想不想克隆自己的声音,输入一段文字后,用你自己的声音朗读出来,下面将手把手教大家如何用GPT-SoVITS训练自己的语音模型,克隆自己的声音,克隆后的声音相似度将会高达99%,根本分辨不出这是克隆的声音还是你本人真实的声音,还不赶紧去试试。
今天我们使用的是GPT-SoVITS,是一款开源的声音克隆和文本到语音转换工具,支持多种语言(将中文、英语、日语文本转换为克隆的声音),在Github上有30K Stars。
项目地址:
https://github.com/RVC-Boss/GPT-SoVITS/
下载并安装GPT-SoVITS
由于大家无法魔法上网和官方的安装方式比较麻烦,尤其对Mac来说,所以提前打包好了,可一键解压安装使用,非常方便,并且后续可更新到最新版本。关注公众号,回复【GPT-SoVITS】,即可获得下载地址。
Windows系统用户下载解压后,执行【go-webui.bat】即可开启Web端开始使用。
Mac用户麻烦一些,需要先安装。打开解压目录,找到【install for mac.sh】,在命令行窗口执行下面命令进行安装:
bash install for mac.sh安装成功后,双击执行update.command来拉取官方仓库更新,双击执行go-webui.command打开webUI,双击go-api.command启动API。下面是执行完开启webUI的效果。
(开启WebUI)
使用GPT-SoVITS(准备阶段)
1、准备工作
录制自己的音频(建议1分钟以上,2分钟以内即可),并转换为wav格式。转换可以选择用下面网站在线转换后下载即可:
https://www.aconvert.com/cn/audio/
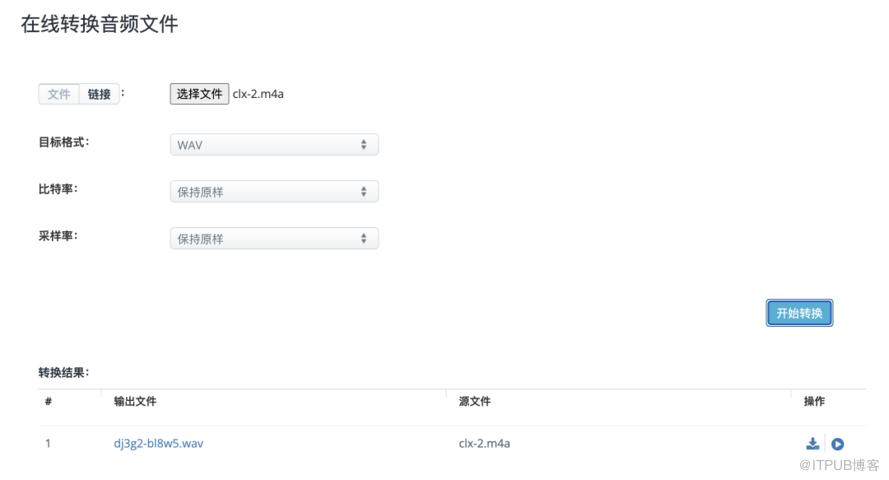
(在线转换为wav格式)
2、去除音频背景声和杂音
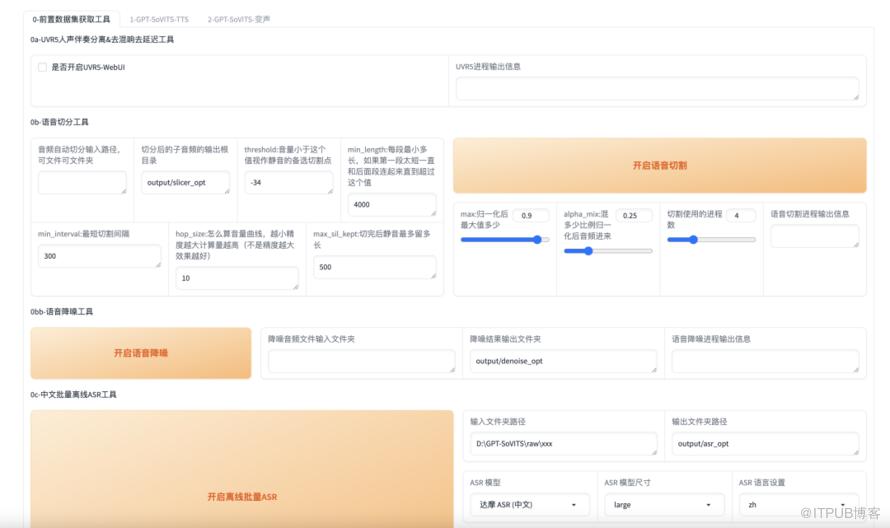
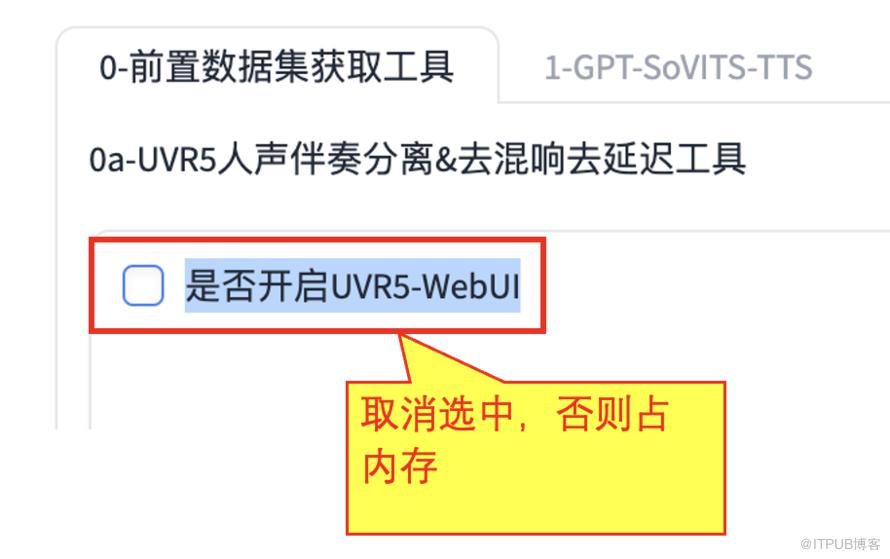
我们首先要做的是去除背景音和杂音,打开Web页面后,找到下面的【0-前置数据集获取工具】,选中下面的【是否开启UVR5-WebUI】。

选中后,过一会儿就会自动打开一个新的Web页面。
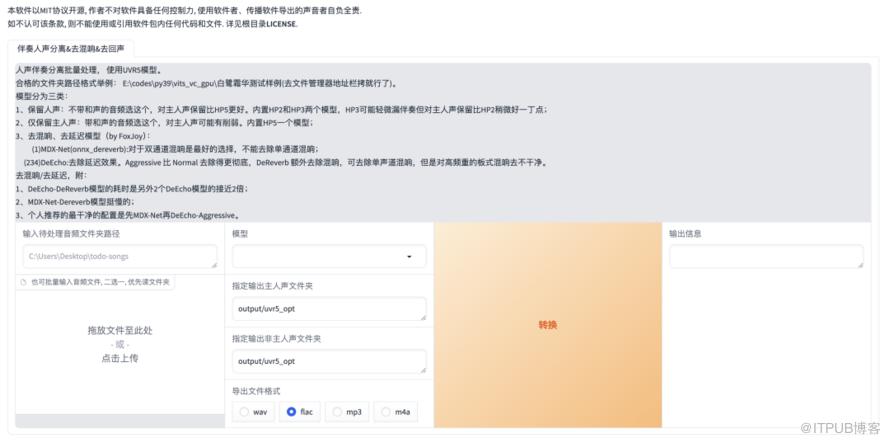
然后在新打开的页面,我们输入下面信息,具体也可参照下面截图说明:
1)输入自己录制转换成wav格式后的音频的路径
2)选择一个模型,建议选择我这个【HP2-all-vocals】
3)转换后输出的路径,可以修改,建议默认的即可
4)转换后的格式,也要选择wav格式
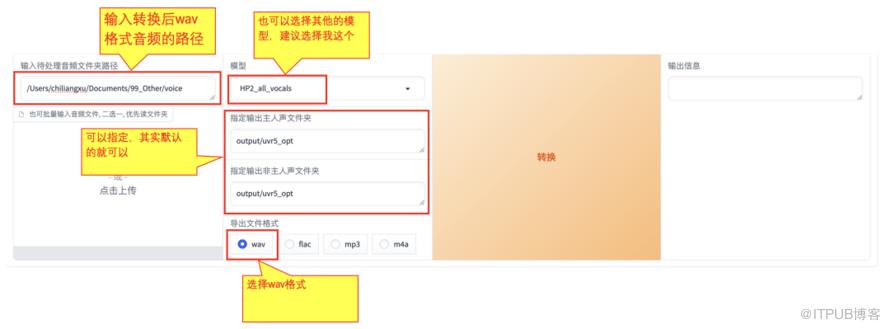
(参照上面信息填写)
单击【转换按钮】,等一会儿(在背后控制台可看到转换的进度),最后会提示转换成功。
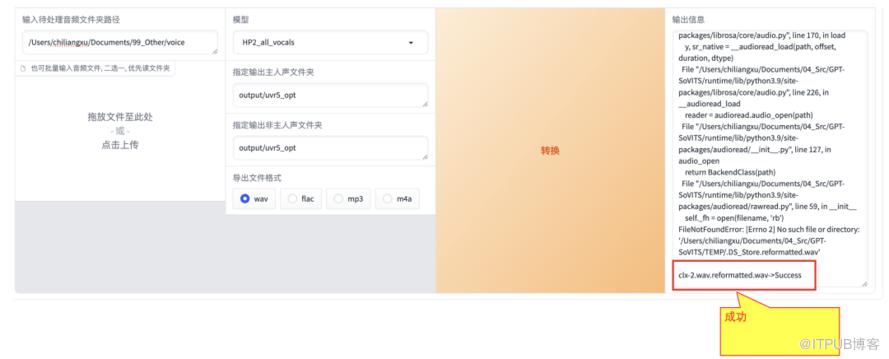
(转换成功)
转换成功后,去上面设置的转换后输出路径中查看,看是否有转换后的文件。

会发现有两个文件,删除第一个instrument开头的那个,只保留下面vocal那个,可以听一下效果如何。

到这里去除背景音和杂音部分就完成了,可以关闭刚才新打开的【UVR5-WebUI】网页,然后取消之前选中的【是否开启UVR5-WebUI】,否则会占用内存。
3、进行语音切割
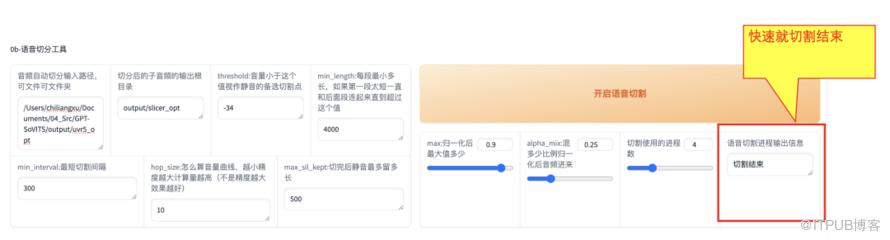
这一步很简单,只需在【语音切分工具】部分,输入上面处理完的output文件夹路径即可,其他参数默认不变。

然后单击【开启语音切割】,很快结束,提示【切割结束】
切割结束后,去对应上面的output文件夹【slicer_opt】路径下确认下是否切割成功了。
(语音切割成功)
4、开启批量离线ASR
在中文批量离线ASR工具部分,输入上面切割后的音频路径,如果上面步骤没改,默认应该是【slicer_opt】中,进行asr文件生成。
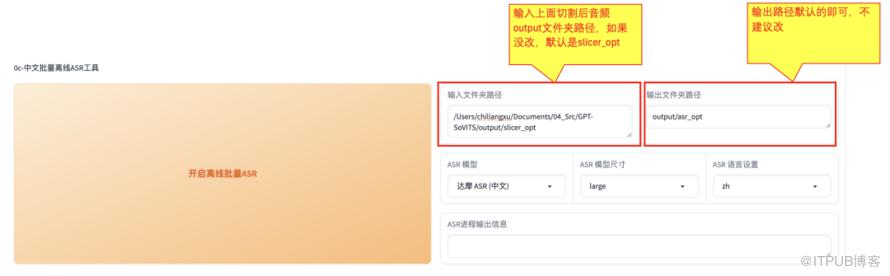
然后单击【开启离线批量ASR】,需要稍等一会儿(同样在控制台可以看到进度),提示【ASR任务完成】才算结束。
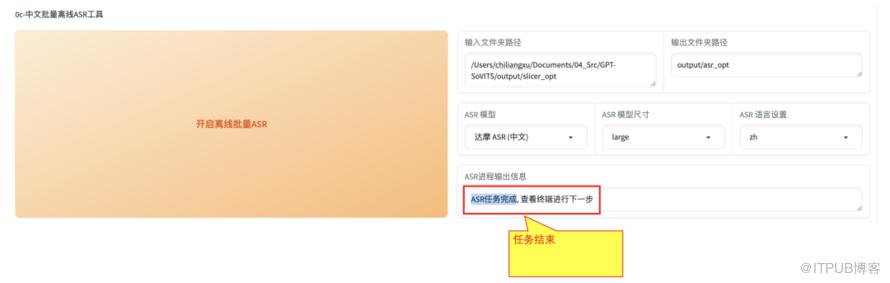
任务结束后,在output对应的asr_opt文件夹,查看结果,会发现有一个【slicer_opt.list】。
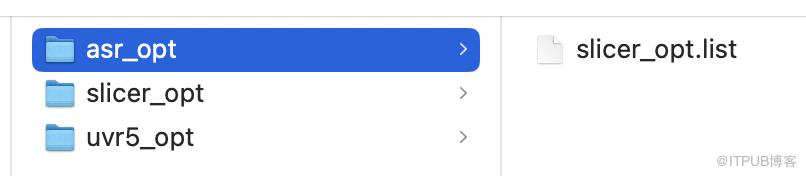
(生成asr成功)
5、进行语音文本校对(这一步很重要)
在【语音文本校对标注工具】中,输入上面生成的【slicer_opt.list】路径,然后选中【是否开启打标WebUI】,过一会儿会打开一个新的web页面,需要一条一条进行语音校对。

在打开新的web页面中,需要对切割后的语音,一条一条的校对,原则如下:
1)、如果语音不清晰的,直接删除
2)、如果文字不正确的,需要改正文字
3)、语音有间隔的,该加标点符号就加
最后要确保,文字与语音的一致性。翻页选择【Next Index】,整体确认后没有问题了,单击【Submit Text】。
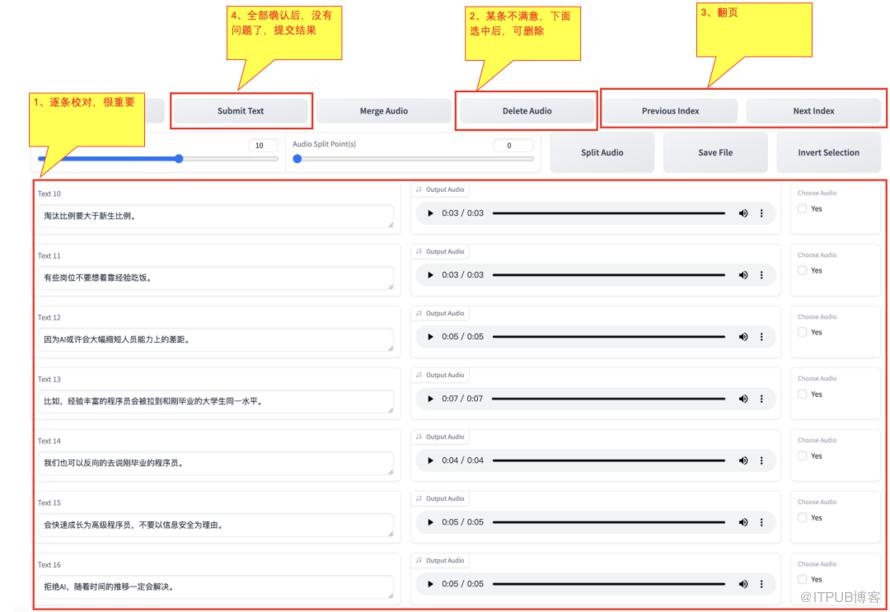
(逐条校对)
提交后,即可关闭新开的网页,回到主页后,和之前一样,取消之前选中的【是否开启打标WebUI】,否则会占用内存。

(回主页后取消选中)
使用GPT-SoVITS(模型训练阶段)
1、开启一键三连
选择【1-GPT-SoVITS-TTS】选项卡后,输入下面三个信息,然后进行一键三连:
1)、【实验/模型名】中输入模型名称,随便起一个即可
2)、【文本标注文件】中输入slicer_opt.list文件路径
3)、【训练集音频文件目录】输入slicer_opt的文件路径
上面三步输入完成后,单击最下面的【开启一键三连】按钮,会稍微等一会儿。

(开启一键三连步骤)
结束后,会提示【一键三连进程结束】

2、进行微调训练(会花一段时间,并且电脑会发热)
首先进行【SoVITS】的训练,可以都设置成默认参数,具体参数不详细介绍了,可以看网页上说明。这里就强调一个参数,如果显卡不太行,建议调低【每张显卡的batch_size】参数,比如设为【8】。然后就可以开始训练了,这一步骤很花时间。
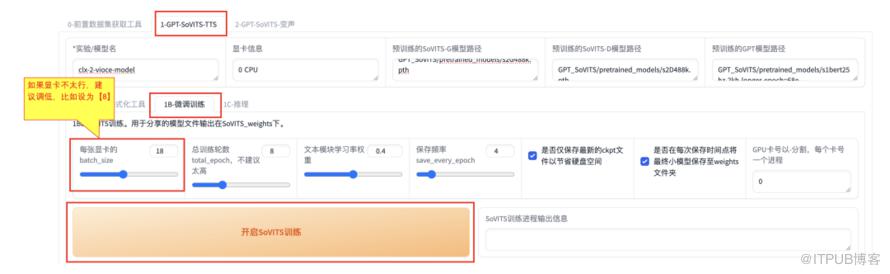
(进行SoVITS训练)
训练的过程和进度,在控制台可以看到,会很漫长。
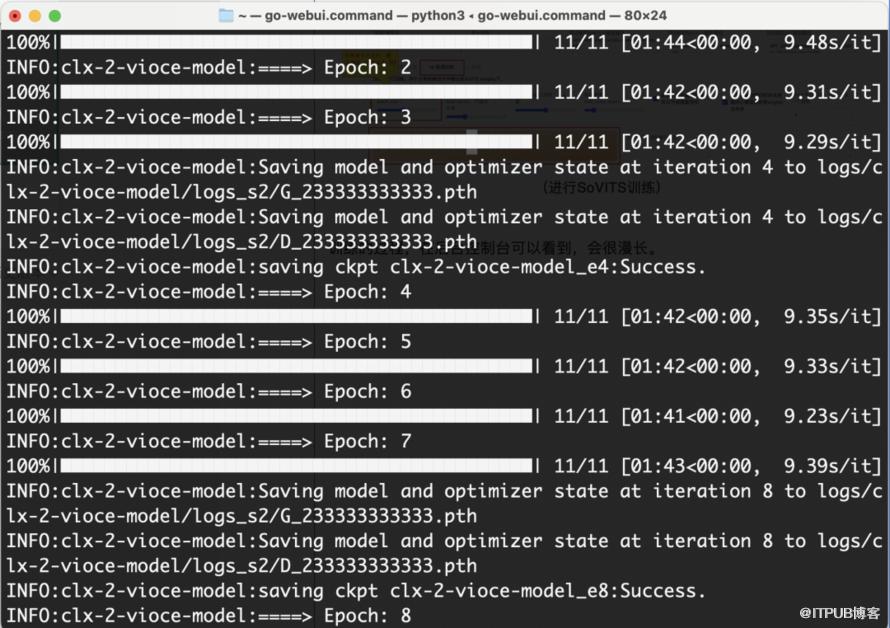
(SoVITS训练中)
训练完成后,会有训练完成的提示。

然后进行【GPT】的训练,参数都默认就可以。如果想要训练后的结果更精确,可以调高【总训练轮数total_epoch】参数,我这里设置为了【30】。

(进行GPT训练)
训练的过程,在控制台可以看到,过程也同样会很漫长。
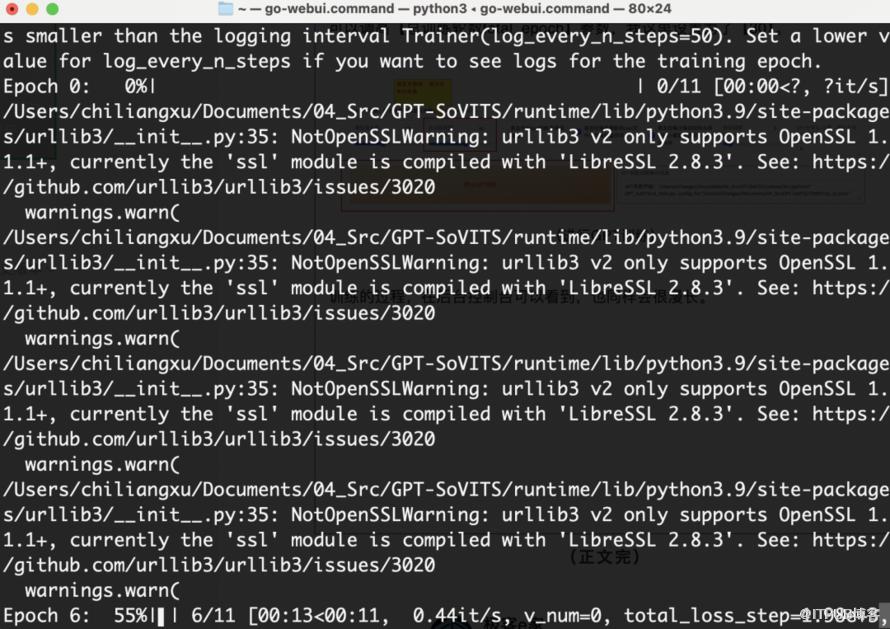
(GPT训练中)
训练完成后,会有训练完成的提示。

推理测试(克隆声音)
终于到了最激动人心的时刻了,我们要试试效果如何。
1、推理前的准备
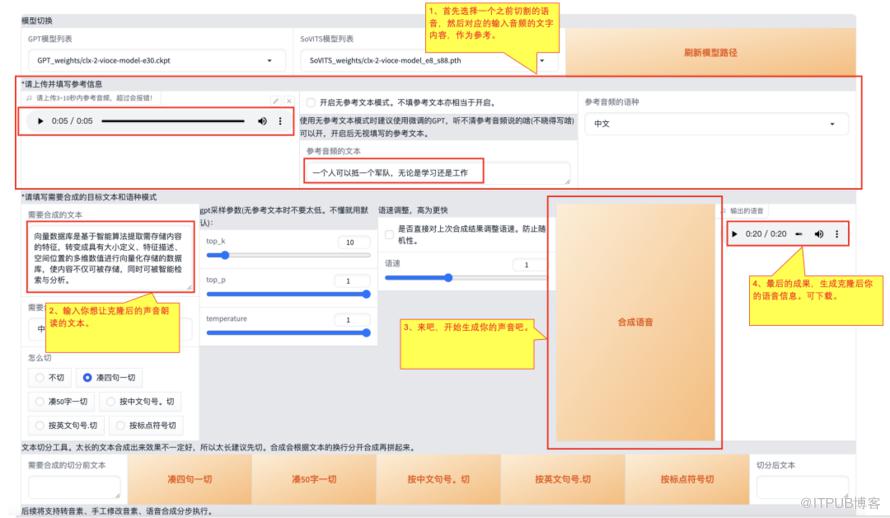
首先在【IC-推理】选项卡,进行下面四步操作,进行推理前的准备。
1)、刷新模型路径
2)、GPT模型列表中,选择最大数的模型
3)、SoVITS模型列表中,选择最大数的模型
4)、选中【是否开启TTS推理WebUI】,开启新的webUI页面,准备进行推理
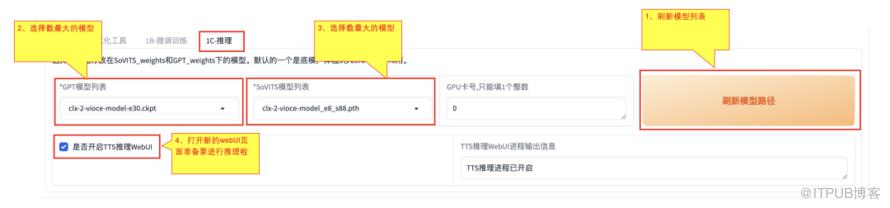
2、进行推理,生成属于自己的语音
1)、选择一个之前切割的语音,然后对应的输入音频的文字内容,作为参考
2)、输入你想让克隆后的声音朗读的文本
3)、单击按钮【合成语音】,这激动人心的时候
最后,你的声音就克隆出来了,在右侧可以在线听或者进行下载。
(克隆声音)
到这里,就彻底完成了,撒花???????
最后给大家展示下效果:
原版音频:
克隆后的音频:
听起来简直就是一模一样,根本分不清是本人还是克隆的声音在说话,有没有被惊艳到!!!
--------------
大家做的过程中,如果有什么疑问,欢迎评论区留言或者私信我。
