首先,目前很火的ChatGPT就是使用Ray框架进行训练的,当前Ray最适合的就是强化学习的训练,这也是它的一个显著特色。不过,Ray建立的初衷还是想建立一个通用的轻量级主打python并发框架。
Spark与Ray都师出同门伯克利amplab。虽然Spark是DataBricks公司主打的产品,但其主要是数据并行,如下图所示,并不能很好处理模型并行。随着目前AI的发展,模型数据量的增多,AI并行运算已经成为标配,例如(CTR,NLP大模型预训练等)。
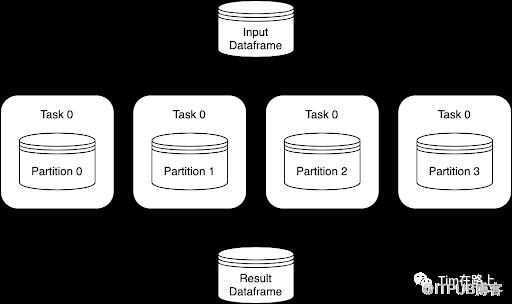
然而在AI计算中,逻辑操作非常复杂,简单的数据并行(即在不同分区上运行相同的函数)并不能解决问题,需要从上到下的模型并行来处理,这也就需要新的框架来占这部分的市场。
Ray 在设计的时候,没有把自己绑定成某一种场景或计算模式的解决方案,它是一个真正的原生的分布式框架。它的设计理念是,在上层抽象出不同的计算模式,包括流、批、图计算、机器学习、深度学习,在下层提供分布式服务,通过它来解决调度问题、容灾问题、资源恢复问题等。
Ray虽然是主要面向机器学习场景,但Ray并没提供具体计算的功能,一般建模(深度学习)中需要结合 TensorFlow或者Pytorch等计算框架使用。对于数据处理Ray可以和Spark更加紧密的结合,Spark的数据输出不需要落盘,就可以直接对接到算法训练框架中,实现真正的端到端训练。
所以说Ray并不会代替Spark,反而是Spark之上的一套框架,可以整合Spark与AI训练。
下面总结下,Ray的优缺点:
优点
最小集群配置
最适合计算繁重的工作负载。已经表明Ray 优于 Spark 和 Dask在某些机器学习任务上,如 NLP、文本规范化等。最重要的是,Ray 的工作速度似乎比 Python 标准多处理快 10%,即使在单个节点上也是如此。
由于越来越多地使用 Ray 来扩展不同的 ML 库,因此您可以以可扩展的并行方式将所有这些库一起使用。另一方面,Spark 将您限制在其生态系统中可用的框架数量大大减少。
独特的基于参与者的抽象,其中多个任务可以异步地在同一个集群上工作,从而提高利用率(相比之下,Spark 的计算模型不太灵活,基于并行任务的同步执行)。
缺点
相对较新(2017 年 5 月首次发布)
并不是真正适合分布式数据处理。Ray 没有用于分区数据的内置原语。刚刚介绍的项目射线数据集, 但这是一个全新的添加,仍然很新而且很简单。
GPU 支持仅限于调度和预订。实际使用 GPU 取决于远程函数(通常通过 TensorFlow 和 PyTorch 等外部库)
Ray的很多功能还不完善,很多宣传中的功能还没达到开箱即用的效果,还在建设中。
总体而言,Ray 更加注重 actor 模型和任务调度、数据传输等方面的高效性和灵活性;Spark 则更加注重分布式数据集和内存计算等方面的高效性和可扩展性。如果任务以数据为中心并且更多地围绕 ETL/预处理,还是注重建设 Spark的。而对于AI模型并行训练,加速 Python 代码运行,强化学习等,可以选择Ray,通过Ray也可以将Spark组织起来,实现端到端的模型训练。