本文内容来自 YashanDB 官网,原文内容请见 https://yashandb.com/newsinfo/7849028.html?templateId=1718516
问题现象
测试中使用自增序列做索引, 在插入数据的过程速度比较慢, 核查关键等待事件是 index block split,time_waited 耗时比其他事件高一个量级

问题的风险及影响
影响业务性能
问题影响的版本
YashanDB 版本:23.2.9.100
问题发生原因
1、索引结构
数据库领域索引的数据结构从简单的二叉树演变为更复杂的 B + 树,已解决数据不均匀、大量增加删除导致数据倾斜,查询性能下降等问题。
相关概念可参考 Binary Search Tree Visualization (usfca.edu
也可参考 YashanDB 官网说明: 索引 | YashanDB Doc

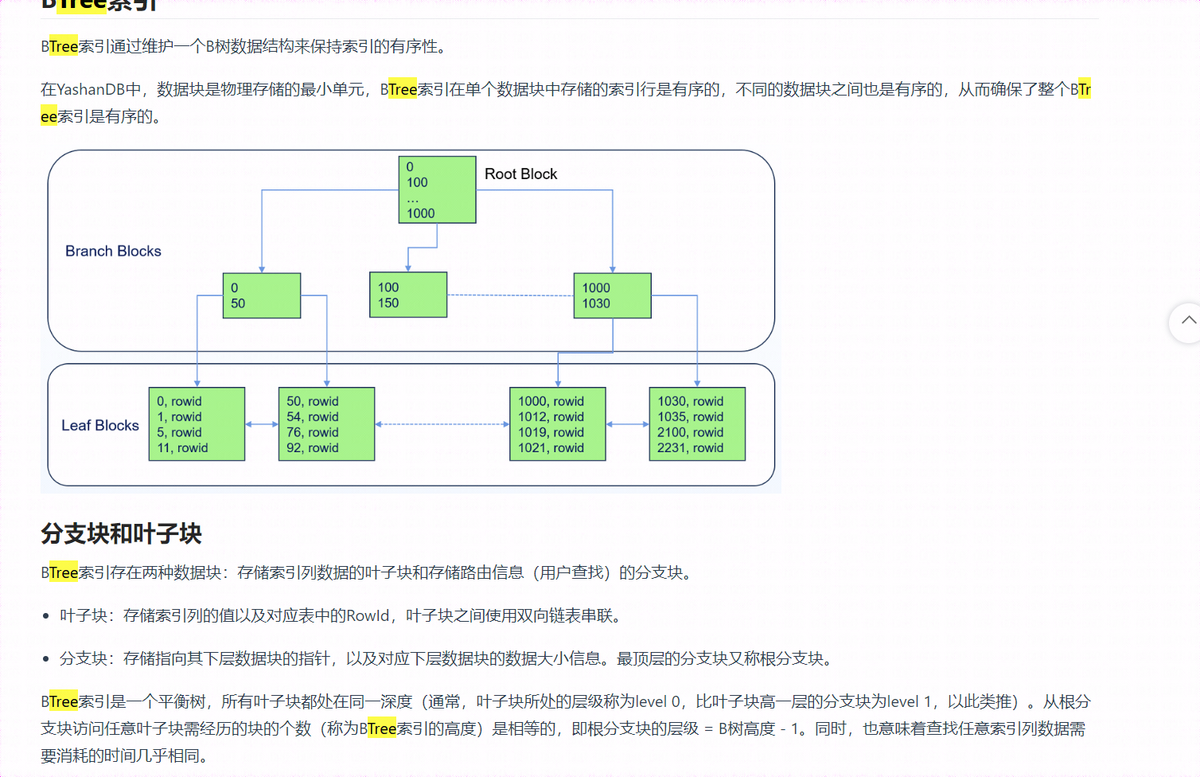
2、自增序列做索引存在的问题
B + 树在索引数据块慢的情况下,需要分裂成 2 个块,分裂的过程,写入请求需要等待。那么如果是插入的数据使用自增序列做索引,写入的数据按顺序,都在同个索引数据块上,所有请求都需要一起等待 block 拆分完成。而如果数据是分散的,那么所有的 block 可能同时都会有数据写入。一个 block 的拆分阻塞的请求就不会是全部,而是极小一部分。
自增序列插入的过程,图形化展示可以在这里体验: B+ Tree Visualization (usfca.edu)
3、解决办法及验证
业界 **:**
针对该问题,业界通用的做法是将自增序列打散,oracle 使用 Reverse 关键字,IBM 使用 Radmon 关键字( www.ibm.com )
崖山和 Oracle 保持一致,使用 reverse 关键字:
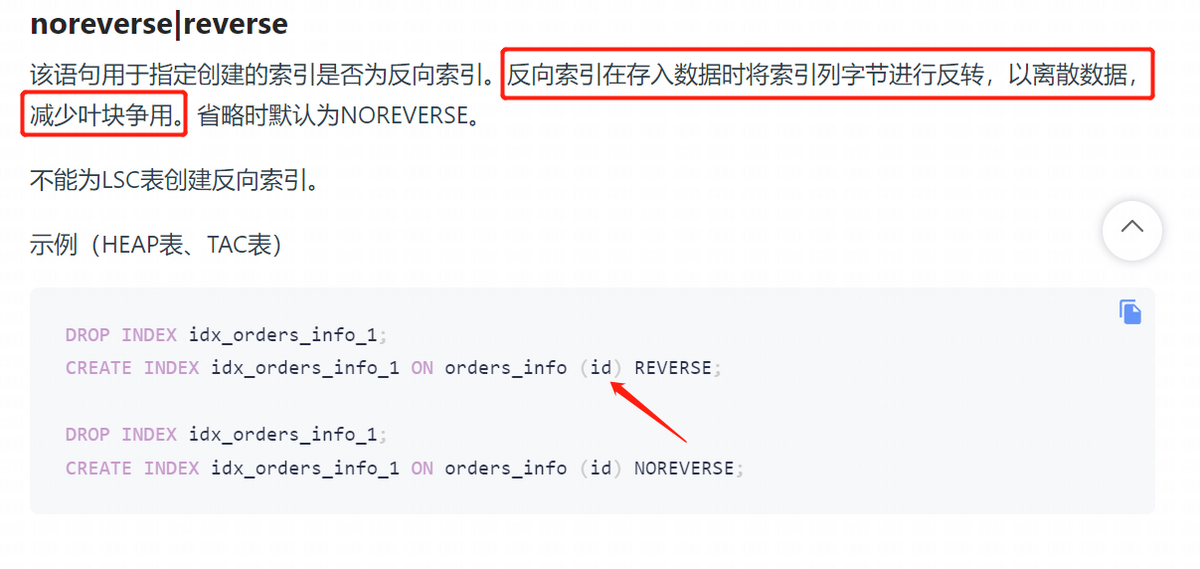
原理:
数字 Reverse 之后,如 1234 变成 4321,1235 变成 5321,1241 则变成 1421,数字分散了。M 区块满了之后,分裂出 N 块,同时 M 还会分裂出 L 块,一直重复下去,由于数组分散,所有块都有可能插入数据,并发做分裂之后插入,等待事件数量减少,性能因此提高。
实际验证结果:
不使用 reverse 索引:

使用 reverse 索引:

结论:
可以看出使用 reverse 索引,性能提升约 6 倍,非常明显。在使用自增 number、int 等做索引,或其他 char/varchar 等存在单调递增的数值列做索引,均可以使用 reverse 做优化提升写入性能。