Spark Web UI是直观地展示运行状况、资源状态等监控数据的前端,而MetricsSystem就负责收集、存储和输出度量指标。
private[spark] class MetricsSystem private (
val instance: String,
conf: SparkConf,
securityMgr: SecurityManager)
extends Logging {
MetricsSystem类有三个主构造方法参数,分别是:
instance,表示该度量系统对应的实例名称,可取的值如"driver"、"executor"、"master"、"worker"、"applications"、"*"(表示默认实例)等。
conf,即SparkConf配置项。
securityMgr,即安全性管理器SecurityManager的实例。
度量系统中的概念
private[this] valmetricsConfig= new MetricsConfig(conf)
private valsinks= new mutable.ArrayBuffer[Sink]
private valsources= new mutable.ArrayBuffer[Source]
private valregistry= new MetricRegistry()
private varrunning: Boolean = false
// Treat MetricsServlet as a special sink as it should be exposed to add handlers to web ui
private varmetricsServlet: Option[MetricsServlet] = None
metricsConfig:度量系统的配置,它是MetricsConfig类的实例,MetricsConfig类提供了设置和加载度量配置的基础功能。
sources:度量来源的缓存数组。所谓度量来源,就是产生及收集监控指标的组件,都继承自Source特征。
sinks:度量目的地的缓存数组。所谓度量目的地,就是输出及表现监控指标的组件,都继承自Sink特征。
registry:度量注册中心,是com.codahale.metrics.MetricRegistry类的实例,Source和Sink都是通过它注册到度量仓库的。这里“度量仓库”并不是Spark内部的东西,而是Codahale提供的度量组件Metrics,Spark以它为基础来构建度量系统。
running:表示当前MetricsSystem是否在运行。
metricsServlet:本质上是一个特殊的Sink,专门供Spark Web UI使用。
注册度量来源
def registerSource(source: Source) {
sources += source
try {
val regName = buildRegistryName(source)
registry.register(regName, source.metricRegistry)
} catch {
case e: IllegalArgumentException => logInfo("Metrics already registered", e)
}
}
private[spark] def buildRegistryName(source: Source): String = {
val metricsNamespace = conf.get(METRICS_NAMESPACE).orElse(conf.getOption("spark.app.id"))
val executorId = conf.getOption("spark.executor.id")
val defaultName = MetricRegistry.name(source.sourceName)
if (instance == "driver" || instance == "executor") {
if (metricsNamespace.isDefined && executorId.isDefined) {
MetricRegistry.name(metricsNamespace.get, executorId.get, source.sourceName)
} else {
if (metricsNamespace.isEmpty) {
logWarning(s"Using default name $defaultName for source because neither " +
s"${METRICS_NAMESPACE.key} nor spark.app.id is set.")
}
if (executorId.isEmpty) {
logWarning(s"Using default name $defaultName for source because spark.executor.id is " +
s"not set.")
}
defaultName
}
} else { defaultName }
}
registerSource()方法首先将度量来源加入缓存数组,调用buildRegistryName()方法来构造Source的注册名称,然后调用MetricRegistry.register()方法注册到度量仓库。Source的注册名称取决于度量的命名空间(由spark.metrics.namespace参数控制,默认值为Application ID),以及Executor ID。其默认注册名称则由MetricRegistry.name()方法来生成。
private def registerSources() {
val instConfig = metricsConfig.getInstance(instance)
val sourceConfigs = metricsConfig.subProperties(instConfig, MetricsSystem.SOURCE_REGEX)
sourceConfigs.foreach { kv =>
val classPath = kv._2.getProperty("class")
try {
val source = Utils.classForName(classPath).newInstance()
registerSource(source.asInstanceOf[Source])
} catch {
case e: Exception => logError("Source class " + classPath + " cannot be instantiated", e)
}
}
}
先调用MetricsConfig.getInstance()方法取得实例名称下的配置,然后用MetricsConfig.subProperties()方法,根据正则表达式^source\.(.+)\.(.+)匹配出该实例所有与Source相关的参数,返回类型为HashMap[String, Properties]。最后,根据配置的class属性,利用反射构造出Source实现类的对象实例,调用代码#13.3中的方法将Source注册到度量仓库。
注册度量目的地
MetricsSystem并没有提供注册单个度量目的地的方法,而只提供了registerSinks()方法在初始化时批量注册度量目的地。
private def registerSinks() {
val instConfig = metricsConfig.getInstance(instance)
val sinkConfigs = metricsConfig.subProperties(instConfig, MetricsSystem.SINK_REGEX)
sinkConfigs.foreach { kv =>
val classPath = kv._2.getProperty("class")
if (null != classPath) {
try {
val sink = Utils.classForName(classPath)
.getConstructor(classOf[Properties], classOf[MetricRegistry], classOf[SecurityManager])
.newInstance(kv._2, registry, securityMgr)
if (kv._1 == "servlet") {
metricsServlet = Some(sink.asInstanceOf[MetricsServlet])
} else {
sinks += sink.asInstanceOf[Sink]
}
} catch {
case e: Exception =>
logError("Sink class " + classPath + " cannot be instantiated")
throw e
}
}
}
}
它前半部分的处理方式与registerSources()方法一致,不过是改用了正则表达式^sink\.(.+)\.(.+)匹配出该实例所有与Sink相关的参数而已。然后同样利用反射构造出Sink实现类的对象实例,如果度量实例名称为servlet,说明是Web UI使用的那个Sink,将它赋值给metricsServlet属性。否则,就将其加入sinks缓存数组。在MetricsSystem初始化的最后,会调用Sink.start()方法分别启动每个Sink。
度量配置MetricsConfig类
def initialize() {
setDefaultProperties(properties)
loadPropertiesFromFile(conf.getOption("spark.metrics.conf"))
val prefix = "spark.metrics.conf."
conf.getAll.foreach {
case (k, v) if k.startsWith(prefix) =>
properties.setProperty(k.substring(prefix.length()), v)
case _ =>
}
perInstanceSubProperties = subProperties(properties, INSTANCE_REGEX)
if (perInstanceSubProperties.contains(DEFAULT_PREFIX)) {
val defaultSubProperties = perInstanceSubProperties(DEFAULT_PREFIX).asScala
for ((instance, prop) <- perInstanceSubProperties if (instance != DEFAULT_PREFIX);
(k, v) <- defaultSubProperties if (prop.get(k) == null)) {
prop.put(k, v)
}
}
}
初始化的流程是:首先调用setDefaultProperties()方法设置默认配置,调用loadPropertiesFromFile()方法从文件中加载配置。然后,在SparkConf中查找以"spark.metrics.conf."字符串为前缀的配置项,将其键的后缀和值加入度量系统的配置。最后,调用subProperties()方法,通过正则匹配分拆出各个度量实例的配置,并保存在perInstanceSubProperties属性(其数据类型为HashMap[String, Properties])中。
private def setDefaultProperties(prop: Properties) {
prop.setProperty("*.sink.servlet.class", "org.apache.spark.metrics.sink.MetricsServlet")
prop.setProperty("*.sink.servlet.path", "/metrics/json")
prop.setProperty("master.sink.servlet.path", "/metrics/master/json")
prop.setProperty("applications.sink.servlet.path", "/metrics/applications/json")
}
Source 类的实现与示例
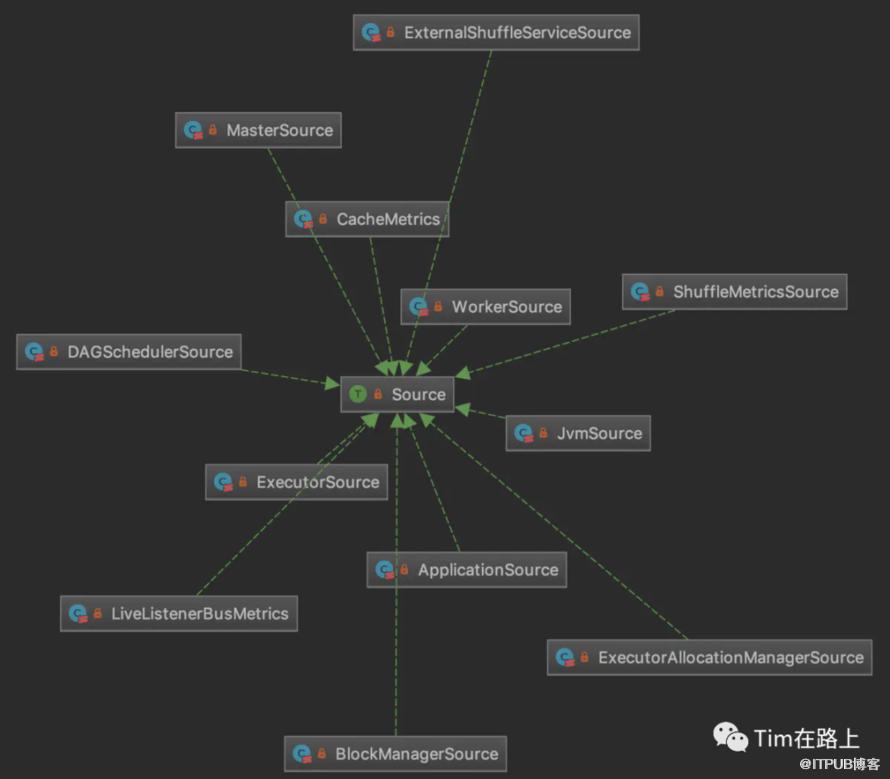
想要通过Source实现注册,可以继承Source, 并进行注册。现在我们看下ExecutorSource是如何实现的。
private[spark]
class ExecutorSource(threadPool: ThreadPoolExecutor, executorId: String) extends Source {
override val metricRegistry = new MetricRegistry()
override val sourceName = "executor"
private def registerFileSystemStat[T](
scheme: String, name: String, f: FileSystem.Statistics => T, defaultValue: T) = {
metricRegistry.register(MetricRegistry.name("filesystem", scheme, name), new Gauge[T] {
override def getValue: T = fileStats(scheme).map(f).getOrElse(defaultValue)
})
}
metricRegistry.register(MetricRegistry.name("threadpool", "activeTasks"), new Gauge[Int] {
override def getValue: Int = threadPool.getActiveCount()
})
metricRegistry.register(MetricRegistry.name("threadpool", "completeTasks"), new Gauge[Long] {
override def getValue: Long = threadPool.getCompletedTaskCount()
})
metricRegistry.register(MetricRegistry.name("threadpool", "currentPool_size"), new Gauge[Int] {
override def getValue: Int = threadPool.getPoolSize()
})
metricRegistry.register(MetricRegistry.name("threadpool", "maxPool_size"), new Gauge[Int] {
override def getValue: Int = threadPool.getMaximumPoolSize()
})
for (scheme <- Array("hdfs", "file")) {
registerFileSystemStat(scheme, "read_bytes", _.getBytesRead(), 0L)
registerFileSystemStat(scheme, "write_bytes", _.getBytesWritten(), 0L)
registerFileSystemStat(scheme, "read_ops", _.getReadOps(), 0)
registerFileSystemStat(scheme, "largeRead_ops", _.getLargeReadOps(), 0)
registerFileSystemStat(scheme, "write_ops", _.getWriteOps(), 0)
}
val METRIC_CPU_TIME = metricRegistry.counter(MetricRegistry.name("cpuTime"))
val METRIC_RUN_TIME = metricRegistry.counter(MetricRegistry.name("runTime"))
val METRIC_JVM_GC_TIME = metricRegistry.counter(MetricRegistry.name("jvmGCTime"))
// ......
}
由此可见,ExecutorSource向注册中心中注册了很多指标,包括与线程池(threadpool)相关的Gauge、与文件系统(filesystem)相关的Gauge(Gauge是Metrics体系内提供的估计度量值的工具),以及大量的计数器,如GC、Shuffle、序列化方面的计数值。这些指标覆盖了整个Executor运行期的方方面面,看官也可以寻找其他Source的实现来进一步参考。
最终在Executor中通过env.metricsSystem.registerSource(*executorSource*) 注册source。
executorSource.METRIC_CPU_TIME.inc(task.metrics.executorCpuTime)
executorSource.METRIC_RUN_TIME.inc(task.metrics.executorRunTime)
executorSource.METRIC_JVM_GC_TIME.inc(task.metrics.jvmGCTime)
executorSource.METRIC_DESERIALIZE_TIME.inc(task.metrics.executorDeserializeTime)
executorSource.METRIC_DESERIALIZE_CPU_TIME.inc(task.metrics.executorDeserializeCpuTime)
executorSource.METRIC_RESULT_SERIALIZE_TIME.inc(task.metrics.resultSerializationTime)
executorSource.METRIC_SHUFFLE_FETCH_WAIT_TIME
.inc(task.metrics.shuffleReadMetrics.fetchWaitTime)
executorSource.METRIC_SHUFFLE_WRITE_TIME.inc(task.metrics.shuffleWriteMetrics.writeTime)
在Executor中更新统计值。
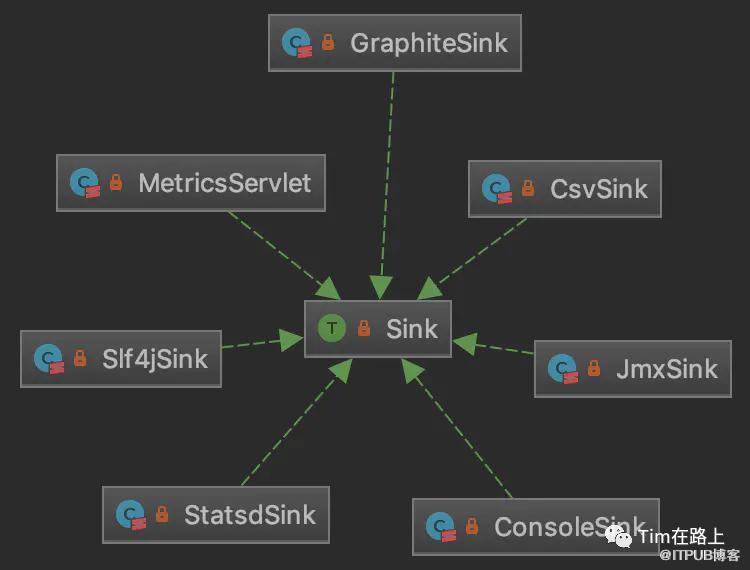
Sink实现类与示例
ink也是一个非常简单的特征,其中定义了3个方法:start()/stop()方法分别用来启动和停止Sink,report()方法用于输出度量值。
private[spark] class JmxSink(val property: Properties, val registry: MetricRegistry,
securityMgr: SecurityManager) extends Sink {
valreporter: JmxReporter = JmxReporter.forRegistry(registry).build()
override def start() {
reporter.start()
}
override def stop() {
reporter.stop()
}
override def report() { }
}
其中有些名称是可以顾名思义的,比如ConsoleSink输出到控制台,CsvSink输出到CSV文件,Slf4jSink输出到符合SLF4J规范的日志。另外,JmxSink可以将监控数据输出到JMX中,从而通过JVM可视化工具(如VisualVM)进行观察。MetricsServlet在前面已经说过,它可以利用Spark UI内置的Jetty服务将监控数据输出到浏览器页面。
本文首先介绍了Spark度量系统的概念,通过阅读MetricsSystem类的相关源码,明确了度量系统是如果运作及发挥作用的。然后对度量配置MetricsConfig做了简单了解,最后简述了度量来源Source及目的地Sink的实现方式。由于度量和监控在Spark各主要功能模块中都是不可或缺的,因此今后在深入阅读Spark Core的其他源码时,我们会非常频繁地见到度量系统相关的方法调用。