TensorFlow是一个前后端分离的计算框架,这样的架构可以使得前端可以在任何地方任何设备上使用API进行构建模型,不会受限于资源、设备的限制。
那么TensorFlow是如何建立前后端的联系的?
在TF中Session起着建立前后端联系的桥梁的作用,用户可以通过创建和管理Session来连接前后端的通道;然后通过session.run()触发一次计算,将前端的graph封装为graphdef pb格式发送到后端,后端在通过graphdef将计算图进行重建、剪枝与分裂,以及分配设备,最终将图运行在多个Executor上。
Session之间采用共享graph的方式来提高运行效率。一个session只能运行一个graph实例。不过一个graph可以被运行在多个session中。
一般情况下,创建session时如果不指定Graph实例,则会使用系统默认Graph。常见情况下,我们都是使用一个graph,即默认graph。
当session创建时,如果graph存在则不会重新创建graph实例,而是将默认graph引用计数加1。当session close时,引用计数减1。只有引用计数为0时,graph才会被回收。
1. Session资源管理
在TF中Session不仅仅是前后端计算连接的通道,同时其还是一个资源管理器,管理着如下资源:
1.图(Graph):Session 管理着计算图的执行,因此也管理着计算图本身,即 Graph 对象,一个Session可以运行一个图实例,但可以并发的运行多个不同子图。
2.变量(Variable):在 TensorFlow 中,变量是需要被存储和优化的张量,Session 会为每个变量分配内存空间,并在运行时更新它们的值。
3.队列(Queue):TensorFlow 中的队列是异步读写的,用于输入数据的存储和读取。Session 会管理这些队列,包括在训练过程中如何填充、读取和清空队列中的数据等。
4.锁(Lock):在多线程环境下,为了防止对同一个资源的并发访问导致的问题,TensorFlow 使用锁来保护共享资源的访问。Session 负责管理这些锁,以确保资源能够正确地被多个线程共享。
5.设备(Device):在 TensorFlow 中,设备是执行计算操作的物理硬件资源,如 CPU、GPU 等。Session 负责将操作分配到不同的设备上执行,以最大化硬件资源的利用率。
6.内存(Memory):Session 负责管理计算图的内存使用情况,包括内存的申请、释放、回收等操作,以确保系统内存资源的有效利用。
正因为Session管理者这么多的资源,所以在使用完后,需要确保 Session 被安全地关闭,以便完全的释放资源。
可以通过Close()进行资源的关闭
sess = tf.Session()
sess.run(targets)
sess.close()
在使用中,我们常常通过上下文管理器创建 Session,使得 Session 在计算完成后,能够自动 关闭,确保资源安全性地被释放。
with tf.Session() as sess:
sess.run(targets)
2. Session的运行方式
在执行Session运算时,我们通常都是创建Session并进行运行,如上述的两种方式。
但有时进行op运算和tensor求值时,并没有指定运行在哪个Session中,那么其是如何运行的?
当我们未指定运行的Session时,都是使用默认的Session运行的。
例如以下两种运行方式:
operation.run()
operation.run()等价于tf.get_default_session().run(operation)
@tf_export("Operation")
class Operation(object):
# 通过operation.run()调用,进行operation计算
def run(self, feed_dict=None, session=None):
_run_using_default_session(self, feed_dict, self.graph, session)
def _run_using_default_session(operation, feed_dict, graph, session=None):
# 没有指定session,则获取默认session
if session is None:
session = get_default_session()
# 最终还是通过session.run()进行运行的。tf中任何运算,都是通过session来run的。
# 通过session来建立client和master的连接,并将graph发送给master,master再进行执行
session.run(operation, feed_dict)
tensor.eval()
tensor.eval()等价于tf.get_default_session().run(tensor), 如下
@tf_export("Tensor")
class Tensor(_TensorLike):
# 通过tensor.eval()调用,进行tensor运算
def eval(self, feed_dict=None, session=None):
return _eval_using_default_session(self, feed_dict, self.graph, session)
def _eval_using_default_session(tensors, feed_dict, graph, session=None):
# 如果没有指定session,则获取默认session
if session is None:
session = get_default_session()
return session.run(tensors, feed_dict)
我们也可以将当前的Session设置为默认Session,默认Session管理是采用栈来进行管理的。这样我们可以创建多个Session依次设置为默认Session,后续可以依次弹出退回到当前的Session。
3. Session的类型与生命周期
前端Session的类型
一般地,存在两种基本的会话类型:Session 与 InteractiveSession。后者常常用于交
互式环境,它在构造期间将其自身置为默认,简化默认会话的管理过程
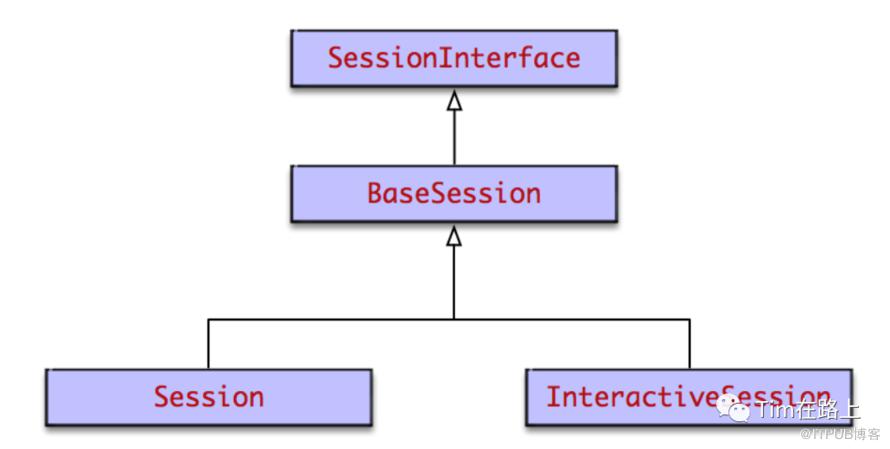
InteractiveSession和Session基本相同,区别在于
InteractiveSession创建后,会将自己替换为默认session。使得之后operation.run()和tensor.eval()的执行通过这个默认session来进行。特别适合Python交互式环境。
InteractiveSession自带with上下文管理器。它在创建时和关闭时会调用上下文管理器的enter和exit方法,从而进行资源的申请和释放,避免内存泄漏问题。这同样很适合Python交互式环境。
InteractiveSession和Session的核心实现都在父类BaseSession中。
后端Session的类型
在后端master中,根据前端client调用tf.Session(target=’’, graph=None, config=None)时指定的target,来创建不同的Session。target为要连接的tf后端执行引擎,默认为空字符串。Session创建采用了抽象工厂模式,如果为空字符串,则创建本地DirectSession,如果以grpc://开头,则创建分布式GrpcSession。
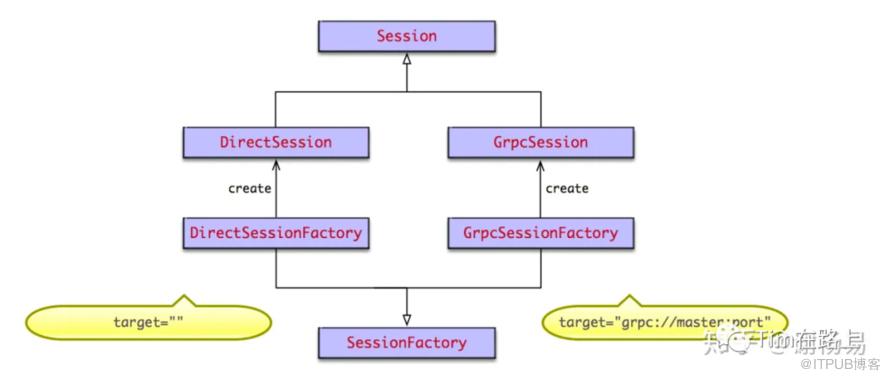
DirectSession只能利用本地设备,将任务创建到本地的CPU GPU上。而GrpcSession则可以利用远端分布式设备,将任务创建到其他机器的CPU GPU上,然后通过grpc协议进行通信。
Session的生命周期
Session 作为 TensorFlow 前后端之间的连接桥梁,不仅是上下文运行环境,而且其生命周期也至关重要。通常情况下,Session 的生命周期可以划分为四个阶段。
首先,在创建阶段,我们通过调用 tf.Session() 来创建一个 Session 实例,系统会进行资源分配,尤其是 Graph 引用计数加 1,表示有一个新的 Session 实例与该 Graph 相关联。
其次,在运行阶段,我们通过调用 session.run() 方法来触发计算图的执行,client 会将整个计算图传递给 master 进行执行。在执行过程中,Session 还会利用计算设备的并行性,将各个计算节点分配到不同的设备上执行,从而加速模型训练和推理的速度。
再次,在关闭阶段,我们可以通过调用 session.close() 来关闭 Session,系统会对资源进行回收,尤其是 Graph 引用计数减 1,表示该 Session 与该 Graph 的关联已经解除。
最后,在销毁阶段,Python 垃圾回收器会自动调用 session.__del__() 方法,进行回收。此时,Session 的生命周期也就结束了。
需要注意的是,Session 的生命周期方法入口基本都在前端 Python 的 BaseSession 中,它会通过 swig 自动生成的函数符号映射关系,调用 C 层的实现。因此,我们需要认真管理 Session 的生命周期,以确保模型的正确性和运行效率。
下面我们将重点分析下Session的创建与运行的过程。
4. Session的创建源码分析
当我们在前端执行Session.run()时,不论那种方式其核心实现都在BaseSession中,下面我们来分析下BaseSession的创建与初始化过程都做了些什么?
# 以下代码经过筛减
class BaseSession(SessionInterface):
def __init__(self, target='', graph=None, config=None):
# 统计Session创建的次数,用于记录日志性能分析等
_python_session_create_counter.get_cell().increase_by(1)
# [1]. 如果graph参数是空的就获取默认图, 如果设置了目标设备就设置
if graph is None:
self._graph = ops.get_default_graph()
else:
self._graph = graph
if target is not None:
try:
self._target = compat.as_bytes(target)
except TypeError:
else:
self._target = None
self._delete_lock = threading.Lock()
self._dead_handles = []
# [2] 判断当前是否开启了混合精度,如果开启,且之前没有开启过,直接将pb文件中的混合精度设置为打开
if (mixed_precision_global_state.is_mixed_precision_graph_rewrite_enabled()
and config.graph_options.rewrite_options.auto_mixed_precision !=
rewriter_config_pb2.RewriterConfig.OFF):
new_config.graph_options.rewrite_options.auto_mixed_precision = (
rewriter_config_pb2.RewriterConfig.ON)
config = new_config
self._session = None
opts = tf_session.TF_NewSessionOptions(target=self._target, config=config)
try:
# [3] 通过调用TF_NewSessionRef创建Session
# pylint: disable=protected-access
self._session = tf_session.TF_NewSessionRef(self._graph._c_graph, opts)
# pylint: enable=protected-access
finally:
tf_session.TF_DeleteSessionOptions(opts)
从上面的代码可知,在BaseSession的初始化中注意做了以下三个事情:
[1] 如果graph参数是空的就获取默认图, 如果没有设置目标设备为None;这里的target参数用于指定Session运行的设备,例如可以通过tf.Session(target='gpu:0')指定运行设备。
[2] 判断当前是否开启了混合精度。如果配置为开启,且之前没有开启过,直接将pb文件中的混合精度设置为打开,否则设置为关闭。通过设置pb文件中的值,方便传递到后端。
[3] 通过调用TF_NewSessionRef创建Session
可见,BaseSession先进行成员变量的赋值,然后调用TF_NewSession来创建session。下面我们看下TF_NewSessionRef是如何执行的。
TF_NewSessionRef()方法由swig自动生成,在bazel-bin/tensorflow/python/pywrap_tensorflow.py中。后面我们再详细介绍分布式框架中Python如何调用C++的。
而TF_NewSessionRef实际上调用c_api.h的TF_NewSession的实现来创建的Session。
下面我们看下c_api.h中TF_NewSession是如何实现的。
TF_Session::TF_Session(tensorflow::Session* s, TF_Graph* g)
: session(s), graph(g), last_num_graph_nodes(0), extend_before_run(true) {}
TF_Session* TF_NewSession(TF_Graph* graph, const TF_SessionOptions* opt,
TF_Status* status) {
Session* session;
// [1] 通过NewSession创建Session
status->status = NewSession(opt->options, &session);
if (status->status.ok()) {
// [2] 将Session封装为结构体进行返回
TF_Session* new_session = new TF_Session(session, graph);
if (graph != nullptr) {
mutex_lock l(graph->mu);
graph->sessions[new_session] = "";
}
return new_session;
} else {
LOG(ERROR) << status->status;
DCHECK_EQ(nullptr, session);
return nullptr;
}
}
上面的代码主要做了以下几件事:
[1] 通过NewSession创建Session;
[2] 将Session封装为结构体进行返回。
其中NewSession的实现是工厂策略模板的实现,它的父类SessionFactory有提供NewSession负责定制化的创建Session, AcceptsOptions方法则表示为要执行此工厂的条件。
class SessionFactory {
public:
virtual Status NewSession(const SessionOptions& options,
Session** out_session) = 0;
virtual bool AcceptsOptions(const SessionOptions& options) = 0;
}
virtual ~SessionFactory() {}
static void Register(const string& runtime_type, SessionFactory* factory);
static Status GetFactory(const SessionOptions& options,
SessionFactory** out_factory);
};
由上面的分析可知,Session后端主要有DirectSessionFactory与GrpcSessionFactory,分别在direct_session.cc与grpc_session.cc文件中,表示本地运行模式与分布式运行模式。
class DirectSessionFactory : public SessionFactory {
...
bool AcceptsOptions(const SessionOptions& options) override {
return options.target.empty();
}
}
class GrpcSessionFactory : public SessionFactory {
...
const char* const kSchemePrefix = "grpc://";
bool AcceptsOptions(const SessionOptions& options) override {
return absl::StartsWith(options.target, kSchemePrefix);
}
}
从上面的代码可以看出,区分本地运行与远程运行的方式,主要是session target参数传递来识别的。如果target为空字符串,则创建本地DirectSession。如果以grpc://开头,则创建分布式GrpcSession。
下面我们以DirectSession为例进行更深入的分析:
class DirectSessionFactory : public SessionFactory {
public:
Session* NewSession(const SessionOptions& options) override {
std::vector<Device*> devices;
// job在本地执行
const Status s = DeviceFactory::AddDevices(
options, "/job:localhost/replica:0/task:0", &devices);
if (!s.ok()) {
LOG(ERROR) << s;
return nullptr;
}
DirectSession* session =
new DirectSession(options, new DeviceMgr(devices), this);
{
mutex_lock l(sessions_lock_);
sessions_.push_back(session);
}
return session;
}
可见在DirectSessionFactory的NewSession主要添加了本地的设备,同时调用了DirectSession来创建Session。
5. Session的运行源码分析
通过session.run()可以启动graph的执行。入口在BaseSession的run()方法中。下面我们来分析下:
class BaseSession(SessionInterface):
def run(self, fetches, feed_dict=None, options=None, run_metadata=None):
# fetches可以为单个变量,或者数组,或者元组。它是图的一部分,可以是操作operation,也可以是数据tensor,或者他们的名字String
# feed_dict为对应placeholder的实际训练数据,它的类型为字典
# [1] 调用内部的_run方法,可以传fetches,feed_dict等参数
result = self._run(None, fetches, feed_dict, options_ptr,run_metadata_ptr)
return result
def _run(self, handle, fetches, feed_dict, options, run_metadata):
# [2] 创建fetch处理器fetch_handler, 得到最终的fetches和targets
fetch_handler = _FetchHandler(
self._graph, fetches, feed_dict_tensor, feed_handles=feed_handles)
# 经过不同类型的fetch_handler处理,得到最终的fetches和targets
# targets为要执行的operation,fetches为要执行的tensor
_ = self._update_with_movers(feed_dict_tensor, feed_map)
final_fetches = fetch_handler.fetches()
final_targets = fetch_handler.targets()
# [3] 通过_do_run开始运行session
if final_fetches or final_targets or (handle and feed_dict_tensor):
results = self._do_run(handle, final_targets, final_fetches,
feed_dict_tensor, options, run_metadata)
else:
results = []
# [4] 输出结果到results中
return fetch_handler.build_results(self, results)
def _do_run(self, handle, target_list, fetch_list, feed_dict, options, run_metadata):
# [3.1] 将要运行的operation添加到graph中
self._extend_graph()
# [3.2] 执行一次运行run,会调用底层C来实现
return tf_session.TF_SessionPRunSetup_wrapper(
session, feed_list, fetch_list, target_list, status)
# 将要运行的operation添加到graph中
def _extend_graph(self):
with self._extend_lock:
if self._graph.version > self._current_version:
# [3.1.1]生成graph_def对象,它是graph的序列化表示
graph_def, self._current_version = self._graph._as_graph_def(
from_version=self._current_version, add_shapes=self._add_shapes)
# [3.1.2] 通过TF_ExtendGraph将序列化后的graph,也就是graph_def传递给后端
with errors.raise_exception_on_not_ok_status() as status:
tf_session.TF_ExtendGraph(self._session,
graph_def.SerializeToString(), status)
self._opened = True
通过上述代码分析可知,其Session运行的主要逻辑如下:
[1] 在运行BaseSession的run方法时,其会调用内部的_run方法,并将fetches,feed_dict等参数传入;
[2] 在_run方法中,首先会创建fetch处理器fetch_handler, 得到最终的fetches和targets,经过不同类型的fetch_handler处理,得到最终的fetches和targets,其分别代码这fetch tensor和target tensor。
[3] 通过调用_do_run方法开始运行session。
[3.1] 通过_extend_graph,将要运行的operation添加到graph中。
[3.1.1]生成graph_def对象,它是graph的序列化表示。
[3.1.2] 通过TF_ExtendGraph将序列化后的graph,也就是graph_def传递给后端。(后面进行分析)
[3.2] 执行一次运行run,会调用底层C来实现,调用TF_SessionRun_wrapper来执行。
[4] 输出结果到results中。
在这里实现TF_ExtendGraph与TF_SessionRun_wrapper都是调用了C api实现,DirectSession和GrpcSession的Run()方法会有所不同。后面我们进行图优化分析时再详细分析其执行过程。
总结
首先,TensorFlow 中 Session 是连接前后端计算的桥梁,它可以将前端的计算图封装为 GraphDef pb 格式发送到后端,后端在通过 GraphDef 将计算图进行重建、剪枝与分裂,以及分配设备,最终将图运行在多个 Executor 上。
其次,Session 还是一个资源管理器,管理着计算图、变量、队列、锁、设备和内存等资源。Session 的类型有两种,分别是 Session 和 InteractiveSession,后端根据前端调用时指定的 target 来创建不同类型的 Session。Session 的生命周期包括四个阶段:创建、运行、关闭和销毁,我们需要认真管理 Session 的生命周期,以确保模型的正确性和运行效率。
再次,TF Session 在初始化时,会先进行成员变量的赋值,然后通过调用TF_NewSession创建Session,其中TF_NewSession是C API, 其有两种实现分别是DirectSessionFactory与GrpcSessionFactory,他们是通过session target参数传递来识别的。在本地运行模式中,Session的初始化最终会new 一个DirectSession对象;
最后,TF Session在运行时,首先创建fetch处理器获取最终的fetches和targets,然后调用_do_run方法开始运行session。在真正的运行前,会先在_extend_graph方法中,会将要运行的operation或tensor添加到graph中,通过 C API TF_ExtendGraph将序列化后的graph传递给后端;最后在_do_run方法中,调用底层C API的TF_SessionRun_wrapper来实现Session的真正运行。