0.
上篇文章说了Clickhouse(下文统称CK)的副本集群玩法,那么这篇咱再来说说CK的分片集群玩法。
我们知道,副本集群的目的是为了提高存储在CK中数据的高可用而设计,而分片集群的目的,则是为了缓解单台服务器的存储和表引擎压力而设计。
通常我们的分布式数据库,比如基于Hadoop生态的数据库、Elasticsearch等这些天然就支持数据的副本和分片策略,只不过这两点落到CK身上,需要额外的配置和比较复杂的操作才能办到,而且这个分布式是以表为粒度展开的。
1.
在说CK的分片集群之前呢,咱们必须要确保一件事情,那就是必须要让多台CK实例之间接受相互通信,因为默认情况下,它们彼此之间可是不能进行通信的哦,昨天我在配置副本集群时就遇到过这个坑,但昨天文章忘说了。
当时我的机器有02,和03两台,其中分别在两台机器创建副本表之后发现,只有我在03这台机器上写数据时,02才能同步到,但是如果我的数据是从02写的话,那么03则同步不了。
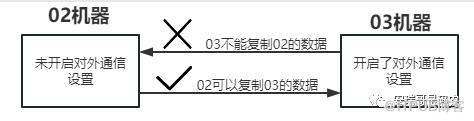
原因在于,我只在03这台机器的配置文件上打开了外部通信配置,而02这台机器没有,因此就导致数据只能往一边同步,这个配置在这里:
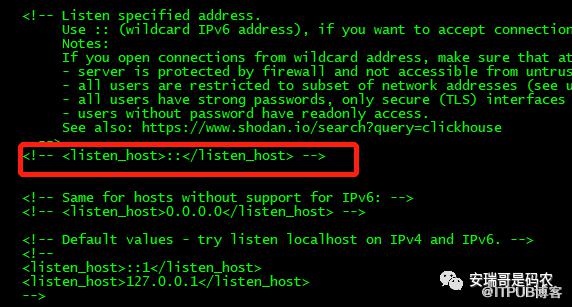
默认是注释掉的,代表除本机之外其他机器无法访问,需要把这注释打开,则表示没有限制,当然也可以将允许连接的机器列表配置在这里。
有些同学在部署集群的时候,如果发现机器之间的数据无法同步,很有可能就是这个原因导致的。
2.
既然要做分片集群,两台机器就显得有点寒碜,咱用3台来做测试,于是我又部署了一台CK实例,于是现在可用的CK实例就有02、03、04三台。
老规矩,咱先来看下对应的官方文档,分片的表引擎说明在文档的这个地方:
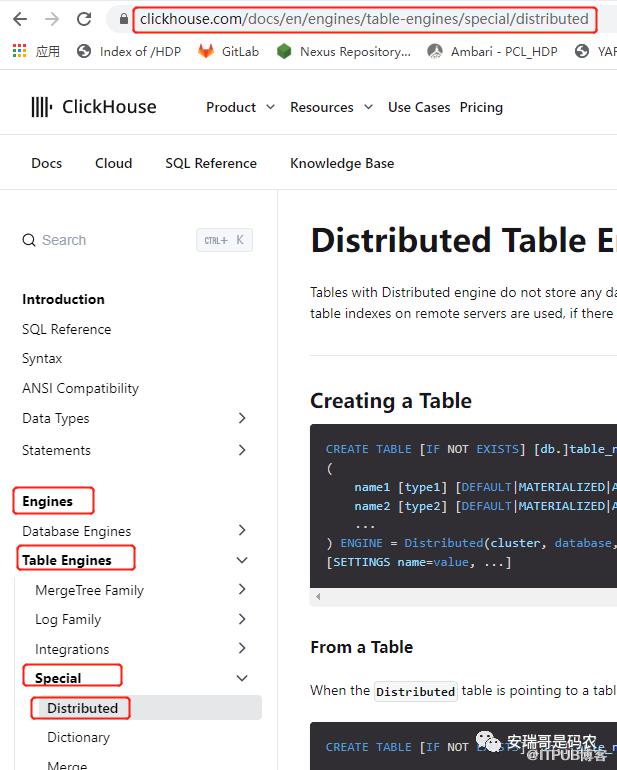
可以看到,它隶属于表引擎这个主题下的Special子主题中。
从官方文档中可以看出来,分片集群的玩法跟副本集群还不太一样,上篇文章写到,副本集群只需要在配置文件中指定zookeeper,然后在建表时的建表语句中指定副本引擎以及副本的一些相关参数就可以了。
但是对于分片集群而言,还需要额外的配置,这里面需要你首先指定一个remote servers,这个配置呢,会显示指定一张表的数据要被切成多少份,也就是多少个shard,然后每个shard又给指定多少个副本(如果不想要冗余,可以只要1个),以及各个副本分布在哪些机器上,可以看到默认的配置中,已经给了很多示例:
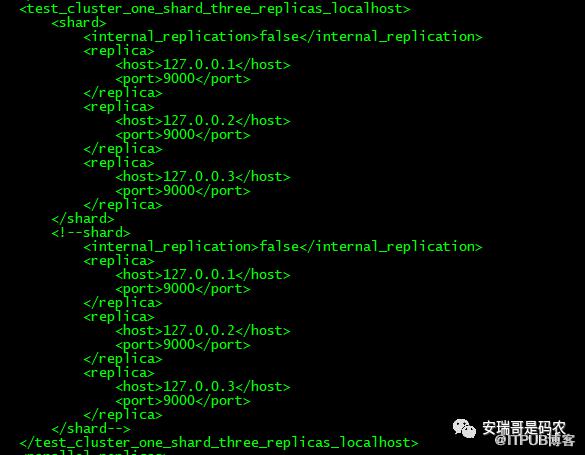
这个就很有意思,也就是说,你想把一张表的数据怎么切(可以指定切片策略),给切到哪些机器上,以及每个切片需要几个副本,完全是自己来决定,CK框架本身不管,跟普通的分布式存储系统很不一样,对不对。
而且这种个性化的设置方式,完全可以以表为单位进行,因为对于一个大规模集群来说,不同业务数据的表,你能够存储的数据量一定是不一样的,比如一张不是很大的表,用3个分片可能就够了,但是如果是一张很大的表,可能需要几十甚至上百个分片,才能将存储压力和引擎的计算压力给分摊开来。
那既然可能不同的表有不同的cluster配置方式,那就说明在一个集群中,需要有多个这种根据不同场景而需要的配置,所以这块的配置,就最好能够独立开来。
虽然我们可以把这些满足不同场景建分片表的配置,给全部写到主配置文件中,也就是/etc/clickhouse-server/config.xml,但是这样一来这个配置文件的耦合度就太高了,且对于一个文件的多次修改操作很容易因为某次操作失误,而让整个系统处于不可用的状态。
于是CK给提供了一种读取额外配置的策略,而/etc/clickhouse-server/config.d/这个目录就是提供给你干这个事情的。
3.
那接下来,咱就在这个额外目录下来配置一个3分片2副本的分片表配置:
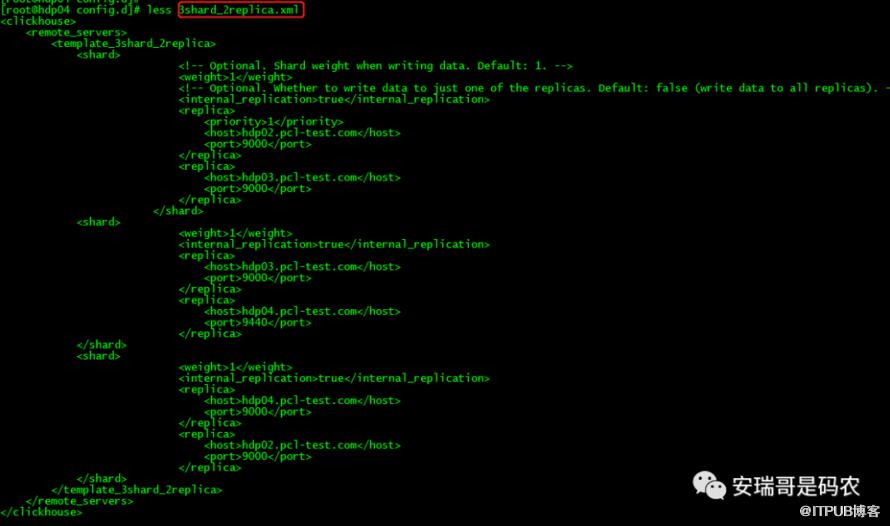
大概解释一下这个配置文件(3shard_2replica.xml):
首先要注意这个xml文件的格式和标签,新版本的跟旧版本有些不一样,其中可以根据自己修改的部分有:
template_3shard_2replica标签:这个是根据自己需要取的cluster名字,我这里取名叫:3分片2副本的模板。意思是只要满足这个要求的分片表都可以使用这个配置;
internal_replication标签:这里面的值是告诉你副本数据是否用内部同步的方式,默认为false,意思是数据每次写入分片时,必须所有副本写完之后才返回,而如果设置为true,则写完一个副本就会直接返回,剩下的CK会做后台同步;
其他的配置就是这个cluster中每个CK实例的hostname以及对应的TCP通信端口,根据你当前集群的配置来填写就可以了。
此外,还需要在主配置文件中,也就是在/etc/clickhouse-server/config.xml文件中加入识别这个额外配置的位置信息,否则CK可能无法识别你的这个额外配置信息:

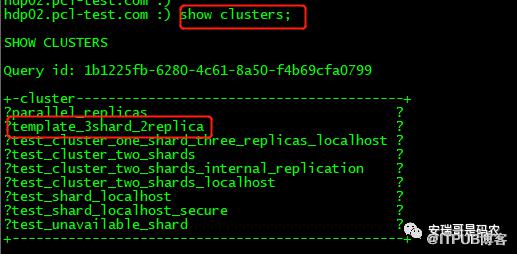
接着,把这两个改动的配置文件给同步到其他两台机器上,然后所有机器重启CK服务,重启后,连接各自的CK实例后,就能看到新添加的分片cluster信息:
既然分片集群的配置准备好了,那接下来,就是建分片表了:

给分片表取名为:cluster_table_01,这个就是一张标准的分片表建表语句,其中:
1,代表要把这张表建在哪个cluster配置上;
2,指定已经配置的cluster标签,跟1保持一样;
3,指定CK的库名;
4,远程表的名字,但是这里需要注意,不能跟create table后面的那个名字重复,否则会报如下错误:

5,分片规则,也就是数据的切分方式,我这里选的随机;
4.
感觉一切没有问题了,但执行时还是报错了:

啥意思呢?就是告诉你,原本配置的3个分片2个副本,落在3台机器上的3个CK实例上是不被允许的,所有的副本必须落在不同的CK实例上才可以,也就是说必须是6个不同的CK实例。
为啥要这么蠢的规定呢?我机器少难道就不配有冗余分片了吗?

那为了能让这个分片表能够建下去,只能老老实实根据它的要求来,把原本配置里的副本数量改为1个:
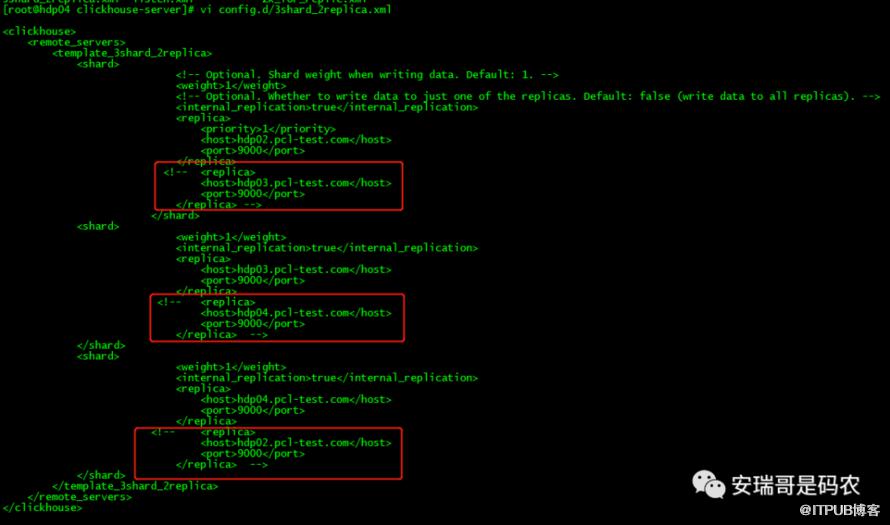
把多余的副本给注释掉,再把配置同步到其他机器,而且需要重启CK的服务。
接着在任意一个CK客户端(配置在cluster中的)执行建表语句,咦... 就可以了,从返回的提示可以看出来,在3台机器中都生效了。
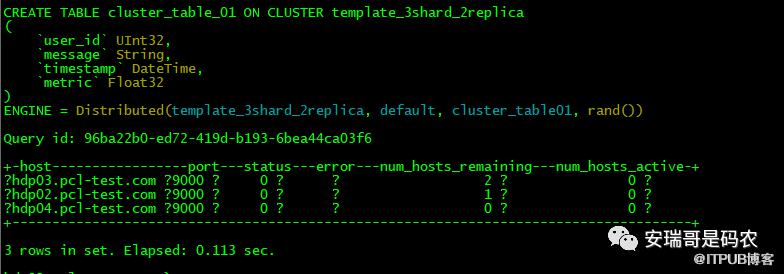
接着,再从任意一个CK客户端写入一条数据试试:

Emm... 又报错了,说红框中的表不存在(依赖的本地表),老实说,看到这里我多少是有点懵逼的,因为它有点违背常理。
然后我又不得不看回官方文档,当我看到这句话的时候,我多少有些释怀了:

意思是我这个分片表就是一个空壳,实际数据压根不在我这,它需要依赖本地表cluster_table01,而这张表我们是没有建的。
那怎么办?
继续建表喽,建什么表呢?本地表cluster_table01。
既然报错说cluster_table01这张表不存在,那我们就把这张表给建起来嘛:
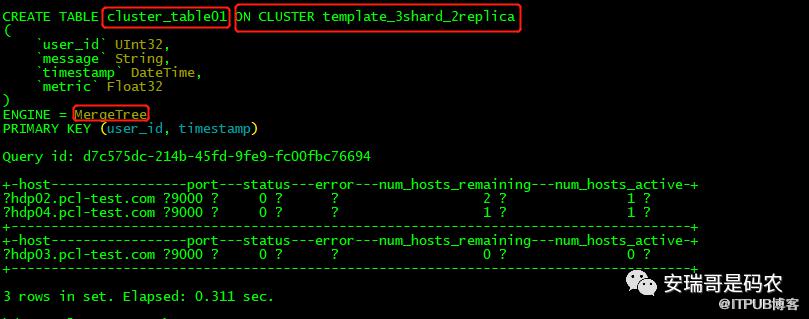
但是注意:这里需要选择你合适的表引擎,因为我这里是建普通的本地表(非副本表),所以引擎选择的是常规的MergeTree,但是需要注意的是,create table语句后面必须要接ON CLUSTER关键字,且后面的cluster名称要跟你要建的分片表cluster标签名称对应。
把本地的建表语句写好之后,在任意一个cluster的客户端执行就可以了,比如我这里的cluster组成为: 02、03、04这几台机器。
那么这个建表语句只需要在任意其中一台执行就可以,执行完,在所有客户端查看一下:
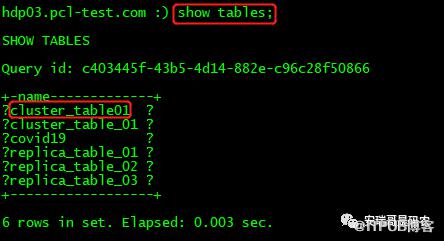
可以发现所有的客户端都能看这张(本地)表,这样一来呢,分片表cluster_table_01就跟每个机器上的本地表cluster_table01能关联上了(因为之前已经创建了分片表了嘛)。
那么接下来,就是往分片表中写数据了,咱们往任意一个客户端中写入数据:

因为这个写入语句我执行了两次,所以分片表中会有两条数据:
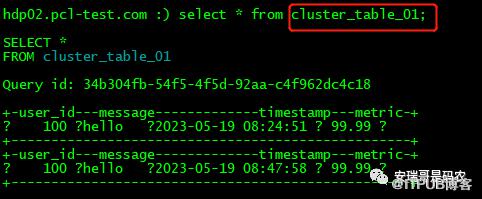
但是前面官网说了,分片表本身是不存储数据的,它只不过是多个本地表数据的一个视图而已(你从实际的存储目录也可以看出来,是空的),而这里的本地表就是cluster_table01。
要知道这个本地表cluster_table01分布在02、03、04三台机器上,而我却只写入了2条记录,那就说明,这里面至少有一台机器的本地表是没有数据的。
我们来验证一下,可以看到如下验证结果:
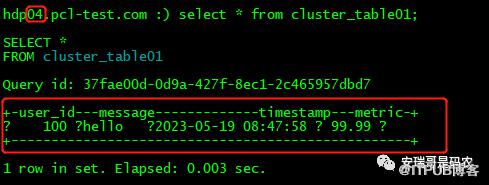
04机器有一条数据
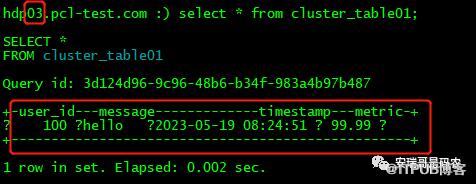
03机器有一条数据
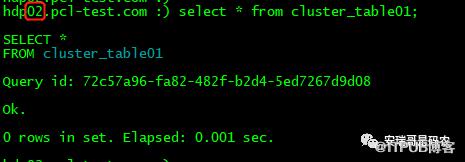
02机器有没有数据
以上,则完成了整个分片表的建设,真TM复杂,也确实把我累够呛。
5.
另外还有一个需要注意的地方,因为分片表在查询的时候,需要CK的实例之间进行通信,而这个通信他需要用到密码(部署CK实例时设置的),你要么免去这个密码,要么把这个密码在配置文件中指定,否则当你查询分片表的时候,它会有如下的报错:

最后:
从以上的操作来看,是不是还挺复杂的,难怪有球友要我重点把分片表好好讲讲的(网上的很多资料都感觉讲的不够清楚),这个执行流程确实够繁琐的,坑够多,非常考验执行者的逻辑缜密程度,稍有些不注意,就容易失败。
当然,我想着既然前期的建表过程如此复杂,那么是不是代表着后续在使用时,其发挥的功能也就异常强大,我不知道。
下一篇,咱就把它正式用起来,来看看它真正的效果怎么样。