加速深度学习模型的训练和推理一直是搞算法同学的痛点。
而编译优化的优点就是可以在运行时对源代码进行转换和重组来提高机器代码的执行效率和性能,最好能够做到一些通用优化或自动的剖析与调优,这样就可以将针对单个模型的优化,直接转变为对所有模型的优化。
回到正题,今天我们就聊一聊TensorFlow是如何通过XLA编译器提升模型效率的。
TensorFlow在架构上是前后端分离的实现。用户理论上可以在任何地方,任何语言进行编程,组成算法模型结构,然后将生成的DAG图发送到后端进行重现并执行。
这样设计的好处就是,TensorFlow可以做到通用且高性能,它可以将即使是“阿猫阿狗“写的代码发送到后端,然后根据集成到系统中的专家经验进行图优化,最后执行出较高的性能。这些图优化技术包括我们常听到的常量合并,图剪枝等。
这其实和数据工程中的思路是一致的,例如Spark, Flink, Presto 等都是采用先生成DAG图,然后在对其进行优化,最后再进行执行。这些优化的经验,也基本可以在各种引擎上共用。
不过,TensorFlow毕竟属于算法特定场景的数据流图执行工具,其在内部支持实现了XLA的图优化技术,严格来说,它不只是图优化技术,它是一个可以提高TensorFlow内核执行速度的Fusion编译器。
1. XLA 是什么?
Tensorflow XLA(加速线性代数)是一个可以提高张量流内核执行速度的编译器,
当运行 TensorFlow 图表时,所有运算都由 TensorFlow 图表执行器单独执行。每个运算都会安装由图表执行器分派的预编译 GPU 内核。
XLA 提供了另一种运行 TensorFlow 模型的模式:这种模式会将您的 TensorFlow 图表中不同的线性代数/计算内核融合在一起,然后在专用寄存器上进行处理,提供了一种基于内存带宽的创新优化。
举一个例子,我们一起看看 XLA 在简单 TensorFlow 计算环境中的优化过程:
def model_fn(x,y,z):
return tf.reduce_sum(x + y * z)
如果运行模型时不使用 XLA,图表会启动三个内核,分别用于乘法、加法和减法。
但是,XLA 可以优化图表,以便在启动单个内核时计算结果。方法是将加法、乘法和减法 “融合” 到单个 GPU 内核中。此外,这种融合运算不会将 yz 和 x+yz 生成的中间值写入内存,而是将这些中间计算的结果直接 “流式传输” 给用户,并完整保存在 GPU 寄存器中。
融合是 XLA 最重要的一种优化方式。内存带宽通常是硬件加速器上最稀缺的资源,因此删除内存运算是提升性能的最佳方法之一。
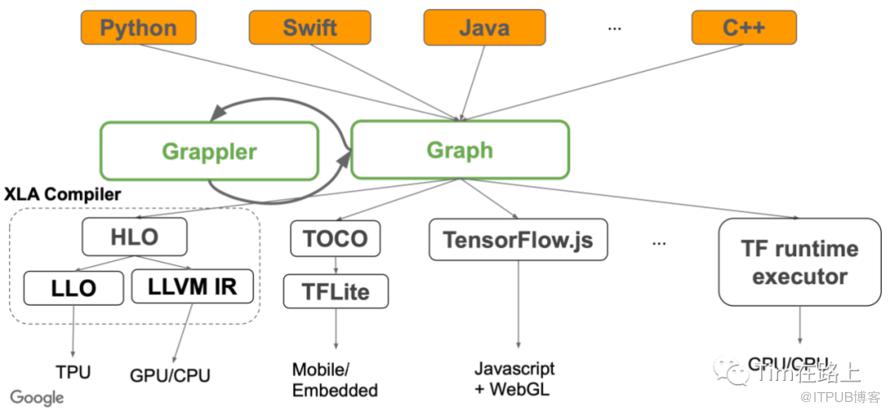
2. 如何使用XLA
基于JIT编译机制使用XLA主要有以下几种方式:
在会话打开打开JIT编译
config = tf.ConfigProto()
config.graph_options.optimizer_options.global_jit_level= tf.OptimizerOptions.ON_1
sess = tf.Session(config=config)
把所有可能操作符编程成XLA计算。
通过环境变量打开JIT编译
os.environ['TF_XLA_FLAGS'] = '--tf_xla_auto_jit=fusible’
os.environ['XLA_FLAGS'] = "--xla_dump_hlo_as_text --xla_dump_to=xla_dumps/ --xla_dump_hlo_pass_re='.*' --xla_dump_hlo_as_html"
此外,如果想要输出XLA编译优化过程中的详细优化日志与中间图,可以通过以上参数设置,注意是一个是XLA_FLAGS一个是TF_XLA_FLAGS。
通过手动启动JIT编译
用户也可以通过编程的方式开启XLA, 如下:
with tf.xla.experimental.jit_scope(compile_ops=True):
...
不过这里要注意的是,如果想部分开启XLA,需要先全局关闭,再针对部分开启;
with tf.xla.experimental.jit_scope(compile_ops=False):
...
with tf.xla.experimental.jit_scope(compile_ops=True):
...
3. 使用 XLA 的注意事项
XLA 无法编译所有 TensorFlow 图表,只有具有以下属性的图表才能传递给 xla.compile。
所有运算都必须具有可推断的形状
XLA 需要能够在给定计算输入的情况下,推断出其编译的所有运算的形状。因此,如果模型函数生成的 Tensor 具有不可推断的形状,则运行时将会出现错误,进而导致运行失败。
XLA 必须支持所有运算
并非所有 TensorFlow 运算都可由 XLA 编译,如果模型中有 XLA 不支持的运算,XLA 编译就会失败。例如,XLA 不支持 tf.where 运算,因此如果您的模型函数包含此运算,使用 xla.compile 运行模型时便会失败。
XLA 支持的每项 TensorFlow 运算都可在 tensorflow/compiler/tf2xla/kernels/ 中调用 REGISTER_XLA_OP,因此您可以使用 grep 来搜索 REGISTER_XLA_OP 宏实例,以查找支持的 TensorFlow 运算列表。
4. XLA执行流程
我们来简单拆解下XLA的实现。
XLA在实现上是对TensorFlow原有执行流程和运行时组件的增加,其主要如下图所示:
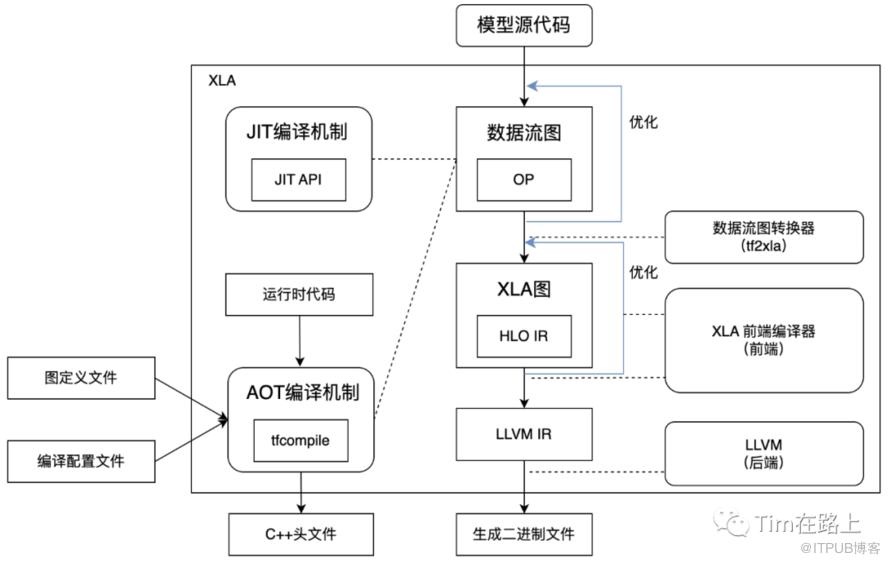
XLA主要由数据流图转换器、XLA编译器、JIT(just-in-time)编译机制、AOT(ahead-of-time)编译机制等模块构成。
在介绍这些模块之前,我们先来了解下,什么是JIT与AOT:JIT (Just-In-Time)是一种编译技术,它在程序运行时动态地将代码编译为机器代码,这允许程序的行为根据运行时的环境和输入数据进行调整和优化,而且某些维度变量(例如批处理大小)可以在非常晚的阶段进行绑定,增加了灵活度。相反AOT预先编译属于静态编译,源代码在应用程序部署之前就需要被编译成目标机器的本地机器代码。
我们首先来介绍下这些模块:
JIT编译机制,用于在Tensorflow应用运行时创建执行数据流图操作的二进制代码,它是一套面向异构设备的通用性能优化机制。该模块的源代码位于tensorflow/compiler/jit。IT编译机制会对数据流图的可优化部分实施优化,将其中大量细粒度的操作融合为少量粗粒度的专用核函数。模型开发者使用JIT机制时,需要在代码中显式引入JIT API,将会话或操作配置为XLA编译模式
AOT编译机制,用于在Tensorflow应用运行前创建集成了模型和运行时的二进制代码,该代码位于tensorflow/compiler/aot。模型开发者使用AOT机制时,需要提供protocol buffers格式编写的数据流图定义文件及编译配置文件。然后使用bazel构建工具,调用AOT封装工具-tfcompile编译数据流图。
数据流图转换器,在Tensorflow数据流图执行前,转换器基于数据流图创建XLA图,将原图中那些可通过XLA优化的操作节点替换为XLA层函数,其实现了一系列线性代数相关的核函数子类,原图中那些可通过XLA优化的操作节点替换为XLA层函数,源代码位于tensorflow/compiler/tf2xla。
XLA编译器用于将XLA图编译为二进制文件,其源代码位于tensorflow/compile/xla。该模块基于LLVM技术实现。在编译器中,前端解析并优化XLA图,将其底层化为LLVM IR,后端将LLVM IR编译为设备特征的二进制文件,并执行二进制代码优化。XLA编译器采用客户端-服务器模式设计,以便管理编译过程的生命周期。
这里我们以JIT方式执行XLA进行举例,JIT目前是XLA使用最多的方式。
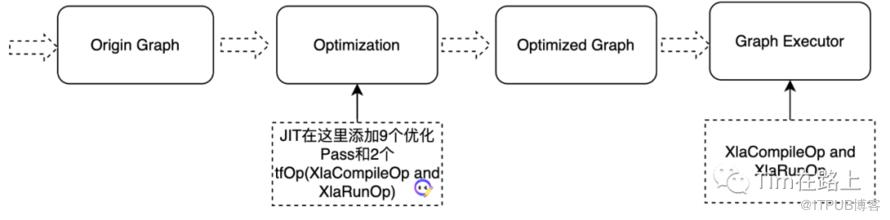
如上图所示,原始的TensorFlow图会通过图优化规则以及TFOp来接入JIT XLA编译的,下面我们展开细说下这里的执行过程。
要想了解这个过程,首先就需要知道TensorFlow图优化过程,TensorFlow中定义一些图优化规则,这些优化规则可能会被执行一遍或多遍的执行。不同的优化策略被应用的时机又是不相同的,某些只有图发生改变时(Extend或Create)被调用执行,某些优化规则是Session.Run时执行,这里不是重点就不展开介绍。

这里我们简单介绍下,GraphOptimizationPass它其中的优化规则就分为四个阶段:
PRE_PLACEMENT(在将设备分配给计算图中的每个节点之前)
POST_PLACMENT (将设备分配给计算图的每个节点之后,在 Grappler 优化计算图之前)
POST_REWRITE_FOR_EXEC (计算图经过 Grappler 优化之后,计算图被设备分割之前)
POST_PARTITIONING(按设备对计算图进行分区后(通过GraphOptimizer优化计算图之前))
具体和XLA相关的优化算子与其执行时机,如下图所示:

其中, MarkForCompilationPass, EncapsulateSubgraphsPass 和 BuildXlaOpsPass 最为关键。
MarkForCompilationPass 用于标记可以使用XLA操作的计算图的节点;
EncapsulateSubgraphsPass 用于将 TensorFlow 计算图簇转换为 XLA 可以处理的计算子图,并交付给BuildXlaOpsPass。
BuildXlaOpsPass 用于将TensorFlow计算图中的节点簇替换为
_XlaCompile节点和_XlaRun节点。
经过上述优化后, TensorFlow中可以被XLA优化的计算子图已经被转换为 XlaCompileOp + XlaRunOp 节点。
而JIT的编译过程XlaCompile中进行的,XlaCompileOp编译得到的二进制直接送到紧接其后的XlaRunOp中执行。
由于XlaCompileOp里面有用于存储之前编译结果的Cache,所以理想情况下(图不变与输入的shape不变),只有第一次会真正的编译。之后的step中由于Cache hit,XlaCompileOp的成本就很低了, 这也是XLA你能够实现加速核心原因。
但是, 在特征识别等输入频繁变动的场景, 由于XlaCompileOp的Cache Miss的概率大大增加, 整体性能就会比常规的TF执行引擎差。
5. JIT XLA 过程梳理
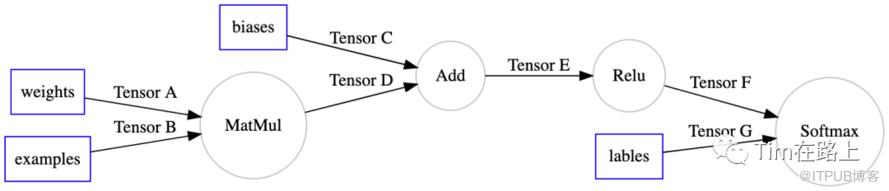
我们先来看 XLA 如何作用于 TensorFlow 的计算图,下面是一张简单的 TensorFlow 计算图。
1. Optimization
MarkForCompilationPass
XLA 通过一个 TensorFlow 的图优化 Pass (MarkForCompilation),在 TensorFlow 计算图中找到适合被 JIT 编译的区域。然后把这个区域定义为一个 Cluster,作为一个独立的 JIT 编译单元,在 TensorFlow 计算图中通过 Node Attribute 标示。标记的方法就是将每一个Node分配一个Cluster编号(_XlaCluster:cluster_0),相同则为同一个Cluster。
EncapsulateSubgraphsPass
根据MarkForCompilationPass对Node cluster的标记,将相同Cluster下的所有Node封装到一个名为cluster_XXX的一个节点中,并把 Cluster 转化成 TensorFlow 的一个 Function 子图。
BuildXlaOpsPass
最后调用 TensorFlow 的图优化 Pass (BuildXlaOps),把 Function 子图转化成特殊的 Xla 节点。每一个Cluster子图都会被替换为XlaCompile + XlaRun。
在 TensorFlow 运行时,运行到 XlaCompile 时,编译 Xla cluster 子图,然后把编译完的 Executable 可执行文件通过 XlaExecutableClosure 传给 XlaRun 运行。
2. TF2XLA
TensorFlow 运行到 XlaCompile 节点时,为了编译这个 Function,通过把 TensorFlow 子图所有的节点翻译成 XLA HLO Instruction 虚拟指令的形式表达,整个子图也由此转化成 XLA HLO Computation。
3. XLA-HLO
XLA 在 HLO 的图表达上进行图优化。聚合可在同一个 GPU Kernel 中执行的 HLO 指令。
4. 代码生成
首先根据虚拟指令分配 GPU Stream 和显存。
然后 IrEmitter 把 HLO Graph 转化成由编译器的中间表达 LLVM IR 表示的 GPU Kernel。
由 LLVM 生成 nvPTX(Nvidia 定义的虚拟底层指令表达形式)表达,进而由 NVCC 生成 CuBin 可执行代码。主要在获取cubin的同时会将其存入CompilationCache以便后续使用。
5. 代码执行
当 TensorFlow 运行到 XlaRun 时,会先从OpContext中获取到XlaCompileOp存入的Key,通过Key找到由 XlaCompile 编译得到的 GPU 可执行代码(Cubin 或 PTX),然后再进行运行。

可以看到只有第一次XlaCompileOp会调用ptx执行真正的编译, 第二次由于Cache Hit,就不再有真实编译了。
6. 总结
下面我们来总结下TensorFlow 如何与 XLA 结合使用来优化计算图的:
通过图优化将适合进行 JIT 编译的区域标记为 Cluster。
将相同 Cluster 下的节点封装为一个子图,并转换为 Xla 节点。
运行时,将子图翻译成 XLA 的虚拟指令形式。
XLA 对虚拟指令进行图优化,聚合可在同一个 GPU Kernel 执行的指令。
生成 GPU Kernel 的 LLVM IR 表示,并最终生成可执行代码。
在执行时,从缓存中获取已编译的代码,并进行计算。
通过 XLA 的优化,可以将 TensorFlow 计算图的某些区域进行 JIT 编译并执行,从而提高计算性能和效率。