来源:安瑞哥是码农
上篇文章简单地讲了下kafka数据如何通过物化视图的方式持久化地写入到CK的本地表中。
因为我写入的这个kafka topic数据流量有近10万条每秒,所以很快这张本地表就塞入了好几亿数据量的数据,很快,同一个聚合查询,眼看随着数据量越来越大,查询效率也变得越来越慢。
最终,啊哦... 这个本地表所在的CK服务,因为OOM而被我成功搞挂了,要知道我这台服务器的配置可是128G内存呢。

既然数据量有这么大,单个表出现瓶颈的速度又太快,那这个时候,自然就想到该让我们的分片表出来亮亮相了,之前的文章只是简单说明了下分片表的玩法,那么这次,咱给他灌个10亿数据试试,看到底抗不抗造。
0. 总体思路
对于CK来说,如果不想通过额外的数据写入工具,比如spark,或者flink,再或者是其他的数据导入工具。
那么,我就可以借助CK的integration引擎,把数据直接写入到分片表中:
但因为是写分片表,所以这里面的花活要比写一张普通的本地表要繁琐一些,其总体步骤可以归纳为如下:
1. 创建CK跟kafka的联合表,也就是创建kafka引擎表,这一步就好比在CK跟kafka之间打开了一个数据连接的通道,但注意,此时kafka的数据并没有引入到CK中;
2. 配置分片表的集群,用来确定我们的分片表数据存储在哪些机器上,以及每个副本的分布情况。我们知道,CK的玩法跟普通的分布式数据库不一样,普通数据库创建分片表时,最多只需要指定分片数量和冗余数量(比如Elasticsearch),有些甚至啥都不用指定(比如基于HDFS的数据库);
3. 创建基于以上分片配置的分片表,确定分片表的字段,基于哪个本地表而创建,以及分片规则(数据拆分规则);
4. 创建用于存储实际分片表数据的本地表(这一步可以跟第3步位置互换),确定本地表字段,以及本地表的引擎;
5. 创建基于分片表的物化视图,将第1步创建的kafka引擎表,跟第3步创建的分片表,建立起数据流通的管道,这样,就把kafka的数据给源源不断给接入到分片表中了。
1. 创建kafka引擎表
根据以上的整体思路,第一步我们要创建的kafka引擎表,根据官网的示例,我们需要确定数据源的字段,连接信息,以及数据的分隔符,因为我的topic中,数据是普通文本,且字段以“|”作为分隔符。
其对应的建表语句如下:

注意其中框出来部分的配置,而这个建表语句的执行,在任意一个CK客户端上就可以。
这样,将kafka的数据引入到CK的入口就准备好了。
2. 分片表的集群配置
在建分片表之前,必须要确定你要建的分片表是基于哪个集群配置上的,也就是你要把要建的这张表数据,给拆分放到哪几台机器上,以及各个副本的存放位置如何。
之前的文章说过,因为我搭建的集群只有3个节点,而且CK规定,每个节点只能存放一张分片表的一个副本,于是我的配置如下:
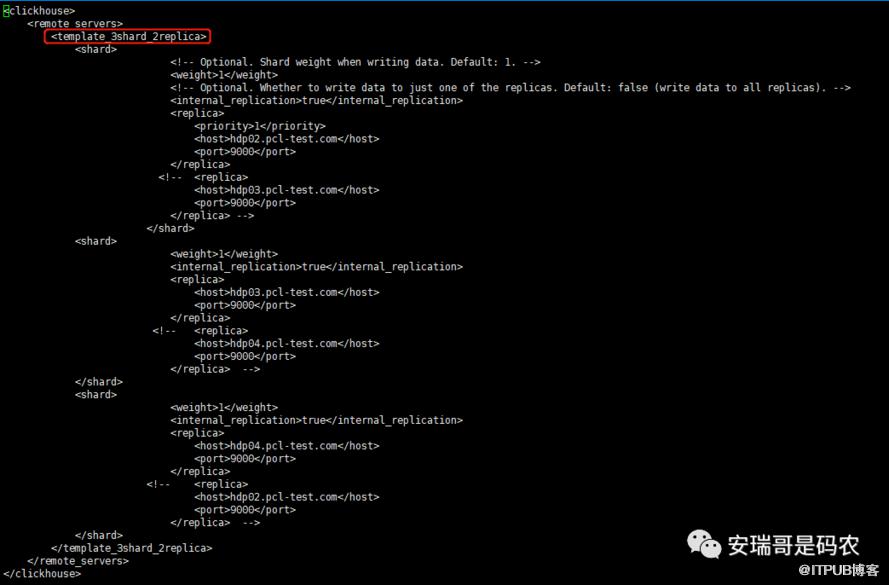
注意,这个配置需要同步到所有CK实例的机器中,详见之前的文章说明。
这个配置就确定了我们要建的分片表,要分成几个分片,每个分片存储在哪台机器上。
3. 创建分片表
接下来,就用分片表引擎,利用上面的分片集群配置,创建出我们的分片表,其建表语句如下:
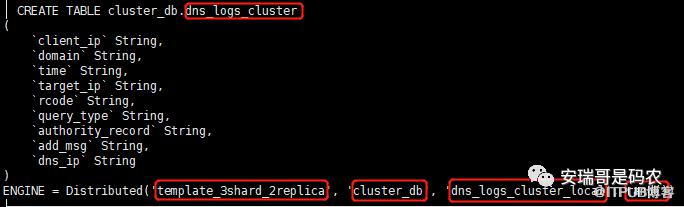
在建表语句下方设置中,分别确定分片表配置、数据库名、依赖的本地表名、分片规则。
这样,就在所有机器上创建出了这张虚拟表(不存任何数据)。
可以看到,我专门为这张分片表建了个cluster_db库,但是这里有个需要注意的问题,那就是需要在每台机器上都要创建这个db,为了这个创建db的语句只执行一次,可以用这种方式:

这样一来,这个cluster_db的创建,都只需要在一个客户端上执行一次就能完成所有机器的db创建。
4. 创建基于分片表的本地表
在上面创建分片表的建表语句中,指定了分片表需要依赖本地表dns_logs_cluster_local,那么就需要在每台机器上都创建这张本地表。
同样,为了只执行一次建表语句,就能同时创建好所有机器的本地表,可以这么来做:
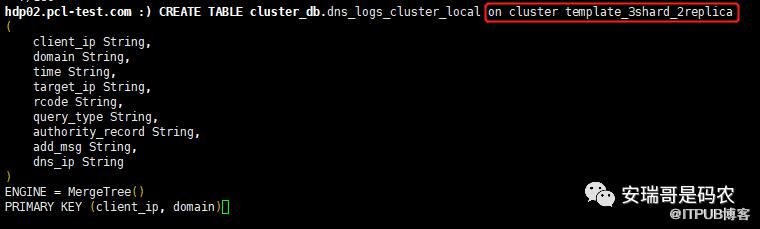
这样就在3台机器上同时创建好了3张一模一样的本地表。
而这3张本地表,才是真正存储分片表数据的地方。
5. 创建基于分片表的物化视图
这一步的目的,就是将kafka的数据给真正引入到刚刚创建的分片表中,并在CK中持久化。
具体的创建语句如下:
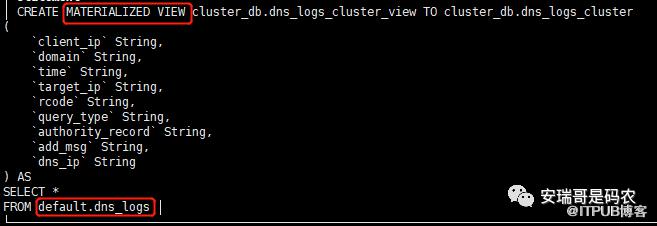
这样一来,就把kafka引擎表default.dns_logs中的数据,给源源不断灌给了分片表cluster_db.dns_logs_cluster中。
而这个物化视图cluster_db.dns_logs_cluster_view,就充当起了这两张表之间的管道作用。
以上,就完成了kafka数据接入到CK分片表的所有步骤。
6. 物化视图的数据管理
引入到CK中的数据,既可以从物化视图上进行查看,也可以通过分片表来进行查看,结果都一样的,因为物化视图指向的其实就是分片表。
来看一下查询效果:
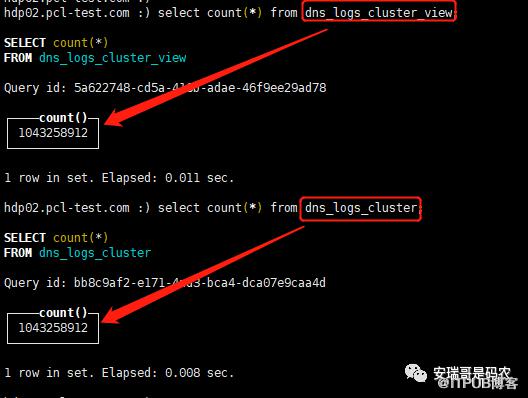
而且,因为物化视图是在其中一台机器上创建的,那么这个视图的名字也就只能对一台机器可见。
所以,想在所有机器的客户端上都用相同的查询语句,还是建议用分片表的表名。
另外,还有一个值得注意的是,现在不是将kafka的数据源源不断灌到CK的分片表了嘛,那如果我不想灌了,想停掉怎么办呢?
最粗鲁的办法就是把刚才创建的物化视图给直接删掉,但是如果你想再次把数据给接上,就只能重建这个视图了,很麻烦。
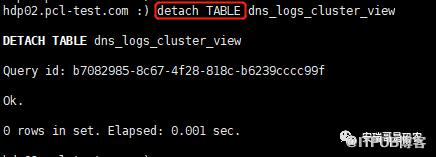
一个更优雅的办法就是,用detach命令,让这个数据管道断开:
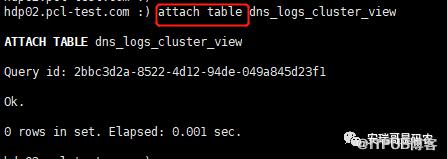
而如果我想再次恢复数据,则可以用attach命令给续上:
7.
从目前用这种方式灌的10亿条数据来看,过程没有出现任何异常,一般的查询也能hold住,而且,分片表因为把数据打散了,因此对于相同数据量的聚合统计来看,比单个的本地表要快很多。
但是,因为数据写入的过程并不透明,是否有脏数据,写入过程是否有异常,数据如果有丢失,该如何记录等等,这些我们需要关心的问题,暂时还无法解决。
也许这,就是这个方式存在的缺陷吧,期待我的下一次探索...