今天我们来聊一聊Spark中的CodeGen。
Tungsten 是 Spark 对CPU和内存使用优化一揽子项目的代号, 它是在2015年启动的,在对许多数据处理问题进行分析后发现,瓶颈的主要部分不是由最初预期的 I/O 或网络问题引起的,而是由 CPU 和内存限制引起的。所以Tungsten使用代码生成来利用现代编译器和 CPU。
Spark Tungsten代码生成分为两个部分,一部分是最基本表达式的代码生成,另一部分称为全阶段代码生成,即WSCG。
在Spark中,其优化主要分为两部分执行前的静态优化和运行时的动态优化。
在Spark中静态优化主要包括基于规则的优化(RBO), 基于代价的优化(CBO),它们的核心的目标就是在执行前将找出最优的执行计划。
动态优化主要包括自适应执行优化(AQE)主要是根据执行过程中的中间数据对执行计划进行调整,它的目前是从全局上消除数据倾斜、降低IO和提高资源利用率。此以外就是Tungsten的Codegen技术和向量化,它主要是针对具体的Task的执行效率的优化。
Spark Codegen的优势
Tungsten Codegen优化
Codegen优化的一部分是基本表达式的代码生成。它依赖于不同CodeGenerator的触发,根据CodeGenerator将表达式转换生成Java代码,然后依赖Janino框架把生成手写代码编译成class文件,最后再加载并执行。
可以看到,基本代码的生成得到的都是一个个单独的处理模块 。
Codegen优化的另一部分全阶段代码生成,即WSCG。我们接下来着重介绍下WSCG。
首先,WSCG 到底是什么?WSCG 指的是基于同一 Stage 内操作符之间的调用关系,把多个 RDD 的 compute 函数捏合成一个,生成一份“手写代码”,然后把这一个函数一次性地作用在输入数据上,真正把所有计算融合为一个统一的函数。
火山模型的问题
要明白Spark Codegen的优势,我们就需要先了解传统SQL执行所应用的火山模型的问题。
当前绝大数的的数据库系统在处理SQL时都是将其翻译成一系列的关系代数算子表达式,然后依赖这些关系代数算子逐条的处理输入数据并产生结果,叫做Volcano 火山模型(又名迭代器模型)。
我们来简化下火山模型:
open() - 初始化一个状态
next() - 产生一个输出
close() - 清理状态
火山模型抽象有三个方法组成,所有的操作符算子只要是实现了迭代器抽象都可以加入到语法树当中参与计算。另外,为了方便操作符之间的数据交换,迭代器模型对所有操作符的输出也做了统一的封装。对于数据源中的每条数据条目,语法树当中的每个操作符都需要完成如下步骤:从内存中读取父操作符的输出结果作为输入数据;调用 next 方法,以操作符逻辑处理数据;将处理后的结果以统一的标准形式输出到内存,供下游算子消费。
这种迭代处理模式提出的背景是减轻查询处理的IO瓶颈,对CPU的消耗考虑的比较少。但这样的处理模式带来了以下问题:
虚函数的调用;
代码本地化能力差,需要保存复杂处理信息等。
内存数据的随机存取,中间数据需要物化到内存。
基于以上的问题,现代数据库开始尝试摆脱火山模型。
一种方式是向量化,即考虑面向数据块block的方式。通过批量执行加列式存储,加小循环,来更好的利用 SIMD的指令和CPU的乱序执行,从而最大化数据并行度和指令并行度,从而分摊掉虚函数调用的开销,并提升执行性能。这种方式在一定程度上确实能够消除大数据量下的调用代价,但也丢掉了可以按照管道传输数据的优势,并且通常情况下会消耗更多的内存与网络带宽。
另一种方式是采用动态生成来取代解释性的结构。通过算子融合,打破了Stage内部算子间的界限,拼出来跟原来的逻辑保持一致的裸的代码通常是一个大的for循环,然后把拼成的代码编译成可执行文件。由于拼出的代码完全不存在迭代器和额外的函数调用,不存在任何框架上的Overhead。所以完全消除了虚函数调用,另外也没有了物化,中间数据都保存在寄存器里。但它的缺点就是因为 for循环比较大,而且每次迭代执行的逻辑非常的复杂,所以很难应用SIMD的优化。
为什么动态代码生成会比火山模型有优势?
3.1 无虚函数分派
在继续之前,我们稍微展开解释下什么是虚函数?
虚函数就像 Java 的抽象方法,它们已声明,但仅在子类中实现。
虚函数的存在是为了多态。它虚就虚在所谓“推迟联编”或者“动态联编”上,一个类函数的调用并不是在编译时刻被确定的,而是在运行时刻被确定的。由于编写代码的时候并不能确定被调用的是基类的函数还是哪个派生类的函数,所以被成为“虚”函数。C++中普通成员函数加上virtual关键字就成为虚函数。Java中其实没有虚函数的概念,它的普通函数就相当于C++的虚函数,动态绑定是Java的默认行为。
public abstract class A {
public abstract eat();
}
public class B extends A {
override public eat() {}
}
public class C extends A {
override public eat() {}
}
A b = new B();
b.eat();
例如上面的代码,当你在调用b.eat()时,编译器不知道应该调用A类的哪个实现。要想知道,就必 须查看vtable。vtable 是一个包含所有虚函数的结构。对于每个虚函数条目,它都存储一个指向此函数定义的指针。虚函数分派使用每个类下的 vpointer,进入对应的虚表,最后才解析要执行的代码。但是如果在整个代码动态生成的情况下,由于一切都发生在明确定义实现的 一个类中,因此不存在虚函数。
3.2 内存中的中间数据与CPU寄存器
在迭代器模型(火山模型)中,每次操作符将元组传递给另一个操作符时,都需要将元组放入内存(函数调用堆栈),即需要保存在内存复杂处理信息。例如,表扫描的算子在处理一个压缩的数据表时,在迭代的模式下,需要每次产生一个数据元组,因此表扫描算子中需要记录当前数据元组在压缩数据流中的位置,以便根据压缩方式跳转到下一条数据元组的位置。
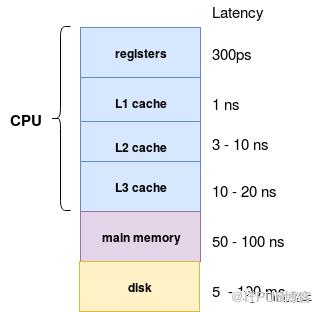
但是在动态代码生成中,编译器实际上将中间数据放在 CPU 寄存器中。同样,CPU 访问内存中的数据所花费的周期数比寄存器中的大几个数量级。
此外对于进行动态生成后的代码,更有利于编译器和 CPU 的优化。
3.3 循环展开和SIMD
现代编译器和 CPU 在编译和执行简单的 for 循环时非常高效。编译器通常可以自动展开简单循环,甚至生成 SIMD 指令来处理每个 CPU 指令的多个元组。CPU 包括流水线、预取和指令重新排序等特性,这些特性使执行简单循环变得高效。然而,这些编译器和 CPU 并不擅长优化 Volcano 模型所依赖的复杂函数调用图。
for (i = 0; i < 100; i++):
do_something(i)
可以由编译器重写为这种优化的(循环展开)形式:
for (i = 0; i < 100; i += 2):
do_something(i)
do_something(i+1)
除上面的以外,在动态生成代码中的每一条指令都是明确的,可以顺序加载到 CPU 寄存器,源数据也可以顺序地加载到 CPU 的各级缓存中,从而大幅提升了 CPU 的工作效率。
Janino动态编译”手写”Java代码
Spark中的动态代码的生成依赖于Janino编译器。Janino是一个轻量级的Java编译器。作为Library,它可以直接在Java程序中调用,动态编译java代码并加载。编译时可以直接引用JVM中已经加载的类,可以做到比 javac 快得多的性能。
下面我们来举一个例子:例如 实现一个 ”x + 4 - x“ 表达式,用scala代码表达如下:
Subtract(Add(Attribute(x), Literal(4)),Attribute(x))
如果在未开启Codegen的情况下实现上述表达式的求值,Spark中一般需要依次遍历表达式树,对其进行模式匹配并依次处理,通过迭代的方式进行计算。例如下面的代码。
tree.transformUp {
case Attribute(idx) => Literal(row.getValue(idx))
case Add(Literal(c1),Literal(c2)) => Literal(c1+c2)
case Subtract(Literal(c1),Literal(c2)) => Literal(c1-c2)
case Literal(c) => Literal(c)
}
可见在上述代码需要做很多类型匹配、虚函数调用、对象创建等额外逻辑,而这些overhead远超对表达式求值本身。虽然通过模式匹配的代码计算可以实现对SQL更加优雅的嵌套处理,但这种方式也会带来更多的性能损耗。
下面我们来看下使用Janino是如何编译编译表达式的:
val exp = new ExpressionEvaluator()
// 设置表达式结果类型
exp.setExpressionType(classOf[Long])
// 设置入参的名字和类型
exp.setParameters(Array("x"), Array(classOf[java.lang.Long]))
// 编译!
exp.cook("x + 4 - x")
// 多次调用来 evaluate
Range(1, 6).foreach{ i =>
println(i + " --> " + exp.evaluate(0, i))
}
我们需要设置表达式的返回结果类型,参数的变量名与类型,已经准备复杂的表达式的字符串形式,然后调用evaluate函数设置参数的值即可。
可见只要设置表达式中的参数名字和类型与结果类型,就可以对字符串类型的表达式进行直接编译,省去了大量的对象创建与函数调用。
Expression Codegen
由上面的示例可知,要利用Janino编译器实现Expression表达式的生成,需要按照Janino语法对表达式进行编译前设置,包含变量的名称类型与初始参数的定义,函数的名称与定义,对象的定义等。那么Spark的Codegen体系是如何实现这些的呢?
Spark中关于Expression Codegen的代码都放在了catalyst/expressions/codegen 文件夹下。下面我们来简单分析下。
要实现对字符串表达式的编译,就需要按照Janino语法设置参数和类型信息。在Spark中,专门定义了CodegenContext类,来负责记录了Spark Expressions将要生成的代码中的各种元素,包括变量、函数等等信息。
CodegenContext是代码生成的上下文。在表达式的生成和消费中都需要携带CodegenContext上下文信息。
下面我们举CodegenContext中的几个简单变量介绍下:
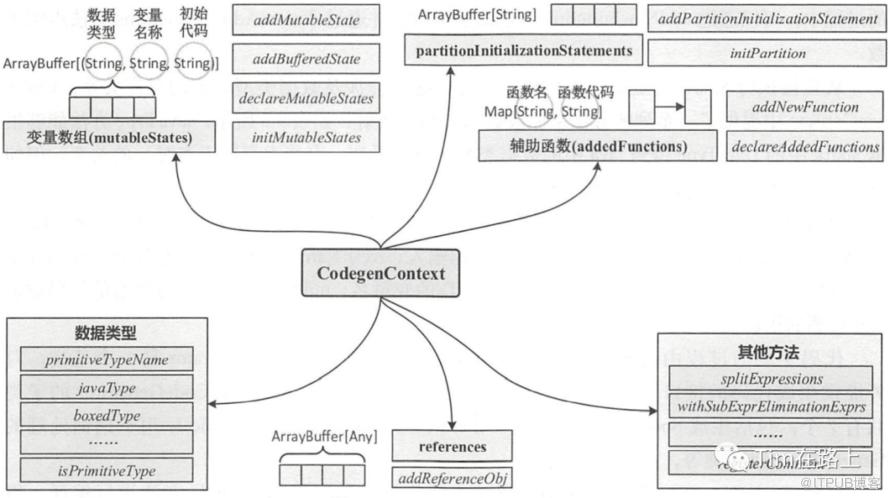
如上图所示,CodegenContext中使用mutableStates来记录和表达生成的代码中的所有变量。mutableStates变量的类型为三元字符串(javaType, variableName, initCode)构成的数组。记录变量的Java 类型、名称和初始化值。
例如如果在mutableStates中存储的三元组(“int”,“count”,“count= 0;”),则表示将生成“private int count;“代码,同时在类的初始化函数中会生成“count= 0”代码。
CodegenContext中使用references来记录要生成的对象。references 也是一个数组,用来保存生成代码中的对象(objects),可以通过 addReferenceObj 方法添加。
CodegenContext中使用addedFunctions来记录要生成的函数。addedFunctions类型为 Map[String, String],提供了函数名和函数代码的映射关系。在代码生成的过程中,可以通过addNewFunction 方法添加函数。
在记录了代码生成的上下文信息后,Spark 中代码是如何生成的呢?
在Spark中代码生成的过程主要由代码生成器(CodeGenerator)完成, CodeGenerator 是一个基类,对外提供生成代码的接口是 generate和create。下面我们来看下CodeGenerator类。
abstract class CodeGenerator[InType <: AnyRef, OutType <: AnyRef] extends Logging {
protected val genericMutableRowType: String = classOf[GenericInternalRow].getName
protected def create(in: InType): OutType
protected def canonicalize(in: InType): InType
/** Binds an input expression to a given input schema */
protected def bind(in: InType, inputSchema: Seq[Attribute]): InType
/** Generates the requested evaluator binding the given expression(s) to the inputSchema. */
def generate(expressions: InType, inputSchema: Seq[Attribute]): OutType =
generate(bind(expressions, inputSchema))
/** Generates the requested evaluator given already bound expression(s). */
def generate(expressions: InType): OutType = create(canonicalize(expressions))
def newCodeGenContext(): CodegenContext = {
new CodegenContext
}
}
如上代码所示,通过调用generate方法使bind方法将表达式的和inputSchema进行绑定(一般会调用BindReferences.bindReference方法)。再调用generate(expressions: InType)方法。在生成前会先调用canonicalize对表达式进行规范化,然后调用create方法进行代码生成。
CodeGenerator有6个子类(目前7个)实现不同阶段的表达式的生成, 其正好对应了SQL的不同片段,CodeGenerator的子类中会重写了bind方法、canonicalize方法、create方法以实现自己的代码生成逻辑。我们都知道SQL在进行catalyst优化时会先转换为AST树,SQL树会被拆分为不同的node。
例如下面的SQL, select name from student where age > 18 所示:
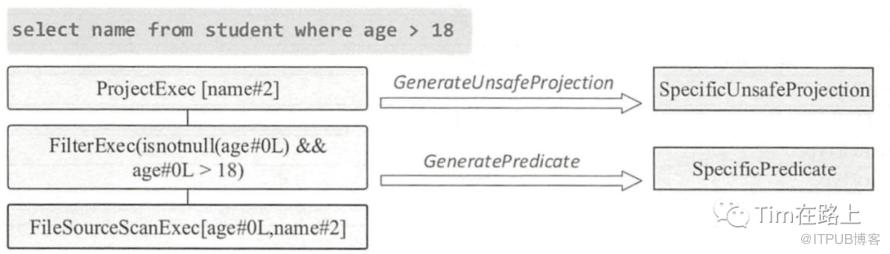
其中name 对应project node 代表数据的投影,student对应relation node阶段代表数据表,age > 18 代码Filter node, 代码数据的过滤谓词。
Spark为SQL的常用node节点都设置了一个Codegenerator的子类。例如 ProjectExec 对应的子类为GenerateUnsafeProject, FilterExec对应的Codegenerator的子类为GeneratePredicate。下图展示就是spark中的所有Codegenerator子类。
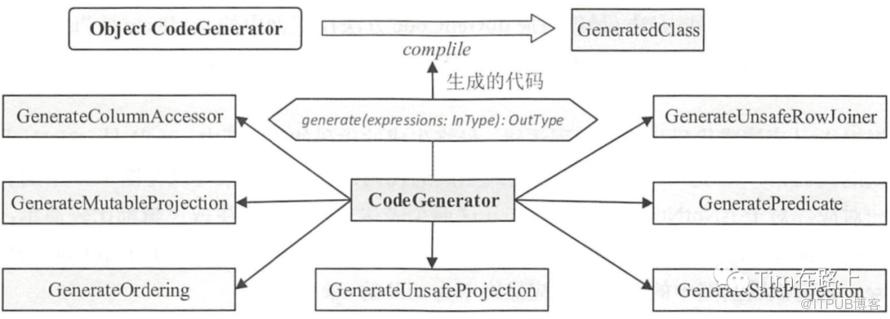
Spark SQL首先通过catalyst将其转换为逻辑计划,然后在从中生成物理计划。最后在执行时根据物理计划节点的类型去调用不同的Codegenerator的子类,最终生成一份”手写“Java代码。最终将SQL的输入在执行前转换为Java类。
Project的代码生成过程
在关闭全阶段代码生成后,spark.sql.codegen.wholeStage 设置为 false,来观察下基本的代码生成功能。
首先,Project即投影,代表的是SQL中select后的查询列,其可以是常量,列名,表达式。
然后,SQL在经过antlr4后会被解析为AST树结构,在逻辑计划阶段转换为Project的表达式。在物理执行阶段Project表达式会转换为ProjectExec物理执行的节点。
其次,在运行时会调用ProjectExec的doExecute方法来执行project的逻辑。在ProjectExec 节点的doExecute方法方法中则会通过调用 UnsafeProjection.create方法。
最后,通过工厂接口其最终会调用到GenerateUnsafeProjection 对象的 generate 方法来生成预定义的”手写“代码UnsafeProjection 类,完成Java版本的投影算子的逻辑。
下面我们来基于代码展开其实现过程。
我们以ProjectExec为例,在运行时在执行ProjectExec时会调用执行其doExecutor()方法。然后,在该方法中会调用UnsafeProjection.create(projectList, child.output),其方法参数是传入为上一个孩子节点的输出,以及要投影的列表projectList。
protected override def doExecute(): RDD[InternalRow] = {
child.execute().mapPartitionsWithIndexInternal { (index, iter) =>
val project = UnsafeProjection.create(projectList, child.output)
project.initialize(index)
iter.map(project)
}
}
override protected def createCodeGeneratedObject(in: Seq[Expression]): UnsafeProjection = {
GenerateUnsafeProjection.generate(in, SQLConf.get.subexpressionEliminationEnabled)
}
通过UnsafeProjection.create会调用GenerateUnsafeProjection.generate方法。最终我们来看下spark是如何生成SpecificUnsafeProjection,通过绑定schema和正则会最终会执行create方法。
private def create(
expressions: Seq[Expression],
subexpressionEliminationEnabled: Boolean): UnsafeProjection = {
// [1] 构造CodegenContext
val ctx = newCodeGenContext()
// [2] 通过createCode生成,代码中动态变更的代码部分
val eval = createCode(ctx, expressions, subexpressionEliminationEnabled)
// [3] 搭建SpecificUnsafeProjection类的代码主题框架
val codeBody =
s"""
|public java.lang.Object generate(Object[] references) {
| return new SpecificUnsafeProjection(references);
|}
|
|class SpecificUnsafeProjection extends ${classOf[UnsafeProjection].getName} {
|
| private Object[] references;
| ${ctx.declareMutableStates()}
|
| public SpecificUnsafeProjection(Object[] references) {
| this.references = references;
| ${ctx.initMutableStates()}
| }
|
| public void initialize(int partitionIndex) {
| ${ctx.initPartition()}
| }
|
| // Scala.Function1 need this
| public java.lang.Object apply(java.lang.Object row) {
| return apply((InternalRow) row);
| }
|
| public UnsafeRow apply(InternalRow ${ctx.INPUT_ROW}) {
| ${eval.code}
| return ${eval.value};
| }
|
| ${ctx.declareAddedFunctions()}
|}
""".stripMargin
val code = CodeFormatter.stripOverlappingComments(
new CodeAndComment(codeBody, ctx.getPlaceHolderToComments()))
logDebug(s"code for ${expressions.mkString(",")}:\n${CodeFormatter.format(code)}")
// [4] 编译生成java代码
val (clazz, _) = CodeGenerator.compile(code)
clazz.generate(ctx.references.toArray).asInstanceOf[UnsafeProjection]
}
从create方法中,我们可以看出其主要进行以下工作
[1] 首先创建了CodeGenContext, 记录必要的动态编译必要的上下文信息。
[2] 通过createCode生成,代码中动态变更的代码部分。
[3] 搭建SpecificUnsafeProjection类的代码主题框架
[4] 编译生成java代码
def createCode(
ctx: CodegenContext,
expressions: Seq[Expression],
useSubexprElimination: Boolean = false): ExprCode = {
val exprEvals = ctx.generateExpressions(expressions, useSubexprElimination)
val exprSchemas = expressions.map(e =>Schema(e.dataType, e.nullable))
val numVarLenFields = exprSchemas.count {
caseSchema(dt, _) => !UnsafeRow.isFixedLength(dt)
//TODO: consider large decimal and interval type
}
val rowWriterClass =classOf[UnsafeRowWriter].getName
val rowWriter = ctx.addMutableState(rowWriterClass, "rowWriter",
v => s"$v = new$rowWriterClass(${expressions.length},${numVarLenFields * 32});")
// Evaluate all the subexpression.
val evalSubexpr = ctx.subexprFunctionsCode
val writeExpressions =writeExpressionsToBuffer(
ctx, ctx.INPUT_ROW, exprEvals, exprSchemas, rowWriter, isTopLevel = true)
val code =
code"""
|$rowWriter.reset();
|$evalSubexpr
|$writeExpressions
""".stripMargin
// `rowWriter` is declared as a class field, so we can access it directly in methods.
ExprCode(code, FalseLiteral, JavaCode.expression(s"$rowWriter.getRow()",classOf[UnsafeRow]))
}
从上面的代码可以看出,SpecificUnsafeProjection类中定义了 3个变量。
首先是 UnsafeRow类型的 result变量,用来记录 PrjectExec 的执行结果;
其次是 BufferHolder 类型的 holder 变量,即投影处理过 程中的缓冲区,用于单数据行的缓存;
最后是 UnsafeRowWriter类型的 rowWriter变量,用来执行写数据操作 。
另外我们再分析下SpecificUnsafeProjection类中的 apply方法,其主要完成4件事。
(1) 重置 BufferHolder对象( resetBufferHolder)。如果 ProjectExec算子表达式的数据类型全 都是固定长度的,那么此时无需再进行任何操作,否则对 BufflerHolder执行 reset操作 。
(2)子表达式评估( evalSubexpr) 。本例中 CodegenContext 的 subexprFunctions 为 空 ,因此 生成的代码不包含任何内容 。
(3)写入表达式( writeExpressions)。这部分是 ProjectExec算子的操作核心,根据数据类型 的不同,对应多种情况。图 9.26展示的是投影算子选择 name这一列的实际代码。可以看到,首 先会判断这一列数据是否为 null,如果是,则直接写入 null;否则获取数据行中对应下标的列, 然后用 rowWriter 写入 。
(4)更新行变量( updateRowSize)。同样的,如果 ProjectExec 算子中表达式的数据类型全都 是固定长度的,那么无需进行任何操作,否则执行 setTotalSize 方法来更新 result对象的行数信息。
总结
在Spark中静态优化主要在执行前将找出最优的执行计划,动态优化主要时在执行时优化,例如自适应执行优化(AQE),RuntimeFilter等。Tungsten Codegen也属于动态优化,其主要是针对具体的Task的执行效率的优化。
Tungsten Codegen优化主要包括两个部分,一部分是最基本表达式的代码生成,另一部分称为全阶段代码生成,即WSCG。其主要解决传统的”火山“迭代计算模型,所带来的虚函数的调用,代码本地化能力差,需要保存复杂处理信息等问题。
基于动态代码生成的”手写“代码,具有不存在虚函数调用,中间数据放在 CPU 寄存器中,可以利用SIMD特性等优势。
Codegen的生成主要依赖于Janino的动态编译。Spark中基本表达式的代码生成流程为:
SQL在经过antlr4后会被解析为AST树结构,经过逻辑计划阶段转换为逻辑表达式。经过物理执行阶段逻辑表达式会转换为物理执行节点。
在运行时会调用物理执行节点的doExecute方法来执行其对应的逻辑。在物理执行的doExecute方法方法中则会通过调用工厂方法,来触发CodeGenerator的不同子类。
通过调用到CodeGenerator子类对象的 generate 方法来动态编译生成预定义的”手写“代码,完成Java版本的投影算子的逻辑。
下面我们再接着介绍WSCG。