就是之前根据 watermark 和滑动时间窗口来实时计算排名前十的上网IP(client_IP)数量,但是当时为了快速达到验证 API 的效果,就把数据源写入到 kafka 的元数据时间(process_time),给定义为watermark和windows需要的事件时间。
package com.anryg.window_and_watermark
import org.apache.flink.configuration.Configuration
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
/**
* @DESC: 用SQL API读取kafka数据,并利用watermark和window功能来对数据进行统计
* @Auther: Anryg
* @Date: 2022/8/14 19:08
*/
object FlinkSQLFromKafkaWithWatermarkAndWindow {
def main(args: Array[String]): Unit = {
val streamingSetting = EnvironmentSettings.newInstance().inStreamingMode().build()
val config = new Configuration() //设置checkpoint
config.setString("execution.checkpointing.interval","10000")
config.setString("state.backend", "filesystem")
config.setString("state.checkpoints.dir","${name_node}:8020/tmp/checkpoint/FlinkTBFromKafkaWithWatermarkAndWindow")
streamingSetting.getConfiguration.addAll(config)
val tableEnv = TableEnvironment.create(streamingSetting)
tableEnv.executeSql(
"""
|Create table kafkaTable(
|client_ip STRING,
|domain STRING,
|time STRING,
|target_ip STRING,
|rcode STRING,
|query_type STRING,
|authority_record STRING,
|add_msg STRING,
|dns_ip STRING,
|event_time AS to_timestamp(time, 'yyyyMMddHHmmss'), //设置事件时间为实际数据的产生时间
|watermark for event_time as event_time - interval '10' second //设置watermark,确定watermark字段
|)
|with(
|'connector' = 'kafka',
|'topic' = '${topic}',
|'properties.bootstrap.servers' = '${kafka_broker}:6667',
|'properties.group.id' = 'FlinkTBFromKafkaWithWatermarkAndWindow',
|'scan.startup.mode' = 'latest-offset',
|'value.format'='csv', //确定数据源为文本格式
|'value.csv.field-delimiter'='|' //确定文本数据源的分隔符
|)
""".stripMargin)
tableEnv.executeSql(
"""
|SELECT
|window_start,
|window_end,
|client_ip,
|count(client_ip) as ip_count
|FROM TABLE(
|HOP( //确定window策略
|TABLE kafkaTable,
|DESCRIPTOR(event_time),
|INTERVAL '30' SECONDS, //确定滑动周期
|INTERVAL '2' MINUTES) //确定窗口时间间隔
|)
|GROUP BY
|window_start,
|window_end,
|client_ip
|ORDER BY ip_count
|DESC
|LIMIT 10
""".stripMargin
).print()
}
}
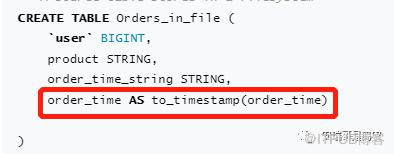
`process_time` TIMESTAMP(3) METADATA FROM 'timestamp',
event_time AS to_timestamp(time, 'yyyyMMddHHmmss'),


package com.anryg.window_and_watermark
import org.apache.flink.configuration.Configuration
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
/**
* @DESC: 用SQL API读取kafka数据,并利用watermark和window功能来对数据进行统计
* @Auther: Anryg
* @Date: 2022/8/14 19:08
*/
object FlinkSQLFromKafkaWithWatermarkAndWindow {
def main(args: Array[String]): Unit = {
val streamingSetting = EnvironmentSettings.newInstance().inStreamingMode().build()
val config = new Configuration() //设置checkpoint
config.setString("execution.checkpointing.interval","10000")
config.setString("state.backend", "filesystem")
config.setString("state.checkpoints.dir","hdfs://192.168.211.106:8020/tmp/checkpoint/FlinkSQLFromKafkaWithWatermarkAndWindow")
streamingSetting.getConfiguration.addAll(config)
val tableEnv = TableEnvironment.create(streamingSetting)
tableEnv.executeSql(
"""
|Create table kafkaTable(
|client_ip STRING,
|domain STRING,
|`time` STRING,
|target_ip STRING,
|rcode STRING,
|query_type STRING,
|authority_record STRING,
|add_msg STRING,
|dns_ip STRING,
|event_time AS to_timestamp(`time`, 'yyyyMMddHHmmss'), //设置事件时间为实际数据的产生时间,注意time这个字段必须要用``符合括起来
|watermark for event_time as event_time - interval '10' second //设置watermark,确定watermark字段
|)
|with(
|'connector' = 'kafka',
|'topic' = 'qianxin',
|'properties.bootstrap.servers' = '192.168.211.107:6667',
|'properties.group.id' = 'FlinkSQLFromKafkaWithWatermarkAndWindow',
|'scan.startup.mode' = 'latest-offset',
|'value.format'='csv', //确定数据源为文本格式
|'value.csv.field-delimiter'='|' //确定文本数据源的分隔符
|)
""".stripMargin)
tableEnv.executeSql(
"""
|SELECT
|window_start,
|window_end,
|client_ip,
|count(client_ip) as ip_count
|FROM TABLE(
|HOP( //确定window策略
|TABLE kafkaTable,
|DESCRIPTOR(event_time),
|INTERVAL '30' SECONDS, //确定滑动周期
|INTERVAL '2' MINUTES) //确定窗口时间间隔
|)
|GROUP BY
|window_start,
|window_end,
|client_ip
|ORDER BY ip_count
|DESC
|LIMIT 10
""".stripMargin
).print()
}
}
event_time AS to_timestamp(time, 'yyyyMMddHHmmss'),
event_time AS to_timestamp(`time`, 'yyyyMMddHHmmss'),
time STRING,
`time` STRING,