TensorFlow在深度学习领域发挥着重要作用,其强大的功能和高性能得益于其核心组件的精心实现与优化。
本文将深入探索TensorFlow核心组件的实现细节,揭示其背后的底层机制。我们将探讨张量(Tensor)、计算图(Computational Graph)、操作(Operation)、变量(Variable)、会话(Session)和优化器(Optimizer)等组件的工作原理和优化策略。
通过对这些核心组件的深入理解,我们将更好地把握TensorFlow的内部工作原理,从而更高效地构建和训练深度学习模型。让我们一起深入研究TensorFlow核心组件的实现,探索机器学习框架的内部奥秘。
1. Tensor 的定义
张量(Tensor)是TensorFlow框架用于管理整体数据流的重要数据结构。
通过提供统一的数据载体,TensorFlow可更方便地定义数学表达式,更准确地描述数学模型。在实际模型运算中,张量扮演了承载数据的角色。
TensorFlow提供的张量抽象最主要的有两种:Tensor和SparseTensor,分别用于表示Dense数据和Sparse数据。SparseTensor实际上是由三个Tensor组成的,实际上是对Tensor的再封装,它被设计成紧凑的数据结构,用于优化高维稀疏数据的内存占用。
下面我们从Tensor开始,了解TensorFlow的底层机制。
从定义上说,可以将Tensor理解为N维数组,我们习惯上叫:
零阶张量表示为标量(Scalar)
一阶张量表示为向量(Vector)
N阶张量表达N维数组
它们在TF中都可以统称为Tensor。
2. Tensor的优势
在具体实现上,Tensor并不直接存储实际的数据;
其类似于Spark的RDD, 其存储的是张量的元信息以及指向实际数据的内存缓冲区的指针。
在优势上:
一方面可以满足TensorFlow延迟计算的特性,在使用Tensor构建图的过程中并不会真正的计算。
另一方面主要是为了实现内存复用,拒绝内存拷贝带来的时空开销。当某个前置操作的输出值被多个后置操作使用的时候,可以通过指针就行多重引用,无需进行重复存储。
其次,可以通过引用计数的方式进行数据的生命周期的管控。
由TensorFlow是如何运行的?可知,TensorFlow的系统结构以C API为界,将整个系统分为「前端」和「后端」两个子系统:
前端系统:提供编程模型,负责构造计算图;
后端系统:提供运行时环境,负责执行计算图。
下面我们从源码的角度,分别从前后端系统来认识下Tensor的实现。
3. Tensor前端(Python)的定义
我们知道TensorFlow前端系统其主要负责构造计算图,图的定义中包含了边和点的概念,但我们在TF前端的源码中并没有没有找到 Node, Edge 的定义。那它是用什么表示的呢?
事实上,在TF前端 Python 系统中,使用Operation 表示图中的 Node 实例,而 Tensor 表示 图中的 Edge 实例。
下面是具体的TF的python定义Tensor源码:
@tf_export("Tensor")
class Tensor(_TensorLike):
def __init__(self, op, value_index, dtype):
# 源节点,tensor的生产者,会计算得到tensor
self._op = op
# tensor在源节点的输出边集合中的索引。源节点可能会有多条输出边
# 利用op和value_index即可唯一确定tensor。
self._value_index = value_index
# tensor中保存的数据的数据类型
self._dtype = dtypes.as_dtype(dtype)
# tensor的shape,可以得到张量的rank,维度等信息
self._shape_val = tensor_shape.unknown_shape()
# 目标节点列表,tensor的消费者,会使用该tensor来进行计算
self._consumers = []
#
self._handle_data = None
self._id = uid()
从上面的源码中,我们知道在TF的Python端的Tensor中主要包含两类信息:
一个是Graph结构信息,如边的源节点和目标节点,其中源节点是Tensor所连接的上游Op,目标节点则通过消费者_consumers数组进行表示,可以Tensor定义可以看出,其连接关系为一对多;
另一个则是它所保存的数据信息,例如数据类型,shape等。
这是一个典型的生产者-消费者关系,Tensor作为Graph的边,使得不同节点Operation之间建立了连接。上游源节点Operation经过计算得到数据Tensor,然后可以传递给下游多个目标节点。
通过Tensor我们可以建立起Op之间的依赖关系,便于后端反向遍历寻找最小依赖子图,以及对图进行剪枝合并优化。
4. Tensor 后端(c++)的定义
在TensorFlow的后端计算图的定义中,存在Node与Edge的概念,同时还存在Tensor的概念,那他们之前是什么关系呢?
在TensorFlow后端中,边缘(Edge)和张量(Tensor)之间存在着相互调用的关系。边缘(Edge)是连接节点(Node)的连接线,用于传递数据和建立计算依赖关系,而张量(Tensor)则是在边缘上携带数据的载体。
Python前端的Tensor对应的后端数据结构则为边Edge,它持有源节点和目标节点的指针,从而将两个节点连接起来。在了解Tensor定义前,我们先来看下Edge类的定义:
class Edge {
private:
Edge() {}
friend class EdgeSetTest;
friend class Graph;
// 源节点, 边的数据就来源于源节点的计算。源节点是边的生产者
Node* src_;
// 目标节点,边的数据提供给目标节点进行计算。目标节点是边的消费者
Node* dst_;
// 边id,也就是边的标识符
int id_;
// 表示当前边为源节点的第src_output_条边。源节点可能会有多条输出边
int src_output_;
// 表示当前边为目标节点的第dst_input_条边。目标节点可能会有多条输入边。
int dst_input_;
// Return true iff this is an edge that indicates a control-flow
// (as opposed to a data-flow) dependency.
bool IsControlEdge() const;
};
从上面的源码可以看出,Edge定义了源节点,目标节点,源节点的第src_output_条边,前边为目标节点的第dst_input_条边。
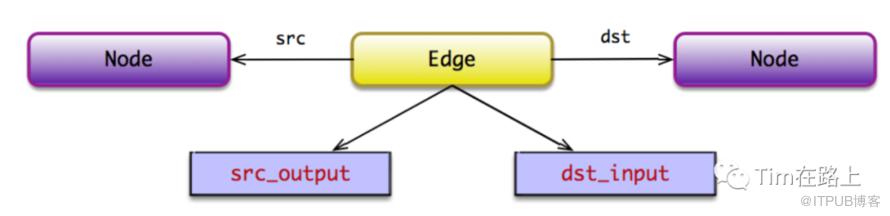
此外在Edge定义中也可以看出,其既可以承载tensor数据,提供给节点Operation进行运算,也可以用来表示节点之间有依赖关系。通过IsControlEdge来判断是否依赖控制边,对于表示节点依赖的边,其src_output_, dst_input_均为-1,此时边不承载任何数据。
一般地,计算图的「普通边」承载 Tensor,并使用 TensorId 标识。Tensor 标识由源节 点的名字,及其所在边的 src_output 唯一确定。
TensorId ::= node_name:src_output
缺省地,src_output 默认为 0;也就是说,node_name 与 node_name:0 两者等价。特殊 地,当 src_output 等于-1 时,表示该边为「控制依赖边」,TensorId 可以标识为 n̂ode_name, 标识该边依赖于 node_name 所在的节点。
下面我们再来看下C++ 中 Tensor是如何定义的:
class Tensor{
public:
// Tensor序列化/反序列化相关
bool FromProto(const TensorProto& other) TF_MUST_USE_RESULT;
void AsProtoField(TensorProto* proto)const;
void AsProtoTensorContent(TensorProto* proto)const;
// Tensor实际为底层数据的一种视图,可用vec或matrix进行展示
template<typename T>typename TTypes::Vec vec() {
return tensor1>();
}
template<typename T>typename TTypes::Matrix matrix() {
return tensor2>();
}
template<typename T, size_t NDIMS>typename TTypes::Tensor tensor();
private:
TensorShape shape_;// 维护Tensor的形状和数据类型
TensorBuffer buf_;// 底层数据的指针
}
首先,TensorBuffer类,它是一个继承引用计数类的虚拟类,不包含任何实现。TensorBuffer类,它是一个继承引用计数类的虚拟类,不包含任何实现。BufferBase继承TensorBuffer类,且维护了一个内存分配器指针。而Buffer类继承BufferBase类,且维护了指向实际数据的指针data_和元素数量elem_。

TensorBuffer的作用是:
数据存储:`TensorBuffer` 提供了一块内存缓冲区,用于存储 `Tensor` 中的数据
数据共享:`TensorBuffer` 通过共享内存缓冲区的方式,可以实现多个 `Tensor` 对象之间的数据共享。
数据传输:`TensorBuffer` 提供了高效的数据传输机制,可以在 `Tensor` 之间进行数据的复制、移动和交换。
其次,TensorShape类,是用于表示张量形状的对象。其中dims():返回一个 std::vector,包含每个维度的大小; num_dimensions():返回张量的维度数量;dim_size(d):返回指定维度的大小,索引从0开始。
可以看出TF后端C++中的Tensor仅仅是维护数据的数据结构,其次其还维护了用于访问和操作张量数据的方法和成员变量。这些方法包括获取张量形状、数据类型以及对张量进行扁平化等操作。
5. 总结
首先,Tensor是TensorFlow框架中用于管理整体数据流的重要数据结构。Tensor可以理解为N维数组,一般用于表示Dense数据。此外,还有另一种叫做SparseTensor,它实际是有三个Tensor组成的用于表示稀疏数据的数据结构。
其次,Tensor的优势之一是它并不直接存储实际的数据,而是存储元信息和指向实际数据的指针。这样可以实现延迟计算和内存复用,避免重复存储和拷贝带来的时空开销。
最后,在TensorFlow前端(Python)中,Tensor表示图中的边,其包含了Graph结构信息,如边的源节点和目标节点,以及保存的数据信息,如数据类型和形状。通过其可以建立Op之间的依赖关系。在TensorFlow后端(C++)中,边缘(Edge)和张量(Tensor)之间存在相互调用的关系,Edge用于连接节点并传递数据和建立计算依赖关系,而Tensor则是在边缘上携带数据的载体。