为什么人们如此热衷听ChatGPT一本正经地胡说八道?不是它聪明到不犯错,而是它聪明到犯的错误跟人特别像,这种人性一面若隐若现地显露,令我们相信通用人工智能的奇点即将推门进来。
ChatGPT的爆火,不仅仅是模型的更新升级,它表示着人工智能大模型时代到来。大模型=大数据+大算力+强算法,它更要求模型的训练框架有着更强的并发与数据处理能力。
搜推广场景的特点
随着推荐系统的发展,推荐模型的规模与复杂度也在快速增长,具体表现在:
训练数据:训练样本从到百亿增长到千亿,增长了近10倍。
稀疏参数:个数从几百到几千,也增长了近10倍;总参数量(也就是tf.Variable)从几亿增长到百亿,增长了10~20倍。
模型复杂度:越来越复杂,模型单步计算时间增长10倍以上。对于大流量业务,一次训练实验,从几个小时增长到了几天。
为了提升模型训练的速度,可以增加计算资源来缩短训练时间,于是出现了分布式大模型训练。通过分布式的大模型框架可以优化模型的训练时间,进一步提升模型训练的Batch Size,进而提升模型的训练效果。
如图1所示,在CTR大模型中,其参数主要分为模型稀疏部分(Sparse参数)和模型稠密部分(Dense参数)两部分。
Sparse参数:参数量级很大,一般在亿级别,甚至十亿/百亿级别,这会导致存储空间占用较大,通常在百G级别,甚至T级别。其特点:①单机加载困难:在单机模式下,Sparse参数需全部加载到机器内存中,导致内存严重吃紧,影响稳定性和迭代效率;②读取稀疏:每次推理计算,只需读取部分参数,比如User全量参数在2亿级别,但每次推理请求只需读取1个User参数。
Dense参数:参数规模不大,模型全连接一般在2~3层,参数量级在百万/千万级别。特点:① 单机可加载:Dense参数占用在几十兆左右,单机内存可正常加载,比如:输入层为2000,全连接层为[1024, 512, 256],总参数为:2000 * 1024 + 1024 * 512 + 512 * 256 + 256 = 2703616,共270万个参数,内存占用在百兆内;② 全量读取:每次推理计算,需要读取全量参数。
因此,解决大模型参数规模增长的关键是将Sparse参数由单机存储改造为分布式存储,改造的方式包括两部分:① 模型网络结构转换;② Sparse参数导出。
对于传统模型训练引擎,例如Tensorflow,在大规模稀疏特征训练的场景中,问题越来越突出。主要表现在横向扩展、性能、定制化功能上,具体如下:
所有参数都是用Variable表达, 对于百亿以上的稀疏参数开辟了大量的内存,造成了资源的浪费;
只支持百级别Worker的分布式扩展,对上千Worker的扩展性较差;
由于不支持大规模稀疏参数动态添加、删除,增量导出,导致无法支持Online Learning;
大规模集群运行时,会遇到慢机和宕机;由于框架层不能处理,导会致任务运行异常。
那么如何解决这些问题呢?针对上述的问题,各个大厂的训练框架进行很多相关优化,目前总结下来,核心的两点,一个在于分布式通信拓扑的设计,还有一个在于Embedding Lookup的性能优化。
针对搜广推场景这种海量样本及大规模稀疏参数(sparse embeddings)的场景,业界也有其解决方案,就是采用CPU/GPU 参数服务器训练框架(PS)。可以参考下李沐大神的这篇文章《Parameter Server for Distributed Machine Learning》。
参数服务器架构
我们首先简单介绍下参数服务器(Paramter Server)架构,PS最早由Alex Smola于2010年在parallel topic models中提出,而后李沐在容错和弹性方面对参数服务器进行相关改进。
简单来说,参数服务器有ps和worker两个角色,ps负责参数的存储,聚合和更新。worker负责从server上pull最新的模型参数,并利用部分训练数据进行模型的forward和backward的计算得到梯度并push回server。
针对Tensorflow在大规模稀疏特征训练的场景中的问题,参数服务器架构是如何解决的呢?
原生的TensorFlow中构建Embedding模块,用户需要首先创建一个足够装得下所有稀疏参数的Variable,然后在这个Variable上进行Embedding的学习。然而,使用Variable来进行Embedding训练存在很多弊端:
Variable的大小必须提前设定好,对于百亿千亿的场景,该设定会带来巨大的空间浪费;
训练速度慢,无法针对稀疏模型进行定制优化。
在参数服务器架构中,可以将Sparse参数存储在PS的HashTable中。使用HashTable来替代Variable,将稀疏特征ID作为Key,Embedding向量作为Value。相比原生使用Variable进行Embedding的方式,具备以下的优势:
HashTable的大小可以在训练过程中自动伸缩,避免了开辟冗余的存储空间,同时用户无需关注申请大小,从而降低了使用成本。
针对HashTable方案的优化,训练速度相比Variable会有很大的提高,可以进行千亿规模模型的训练,扩展性较好,类似于Redis。
基于稀疏参数的动态伸缩,可以在此基础上支持Online Learning
此外,针对宕机的问题,可以通过实现断点续训来解决。
在分布式大模型框架的训练中,首先可以根据参数服务器(PS)是否放到本地,可以分为远程参数服务器(Remote PS)架构与本地参数服务器(Local PS)架构。其次,可以根据worker的下一次forward是否需要等到所有其他worker的梯度完成聚合更新获取到最新的模型参数,可以分为异步(Aynschronous Parallel),同步(Synchronous Parallel)和半同步(Stale Synchonrouse Parallel)的训练策略。
下面我们来了解下不同参数服务器实现的方案。
远程CPU异步参数服务器架构
在这种架构模式中,包含CPU Ps节点和CPU Worker节点。
PS 节点中心化存储模型Embedding&&Dense参数,可支持TB级稀疏特征存取。
Worker节点为CPU机器,负责从CFS/HDFS拉取训练数据,从PS节点pull模型参数训练,将参数Grad push异步到ps节点。
可以看出这种模式中,Sparse参数训练时通过自定义PS参数服务器进行训练,Dense参数可以通过Tensorflow原生PS进行训练。
在这里的异步是指,一个worker在完成backward得到梯度以后就push到PS上进行模型参数的更新,然后pull最新的参数开始下一轮迭代,而不需要等待其他worker完成该轮次梯度的计算和push。
优势:
无需等待worker完成该轮梯度计算和push就直接进行下一轮计算,其性能会优于同步模式。
劣势:
Dense模型变得复杂,CPU算力遇到瓶颈
随着训练规模变大,模型训练Staleness问题显著。
异步更新或者半同步更新并没有理论上的收敛性证明,存在影响模型训练精度的问题。
适用于Ctr Dense模型较轻的情境,如MLP,WDL,MMoe etc。
远程GPU半同步参数服务器架构
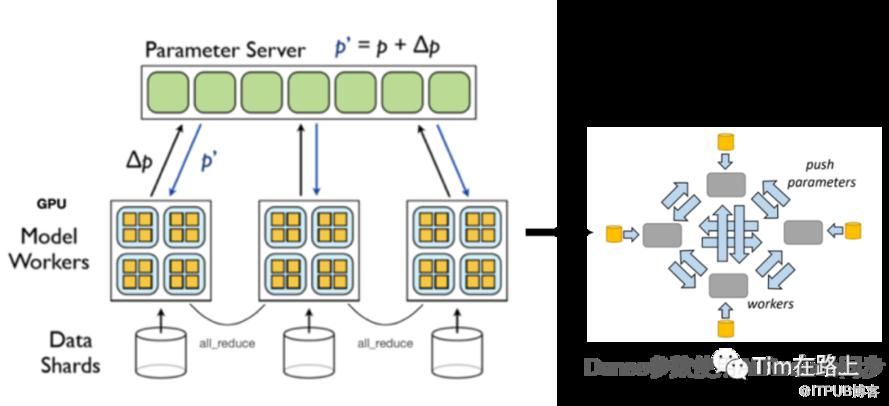
此模式中,包含CPU Ps节点和GPU Worker节点。
Worker节点为GPU机器,每个Worker机器保存模型Dense的副本,训练过程包括:从HDFS拉取训练数据,从Ps节点Pull模型Embedding参数,Dense参数通过Nccl进行AllReduce同步更新,Embedding Grad则Push回Ps节点。
PS 接收到Worker端的Emb Grad,并依次更新Emb参数。
可以看出这种模式中,Sparse参数训练时通过自定义PS参数服务器进行训练,Dense参数通过Nccl的AllReduce进行同步更新。
Dense参数通过GPU间的Allreduce更新,解决了CPU集群稳定性差,计算不均衡带来性能效果不稳定的问题,同时也提升了Dense的可训能力。
针对SparseNet部分( 低IO pressure, 但高memory consumption),DenseNet部分 (高IO pressure,但低memory consumption)的特点,对sparsenet进行异步更新(因为Embedding Lookuptable的更新是稀疏的,冲突概率低),DenseNet采用同步更新的方式尽量逼近同步训练的效果。
优势:
既能解决大Embedding存储、训练问题,又能利用GPU算力加速模型训练。
劣势:
半同步更新并没有理论上的收敛性证明,存在影响模型训练精度的问题。
适用于Ctr Dense模型较重的场景,如 Transformer+MMoe。
远程GPU全同步参数服务器架构
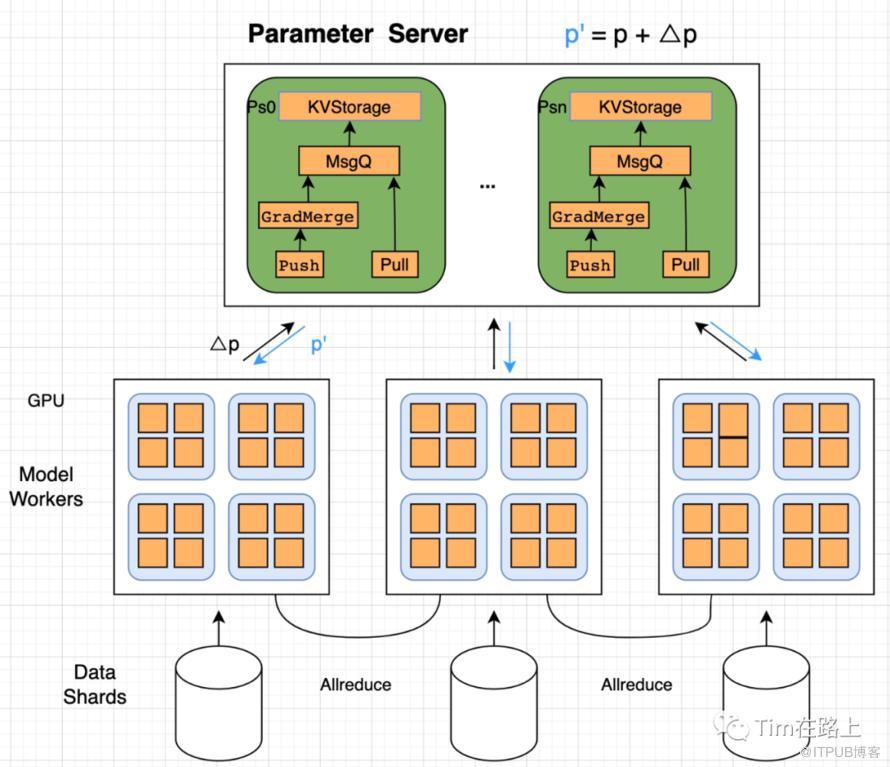
此模式为GPU-Ps 全同步方式,和TF同步方式完全对齐。
Worker节点为GPU机器,每个Worker节点保存模型Dense的副本,训练过程包括:
Worker端
从HDFS拉取训练数据,从Ps节点Pull模型Embedding参数、模型Forward计算loss、 模型Backward计算参数Grad。
Ps端
每个Ps收集来自各个Worker的Emb参数UpdateGrad请求,Grad更新到Emb参数上去。
更新结束,向Worker返回状态码,并开始下一轮的训练。
这里的通信方式和半同步基本一致,唯一的不同是,Sparse参数在进行push到自定义PS时,需要先进行GradMerge操作。
这里的同步更新指的是,下一次迭代需要等到所有worker完成backward,并将梯度push到PS,并由PS完成所有梯度的聚合并进行模型参数的更新,然后再pull最新的模型参数进行下一轮的迭代。
优势:
全同步的训练方式和TF的同步方式完全对齐,精度可以保障。
劣势:
由于是全同步的训练,其性能会大打折扣。在分布式模型训练中存在水桶效应,即训练的性能依赖于性能最差的节点。
GPU本地多级参数服务器架构
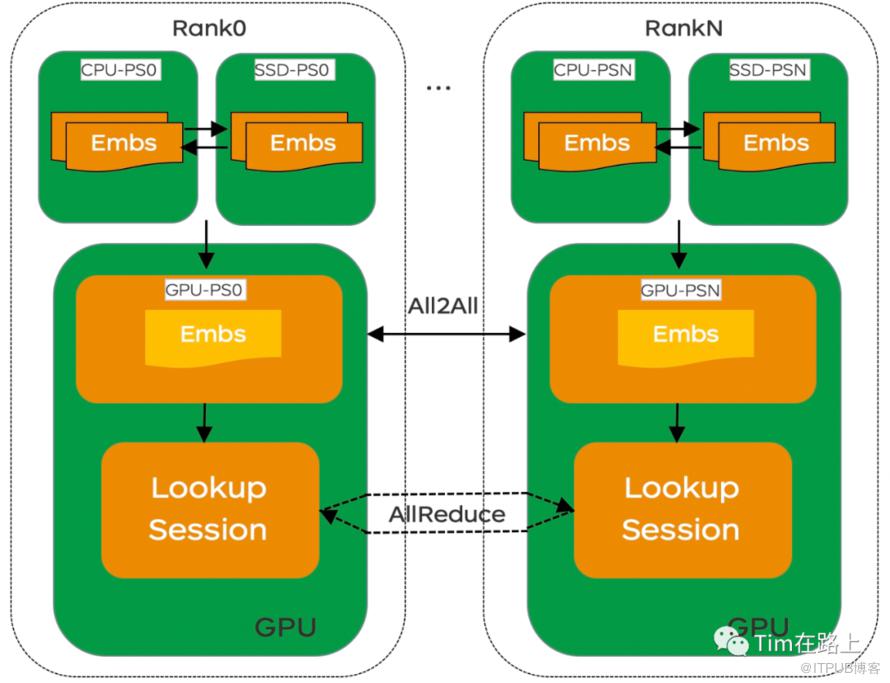
此模式中,仅包含GPU Worker节点,将PS角色放置在Worker内部,属于全GPU的训练模式,这种模式利用率,利用了Nviadia A100等新硬件在资源与性能上的提升。
训练过程为:
Worker端
在训练中Dense参数通过Allreduce进行同步通信,Sparse参数通过AlltoAll进行同步通信。为了能容纳大量的Sparse参数,一般采用多级PS的结构,如上图所示,存在GPU-ps, CPU-ps和SSD-ps等。
优势:
参数服务器设计,避免了RemotePs网络IO,序列化反序列化的开销。
全GPU 计算&&通信模式,充分利用Nvlink, GDR高速带宽,以及GPU高强算力。
全同步模式,避免异步训练梯度延迟更新问题,避免精度问题。
劣势:
硬件成本高昂:需要多个GPU加速器、高速网络设备和参数服务器等硬件组成,硬件成本较高。