全阶段代码生成,即WSCG。它指的是基于同一 Stage 内操作符之间的调用关系,把多个 RDD 的 compute 函数捏合成一个,生成一份“手写代码”,然后把这一个函数一次性地作用在输入数据上,真正把所有计算融合为一个统一的函数。
通俗的讲,就是将多个操作符表达式编译为一个Java函数,避免scala 迭代计算和物化rows所带来的overhead。
全阶段代码生成具有以下的优势:
消除虚函数调度。
将中间数据从内存移动到 CPU 寄存器。
利用现代 CPU 功能循环展开和使用 SIMD。通过向量化技术,引擎将加快对复杂操作代码生成运行的速度。
之前已经介绍过了,这里就不再过多赘述了。
执行WSCG需要满足的条件
随着主存的增长,查询的性能越来越取决于查询本身的原始的CPU的成本。对于 Spark SQL来说,经典的迭代式的查询处理虽然灵活简单,但是由于存在局部性,其性能已不能适用现代的CPU。
全阶段代码生成时如何实现的?
Catalyst全阶段代码生成的入口是CollapseCodegenStages规则,它的注入是在代码执行前的preparations阶段。
def apply(plan: SparkPlan): SparkPlan = {
if (conf.wholeStageEnabled) {
insertWholeStageCodegen(plan)
} else {
plan
}
}
只有当conf.wholeStageEnabled设置为true时,才会执行全阶段代码生成的逻辑。但是想要执行代码生成还需要满足一定的条件。
private def insertWholeStageCodegen(plan: SparkPlan): SparkPlan = {
plan match {
// For operators that will output domain object, do not insert WholeStageCodegen for it as
// domain object can not be written into unsafe row.
case plan if plan.output.length == 1 && plan.output.head.dataType.isInstanceOf[ObjectType] =>
plan.withNewChildren(plan.children.map(insertWholeStageCodegen))
case plan: LocalTableScanExec =>
// Do not make LogicalTableScanExec the root of WholeStageCodegen
// to support the fast driver-local collect/take paths.
plan
case plan: CommandResultExec =>
// Do not make CommandResultExec the root of WholeStageCodegen
// to support the fast driver-local collect/take paths.
plan
case plan: CodegenSupport if supportCodegen(plan) =>
// The whole-stage-codegen framework is row-based. If a plan supports columnar execution,
// it can't support whole-stage-codegen at the same time.
assert(!plan.supportsColumnar)
WholeStageCodegenExec(insertInputAdapter(plan))(codegenStageCounter.incrementAndGet())
case other =>
other.withNewChildren(other.children.map(insertWholeStageCodegen))
}
}
插入WholeStageCodegenExec算子需要满足以下条件:
[1] 算子的输出个数为1且数据类型为ObjectType,表明其不是unsafe row,跳过,迭代判断其孩子节点。
[2] plan为LocalTableScanExec的不进行处理。
[3] plan为CommandResultExec的不进行处理。
[4] plan为CodegenSupport的还需判断其所有表达式是否都支持Codegen, 当前plan和其孩子plan的schema的字段个数是否超过了conf.wholeStageMaxNumFields(默认100)。
另外需要注意的是whole-stage-codegen是基于row的,如果plan支持columnar, 则不能同时支持全阶段代码生成。
当以上条件满足会返回一个WholeStageCodegenExec算子。同时其参数中会传入codegenStageCounter计数器,他是codegen阶段生成ID,ID用于帮助区分codegen阶段。例如下面的物理计划:
== Physical Plan ==
*(5) SortMergeJoin [x#3L], [y#9L], Inner
:- *(2) Sort [x#3L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(x#3L, 200)
: +- *(1) Project [(id#0L % 2) AS x#3L]
: +- *(1) Filter isnotnull((id#0L % 2))
: +- *(1) Range (0, 5, step=1, splits=8)
+- *(4) Sort [y#9L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(y#9L, 200)
+- *(3) Project [(id#6L % 2) AS y#9L]
+- *(3) Filter isnotnull((id#6L % 2))
+- *(3) Range (0, 5, step=1, splits=8)
从上面的物理计划可以看出,相邻的节点其代码生成的id并不相邻。另外如果支持代码生成的节点会在打印物理计划时在其前缀加上*的标识。
如上面代码所示,在遍历物理执行计划树时,会先调用insertInputAdapter(plan)去判断是否要为其插入一个 inputAdapter 的物理节点。
有下面三种情况会为其添加inputAdapter节点:
如果不支持代码生成的节点时;
碰到SortMergeJoinExec节点时,会为其孩子节点添加inputAdapter,这里主要是对codegen的拆分。
碰到ShuffledHashJoinExec节点时,同上。
从上面可以看出,这里将不支持codegen的节点、SortMergeJoinExec节点和ShuffledHashJoinExec节点看作为一个codegen的分割点,通过这三种类型的节点可将整个物理计划拆分成多个代码段。而 InputAdapter节点可以看作是对应 WholeStageCodegenExec所包含子树的叶 子节点,起到 InternalRow的数据输入作用。
那么那些节点是支持代码生成的,哪些是不支持支持代码生成的?
Produce和Consume模式
如果一个physical plan如果想要支持 codegen,就需要实现CodegenSupport接口,并且重写doProduce和doConsume函数。
我们先来看下CodegenSupport接口:
trait CodegenSupport extends SparkPlan {
...
/**
* Whether this SparkPlan supports whole stage codegen or not.
*/
def supportCodegen: Boolean = true
/**
* Returns all the RDDs of InternalRow which generates the input rows.
*/
def inputRDDs(): Seq[RDD[InternalRow]]
/**
* Generate the Java source code to process, should be overridden by subclass to support codegen.
*/
protected def doProduce(ctx: CodegenContext): String
/**
* Generate the Java source code to process the rows from child SparkPlan. This should only be
* called from `consume`.
*/
def doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String = {
throw new UnsupportedOperationException
}
}
我们来简单说明下上述的方法。在 CodegenSupport比较重要的就是doProduce和doConsume方法。doProduce方法用于生成“手写”代码的主要框架,doConsume方法主要用于向框架填充每一个操作符的运算逻辑,inputRDDs用于获得产生输入数据的。
下面我们来看看其调用流程, 我们从WholeStageCodegenExec的doExecutor方法开始。
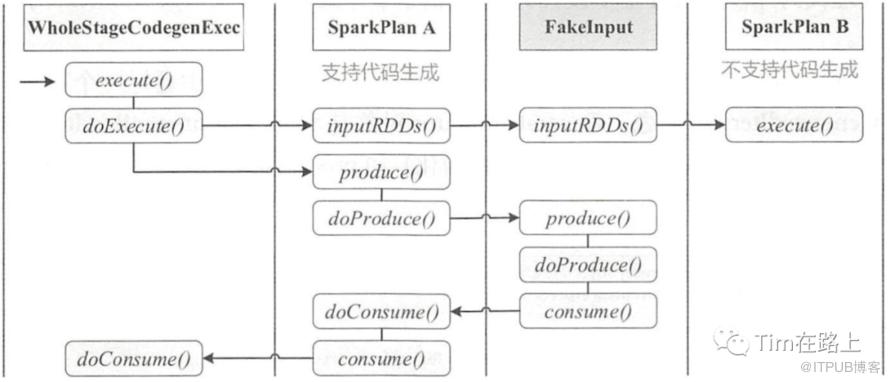
// [1] 首先是调用doCodeGen来生成“手写”代码
override def doExecute(): RDD[InternalRow] = {
val (ctx, cleanedSource) = doCodeGen()
...
}
def doCodeGen(): (CodegenContext, CodeAndComment) = {
val startTime = System.nanoTime()
val ctx = new CodegenContext
// [2] 迭代递归调用produce方法
val code = child.asInstanceOf[CodegenSupport].produce(ctx, this)
...
}
final def produce(ctx: CodegenContext, parent: CodegenSupport): String = executeQuery {
this.parent = parent
ctx.freshNamePrefix = variablePrefix
// [3] 调用doProduce方法生成手写代码的主要框架
s"""
|${ctx.registerComment(s"PRODUCE: ${this.simpleString(conf.maxToStringFields)}")}
|${doProduce(ctx)}
""".stripMargin
}
// Leaf codegen node
override def doProduce(ctx: CodegenContext): String = {
// Inline mutable state since an InputRDDCodegen is used once in a task for WholeStageCodegen
val input = ctx.addMutableState("scala.collection.Iterator", "input", v => s"$v = inputs[0];",
forceInline = true)
val row = ctx.freshName("row")
...
// [4] 在叶子codegen的节点中的doProduce()方法中, 调用consume方法
s"""
| while ($limitNotReachedCond $input.hasNext()) {
| InternalRow $row = (InternalRow) $input.next();
| ${updateNumOutputRowsMetrics}
| ${consume(ctx, outputVars, if (createUnsafeProjection) null else row).trim}
| ${shouldStopCheckCode}
| }
""".stripMargin
}
}
final def consume(ctx: CodegenContext, outputVars: Seq[ExprCode], row: String = null): String = {
...
// [5] 调用父节点的doConsume方法,来生成表达式的细节
val consumeFunc = if (confEnabled && requireAllOutput
&& CodeGenerator.isValidParamLength(paramLength)) {
constructDoConsumeFunction(ctx, inputVars, row)
} else {
parent.doConsume(ctx, inputVars, rowVar)
}
}
// doExecute方法
// [6] 直接从子节点获取数据的输入, 然后执行代码生成的generate方法按照上述逻辑进行生成代码。
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
assert(rdds.size <= 2, "Up to two input RDDs can be supported")
if (rdds.length == 1) {
rdds.head.mapPartitionsWithIndex { (index, iter) =>
val (clazz, _) = CodeGenerator.compile(cleanedSource)
val buffer = clazz.generate(references).asInstanceOf[BufferedRowIterator]
buffer.init(index, Array(iter))
new Iterator[InternalRow] {
override def hasNext: Boolean = {
val v = buffer.hasNext
if (!v) durationMs += buffer.durationMs()
v
}
override def next: InternalRow = buffer.next()
}
}
}
从上面的代码可以看出,代码生成可以看作是两个方向相反的递归过程:代码的整体框架由 produce/doProduce 方法负责,父节点调用子节点;代码具体处理逻辑由 consume/doConsume 方法负责,由子节点调用父节点。
整个物理算子树的执行过程被InputAdapter分隔开。
每一个WholeStageCodegenExec执行时,首先获取输入inputRDDs,递归执行子节点的inputRDDs函数,直到碰到InputAdapter或者数据源物理计划节点,返回子物理计划节点的executor计算结果RDD或者数据源RDD。
然后进行代码生成,递归执行produce()函数,直到碰到InputAdapter或者数据源物理计划节点,返回所有子节点生成的综合代码。利用在WholeStageCodegenExec节点上利用生成代码对inputRDDs进行处理。
所以WholeStageCodegenExec的executor方法不会递归调用子物理计划节点的executor方法,而是首先获得整个WholeStageCodegenExec子树的输入inputRDDs,然后获得整个WholeStageCodegenExec子树的生成代码。最后用生成代码对inputRDD进行处理,一次性的完成了子树中所有物理计划节点的执行任务。这样避免了火山模型中的迭代调用。
这里可以看出其实是将迭代调用转移到了代码生成的阶段,在执行阶段只需一次调用即可。
代码生成过程示例
下面我们以购买iPhone的北京用户统计进行举例。
Select count(userId) from t_order_info where city='Beijing';
首先,在解释其执行过程前,我们再来回顾下之前的知识,以及明确下其生成的结果。
在之前的火上模型中,这条SQL在经过Catalyst的逻辑计划和物理计划后,会被拆分为多个Exec。分别为FileScanExec, FilterExec, ProjectExec 和 AggExec。
每一个Exec中都有doExecutor()方法,在执行时会按照流程进行依次的迭代计算,数据会在每个算子间进行流转。而代码生成则是在执行前先基于inputRDDs接口直接从叶子节点获取数据,然后基于doProduce、doConsume捏合成的“手写”代码进行一次调用。
我们利用手写代码的实现方式不仅消除了操作符,也消除了操作符的虚函数调用,更没有不同算子之间的数据交换,计算逻辑完全是一次性地应用到数据上。而且,代码中的每一条指令都是明确的,可以顺序加载到 CPU 寄存器,源数据也可以顺序地加载到 CPU 的各级缓存中,从而大幅提升了 CPU 的工作效率。
上述的SQL最终转换的手写代码为:
var count = 0;
for (order <- order_info) {
if (city='Beijing') {
count += 1;
}
}
那么WSCG 是怎么在运行时动态生成代码的呢?
首先,WSCG 是在一个 Stage 内部生成"手写"代码的,这条SQL它由于count(userId)的聚合操作引入了Shuffle, 它可以被分割成两个Stage。第一个Stage为FileScanExec, FilterExec, ProjectExec ,第二个为AggExec。
其次,在执行物理计划前会执行CollapseCodegenStages 规则,它的作用正是尝试为每一个 Stages 生成“手写代码”。总的来说,即从父节点到子节点,递归调用 doProduce,生成代码框架从子节点到父节点,递归调用 doConsume,向框架填充每一个操作符的运算逻辑。
下面我们来简单梳理下其执行流程:
首先,在 Stage 顶端节点也就是 Project 之上,会添加上 WholeStageCodeGen 计算节点。WholeStageCodeGen 节点通过调用 doExecute 来触发整个代码生成过程的计算。doExecute 会递归调用子节点的 doProduce 函数,直到遇到 Shuffle Boundary 为止。这里,Shuffle Boundary 指的是 Shuffle 边界,要么是数据源,要么是上一个 Stage 的输出。在叶子节点(也就是 Scan)调用的 doProduce 函数会先把手写代码的框架生成出来,如上图中右侧蓝色部分的代码。
然后,Scan 中的 doProduce 会反向递归调用每个父节点的 doConsume 函数。不同操作符在执行 doConsume 函数的过程中,会把关系表达式转化成 Java 代码,然后把这份代码像做“完形填空”一样,嵌入到刚刚的代码框架里。比如上图中橘黄色的 doConsume 生成的 if 语句,其中包含了判断地区是否为北京的条件,以及紫色的 doConsume 生成了获取必需字段 userId 的 Java 代码。
最后,Tungsten 利用 CollapseCodegenStages 规则,经过两层递归调用把 Catalyst 输出的 Spark Plan 加工成了一份“手写代码”,并把这份手写代码会交付给 DAGScheduler。拿到代码之后,DAGScheduler 再去协调自己的两个小弟 TaskScheduler 和 SchedulerBackend,完成分布式任务调度。
总结
在支持更通用的火山迭代器模型中,两个运算符之间的每次连接调用都会导致一个虚函数调用 + 从内存中读取父输出 + 将最终输出写入内存。这也导致其存在过多的虚函数的调用,广泛的内存访问和无法利用流水线、预取、分支预测、SIMD、循环展开等能力。
因此,在Spark SQL的运行时,我们获得了更多的已知信息,可以动态的更加定制化的为此SQL生成更简单但效率较高的"手写"代码,这就是全阶段代码生成想要做的事情。
1、全阶段代码生成是将一个Stage的代码进行“捏合”。
2、SQL生成的物理计划在执行前会先执行CollapseCodegenStages 规则,它的作用正是尝试为每一个 Stages 生成“手写代码”。
3、每一个WholeStageCodegenExec执行时,首先获取输入inputRDDs,直接从叶子节点获取数据的输入。
4、从父节点到子节点,递归调用 doProduce,生成代码框架,直到遇到 Shuffle Boundary 为止。
5、从子节点到父节点,递归调用 doConsume,向框架填充每一个操作符的运算逻辑。
当我们想要做的操作很简单时,全阶段代码生成效果会特别好。但是在某些情况下,生成代码以将整个查询融合到一个函数中是不可行的。例如,包含复杂的 I/O,复杂的外部集成。像是格式复杂的csv, parquet, 或使用 python、张量流等第三方组件,我们将无法将他们的代码集成到我们的代码中。
那么这种情况如何处理呢?这就离不开向量化的处理。