,
emit(
event) {
// 将 event 存入 events 数组中
self.
events.
push(event);
// 判断是否上传接口
(self.
events.
length >= self.
options.
limitCount ||
JSON.
stringify(self.
events).
length > self.
options.
limitSize) && self.
save()
// console.log(self.events, self.options);
// this.eventIndex++,
// (3 === this.eventIndex || this.events.length >= this.options.limitCount || JSON.stringify(this.events).length > this.options.limitSize) && this.save(!1)
}
})
}
// 阶段性上传数据,但不停止录屏
stageUpload(
) {
this.
checkNotUpload()
}
// 重新录屏,会产生新的recordId,用于连续多次投保需要重新录制,产生多个视频
reset(
) {
this.
checkNotUpload()
this.
recordId =
this.
createUuuid()
this.
events = []
sessionStorage.
setItem(
this.
sessionkey,
this.
recordId)
}
checkNotUpload(
) {
this.
save()
}
save(
) {
// 判断是否有events
if (
this.
events.
length ===
0) {
return
}
// 发送请求
const eventJson =
this.
events
this.
events = []
// 发送请求
// 1.实例化异步对象 内置的,通过它 不刷新页面发送请求
const xhr =
new
XMLHttpRequest()
// 2.设置请求的 地址 和方法
// 没有params属性,需要自行拼接
let url =
'traceable-service/api/v1/insureRecord/collect';
if (
/\/\/test-/.
test(location.
href) ||
/\/\/localhost/.
test(location.
href)) {
url =
'traceable-service/api/v1/insureRecord/collect';
}
xhr.
open(
'post', url)
// post请求 一定要设置请求头
xhr.
setRequestHeader(
'content-type',
'application/json'
)
// 3.注册回调函数服务器响应内容回来之后触发
xhr.
addEventListener(
'load',
function(
) {
// response响应
console.
log(xhr.
response)
})
// 4.发送请求post请求参数url格式化拼接多个参数用&符隔开
xhr.
send(
JSON.
stringify({
....数据拼装
}))
}
getTraceId(
) {
return
sessionStorage.
getItem(
this.
sessionkey) ||
''
}
}
Record =
new
CxRecordClass({
recordId:
'' })
Record.
record()
}
catch (error) {
}
可以打开一下浏览器F12的调试模式观察,在用户进行操作的时候,会产生多个collect的接口发送数据,而且发送的数据中相关的events的上报DOM节点的数据量还不小。
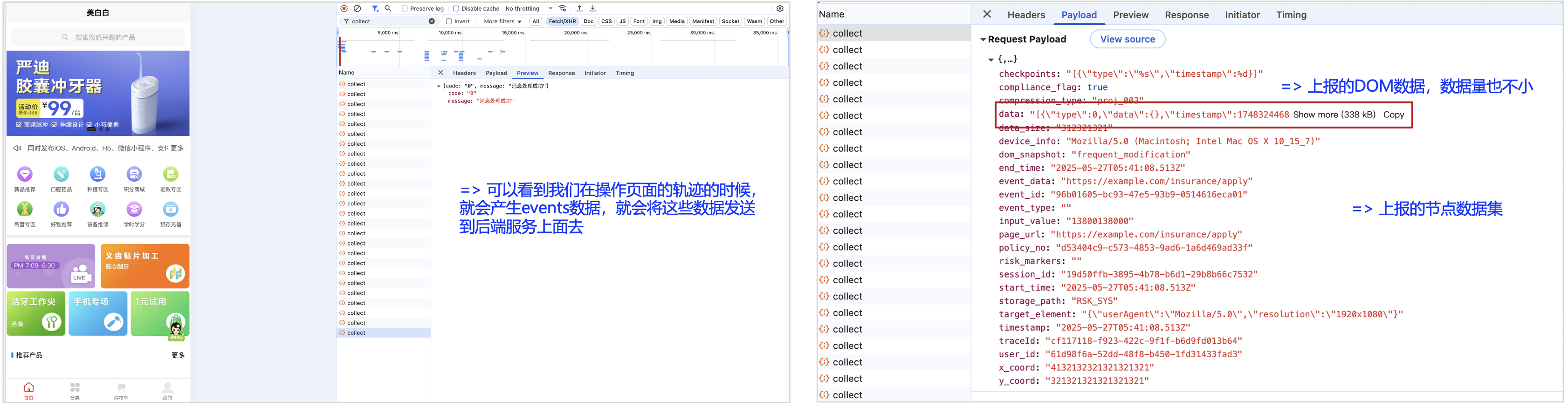

也可以来查看一下我上传的相关操作视屏:
4.4 数据脚本结果分析:
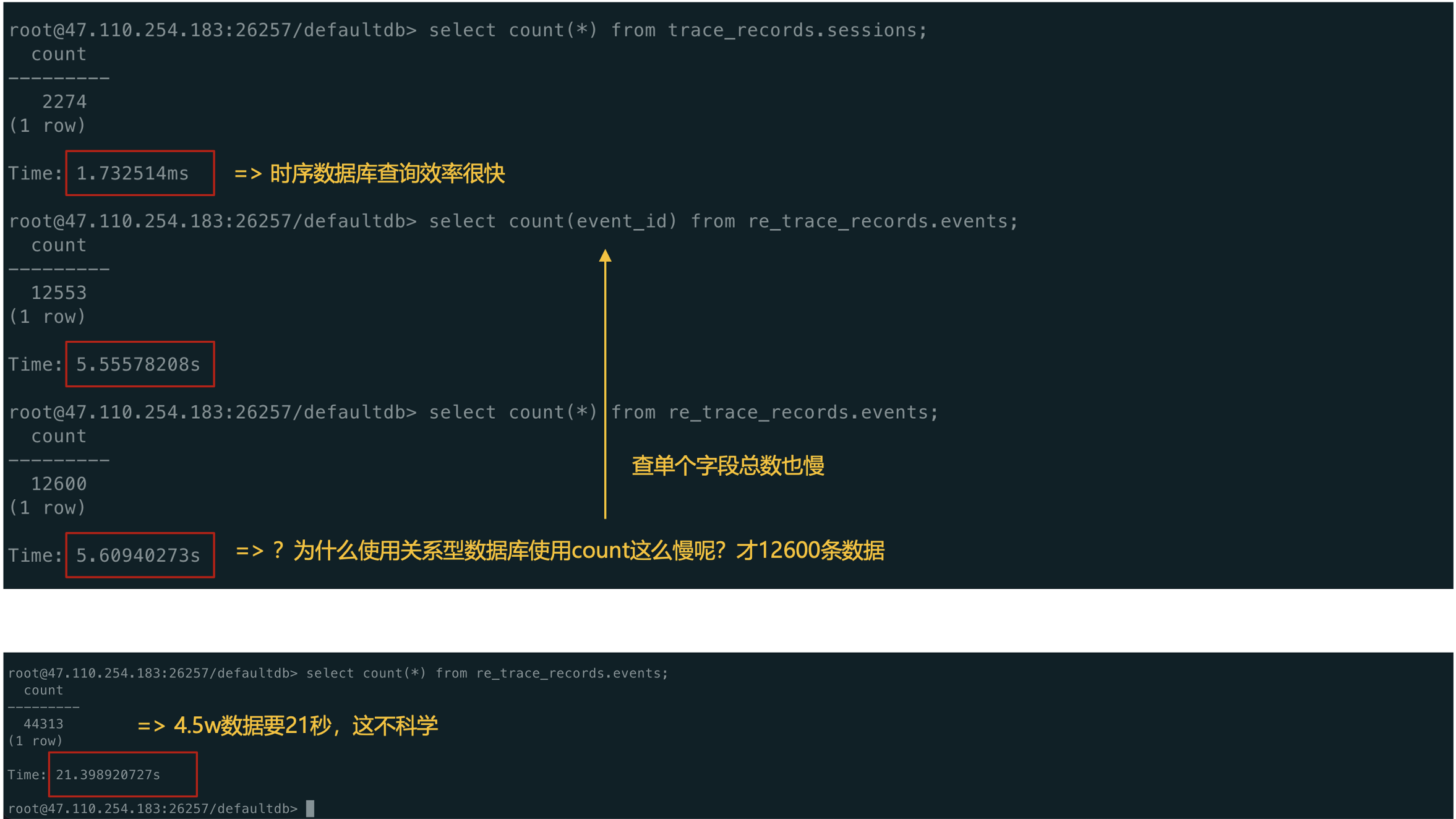
上面我们已经完成前后端的开发,以及数据结构的对接后,在开发完成后,我们来尝试跑一下脚本来试一下数据插入,我们在数据插入之后,接下来我们来分析一波数据,首先来查一下总数,我们可以看到以下结果情况:
①. 时序数据表查询,可以看到查一个总数,非常的快,只需要1.73ms。
②. 关系型数据表查询,可以看到查一个总数,在1.3w左右的数据量,表现的非常不理想,可以看到在4.5w数据量的时候,需要21秒。

为了验证一下与MySQL数据库两者的对比,这里我们同样在4核8G的配置上启动一个MySQL的docker容器。


-- 创建sessions表
CREATE
TABLE
IF
NOT
EXISTS
sessions (
session_id
VARCHAR(
50)
PRIMARY
KEY,
project_id
VARCHAR(
50)
NOT
NULL,
user_id
VARCHAR(
50),
start_time
TIMESTAMP
NULL,
end_time
TIMESTAMP
NULL,
page_url
VARCHAR(
255),
device_info
TEXT,
checkpoints
TEXT,
dom_snapshot
LONGTEXT,
policy_no
VARCHAR(
50),
compliance_flag
BOOLEAN,
risk_markers
TEXT,
storage_path
VARCHAR(
255),
data_size
INT,
compression_type
VARCHAR(
20),
created_at
TIMESTAMP
DEFAULT
CURRENT_TIMESTAMP
)
ENGINE=
InnoDB
DEFAULT
CHARSET=utf8mb4;
-- 创建events表
CREATE
TABLE
IF
NOT
EXISTS
events (
event_id
BIGINT
AUTO_INCREMENT
PRIMARY
KEY,
session_id
VARCHAR(
50)
NOT
NULL,
timestamp
TIMESTAMP
NOT
NULL,
event_type
VARCHAR(
50)
NOT
NULL,
event_data
TEXT
NOT
NULL,
target_element
VARCHAR(
255),
x_coord
INT,
y_coord
INT,
input_value
TEXT,
page_url
VARCHAR(
255),
created_at
TIMESTAMP
DEFAULT
CURRENT_TIMESTAMP
)
ENGINE=
InnoDB
DEFAULT
CHARSET=utf8mb4;
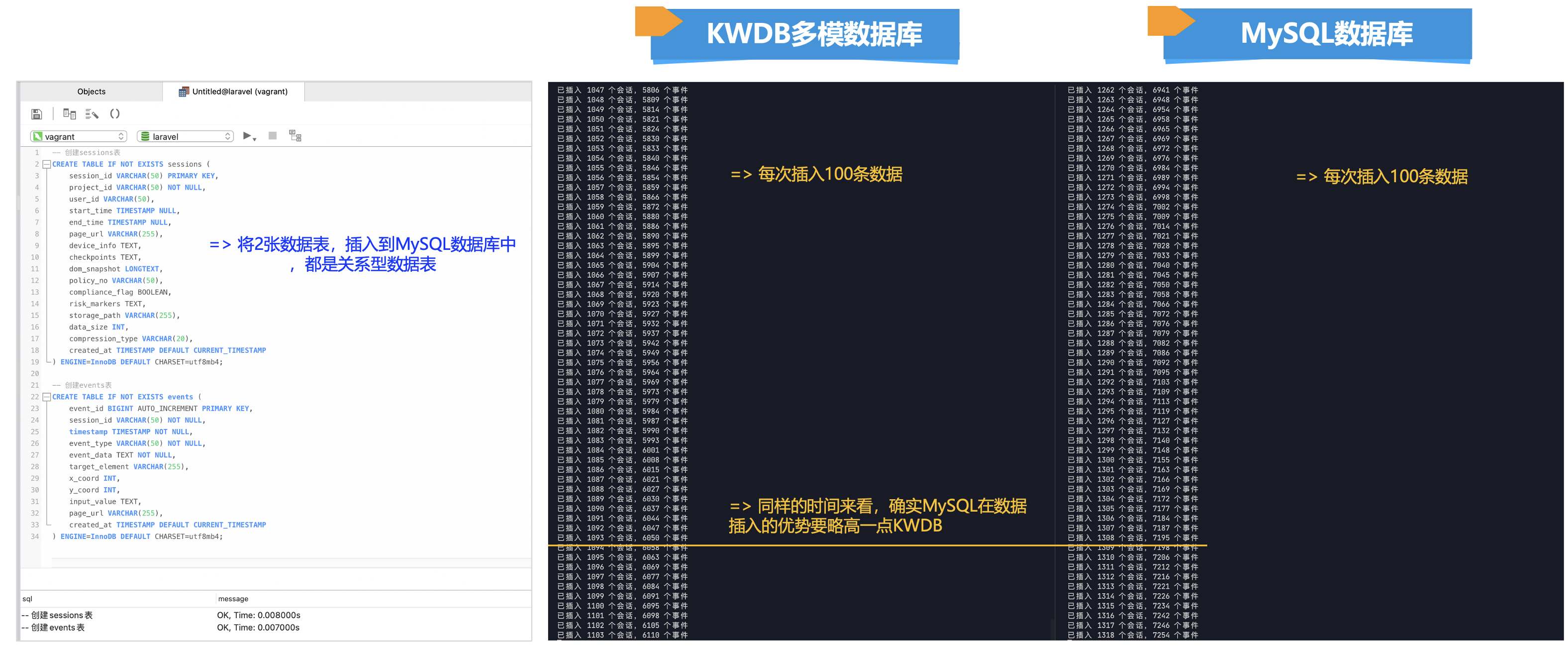
同样,写一个MySQL相关的数据库测试脚本,可以开两个终端,这样就可以一起开着来测试一下写入数据的对比的情况,可以看到以下的结果:
①. 在KWDB多模数据库,可以看到每次插入100条数据,在同样的时间来看,确实MySQL在数据插入文本的场景优势要略高一点KWDB。
②. 这样,同样说明了KWDB多模数据库在处理大文本类型时,可能会存在比MySQL这种关系型数据库要弱势一点。

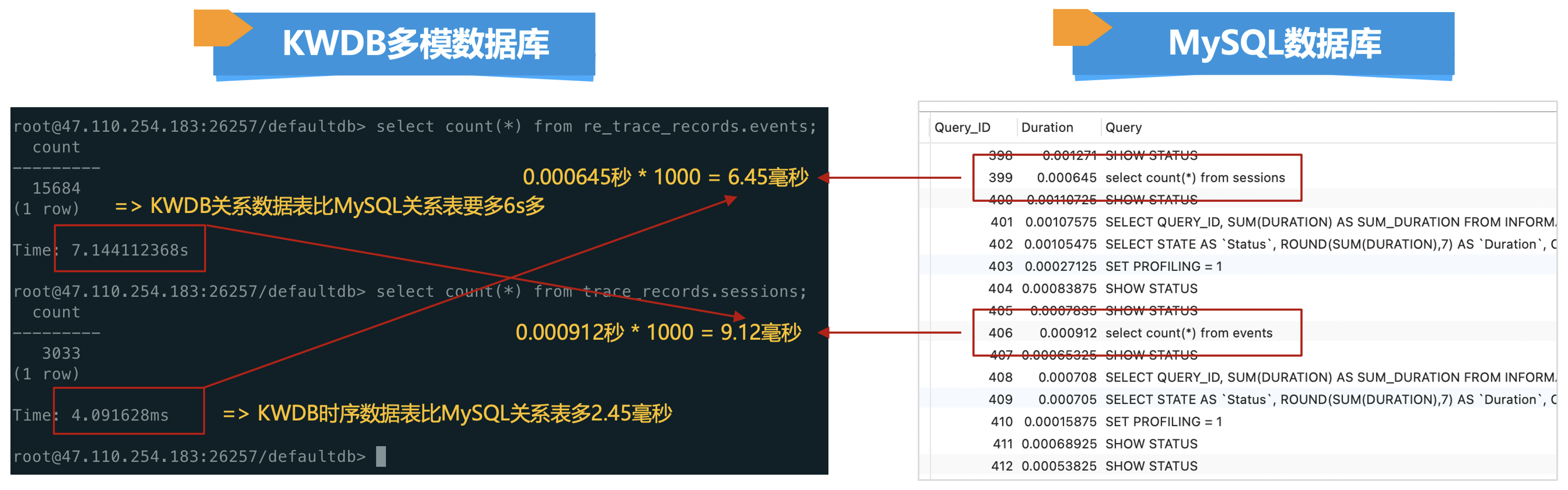
①. KWDB多模数据库以时序数据表对比MySQL关系数据表查询的时间要快一点,差不多的数据量查询count总数要快2.15毫秒。
②. 同样都是关系型数据库来看的话,KWDB在文本上查询总数确实要比较拉垮。
如果想要知道MySQL的执行语句的时间,可以使用show profiles;命令来进行查看。

那么,我们换个思路,目前不考虑大段文体longText类型的数据类型,目前来看看对比一下时序数据库的测试过程,那我们将event_data的数据改为一个字符串“test data”,我们再来跑一下脚本进行测试一下。


①. KWDB多模数据库以时序数据表对比MySQL关系数据表插入的时间要快一点,差不多的数据量要快23%左右。
②. 另外,计算公式来看的话,差值 = 7072 - 5748 = 1324,增长百分比 = (1324 / 5748) * 100% ≈ 23.04%,这个数据非常的可观。


以下是相关视屏记录操作,可以进行比对一下:
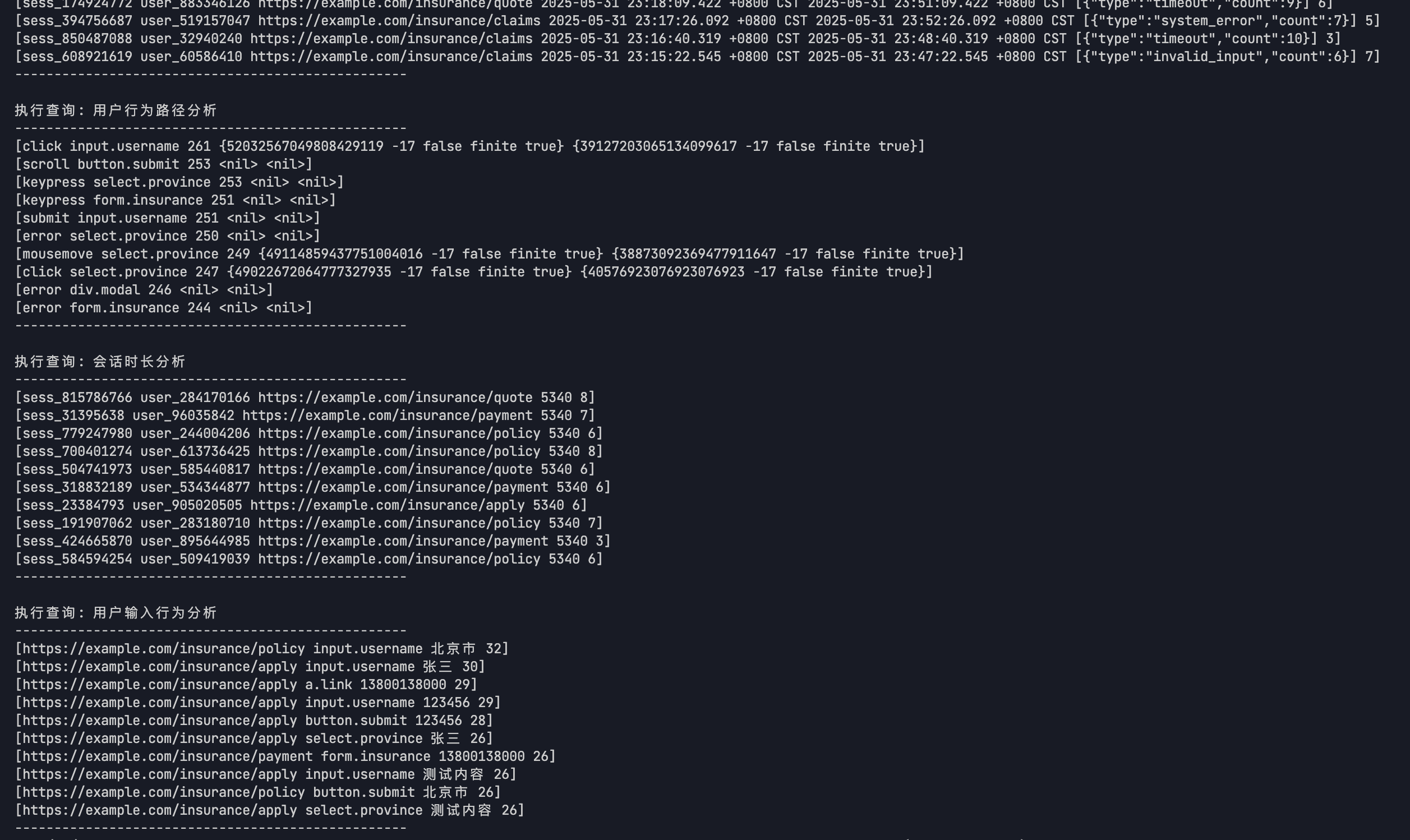
五、时序数据表与关系型数据表多模查询:
下面可以通过时序数据表与关系型数据表多模查询,这里我们可以尝试查询5个SQL语句。
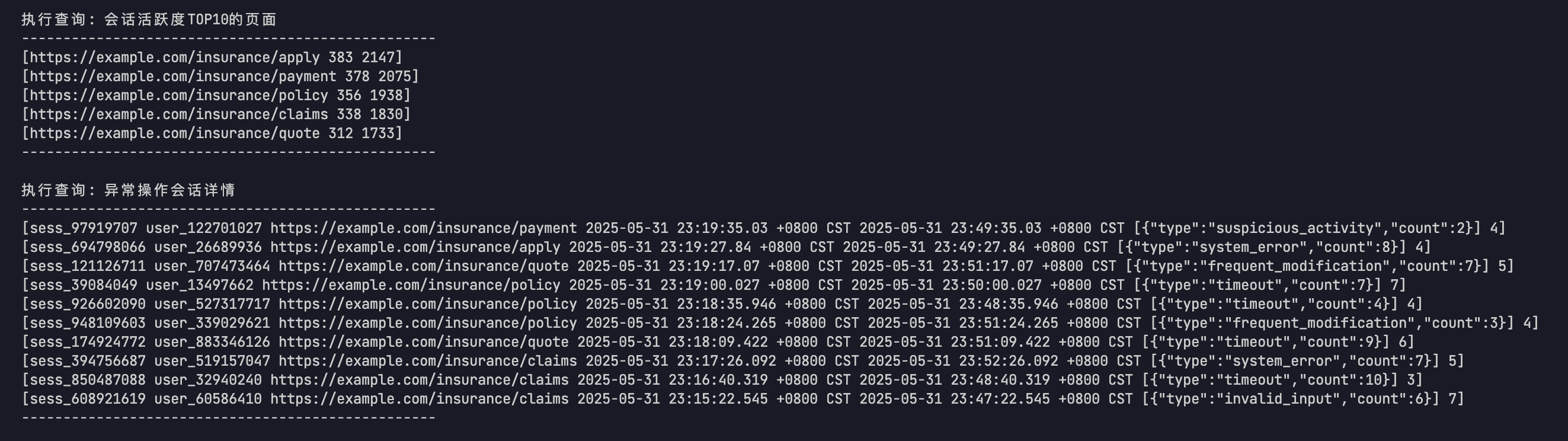
会话活跃度前十的页面
1.统计每个页面的会话数和事件数
- • 通过 sessions 和 events 表关联查询
- • 按会话数降序排列,显示前10个最活跃的页面
- • 查询条件限制在最近24小时内的数据
- • 异常操作会话详情
2.查询可能存在风险的会话信息
- • 包含会话ID、用户ID、页面URL、开始时间、结束时间、风险标记等信息
- • 统计每个会话的事件数量
- • 通过关联 sessions 和 events 表获取完整信息
3.这些查询主要用于:
- • 监控和分析用户行为
- • 识别异常操作
- • 统计页面访问情况
- • 追踪用户交互事件
查询结果会以表格形式展示,包含分隔线,方便查看数据。这些分析数据对于系统监控、安全审计和用户体验优化都很有帮助。
package main
import (
"context"
"fmt"
"log"
"math/rand"
"os"
"strings"
"time"
"github.com/jackc/pgx/v5"
)
// Event 表示一个用户操作事件
type
Event struct {
EventID int64
SessionID string
Timestamp time.
Time
EventType string
EventData string
TargetElement string
XCoord *int
YCoord *int
InputValue *string
}
// GetSessionEvents 获取指定会话的所有事件
func
GetSessionEvents(db *pgx.
Conn, sessionID string) ([]
Event, error) {
rows, err := db.
Query(context.
Background(),
`SELECT event_id, session_id, timestamp, event_type, event_data,
target_element, x_coord, y_coord, input_value
FROM events
WHERE session_id = $1
ORDER BY timestamp`,
sessionID,
)
if err != nil {
return nil, fmt.
Errorf(
"error querying events: %v", err)
}
defer rows.
Close()
var events []
Event
for rows.
Next() {
var event
Event
err := rows.
Scan(
&event.
EventID,
&event.
SessionID,
&event.
Timestamp,
&event.
EventType,
&event.
EventData,
&event.
TargetElement,
&event.
XCoord,
&event.
YCoord,
&event.
InputValue,
)
if err != nil {
return nil, fmt.
Errorf(
"error scanning event: %v", err)
}
events =
append(events, event)
}
return events, nil
}
type
QueryExample struct {
Name string
SQL string
}
// GetTraceQueries 返回所有示例查询
func
GetTraceQueries() []
QueryExample {
return []
QueryExample{
{
Name:
"会话活跃度前十的页面",
SQL:
`
SELECT
s.page_url,
COUNT(DISTINCT s.session_id) as session_count,
COUNT(e.event_id) as event_count
FROM trace_records.sessions s
LEFT JOIN re_trace_records.events e ON s.session_id = e.session_id
WHERE s.start_time >= $1
GROUP BY s.page_url
ORDER BY session_count DESC
LIMIT 10
`,
},
{
Name:
"异常操作会话详情",
SQL:
`
SELECT
s.session_id,
s.user_id,
s.page_url,
s.start_time,
s.end_time,
s.risk_markers,
COUNT(e.event_id) as event_count
FROM trace_records.sessions s
LEFT JOIN re_trace_records.events e ON s.session_id = e.session_id
WHERE s.compliance_flag = false
AND s.start_time >= $1
GROUP BY s.session_id, s.user_id, s.page_url, s.start_time, s.end_time, s.risk_markers
ORDER BY s.start_time DESC
`,
},
{
Name:
"用户行为路径分析",
SQL:
`
SELECT
e.event_type,
e.target_element,
COUNT(*) as action_count,
AVG(CASE WHEN e.x_coord IS NOT NULL THEN e.x_coord END) as avg_x,
AVG(CASE WHEN e.y_coord IS NOT NULL THEN e.y_coord END) as avg_y
FROM re_trace_records.events e
JOIN trace_records.sessions s ON e.session_id = s.session_id
WHERE s.start_time >= $1
GROUP BY e.event_type, e.target_element
ORDER BY action_count DESC
`,
},
{
Name:
"会话时长分析",
SQL:
`
SELECT
s.session_id,
s.user_id,
s.page_url,
EXTRACT(EPOCH FROM (s.end_time - s.start_time)) as duration_seconds,
COUNT(e.event_id) as event_count
FROM trace_records.sessions s
LEFT JOIN re_trace_records.events e ON s.session_id = e.session_id
WHERE s.start_time >= $1
GROUP BY s.session_id, s.user_id, s.page_url, s.start_time, s.end_time
HAVING COUNT(e.event_id) > 0
ORDER BY duration_seconds DESC
`,
},
{
Name:
"用户输入行为分析",
SQL:
`
SELECT
s.page_url,
e.target_element,
e.input_value,
COUNT(*) as input_count
FROM re_trace_records.events e
JOIN trace_records.sessions s ON e.session_id = s.session_id
WHERE e.event_type IN ('input', 'submit')
AND e.input_value IS NOT NULL
AND s.start_time >= $1
GROUP BY s.page_url, e.target_element, e.input_value
ORDER BY input_count DESC
`,
},
}
}
// 辅助函数:创建整数指针
func
intPtr(i int) *int {
return &i
}
// 辅助函数:创建字符串指针
func
strPtr(s string) *string {
return &s
}
func
main(
) {
// 初始化随机数种子
rand.
Seed(time.
Now().
UnixNano())
// 连接到数据库
config, err := pgx.
ParseConfig(
"postgresql://root@47.110.144.145:26257/defaultdb?sslmode=verify-full&sslrootcert=./certs/ca.crt&sslcert=./certs/client.root.crt&sslkey=./certs/client.root.key")
if err != nil {
log.
Fatal(
"Unable to parse database config:", err)
}
// 插入示例数据
// for {
numEvents, err :=
InsertSampleData(conn)
if err != nil {
log.
Fatal(
"Error inserting sample data:", err)
}
sessionCount++
eventCount += numEvents
fmt.
Printf(
"已插入 %d 个会话,%d 个事件\n", sessionCount, eventCount)
// }
// 执行示例查询
queries :=
GetTraceQueries()
for _, query := range queries {
fmt.
Printf(
"\n执行查询: %s\n", query.
Name)
rows, err := conn.
Query(context.
Background(), query.
SQL, time.
Now().
Add(-
24*time.
Hour))
if err != nil {
log.
Printf(
"Error executing query '%s': %v\n", query.
Name, err)
continue
}
defer rows.
Close()
// 打印查询结果
fmt.
Println(strings.
Repeat(
"-",
50))
for rows.
Next() {
values, err := rows.
Values()
if err != nil {
log.
Printf(
"Error reading row values: %v\n", err)
continue
}
fmt.
Println(values)
}
fmt.
Println(strings.
Repeat(
"-",
50))
}
// 查询并展示特定会话的事件
sessionID :=
"sess_123456789"
events, err :=
GetSessionEvents(conn, sessionID)
if err != nil {
log.
Fatal(
"Error querying session events:", err)
}
fmt.
Printf(
"\n会话 %s 的事件记录:\n", sessionID)
fmt.
Println(strings.
Repeat(
"-",
80))
for _, event := range events {
fmt.
Printf(
"时间: %v\n类型: %s\n目标元素: %s\n",
event.
Timestamp.
Format(
"2006-01-02 15:04:05"),
event.
EventType,
event.
TargetElement)
if event.
XCoord != nil && event.
YCoord != nil {
fmt.
Printf(
"坐标: (%d, %d)\n", *event.
XCoord, *event.
YCoord)
}
if event.
InputValue != nil {
fmt.
Printf(
"输入值: %s\n", *event.
InputValue)
}
fmt.
Printf(
"事件数据: %v\n", event.
EventData)
fmt.
Println(strings.
Repeat(
"-",
40))
}
}


六、总结 :
“KWDB创作者计划产品测评活动”由KWDB联合CSDN推出,面向开源版本2.2.0,支持用户从分布式架构、多模融合、安全性、并发性能等多维度测评时序数据库。参与者可积累实战经验并拓展技术栈。KWDB核心优势
作为面向AIoT场景的分布式多模数据库,KWDB的核心特性包括:
- • 多模融合:支持同一实例同时管理时序库与关系库,高效处理工业物联网、车联网等领域的高频数据。
- • 高性能:单节点每秒百万级写入,千万级数据毫秒级响应,通过数据压缩技术降低90%存储成本。
- • 易用性:提供裸机、容器及源码编译三种部署方式,适配云边端一体化场景。
以Ubuntu系统裸机部署单节点为例,应用案例“新零售回溯系统”,针对用户行为轨迹记录需求(如双11高频时序数据),设计思路包括需求分析:处理海量连续数据、高频写入(如DOM节点记录)。技术实现创建时序数据表,利用KWDB原生AI能力优化查询,通过分布式架构保障高并发场景可靠性。
KWDB凭借多模融合与高性能特性,有效解决IoT领域数据管理痛点,为开发者提供低成本、高可用的时序数据处理方案。