在深度学习领域中,TensorFlow是一个备受瞩目的开源框架,被广泛应用于构建强大而高效的机器学习模型。然而,对于初学者或初次接触TensorFlow的人来说,理解TensorFlow的运行原理可能是一个具有挑战性的任务。
本文将带您深入探索TensorFlow的运行原理,解释TensorFlow是如何工作的,以及它在背后使用的核心原理和技术。无论是从计算图的构建到模型的执行,还是从变量的管理到分布式训练,我们将揭示TensorFlow的内部机制,让您对这个强大的深度学习框架有更深入的了解。
通过对TensorFlow的内部机制和优化技术的了解,我们可以更好地调试和排查问题,并优化模型的性能和效果。此外,对TensorFlow运行原理的了解还为我们扩展和定制框架提供了基础,使我们能够针对特定需求进行二次开发或优化。
因此,深入了解TensorFlow的运行原理对于我们在深度学习领域的学习、研究和实践具有重要意义。它不仅为我们提供了更深入的理解,还为我们的工作和创新提供了更大的潜力和可能性。
让我们开始这段关于TensorFlow运行原理的探索之旅吧。
1. TensorFlow是什么?优势是什么?
TensorFlow是一个开源的深度学习框架,它的名字即表达了它的初衷,让张量(Tensor)在神经网络里自由的流动(Flow)。
其中的张量其广义上可以表示为任何数据,在TF等深度学习库中,通常用张量来描述多维数组,它表示的是一个数据的容器。在物理实现时,即在TF中Tensor是一个句柄,它存储张量的元信息以及指向张量数据的内存缓冲区指针,并不直接存储数据。用户通过执行操作来创建或计算张量,张量的形状不一定在编译时确定,可以在运行时通过形状推断计算出。
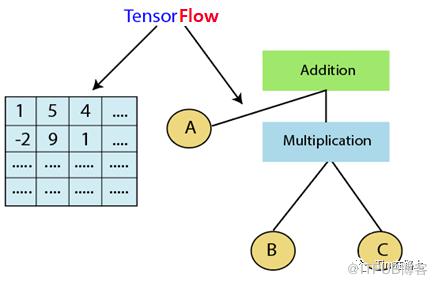
此外,TensorFlow采用了数据流图(data flow graphs),进行数值计算的开源框架。如下图所示,节点(Nodes)在图中表示数学操作,如Addition等,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
那么什么是TensorFlow? 可以一句话总结,TensorFlow = 多维数据数组 + 数据流图。
TensorFlow 的优势:
高度的灵活性。TF不是一个严格的“神经网络”库。你可以按照TF的规范,在TF中实现自己的算子节点与调用接口,通过调用组织成一个数据流图,理论上也可以帮你做算法外的其他事情。
真正的可移植性。TF框架可以运行在多个 CPU 、GPU、TPU 和移动操作系统上。也可以在没有特殊硬件的前提下,在你的笔记本上跑一下机器学习。
性能最优化。TF不仅支持生产数据流图,还支持对数据流图就优化,例如剪枝,常量合并,以及XLA算子融合等,使得即使阿猫阿狗也可以写成高性能模型,此外TF还给予了线程、队列、异步操作等以最佳的支持,可以让你可以将你手边硬件的计算潜能全部发挥出来。
多语言支持。Tensorflow使用c++作为高性能的Core层,支持使用易用的python使用界面来构建和执行你的graphs,此外也在支持或已支持Go,Java,Lua,Javascript,或者是R等多语言。
TensorFlow的核心组件
下面我们通过一段代码来了解下TensorFlow中的核心组件 张量、计算图和会话。
import tensorflow as tf
# 创建一个计算图
graph = tf.Graph()
# 在计算图中定义操作
with graph.as_default():
# 定义输入张量
a = tf.constant(2.0, name="a")
b = tf.constant(3.0, name="a")
# 定义计算操作
c = tf.add(a, b)
# 'Add:0' shape=() dtype=float32>
d = tf.multiply(a, b)
e = tf.pow(c, d)
# 创建一个会话并执行计算图中的操作
with tf.Session(graph=graph) as sess:
result = sess.run(e)
print("Result:", result)
1. 计算图
在TF1.x版本中,编译一个程序一般分两步,一个是构建计算图,一个是执行计算图。如上代码所示,我们创建两个常量Tensor a和b作为数据的输入,并构建一系列的加、乘和幂的操作。最后构建了一个会话,并运行e。此时TF会通过e训练其依赖的操作节点,并将其转换为一个计算图。
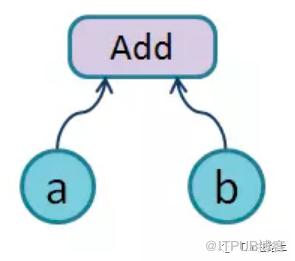
当然这里要注意系统会默认维护一个张量计算图,用户可以创建。如上所示,我们通过tf.Graph()创建了一个计算图,并将其作为默认,不同的计算图之间张量不可共享。
2. 张量
我们要注意张量包括了名字,维度,类型三个属性。张量的名字是张量的唯一标识,通过名字我们也可以发现张量是如何计算出来的,如我们之间打印c, 则显示其名字为'Add:0',表示由Add节点第0个输出。
张量的维度,说明了张量的维度信息,如shape=(2,) 表示2维的张量。
张量的数据累积,如dtype=float32,在张量计算器会对张量的数据类型进行校验,发现不匹配会提前报错。
3. 会话
会话用于管理程序运行时的资源,用于执行定义好的运算。
要启动计算图,首先要创建一个Session对象。使用tf.Session()创建会话,调用run()函数执行计算图。
在交互式环境下(例如IPython),使用设置默认会话的方式来获取张量的取值更加方便,TensorFlow提供了一种在交互式环境下直接构建默认会话的函数:tf.InteractiveSession,该函数会自动将生成的会话注册为默认会话,使用 tf.Tensor.eval()代替 Session.run()。
TensorFlow系统架构
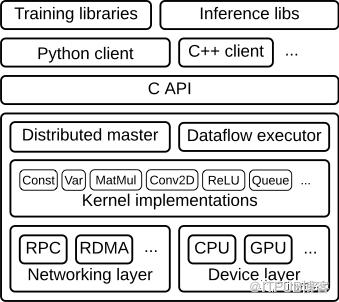
如上图所示,整个框架以C API为界,分为前端和后端两大部分。
1. 前端
提供编程模型,多语言的接口支持,比如Python Java C++等。通过C API建立前后端的连接。
2. 后端
提供运行环境,完成计算图的执行。进一步分为4层
运行时:分为分布式运行时和本地运行时,负责计算图的接收,构造,编排等。
计算层:提供各op算子的内核实现,例如conv2d, relu等
通信层:实现组件间数据通信,基于GRPC和RDMA两种通信方式
设备层:提供多种异构设备的支持,如CPU GPU TPU FPGA等
TensorFlow运行流程
当在TensorFlow中进行模型训练和推断时,通常会遵循以下典型流程:数据准备、构建计算图、运行计算图和更新模型参数。
1. 数据准备
在TensorFlow中,数据通常以张量(Tensor)的形式表示。数据准备的步骤包括加载和预处理数据。下面是一个加载数据的示例:
import tensorflow as tf
# 加载数据
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 预处理数据
train_images = train_images / 255.0
test_images = test_images / 255.0
在这个示例中,我们使用了MNIST数据集作为训练和测试数据。首先,我们使用tf.keras.datasets.mnist.load_data()加载数据集,然后将像素值归一化到0到1之间,以便更好地进行训练。
2. 构建计算图
使用计算图(Graph)来表示模型和计算操作。
# 构建计算图
graph = tf.Graph()
with graph.as_default():
# 定义输入和标签占位符
inputs = tf.placeholder(tf.float32, shape=[None, 784])
labels = tf.placeholder(tf.int64, shape=[None])
# 定义模型
dense = tf.layers.dense(inputs, units=128, activation=tf.nn.relu)
logits = tf.layers.dense(dense, units=10)
在这个示例中,我们首先创建了一个计算图对象graph。然后,使用tf.placeholder定义了输入和标签的占位符。接下来,我们使用tf.layers.dense构建了一个全连接层,然后再次使用tf.layers.dense构建了输出层。
在TF中,我们可以使用张量(Tensor)、变量(Variable)、占位符(Placeholder)和操作(Operation)等。
TensorFlow 1.x 的图是一个静态图,即在图的构建阶段定义好后不可修改。
张量(Tensor):TensorFlow的数据单位是张量,它可以是多维数组。张量可以表示输入数据、模型参数、中间结果等。普通Tensor 的生命周期通常随依赖的计算完成而结束,内存也随即释放。
变量(Variable):特殊的张量,变量用于存储和更新模型的参数。在图的构建阶段,我们使用`tf.Variable`来定义变量。在分布式场景下由各个节点共享。变量常驻内存, 在每一步训练时不断更新其值,以实现模型参数的更新。
占位符(Placeholder):占位符用于表示输入数据的位置,在图的构建阶段,我们使用`tf.placeholder`来定义占位符。
操作(Operation):操作表示计算图中的计算步骤。例如,矩阵乘法、卷积等都是操作。
通过使用这些API,我们可以定义输入数据、模型的结构以及操作的顺序。
在TensorFlow1.0时代,采用的是静态计算图,需要先使用TensorFlow的各种算子创建计算图,然后再开启一个会话Session,显式执行计算图。模型搭建和训练分为两个阶段,由两种语言分别实现编程接口和核心运行时,还涉及到计算图的序列化及跨组件传输。
而在TensorFlow2.0时代,采用的是动态计算图,模型的搭建和训练放在一个过程中,即每使用一个算子后,该算子会被动态加入到隐含的默认计算图中立即执行得到结果,不需要使用Session了,像原始的Python语法一样自然。
3. 定义损失函数和优化器
# 定义损失函数和优化器
labels_placeholder = tf.placeholder(tf.int64, shape=[None])
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels_placeholder, logits=logits))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(loss)
使用tf.nn.sparse_softmax_cross_entropy_with_logits计算交叉熵损失函数,并使用tf.train.GradientDescentOptimizer定义了优化器。接下来,我们使用optimizer.minimize方法来最小化损失函数,并得到一个训练操作train_op。
损失函数和优化器是编译一个神经网络模型必须的两个参数之一。损失函数是指用于计算标签值和预测值之间差异的函数。
4. 运行计算图
# 创建会话并运行训练过程
with tf.Session(graph=graph) as sess:
# 初始化变量
sess.run(tf.global_variables_initializer())
# 迭代训练
for epoch in range(num_epochs):
# 执行训练操作
feed_dict = {inputs: train_images, labels_placeholder: train_labels}
_, current_loss = sess.run([train_op, loss], feed_dict=feed_dict)
# 打印当前损失
print("Epoch:", epoch, "Loss:", current_loss)
我们使用tf.Session创建了一个会话对象sess,并将之前创建的计算图graph传递给会话。然后,我们通过调用sess.run来运行计算图,并将输入数据通过feed_dict传递给占位符。
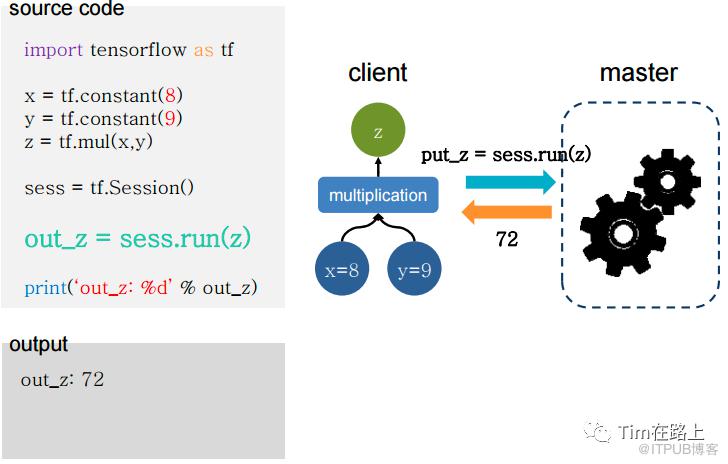
通过Session运行的客户端,通过Session发送计算任务到其连接的执行引擎(进程内引擎)完成执行。
TensorFlow执行流程
TensorFlow的一个重要特点是图的构造和执行相分离。在TensorFlow中,用户首先通过编程接口添加算子,构建整个计算图。然后,在图的执行阶段,用户可以执行训练和推断操作。整体流程如下:
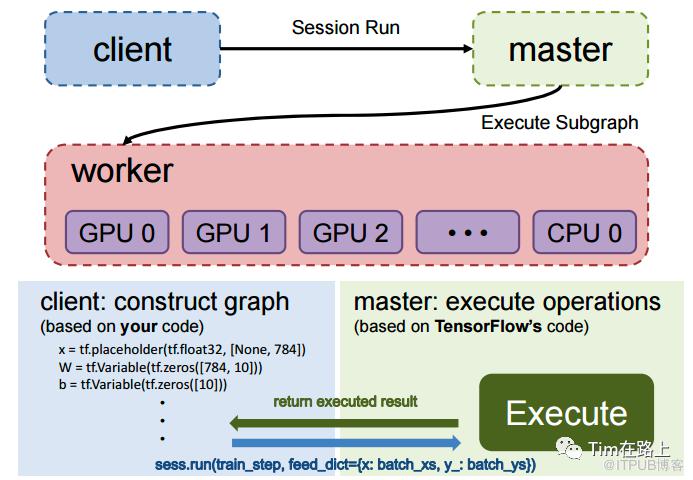
图的构造阶段:
在客户端(client)中,用户使用TensorFlow的多语言编程接口,通过添加算子来构造计算图。这些算子表示了数据流动和操作之间的依赖关系。图的传递阶段:
客户端开启会话(session),通过会话与主节点(master)建立连接。当调用`session.run()`方法时,构造好的图会被序列化为GraphDef的protobuf格式,并传递给主节点。图的剪枝阶段:
主节点根据`session.run()`方法传递的fetches和feeds列表,从整个图中进行反向遍历,实施剪枝操作,得到最小依赖子图。图的分裂阶段:
主节点将最小子图分裂为多个图分区(Graph Partition),并将它们注册到多个工作节点(worker)上。每个工作节点负责执行一个图分区。图的二次分裂阶段:
每个工作节点根据可用的硬件资源(如CPU、GPU),将图分区按照设备约束规范(例如`tf.device('/cpu:0')`)进行二次分裂,使得每个计算设备对应一个图分区。图的运行阶段:
对于每个计算设备,工作节点根据操作(op)在内核中的实现,完成相应的计算。设备间的数据通信可以使用send/recv节点,而工作节点之间的通信通常使用GRPC或RDMA协议进行。
通过以上流程,TensorFlow实现了图的构造和图的执行相分离的机制,使得用户可以灵活地构建和执行计算图,并利用分布式计算和设备加速等特性提高计算效率。
总结
TensorFlow是一个强大的深度学习框架,其运行原理涉及图的构建和图的执行两个关键步骤。在图的构建阶段,用户使用TensorFlow的API定义计算图的结构和操作的依赖关系。通过张量、变量、占位符和操作等元素的组合,构建出完整的计算图。
在图的执行阶段,用户创建会话(Session)来执行计算图。会话提供了执行环境和资源管理。通过调用session.run()方法,TensorFlow自动根据计算图的依赖关系进行操作的执行。在执行过程中,TensorFlow会进行自动的优化和并行化操作,以提高计算效率。
TensorFlow的图执行模型具有以下特点:
延迟执行:TensorFlow采用的是延迟执行模型,即图的执行在真正需要获取结果时才触发。这种机制允许用户在构建图时灵活添加、修改和组合操作。
自动优化:TensorFlow会根据计算图的结构和操作之间的依赖关系进行自动优化。这包括常量折叠、公共子图消除、运算融合等优化手段,以提高计算效率。
并行计算:TensorFlow可以自动将独立的操作并行执行,以充分利用多核CPU和GPU等硬件资源。这样可以加速模型的训练和推断过程。
分布式计算:TensorFlow支持分布式计算,可以将计算任务分布到多个设备和多台机器上进行并行计算,提升整体性能和可扩展性。
总结起来,TensorFlow通过图的构建和图的执行相分离的设计,实现了灵活高效的深度学习模型训练和推断。用户可以通过API定义计算图,TensorFlow自动优化和并行化计算,以提供快速的计算速度。同时,TensorFlow支持分布式计算和自定义操作的扩展性,使其成为广泛应用于深度学习领域的重要工具和框架。