在Spark中,Executor是运行在每个工作节点上的计算单元,负责执行任务并管理内存资源。其中,每个Executor实例运行在一个独立的JVM进程中,并分配了一定的计算资源(CPU、内存等)。
合理配置和管理Executor端的内存可以显著提高应用程序的吞吐量和响应时间,并避免由于内存不足而引起的性能问题或报错。例如Executor端经常发生的OutOfMemoryError错误非常引人头疼。
Spark提供了一些内存管理相关的参数,如Executor内存总量、堆内存占比、缓存管理等,如何更好的使用这些参数来利用Spark内存就需要了解Spark的内存机制。
1. 内存总体布局
整个Executor内存区域分为两部分:堆外内存、堆内内存。
1.1 堆外内存
在Spark中,其堆外内存的大小由 spark.executor.memoryOverhead 参数指定,默认大小为 executorMemory * 0.10, with minimum of 384m。
堆外内存是一种在Executor端使用的内存空间,用于存储Spark的内部数据结构和缓存,以减少对Java堆的压力并提高性能。
默认情况下,Executor的堆外内存是由Off-Heap内存管理器来管理的,而不是使用Java堆内存。Off-Heap内存是直接分配在操作系统的内存空间中,而不受Java堆大小的限制。
使用堆外内存可以通过配置Spark的内存管理参数来实现。主要的参数是spark.memory.offHeap.enabled,默认值为false。如果将其设置为true,Spark将启用堆外内存管理。此外,还可以通过spark.memory.offHeap.size参数来指定堆外内存的总大小。
1.2 堆内内存
大小由 Spark 应用程序启动时的 –executor-memory 或 spark.executor.memory 参数配置,即JVM最大分配的堆内存 (-Xmx)。Spark为了更高效的使用这部分内存,对这部分内存进行了逻辑上的划分管理。
注意事项:
对于Yarn集群,需要满足下面要求: ExecutorMemory + MemoryOverhead <= MonitorMemory,若应用提交之时,指定的 ExecutorMemory 与 MemoryOverhead 之和大于 MonitorMemory,
则会导致 Executor 申请失败;若运行过程中,实际使用内存超过上限阈值,Executor 进程会被 Yarn 终止掉 (kill)。
2. 内存管理
Spark 内存管理主要包括:
静态内存管理(StaticMemoryManager)
统一内存管理(UnifiedMemoryManager)
UnifiedMemoryManager 是 Spark 1.6 之后默认的内存管理器,1.6 之前采用的静态管理(StaticMemoryManager)方式仍被保留, 可通过配置 spark.memory.useLegacyMode 参数启用。
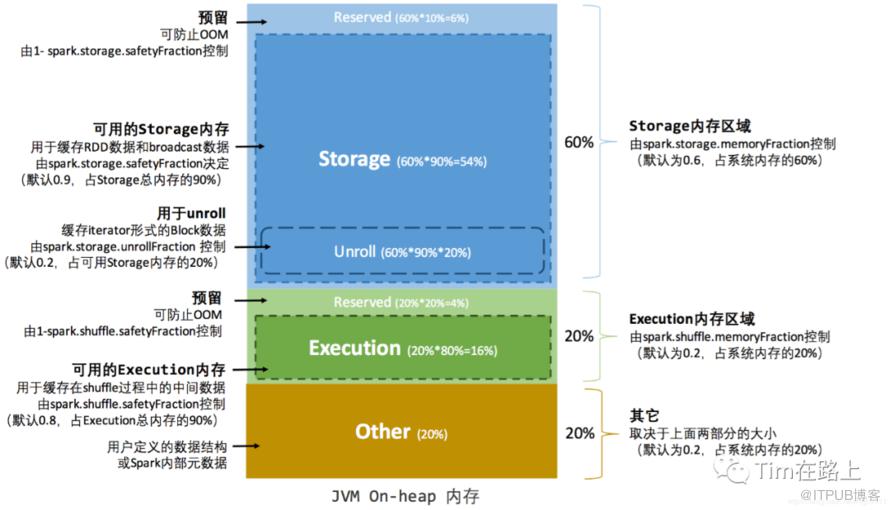
2.1 静态内存管理
2.2 统一内存管理
统一内存管理,包括:堆内内存(on-heap Memory) 和堆外内存 (off-heap Memory) 两大区域,下面对这两块区域进行详细的说明。
堆内内存 (on-heap Memory)
默认情况下,Spark 仅仅使用了堆内内存,spark 对堆内内存的管理是一种逻辑上的"规划式"的管理,Executor 端的堆内内存区域在逻辑上被划分为以下四个区域:
执行内存 (Execution Memory): 主要用于存放: Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据
存储内存 (Storage Memory): 主要用于存储 spark 的 cache 数据,例如:RDD的缓存、unroll数据, 其中sql场景cache table等
用户内存(User Memory: 主要用于存储 RDD 转换操作所需要的数据,例如:RDD 依赖等信息
-
预留内存(Reserved Memory: 系统预留内存,会用来存储Spark内部对象
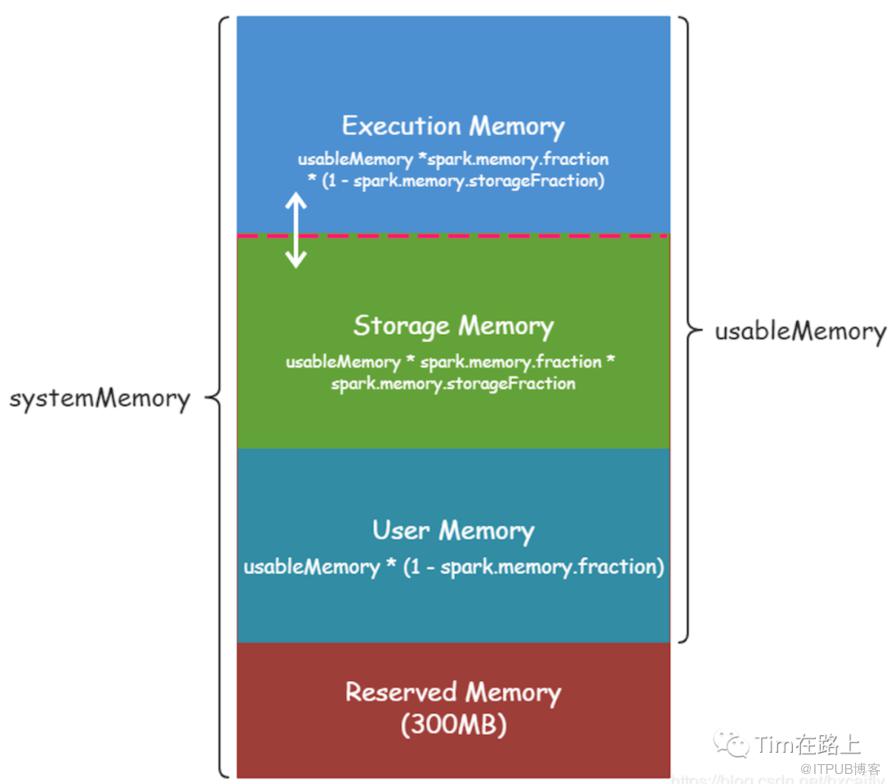
The region shared between execution and storage is a fraction of (the total heap space - 300MB)
configurable through `spark.memory.fraction` (default 0.6). The position of the boundary within
this space is further determined by `spark.memory.storageFraction` (default 0.5).
This means the size of the storage region is 0.6 * 0.5 = 0.3 of the heap space by default.
• systemMemory = Runtime.getRuntime.maxMemory,其实就是通过参数 spark.executor.memory 或 --executor-memory 配置的。
堆外内存 (off-heap Memory)
如果堆外内存被启用,那么 Executor 内将同时存在堆内和堆外内存,两者的使用互不影响,这个时候 Executor 中的 Execution 内存是堆内的 Execution 内存和堆外的 Execution 内存之和,同理,Storage 内存也一样。其内存分布如下图所示:
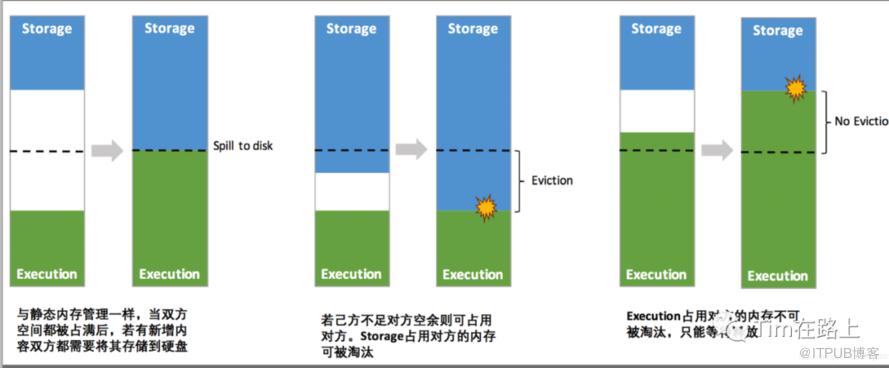
统一内存管理机制
与静态内存管理最大的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域:
其中最重要的优化在于动态占用机制,其规则如下:
程序提交的时,会设定基本的 Execution 内存和 Storage 内存区域(spark.memory.storageFraction default 0.5 参数设置)。我们用 onHeapStorageRegionSize 来表示 spark.storage.storageFraction 划分的存储内存区域。
当计算内存不足时,可以借用 onHeapStorageRegionSize 中未使用部分,且 Storage 内存的空间被对方占用后,需要等待执行内存自己释放,不能抢占(这里需要注意)。
若实际 StorageMemory 使用量超过 onHeapStorageRegionSize,那么当计算内存不足时,可以驱逐并借用 StorageMemory – onHeapStorageRegionSize 部分,而 onHeapStorageRegionSize 部分不可被抢占。
源码片段:
def maybeGrowExecutionPool(extraMemoryNeeded: Long): Unit = {
if (extraMemoryNeeded > 0) {
// There is not enough free memory in the execution pool, so try to reclaim memory from
// storage. We can reclaim any free memory from the storage pool. If the storage pool
// has grown to become larger than `storageRegionSize`, we can evict blocks and reclaim
// the memory that storage has borrowed from execution.
val memoryReclaimableFromStorage = math.max(
storagePool.memoryFree,
storagePool.poolSize - storageRegionSize)
if (memoryReclaimableFromStorage > 0) {
// Only reclaim as much space as is necessary and available:
val spaceToReclaim = storagePool.freeSpaceToShrinkPool(
math.min(extraMemoryNeeded, memoryReclaimableFromStorage))
storagePool.decrementPoolSize(spaceToReclaim)
executionPool.incrementPoolSize(spaceToReclaim)
}
}
}
反之,当存储内存不足时(存储空间不足是指不足以放下一个完整的 Block),也可以借用计算内存空间;但是 Execution 内存的空间被存储内存占用后,是可让对方将占用的部分转存到硬盘,然后“归还”借用的空间。
如果双方的空间都不足时,则存储到硬盘;将内存中的块存储到磁盘的策略是按照 LRU(最近最少使用) 规则进行的。
3. 任务内存管理
Executor 中任务以线程的方式执行,各线程共享JVM的资源,任务之间的内存资源没有强隔离(任务没有专用的Heap区域)。因此,可能会出现这样的情况:先到达的任务可能占用较大的内存,而后到的任务因得不到足够的内存而挂起。
在 Spark 任务内存管理中,使用 memoryForTask (一个HashMap数据结构) 存储任务与其消耗内存的映射关系。每个任务可占用的内存大小为潜在可使用计算内存(潜在可使用计算内存为: 初始计算内存 + 可抢占存储内存)的 1/2n ~ 1/n,当剩余内存为小于 1/2n 时,任务将被挂起,直至有其他任务释放执行内存,而满足内存下限 1/2n,任务被唤醒。其中 n 为当前 Executor 中活跃的任务数量。
任务执行过程中,如果需要更多的内存,则会进行申请,如果存在空闲内存,则自动扩容成功,否则,将抛出 OutOffMemroyError。每个 Executor 中可同时运行的任务数由 Executor 分配的 CPU 的核数 N 和每个任务需要的 CPU 核心数 C 决定。其中:
N = spark.executor.cores
C = spark.task.cpus (default 1)
3.1 内存管理
MemoryManager 内存管理器(一个executor对应一个实例),限制executor存储内存(storage)和执行内存(execution)大小的管理器,两个实现类:StaticMemoryManager、UnifiedMemoryManager(默认,Executor创建spark-env时创建)
MemoryManager主要功能是:
记录用了多少StorageMemory和ExecutionMemory
申请Storage、Execution Memory
释放Stroage、Execution Memory
MemoryManager创建StorageMemoryPool和ExecutionMemoryPool对象,用来创建堆内或堆外的Storage和Execution内存池,管理Storage和Execution的内存分配。
ExecutionMemoryPool核心方法:
+ memoryForTask
+ memoryUsed
+ getMemoryUsageForTask
+ acquireMemory
+ releaseMemory
+ releaseAllMemoryForTask
StorageMemoryPool核心方法:
+ memoryUsed
+ memoryStore
+ setMemoryStore
+ acquireMemory
+ releaseMemory
+ releaseAllMemory
+ freeSpaceToShrinkPool
on-heap:
onHeapExecutionMemoryPool
onHeapStorageMemoryPool
off-heap:
offHeapExecutionMemoryPool
offHeapStorageMemoryPool
usableMemory = systemMemory - reservedMemory(300M)
maxHeapMemory= (usableMemory * memoryFraction).toLong // memoryFraction = 0.6
maxOffHeapMemory = conf.get(MEMORY_OFFHEAP_SIZE) // spark.memory.offHeap.size 堆外内存
onHeapStorageMemoryPool = maxHeapMemory * spark.memory.storageFraction (default 0.5)
onHeapExecutionMemoryPool = maxHeapMemory * (1 - spark.memory.storageFraction)
offHeapStorageMemoryPool= maxOffHeapMemory * spark.memory.storageFraction
offHeapExecutionMemoryPool= maxOffHeapMemory * (1 - spark.memory.storageFraction)
3.2 StorageMemory 管理
MemoryStore 的内存模型
MemoryStore负责将 Block 存储到内存,减少对磁盘的依赖,MemoryStory依赖MemoryManager(与之相对应的是DiskStore,负责将Block存储在磁盘上)。
其中:
maxMemory = memoryManager.maxOnHeapStorageMemory + memoryManager.maxOffHeapStorageMemory
MemoryStore分为三部分:
blocksMemoryUsed:Block存储占用(存储为MemoryEntry,一种特制,有两种实现:DeserializedMemoryEntry、SerializedMemoryEntry)
currentUnrollMemory:将要被展开的Block数据占用的内存,称为currentUnrollMemory
未被使用的内存
其他补充:
在MemoryStore中,存储/执行内存的软边界,堆内/堆外内存的隔阂都是透明的,其原因:MemoryStory依赖MemoryManager
展开(Unroll)操作的内存必须是将整个Block内存提前申请好的,防止向内存真正写入数据的时候发生内存溢出
展开(Unroll)所申请的这部分其实并没有被真正的占用,是先过一遍partition的数据,看一下全部cache到内存需要占用多大,然后向MemoryManager预约这么大的内存,如果完全足够,那么才将数据完全存储到内存中,这时候占用内存是StorageMemory中的。
3.2 ExecutionMemory 管理
3.2.1 ExecutionMemory的内存模型
TaskMemoryManager 是Tungsten内存管理机制的核心实现类(Tungsten内存管理只作用于执行内存),TaskMemoryManager 用于管理单个任务尝试的内存分配与释放, 实际上依赖于MemoryManager提供的内存管理能力,多个TaskMemoryManager将共享MemoryManager所管理的内存。它的功能包括:
建立类似于操作系统内存页管理的机制,对ON_HEAP和OFF_HEAP内存统一编址和管理
通过调用MemoryManager(逻辑内存)和MemoryAllocator(物理内存),将逻辑内存的申请、释放与物理内存的分配、释放结合起来
记录和管理task attempt的所有Memory Consumer(执行内存的申请及释放是以Memory Consumer为基本单元)
3.2.2 MemoryConsumer 分布情况
在 Spark 中,使用抽象类 MemoryConsumer 来表示需要使用内存的消费者。在这个类中定义了分配,释放以及 Spill 内存数据到磁盘的一些方法或者接口。
具体的消费者可以继承 MemoryConsumer 从而实现具体的行为,其有各种实现(包括:Shuffle、Join、Sort、Aggregation 等类型),统计有13个。
注:3.2.1中已经提到,逻辑内存的申请、释放与物理内存的分配、释放结合起来,实现内存管理。
真正物理内存控制
+allocateArray(long size)
+freeArray(LongArray array)
+allocatePage(long required)
+freePage(MemoryBlock page)
逻辑上面的内存控制
+acquireMemory(long size)
+freeMemory(long size)
3.2.3 Execution Memory 详细分布情况
因 StorageMemory可能会被借用,故StorageMemory也作为其一部分。
注:每个Task都会有一个独立的TaskMemoryManager为其管理内存,多个task的 TaskMemoryManager共享MemoryManager的内存,每一个TaskMemoryManager管理任务又会有多个MemoryConsumer进行消费及释放。
4. 内存分配器
内存管理提供了在 Tungsten 的堆外内存上分配内存的UnsafeMemoryAllocator和堆内内存上分配内存HeapMemoryAllocator。
UnsafeMemoryAllocator 是通过sun.misc.Unsafe的各种API操控系统内存
HeapMemoryAllocator是通过JVM Heap上分配对象的方式操控JVM Heap
操作系统中的 Page 是一个内存块,在 Page 中可以存放数据,操作系统中会有多种不同的 Page; 操作系统对数据的读取,往往是先确定数据所在 Page,然后使用 Page 的偏移量(offset)和 所读取数据的长度(length)从 Page 中读取数据。
于是spark里面的 Tungsten 中实现了一种与操作系统的内存页 Page 非常相似的数据结构,这个对象就是 MemoryBlock,MemoryBlock中的数据可以位于JVM Heap上,也可以位于 off-heap上面。
MemoryBlock 包含以下成员:
length:内存块大小
pageNumber:Page id
obj:堆内:对象在JVM堆中的地址;堆外:该值为null
offset:堆内:Page 的起始地址(相对于所在对象在JVM堆地址的偏移量);堆外:Page 在操作系统内存中的地址
4.1 HeapMemoryAllocator 内存分配器
在分配 MemoryBlock 时,申请的大小大于1M,且在 bufferPoolsBySize 中存在指定大小的MemoryBlock,则从bufferPoolsBySize中获取 MemoryBlock
在分配 MemoryBlock 时,申请的内存大小小于1M,或者 bufferPoolsBySize 中不存在指定大小的MemoryBlock,则单独的创建 MemoryBlock
在释放 MemoryBlock 时,如果 MemoryBlock 的大小大于1M,则将此 MemoryBlock 放入 bufferPoolsBySize中
MemoryBlock 的 obj 属性保存了对象在JVM堆中的地址
MemoryBlock 的 offset 属性保存了 Page 的起始地址(相对于所在对象在JVM堆地址的偏移量)
MemoryBlock 的 lengh 属性保存了 Page 的页面大小(即从offset开始,连续的内存空间的大小)
4.2 UnsafeMemoryAllocator 内存分配器
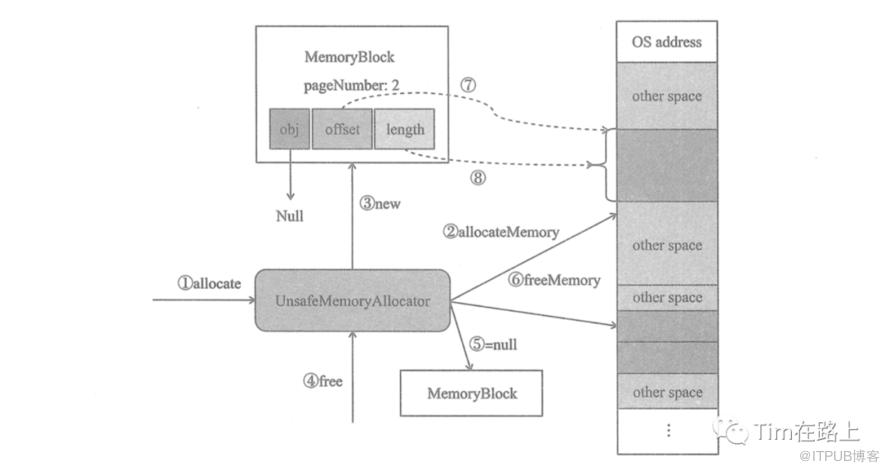
调用 UnsafeMemoryAllocator 的allocate方法分配 MemoryBlock
UnsafeMemoryAllocator 调用 sum.misc.Unsafe 的 allocatorMemory 方法请求操作系统分配内存
操作系统分配内存后,将此块内存的地址信息返回给 UnsafeMemoryAllocator ,UnsafeMemoryAllocator 利用内存地址信息及内存大小创建 MemoryBlock ,注意此时的 obj 属性为null
调用 UnsafeMemoryAllocator 的free 方法释放 MemoryBlock
在调用 UnsafeMemoryAllocator 的free 方法之前,调用方已经将此 MemoryBlock 的引用设置为null
UnsafeMemoryAllocator 调用 sum.misc.Unsafe 的 freeMemory方法请求操作系统释放内存
MemoryBlock 的 offset 属性保存 Page 在操作系统内存中的地址
-
MemoryBlock 的 lengh 属性保存了 Page 的页面大小(即从offset开始,连续的内存空间的大小)