我们知道,Hbase 是一个面向列式存储的分布式数据库,其设计思想来源于 Google 的 BigTable 论文。可以通过分布式集群读写海量数据,这是传统的数据库很难实现的,那么 Hbase 是如何做到的呢?下面我们就来共同探讨下 Hbase 的基本架构原理。
一. Hbase 数据结构
1. 逻辑结构
2. 物理结构
二. Hbase 数据模型
Name Space
命名空间,类似于关系型数据库的 DatabBase,每个命名空间下有多个表。
HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。Region
类似于关系型数据库的 Table。不同的是,HBase 定义表时只需要声明 列族 即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态指定。Row
HBase 表中的每行数据都由一个RowKey和多个Column组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以RowKey的设计十分重要。Column
HBase 中的每个列都由Column Family(列族)和Column Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。TimeStamp
用于标识数据的不同版本,每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间。Cell
由{rowkey, column Family:column Qualifier, timeStamp} 唯一确定,并且以字节数组的形式存储。
三. Hbase架构
Hbase 整体主要由 Zookeeper,Hmaster,Region Server,Hdfs文件系统组成。由这四部分共同完成数据的读取与写入。Region Server
Region Server为 Region的管理者,主要作用如下:
- Region 的相关操作:splitRegion、compactRegion
HMaster
HMaster是所有Region Server的管理者,主要作用如下:
- 表的相关操作:create, delete, alter
- RegionServer 的相关操作:分配 regions 到每个 RegionServer,监控每个RegionServer 的状态,负载均衡和故障转移。
Zookeeper
HBase 通过 Zookeeper 来做 Master 的高可用、RegionServer 的监控以及集群配置的维护等工作。HDFS
HDFS 为 HBase 提供底层数据存储服务。
四. Hbase 原理浅析
上图展示了 Hbase 整体架构原理。其中有几个比较重要的概念,如下:
StoreFile
保存实际数据的物理文件,StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有一个或多个 StoreFile,数据在每个 StoreFile 中都是有序的。MemStore
由于 HFile 中的数据要求必须是有序的,所以数据先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile。WAL
由于数据要经 MemStore 排序后才能刷写到 HFile,因此可能导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入 MemStore 中。这样当系统出现故障时,数据可以通过日志文件回放。
1. 数据写入流程
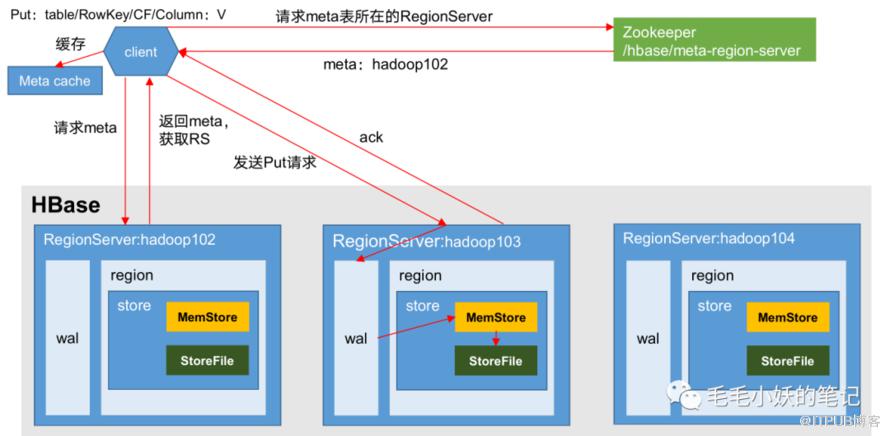
- 客户端程序访问 zookeeper,获取 hbase:meta 表所在的 Region Server 地址。
- 然后再访问对应的 Region Server,获取具体的 hbase:meta 表,根据 rowkey,查询目标数据所在的具体 Region。并将该 table 的 region 信息以及 meta 表的位置缓存在客户端的 meta cache,以便下次访问。
- 将数据写入对应的 MemStore,数据会在 MemStore 进行排序。
- MemStore 的刷写时机到达后,将数据刷写到 HFile。
2. 数据读取流程
前三步其实和数据写入流程一致,都是找到具体的 region Server 并建立连接。然后进行如下操作:
- 分别在 Block Cache,MemStore 和 Store File 中查询目标数据,并将查到的数据进行合并。
- 将从文件中查询到的数据块缓存到Block Cache。
由于 memStore 每次刷写都会生成一个新的 HFile,且同一个字段的不同版本(timStamp)和不同类型(Put/Delete)有可能会分布在不同的 HFile 中,因此查询时需要遍历所有的 HFile。为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为 Minor Compaction 和 Major Compaction。Minor Compaction 会将临近的若干个较小的 HFile 合并成一个较大的HFile。Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大的 HFile,并且会清理掉过期和删除的数据。
五. Hbase 调优
1. HMaster 高可用
在 HBase 中, HMaster 负责监控 HRegionServer 的生命周期 以及 RegionServer 的负载均衡,如果 HMaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,所以HBase支持对HMaster的高可用配置。- 在 conf 目录下创建 backup-masters 文件
touch conf/backup-masters
- 在 backup-masters 文件中配置高可用 HMaster 节点
echo hmaster002 > conf/backup-masters
2. 预分区
每一个 region 维护着 StartRow 与 EndRow,如果新增的数据符合某个 Region 维护的 RowKey 范围,则该数据交给这个 Region 维护。依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能。
create 'demo','info','partition1',SPLITS => ['1000','2000','3000','4000']
create 'demo','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
create 'demo','partition3',SPLITS_FILE => 'splits.txt'
3. RowKey设计
一条数据的唯一标识就是 RowKey,设计 RowKey 的主要目的 ,就是让数据均匀的分布于所有的 region 中,在一定程度上可以防止数据倾斜。接下来我们就看下 RowKey 常用的设计方案。
六. HBase 与 Hive 的对比
- 数据仓库
Hive 的本质相当于将 HDFS 中存储的文件在 Mysql 中做了一个映射关系,以使用 HQL 去查询。
- 用于数据分析、清洗
Hive 适用于离线的数据分析和清洗,延迟较高。
- 基于 HDFS 和 MapReduce
Hive 数据存储在 DataNode 上,编写的 HQL 语句最终还要转换为 MapReduce 代码执行。
- 用于存储结构化和非结构化的数据
适用于单表非关系型数据的存储,不适合做关联查询。
- 基于HDFS
数据存储在 DataNode 中,被 ResionServer 以 region 的形式进行管理。
-
延迟较低
HBase 可以针对单表进行大数据量存储,同时提供了高效的数据访问速度。在数仓中,我们经常用来做维度表和标签系统。




