我们之前介绍的RAG,更多的是使用输入text来查询相关文档。在某些情况下,信息可以出现在图像或者表格中,然而,之前的RAG则无法检测到其中的内容。
针对上述情况,我们可以使用多模态大模型来解决,比如GPT-4-Vision,它有非常好的图像理解能力,可以理解图像内部发生的事情。
现在的问题与我们如何从矢量数据库中检索正确的图像。我们可以参考LangChain博客[1]中两种实现多模态RAG方法。
两种方法如下所示:
Multimodal Embedding (using Open Clip Embedding)
Multi-vector retriever with image summary
一、多模态嵌入(使用CLIP Embedding)
根据langchain博客[1],多模态嵌入方法的准确率仅为60%,而多向量检索方法的准确率约为90%。然而,多模态嵌入方法非常划算,因为只调用一次GPT-4-Vision。
对于多模态嵌入方法,我们需要使用Open CLIP Embeddings。CLIP(对比语言-图像预训练)是Open AI于2021年开发的一个嵌入模型,是一个在同一空间共享文本和图像嵌入的嵌入模型。
多模态嵌入与其他RAG系统类似,现在唯一的区别是图像也嵌入了这个矢量数据库中。但是,这个模型不足以解释图像中的信息,例如,在某些情况下,图像中存在与数字相关的信息,或者数据库中的图像类型相似,嵌入无法从数据库中检索相关图像。
完整的代码可以参考langchain cookbook[2],下图是整体架构图:
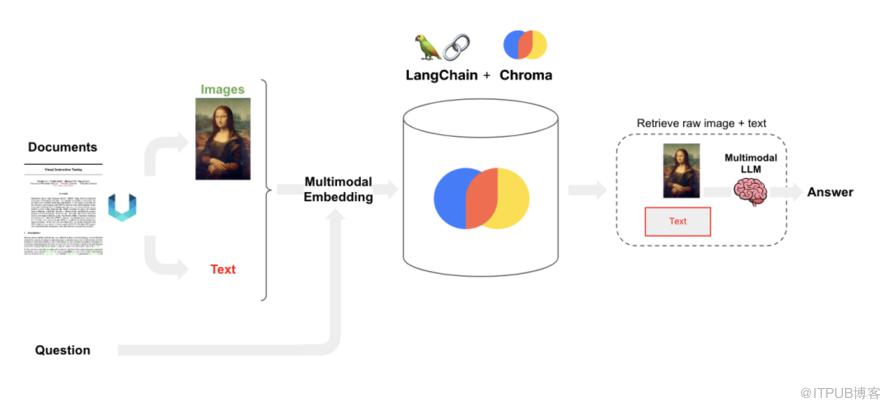
下面稍微介绍一下几个关键步骤:
步骤1:从PDF中提取图像
使用unstructured库抽取PDF信息,并创建一个文本和图像列表。提取的图像需要存储在特定的文件夹中。
# Extract images, tables, and chunk textfrom unstructured.partition.pdf import partition_pdfraw_pdf_elements = partition_pdf(filename="LCM_2020_1112.pdf",extract_images_in_pdf=True,infer_table_structure=True,chunking_strategy="by_title",max_characters=4000,new_after_n_chars=3800,combine_text_under_n_chars=2000,image_output_dir_path=path,)
步骤2:创建矢量数据库
准备矢量数据库,并将图像URI和文本添加到矢量数据库中。
# Create chromavectorstore = Chroma(collection_name="mm_rag_clip_photos", embedding_function=OpenCLIPEmbeddings())# Get image URIs with .jpg extension onlyimage_uris = sorted([os.path.join(path, image_name)for image_name in os.listdir(path)if image_name.endswith(".jpg")])print(image_uris)# Add imagesvectorstore.add_images(uris=image_uris)# Add documentsvectorstore.add_texts(texts=texts)
步骤3:QnA管道
最后一部分是Langchain QnA管道。
chain = ({"context": retriever | RunnableLambda(split_image_text_types),"question": RunnablePassthrough(),}| RunnableLambda(prompt_func)| model| StrOutputParser())
如上面的脚本所示,有两个重要的自定义函数在这个管道中发挥着重要作用,分别是:split_image_text_types和prompt_func。
对于split_image_text_types函数,使用CLIP嵌入获取相关图像后,还需要将图像转换为base64格式,因为GPT-4-Vision的输入是base64格式。
prompt_func函数是描述如何构建prompt工程。在这里,我们将“问题”和“base64图像”放在提示中。
二、带图像摘要的多向量检索器
根据langchain的观察结果,该方法比多模态嵌入方法的准确性更高,它使用GPT-4V提取摘要。
如果使用多矢量方法摘要时,需要提交文档中的所有图片进行摘要。当在矢量数据库中进行相似性搜索时,图像的摘要文本也可以提供信息。
一般来说,摘要用于查找相关图像,相关图像输入到多模态LLM以回答用户查询。这两条信息需要分开,这就是为什么我们在这种情况下使用多向量检索器[3]的原因。
优点:图像检索精度高
缺点:这种方法非常昂贵,因为GPT-4-Vision非常昂贵,尤其是如果你想总结许多图像,如果你有成本问题,可能会是一个问题。
完整的代码可以参考langchain cookbook[4],下图是整体架构图:
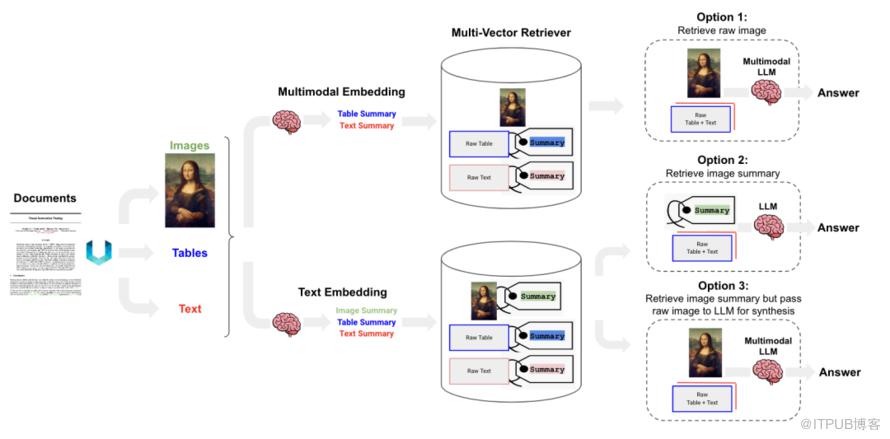
该方法也可以很好地回答图像中的问题,唯一的问题是整个过程比较缓慢,大概是因为GPT-4-Vision需要时间来处理整个事情。
下面稍微介绍一下几个关键步骤:
步骤1:提取图像
该步骤与上述多模态嵌入方法类似。
步骤2:生成文本和图像摘要
使用generate_text_summarys和generate_mg_summarys函数生成每个文本和图像的摘要。数据结构,如下所示:
{"input":text, "summary":text_summaries},{"input":table, "summary":table_summaries},{"input":image_base64, "summary":image_summaries }
此结构将添加到多矢量检索器中。
步骤3:创建多矢量检索器
使用下面的python脚本将上述数据结构添加到多向量检索器中,我们还需要指定矢量数据库。
# The vectorstore to use to index the summariesvectorstore = Chroma(collection_name="mm_rag_cj_blog", embedding_function=OpenAIEmbeddings())# Create retrieverretriever_multi_vector_img = create_multi_vector_retriever(vectorstore,text_summaries,texts,table_summaries,tables,image_summaries,img_base64_list,)
使用create_multi_vector_requirer函数初始化多向量。langchain中的MultiVectorRetriever是一个创建多向量检索器的类,在这里我们需要添加向量存储、文档存储和key_id作为输入。
该案例中,我们的文档存储设置为InMemoryStore,将不会持久化。因此需要使用另一个langchain存储类来使其持久化,可以参考[5]。
docstore很重要,它存储我们的图像和文本,而不是摘要。摘要存储在矢量存储中。
def create_multi_vector_retriever(vectorstore, text_summaries, texts, table_summaries, tables, image_summaries, images):"""Create retriever that indexes summaries, but returns raw images or texts"""# Initialize the storage layerstore = InMemoryStore()id_key = "doc_id"# Create the multi-vector retrieverretriever = MultiVectorRetriever(vectorstore=vectorstore,docstore=store,id_key=id_key,)# Helper function to add documents to the vectorstore and docstoredef add_documents(retriever, doc_summaries, doc_contents):doc_ids = [str(uuid.uuid4()) for _ in doc_contents]summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]})for i, s in enumerate(doc_summaries)]retriever.vectorstore.add_documents(summary_docs)retriever.docstore.mset(list(zip(doc_ids, doc_contents)))# Add texts, tables, and images# Check that text_summaries is not empty before addingif text_summaries:add_documents(retriever, text_summaries, texts)# Check that table_summaries is not empty before addingif table_summaries:add_documents(retriever, table_summaries, tables)# Check that image_summaries is not empty before addingif image_summaries:add_documents(retriever, image_summaries, images)return retriever
步骤4:QnA管道
最后一步与前面的方法类似。只有检索器不同,现在我们使用的是多向量检索器。
三、结论
如果使用多模态RAG,这两种方法是合适的。其实谷歌也发布了他们的多模态嵌入[6],亚马逊也有Titan多模态嵌入[7]。相信在未来,多模态嵌入将有许多选择。
参考文献:
[1] https://blog.langchain.dev/multi-modal-rag-template/
[2] https://github.com/langchain-ai/langchain/blob/master/cookbook/multi_modal_RAG_chroma.ipynb
[3] https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
[4] https://github.com/langchain-ai/langchain/blob/master/cookbook/Multi_modal_RAG.ipynb
[5] https://python.langchain.com/docs/integrations/stores/file_system
[6] https://cloud.google.com/vertex-ai/docs/generative-ai/embeddings/get-multimodal-embeddings
[7] https://docs.aws.amazon.com/bedrock/latest/userguide/titan-multiemb-models.html