Spark是一个分布式的大数据计算引擎。随着生态的发展,现在已经变成一个通用的计算框架,其集成了SQL查询,图处理,机器学习,流处理等。
随着各种计算引擎的发展,所有的引擎非常重视SQL的支持,SparkSQL也是Spark生态最重要的一部分。
Spark强调的是基于内存的计算,所以Spark更适用于性能好的服务器上运行。Spark的架构上,可以归为lambda架构,实现流批的一体(Spark的流处理实质依然是微批)。
Spark是分布式并发程序,实现了资源管理,任务分配,结果收集等功能。
Spark架构
说起Spark的架构,需要先明白Spark实现的几种方式:local模式,standalone模式,cluster模式(基于资源管理器的方式,资源管理器有yarn,mesos,k8s等)。
仅谈论Spark的构成,包括Cluster Manager集群资源管理器,负责维护资源的管理和分配,目前包括 Spark 原生的 Cluster Manager、Mesos Cluster Manager 和 Hadoop YARN Cluster Manager。Worker Node任务的工作节点,负责分区任务的执行。Driver 任务的控制节点,负责资源申请,任务监控与分配。从中可以看出,Spark属于Master/slave模式。
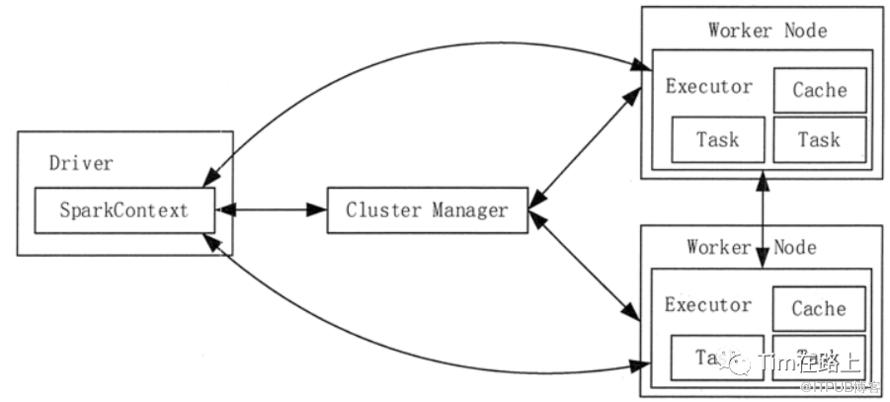
在Spark的Driver节点中,主要运行我们提交的程序,程序的入口就是SparkContext。Driver节点会加载Spark的执行环境SparkEnv, 统计Spark执行过程信息,向Cluster Manager 申请Task需要的资源节点等。
Driver在执行提交的程序时,会根据Action算子提交Job。一个Action算子提交一个Job,并将其交给DAGScheduler, DAGScheduler在submitJob时会从后向前根据血缘关系遍历,如果一个RDD是ShuffleRDD, 会将其前后分为两个Stage。之后,会将TaskSets提交给TaskScheduler, 并封装为TaskManager。最后在Worker节点上启动Executor进程,并将Task分发给Worker节点执行。
程序的提交执行,为一个Application, 其会通过Driver节点向Cluster Manager申请资源,然后在Worker节点启动一批Executor。每一个Executor是一个进程,其只服务于当前申请的Application。一个Worker节点上会存在多个Application申请的Executor进程,它们之间资源是相互隔离的。当分区Task(执行逻辑)分发到当前Worker的Executor上,则会在其上启动一个线程进行执行Task任务。Executor中包含一个blockManager,由于迭代计算会产生很多中间结果,可以将其存储在这个模块中,减少io操作,提高性能。
参考:http://c.biancheng.net/view/3651.html
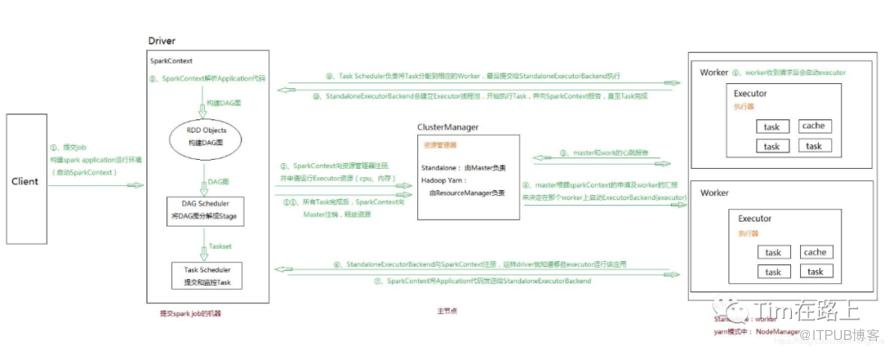
1、通过SparkSubmit提交job后,Client就开始构建 spark context,即 application 的运行环境(使用本地的Client类的main函数来创建spark context并初始化它)
2、yarn client提交任务,Driver在客户端本地运行;yarn cluster提交任务的时候,Driver是运行在集群上
3、SparkContext连接到ClusterManager(Master),向资源管理器注册并申请运行Executor的资源(内核和内存)
4、Master根据SparkContext提出的申请,根据worker的心跳报告,来决定到底在那个worker上启动executor
5、Worker节点收到请求后会启动executor
6、executor向SparkContext注册,这样driver就知道哪些executor运行该应用
7、SparkContext将Application代码发送给executor(如果是standalone模式就是StandaloneExecutorBackend)
8、同时SparkContext解析Application代码,构建DAG图,提交给DAGScheduler进行分解成stage,stage被发送到TaskScheduler。
9、TaskScheduler负责将Task分配到相应的worker上,最后提交给executor执行
10、executor会建立Executor线程池,开始执行Task,并向SparkContext汇报,直到所有的task执行完成
11、所有Task完成后,SparkContext向Master注销
Spark on Yarn
yarn是Hadoop2 的资源管理,任务调度的框架。主要包含三大模块:ResourceManager(RM)、
NodeManager(NM)、ApplicationMaster(AM)。
yarn的运行流程如下所示:
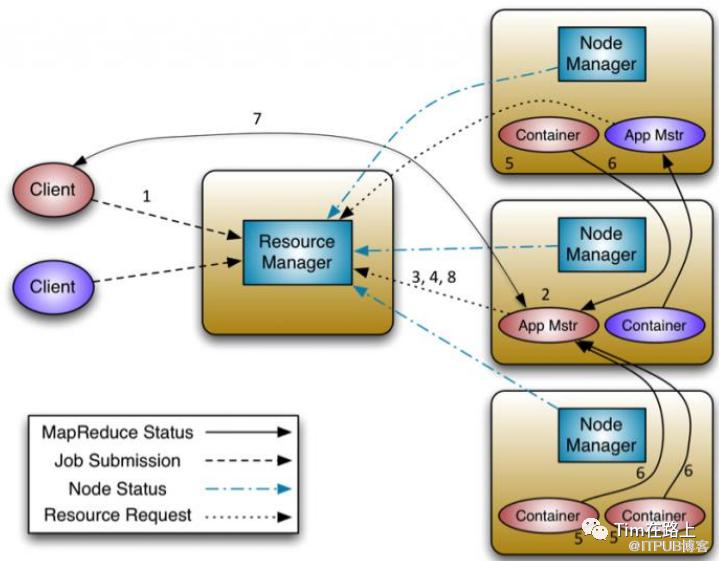
client 向 RM 提交应用程序,其中包括启动该应用的 ApplicationMaster 的必须信息,例如
ApplicationMaster 程序、启动 ApplicationMaster 的命令、用户程序等。ResourceManager 启动一个 container 用于运行 ApplicationMaster。
启动中的ApplicationMaster向ResourceManager注册自己,启动成功后与RM保持心跳。
ApplicationMaster 向 ResourceManager 发送请求,申请相应数目的 container。
ResourceManager 返回 ApplicationMaster 的申请的 containers 信息。申请成功的
container,由 ApplicationMaster 进行初始化。container 的启动信息初始化后,AM 与对
应的 NodeManager 通信,要求 NM 启动 container。AM 与 NM 保持心跳,从而对 NM 上
运行的任务进行监控和管理。container 运行期间,ApplicationMaster 对 container 进行监控。container 通过 RPC 协议
向对应的 AM 汇报自己的进度和状态等信息。应用运行期间,client 直接与 AM 通信获取应用的状态、进度更新等信息。
应用运行结束后,ApplicationMaster 向 ResourceManager 注销自己,并允许属于它的
container 被收回。
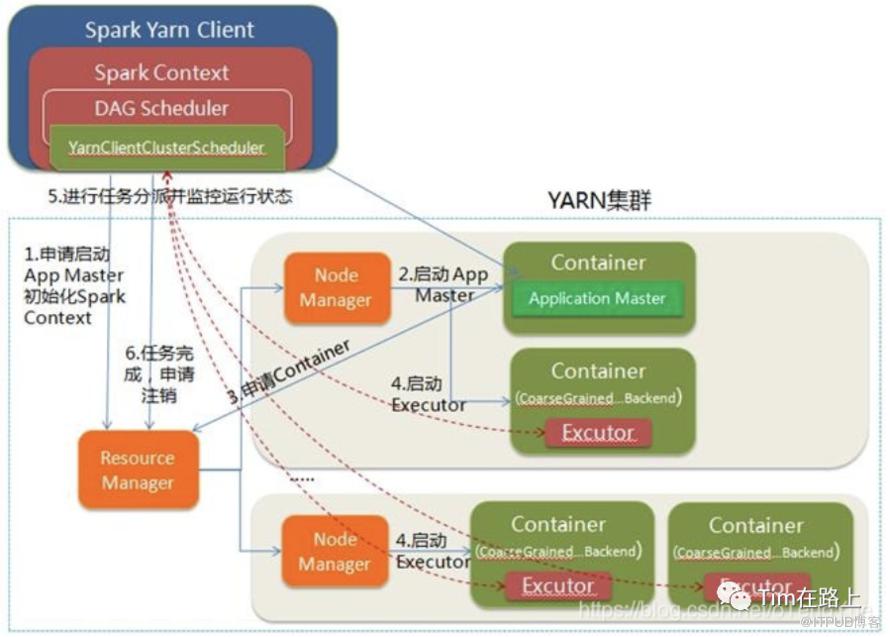
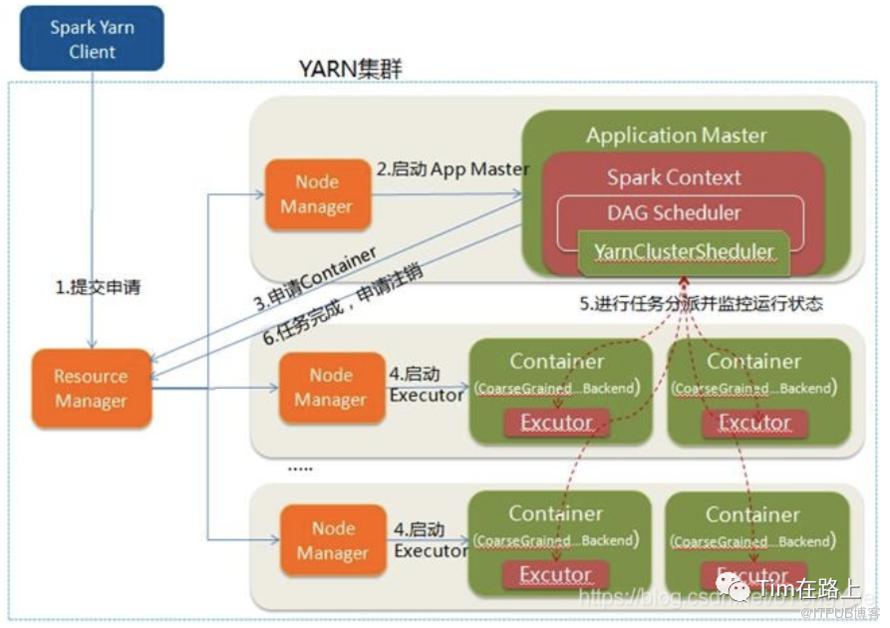
Spark on yarn, 有两种模式,一种是client模式,一种是cluster模式。
cluster模式,driver节点和AM节点在同时在集群中的一个随机节点中,client只负责提交程序即可,所以不能创建shell,但这样的好处是可以根据集群资源的情况选取性能好的节点做driver。client模式,中client负责driver的处理(DagScheduler, TaskScheduler), AM在集群中的随机一个节点, driver节点则就是client节点,可以创建shell。
参考:https://www.cnblogs.com/skaarl/p/13960639.html
Spark运行特点:
每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行Task。这种Application隔离机制是有优势的,无论是从调度角度看(每个Driver调度它自己的任务),还是从运行角度看(来自不同Application的Task运行在不同JVM中),当然这样意味着Spark Application不能跨应用程序共享数据,除非将数据写入外部存储系统
Spark与资源管理器无关,只要能够获取Executor进程,并能保持互相通信就可以了
提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息互换
Task采用了数据本地性和推测执行的优化机制
Spark抽象出分布式内存存储结构弹性分布式数据集RDD,进行数据的存储。RDD能支持粗粒度写操作,但对于读取操作,RDD可以精确到每条记录,这使得RDD可以用来作为分布式索引
Spark的特性是能够控制数据在不同节点上的分区,用户可以自定义分区策略,如Hash分区等。Spark SQL在Spark的基础上实现了列存储和列存储压缩。Spark采用了事件驱动的nettyRpc来启动任务,通过线程池复用线程来避免进程或线程启动和切换开销。
参考:https://www.cnblogs.com/Mayny/p/9330436.html
总结
Spark 实际是分布式的计算引擎,主要思想将数据拆分为多个分区,将计算进行拆分为小的计算单元(拆分的原则是1.需要回收结果或完成计算,2.是否需要shuffle过程),通过分布式计算提高执行效率。在Driver节点将计算拆分为一个个Task集, 将其分发到Worder节点(靠近数据),加载数据,执行逻辑。