Spark定义了RDD间的依赖关系,使用类进行表示:
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
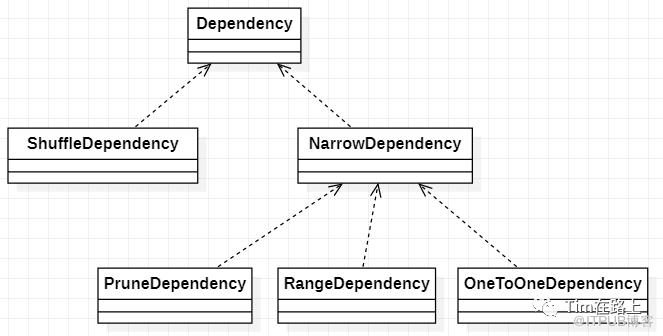
Dependency有两个子类,包括窄依赖NarrowDependency, 宽依赖ShuffleDependency。NarrowDependency又包括PruneDependency,RangeDependency,OneToOneDependency。
NarrowDependency
NarrowDependency指的是子RDD的每个分区都依赖于少量父RDD的分区。窄依赖允许pipleline执行。窄依赖的实现分为三种:
一对一依赖(OneToOneDependency):【1-to-1的依赖】,指父RDD和子RDD分区之间是一对一的依赖关系且父RDD与子RDD的分区数量相同,如map、filter等常见算子。
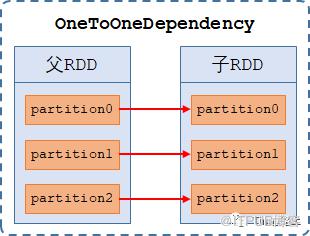
范围依赖(RangeDependency):【n-to-1的依赖】,指父RDD和子RDD之间属于某个范围的依赖关系(当2个父RDD拼接成一个子RDD时,子RDD的分区分别依赖于父RDD0的所有分区、父RDD1的所有分区)且子RDD的分区数量=所有父RDD的分区数之和,仅被UnionRDD使用,如union算子。
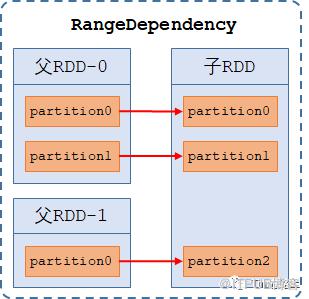
剪枝依赖(PruneDependency):【1-to-部分 的依赖】,指子RDD仅依赖部分父RDD的分区,是一种数据过滤优化,仅被PartitionPruningRDD使用。
ShuffleDependency
Shuffle依赖(ShuffleDependency):【n-to-n的依赖】,指子RDD的每一个分区都依赖父RDD的多个分区或全部分区,仅K-V类型的RDD才会使用宽依赖,如reduce、groupBy、reduceByKey等算子。
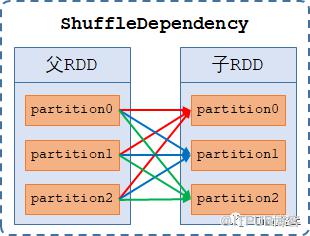
分区器 HashPartitioner AND RangePartitioner
Spark RDD的宽依赖中存在Shuffle过程,Spark的Shuffle过程同MapReduce,也依赖于Partitioner数据分区器。主要是HashPartitioner和RangePartitioner两个类,分别用于根据RDD中key的hashcode值进行分区以及根据范围进行数据分区。
HashPartitioner
Spark中非常重要的一个分区器,也是默认分区器,默认用于90%以上的RDD相关API上;
功能:依据RDD中key值的hashCode的值将数据取模后得到该key值对应的下一个RDD的分区id值,支持key值为null的情况,当key为null的时候,返回0;该分区器基本上适合所有RDD数据类型的数据进行分区操作;
但是需要注意的是,由于JAVA中数组的hashCode是基于数组对象本身的,不是基于数组内容的,所以如果RDD的key是数组类型,那么可能导致数据内容一致的数据key没法分配到同一个RDD分区中,这个时候最好自定义数据分区器,采用数组内容进行分区或者将数组的内容转换为集合。
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
// 如果是负数 mod + numPartitions 转为正数
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
RangePartitioner
SparkCore中除了HashPartitioner分区器外,另外一个比较重要的已经实现的分区器,主要用于RDD的数据排序相关API中,比如sortByKey,sortby、orderby底层使用的数据分区器就是RangePartitioner分区器;
该分区器的实现方式主要是通过两个步骤来实现的:
第一步:先重整个RDD中抽取出样本数据,将样本数据排序,计算出每个分区的最大key值,形成一个Array[KEY]类型的数组变量rangeBounds;
第二步:判断key在rangeBounds中所处的范围,给出该key值在下一个RDD中的分区id下标;
该分区器要求RDD中的KEY类型必须是可以排序的,它能保证各个Partition之间的Key是有序的,并且各个Partition之间数据量差不多,但是不保证单个Partition内Key的有。
class RangePartitioner[K: Ordering : ClassTag, V](
partitions: Int,
rdd: RDD[_ <: Product2[K, V]],
private var ascending: Boolean = true)
extends Partitioner {
// We allow partitions = 0, which happens when sorting an empty RDD under the default settings.
require(partitions >= 0, s"Number of partitions cannot be negative but found $partitions.")
// 获取RDD中key类型数据的排序器
private var ordering = implicitly[Ordering[K]]
// An array of upper bounds for the first (partitions - 1) partitions
private var rangeBounds: Array[K] = {
if (partitions <= 1) {
// 如果给定的分区数是一个的情况下,直接返回一个空的集合,表示数据不进行分区
Array.empty
} else {
// This is the sample size we need to have roughly balanced output partitions, capped at 1M.
// 给定总的数据抽样大小,最多1M的数据量(10^6),最少20倍的RDD分区数量,也就是每个RDD分区至少抽取20条数据
val sampleSize = math.min(20.0 * partitions, 1e6)
// Assume the input partitions are roughly balanced and over-sample a little bit.
// 计算每个分区抽取的数据量大小, 假设输入数据每个分区分布的比较均匀
// 对于超大数据集(分区数超过5万的)乘以3会让数据稍微增大一点,对于分区数低于5万的数据集,每个分区抽取数据量为60条也不算多
val sampleSizePerPartition = math.ceil(3.0 * sampleSize / rdd.partitions.size).toInt
// 从rdd中抽取数据,返回值:(总rdd数据量, Array[分区id,当前分区的数据量,当前分区抽取的数据])
val (numItems, sketched) = RangePartitioner.sketch(rdd.map(_._1), sampleSizePerPartition)
if (numItems == 0L) {
// 如果总的数据量为0(RDD为空),那么直接返回一个空的数组
Array.empty
} else {
// If a partition contains much more than the average number of items, we re-sample from it
// to ensure that enough items are collected from that partition.
// 计算总样本数量和总记录数的占比,占比最大为1.0
val fraction = math.min(sampleSize / math.max(numItems, 1L), 1.0)
// 保存样本数据的集合buffer
val candidates = ArrayBuffer.empty[(K, Float)]
// 保存数据分布不均衡的分区id(数据量超过fraction比率的分区)
val imbalancedPartitions = mutable.Set.empty[Int]
// 计算抽取出来的样本数据
sketched.foreach { case (idx, n, sample) =>
if (fraction * n > sampleSizePerPartition) {
// 如果fraction乘以当前分区中的数据量大于之前计算的每个分区的抽象数据大小,那么表示当前分区抽取的数据太少了,该分区数据分布不均衡,需要重新抽取
imbalancedPartitions += idx
} else {
// 当前分区不属于数据分布不均衡的分区,计算占比权重,并添加到candidates集合中
// The weight is 1 over the sampling probability.
val weight = (n.toDouble / sample.size).toFloat
for (key <- sample) {
candidates += ((key, weight))
}
}
}
// 对于数据分布不均衡的RDD分区,重新进行数据抽样
if (imbalancedPartitions.nonEmpty) {
// Re-sample imbalanced partitions with the desired sampling probability.
// 获取数据分布不均衡的RDD分区,并构成RDD
val imbalanced = new PartitionPruningRDD(rdd.map(_._1), imbalancedPartitions.contains)
// 随机种子
val seed = byteswap32(-rdd.id - 1)
// 利用rdd的sample抽样函数API进行数据抽样
val reSampled = imbalanced.sample(withReplacement = false, fraction, seed).collect()
val weight = (1.0 / fraction).toFloat
candidates ++= reSampled.map(x => (x, weight))
}
// 将最终的抽样数据计算出rangeBounds出来
RangePartitioner.determineBounds(candidates, partitions)
}
}
}
// 下一个RDD的分区数量是rangeBounds数组中元素数量+ 1个
def numPartitions: Int = rangeBounds.length + 1
// 二分查找器,内部使用java中的Arrays类提供的二分查找方法
private var binarySearch: ((Array[K], K) => Int) = CollectionsUtils.makeBinarySearch[K]
// 根据RDD的key值返回对应的分区id。从0开始
def getPartition(key: Any): Int = {
// 强制转换key类型为RDD中原本的数据类型
val k = key.asInstanceOf[K]
var partition = 0
if (rangeBounds.length <= 128) {
// If we have less than 128 partitions naive search
// 如果分区数据小于等于128个,那么直接本地循环寻找当前k所属的分区下标
while (partition < rangeBounds.length && ordering.gt(k, rangeBounds(partition))) {
partition += 1
}
} else {
// Determine which binary search method to use only once.
// 如果分区数量大于128个,那么使用二分查找方法寻找对应k所属的下标;
// 但是如果k在rangeBounds中没有出现,实质上返回的是一个负数(范围)或者是一个超过rangeBounds大小的数(最后一个分区,比所有数据都大)
partition = binarySearch(rangeBounds, k)
// binarySearch either returns the match location or -[insertion point]-1
if (partition < 0) {
partition = -partition - 1
}
if (partition > rangeBounds.length) {
partition = rangeBounds.length
}
}
// 根据数据排序是升序还是降序进行数据的排列,默认为升序
if (ascending) {
partition
} else {
rangeBounds.length - partition
}
}
如果分区数量小于2或者rdd中不存在数据的情况下,直接返回一个空的数组,不需要计算range的边界;如果分区数据大于1的情况下,而且rdd中有数据的情况下,才需要计算数组对象
计算总体的数据抽样大小sampleSize,计算规则是:至少每个分区抽取20个数据或者最多1M的数据量
根据sampleSize和分区数量计算每个分区的数据抽样样本数量sampleSizePrePartition
调用RangePartitioner的sketch函数进行数据抽样,计算出每个分区的样本
计算样本的整体占比以及数据量过多的数据分区,防止数据倾斜
对于数据量比较多的RDD分区调用RDD的sample函数API重新进行数据抽取
将最终的样本数据通过RangePartitoner的determineBounds函数进行数据排序分配,计算出rangeBounds
参考:https://blog.csdn.net/zc19921215/article/details/88673568
举例验证
(1) oneToOne依赖
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("Spark partition")
.getOrCreate()
val rdd = spark.sparkContext.textFile("D:\\a.txt")
println(rdd.partitions.length)
val result = rdd.collect()
println(result.mkString("\n"))
spark.stop()
}
在SparkContext调用textFile读取文件后,根据其rdd.dependencies可以看出rdd的的依赖关系为:
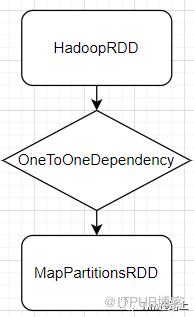
其实可以通过源码发现其转换依赖关系:
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path,classOf[TextInputFormat],classOf[LongWritable],classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
HadoopRDD返回的的数据为<分区key, value>, 首先经过map, 将k-v数据变为仅仅value的数据。
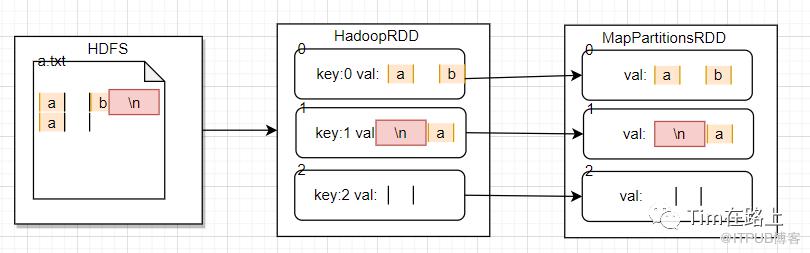
OneToOne依赖的分区特点是,分区中的数据也是一一对应的,下面我们看下数据是如何流转的。
数据文件a.txt的数据内容

从文件中黄色线代表回车,绿色线代表空格。从中可以看出该文件一共7字节(回车符占据2个字符)。
执行rdd.asInstanceOf[MapPartitionsRDD].prev.partitions。
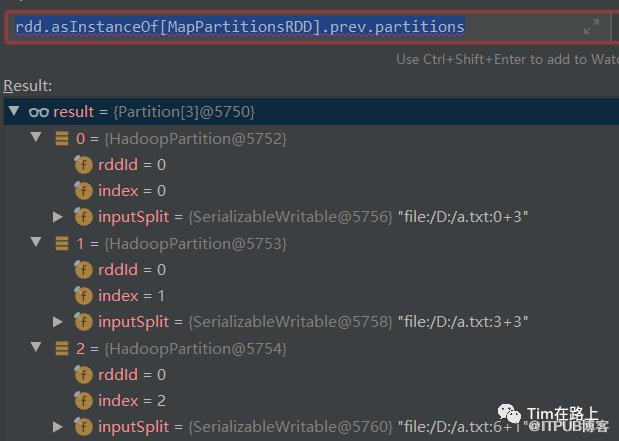
HadoopRDD生成了三个分区分别是<0,3><3,6><6,1>。HadoopRDD的分区策略可以查看Spark RDD中,后面也会详细介绍。
这里再简要提一下:首先我们未设置分区数,默认获取的分区数为2,HadoopRDD会计算读取文件总的bytes为7。globleSize则为7/2=3bytes。
由于我们文件内容很小不超过HDFS 的block的大小(128M)。则按照globleSize作为划分单位,进行划分。7bytes的文件按照3byte进行划分,结果为分为3个分区。如果文件为8byte,则分区大小可以除尽,则为2个分区。
其次,我们再执行rdd.partitions命令查看MapPartitionsRDD分区内容。
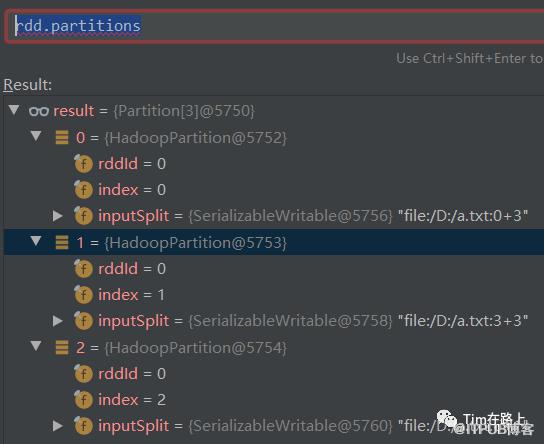
发现分区内容是没有变化,这印证了OneToOne依赖的分区间的数据也是一对一映射的。下面画图解释下:
(2) range依赖
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("Spark partition")
.getOrCreate()
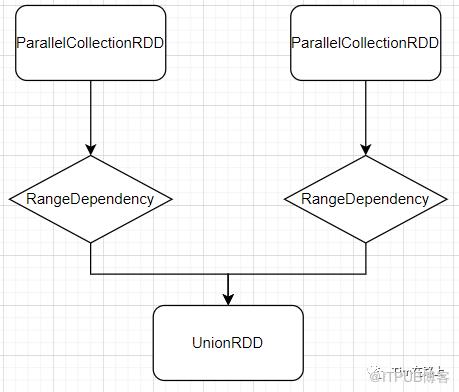
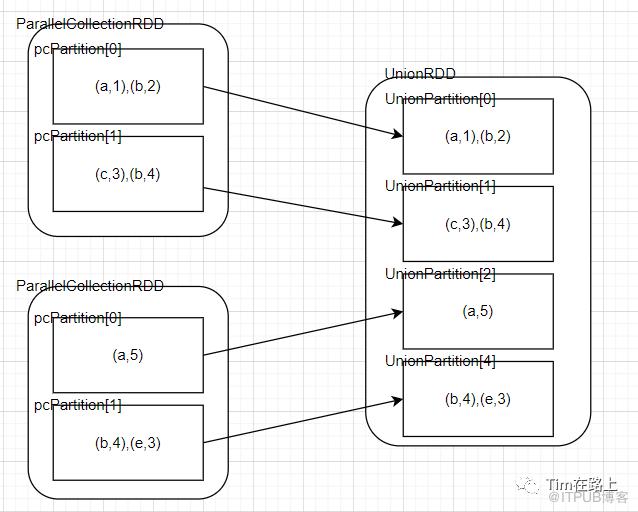
val rdd = spark.sparkContext.parallelize(Seq(("a", 1), ("b", 2), ("c", 3), ("b", 4)), 2)
val rdd1 = spark.sparkContext.parallelize(Seq(("a", 5), ("b", 4), ("e", 3)), 2)
val rdd3 = rdd.union(rdd1)
println(rdd3.collect().mkString("\n"))
spark.stop()
}
分析程序的依赖关系如下所示:
RangeDependency的数据流动关系如下所示:
(3) prune依赖
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("Spark partition")
.getOrCreate()
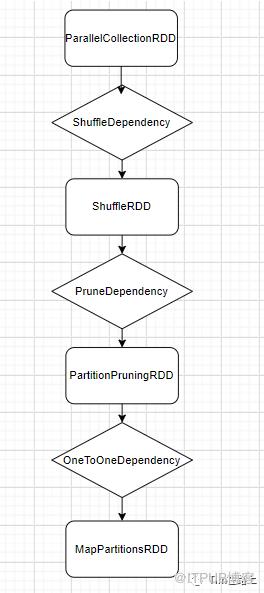
val rdd = spark.sparkContext.parallelize(Seq(("a", 1), ("b", 2), ("c", 3), ("b", 4)), 2)
val rdd2 = rdd.sortByKey()
val rdd3 = rdd2.filterByRange("a", "b")
println(rdd3.collect().mkString("\n"))
spark.stop()
}
分析程序的依赖关系如下所示:
PruneDependency一般用于sort后的算子, 如果没有排序则在使用时也会先进行排序。那么其数据是如何流动的:
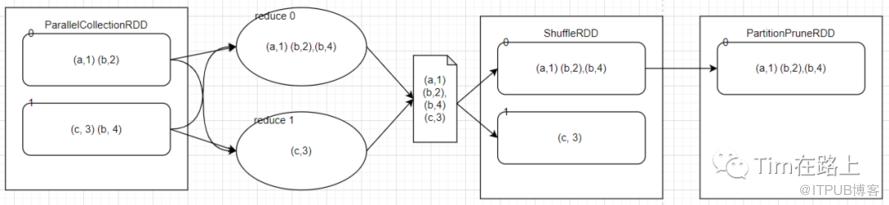
这里再执行SortByKey时会使用RangePartitioner分区器,其原理是超过60行数据的对其先采样,然后再进行排序,对排序结果切分为对应的reduce分区数,这样就找到每一个分区的边界,最后对原数据文件按照边界进行拆分。
欢迎点赞加转发,你们的点赞是我更新的动力!