Tungsten 可以说为Spark成为大数据必备的主流组件奠定了基础,同时可以给其他的分布式计算框架提供着借鉴意义。
Tungsten Project是在2015年启动的,在对许多数据处理问题进行分析后发现,瓶颈的主要部分不是由最初预期的 I/O 或网络问题引起的,而是由 CPU 和内存限制引起的。
所以Tungsten 是 Spark 对CPU和内存使用优化一揽子项目的代号,其主要包括以下内容,这些内容并非是一个改造可以带来的,有些甚至是非常独立的,所以我们先总体进行介绍后,在各个进行深入分析理解。
Tungsten 项目包括以下部分:
-
内存管理和二进制处理:
利用应用程序语义显式管理内存并消除 JVM 对象模型和垃圾收集的开销
-
缓存感知计算:
利用内存层次结构的算法和数据结构
-
代码生成:
使用代码生成来利用现代编译器和 CPU
-
无虚函数分派:
这减少了多次 CPU 调用,这在分派数十亿次时会对性能产生深远影响。
-
内存中的中间数据与 CPU 寄存器:
Tungsten Phase 2 将中间数据放入 CPU 寄存器中。这是从 CPU 寄存器而不是从内存中获取数据的周期数减少了一个数量级
循环展开和 SIMD:优化 Apache Spark 的执行引擎,以利用现代编译器和 CPU 高效编译和执行简单 for 循环(相对于复杂函数调用图)的能力。其中最主要的是内存管理和二进制处理,缓存感知计算以及代码生成。而无虚函数分派、内存中的中间数据与 CPU 寄存器和循环展开和 SIMD都包括在动态代码生成中。
1.内存管理和二进制处理
其实UnsafeRow已经在unsafeShuffleWriter那一讲将过了,那这里就在简单重复下。
Tungsten对内存管理优化的原因主要有两方面:
1. Java对象占用内存的空间大。2. Jvm垃圾回收的开销大。
下面我们分析下直接采用JAVA对象存储的问题:我们拿类型是 String 的 name 来举例,如果一个用户的名字叫做“abcd”,它本应该只占用 4 个字节,但在 JVM 的对象存储中,“abcd”会消耗总共 48 个字节,其中包括 12 个字节的对象头信息、8 字节的哈希编码、8 字节的字段值存储和另外 20 个字节的其他开销。
另外,如果存在一个User表,其中存在username String, age Int, sex Char三个字段。那么一行数据需要创建三个包装类,同时需要将其装入到Array数组中,最后封装为GenericMutableRow。那么总共需要5个类。我们知道大量的类的创建会加剧JVM的GC情况,如果可以将其封装为一个类中,那么就减少了大量的类的创建。
那么Tungsten是如何解决这些问题的?
Tungsten使用新的序列化格式比通常的方法(Kryo、Java 序列化)更紧凑、更快,它是一种紧凑的二进制格式 Unsafe Row数据结构,即UnsafeRow。
Unsafe Row 是一种字节数组,它可以用来存储下图所示 Schema 为(userID,name,age,gender)的用户数据条目。总的来说,所有字段都会按照 Schema 中的顺序安放在数组中。其中,定长字段的值会直接安插到字节中,而变长字段会先在 Schema 的相应位置插入偏移地址,再把字段长度和字段值存储到靠后的元素中。
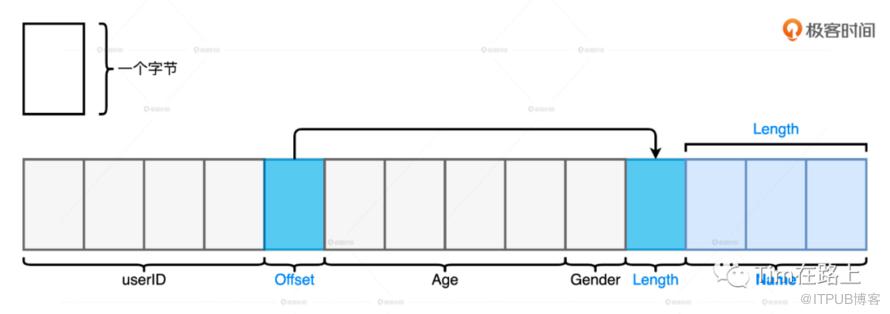
字节数组的存储方式在消除存储开销的同时,仅用一个数组对象就能轻松完成一条数据的封装,显著降低 GC 压力。
下面我们来看下UnsafeRow是如何存储一行数据的。
在UnsafeRow中使用序列化的Row(二进制数组)来存储,每个序列化的Row由三部分组成:
Null Bit set Bitmap,在bitmap中跟踪空值,也用于初始化,初始化所有值为空。
填充的值,(1) 如果空值取0。(2) 对于NullType、BooleanType、ByteType、ShortType、IntegerType、LongType、FloatType、DoubleType、DateType、TimestampType存储其真实值。(3) 对于非以上类型的可变变量,填充其Offset偏移量。
可变长度变量的值,分为两部分为Length和其内容。例如String,第一个存储的字对应于长度,第二个字对应于以 UTF-8 编码的 String 的内容字节。
使用UnsafeRow进行存储对象和数据,减少了大量对象的生成,减少了内存的占用,避免了GC的问题。不过,Tungsten 并未止步于此,为了统一堆外与堆内内存的管理,同时进一步提升数据存储效率与 GC 效率,Tungsten 还推出了基于内存页的内存管理模式。
为了统一管理 Off Heap 和 On Heap 内存空间,Tungsten 定义了统一的 128 位内存地址,简称 Tungsten 地址。Tungsten 地址分为两部分:前 64 位预留给 Java Object,后 64 位是偏移地址 Offset。具体的定义在MemoryLocation类中
1public class MemoryLocation {
2
3 @Nullable
4 Object obj;
5
6 long offset;
7
8 public MemoryLocation(@Nullable Object obj, long offset) {
9 this.obj = obj;
10 this.offset = offset;
11 }
12...
13}
对于 On Heap 空间的 Tungsten 地址来说,前 64 位存储的是 JVM 堆内对象的引用或者说指针,后 64 位 Offset 存储的是数据在该对象内的偏移地址。而 Off Heap 空间则完全不同,在堆外的空间中,由于 Spark 是通过 Java Unsafe API 直接管理操作系统内存,不存在内存对象的概念,因此前 64 位存储的是 null 值,后 64 位则用于在堆外空间中直接寻址操作系统的内存空间。
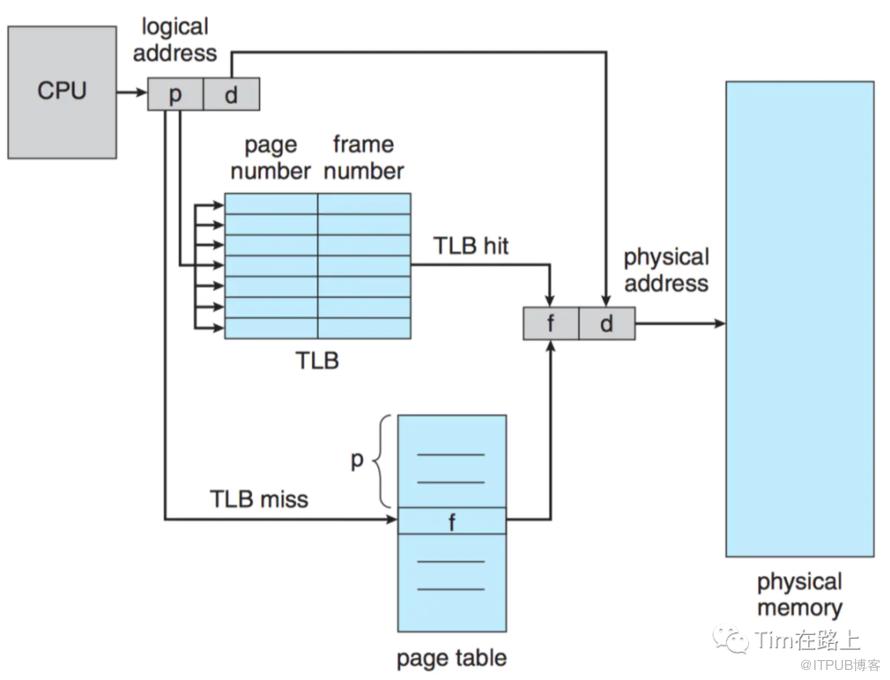
每个Task的内存空间被分为多个内存页Page, 每个内存页本质上都是一个内存块(MemoryBlock)。TaskMemoryManager统一了堆内堆外内存的访问方式,引入了虚拟内存逻辑地址的概念,并将逻辑地址转换为实际的物理地址。逻辑地址是一个64bits的长整型,高13bits用来表示页号pageNumber,低51bits用来表示该内存内部的偏移offset。
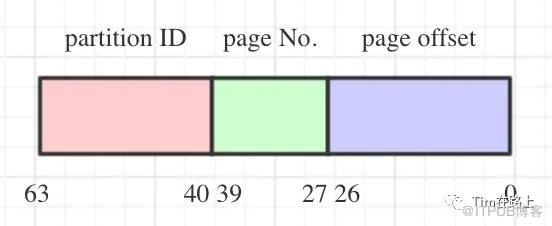
同时Tungsten基于以上的内存优化重写实现新的HashMap数据结构的实现BytesToBytesMap。除此以外最重要的应用莫过于基于内存优化实现SortShuffleWriter的实现,主要包含UnsafeShuffleWriter、ShuffleExternalSorter和ShuffleInMemorySorter。
2.缓存敏感计算
敏感计算指的是利用访问CPU的L1/L2/L2级缓存比访问内存的速度快的特性,Tungsten通过设计缓存优化的数据结构来提高缓存的命中率(Cache hit)和(Cahce locality)的特性。
主要的实现应用主要是UnsafeExternalSorter和UnsafeInMemorySorter的实现上。
Tungsten中cache-aware排序原理如下所示:
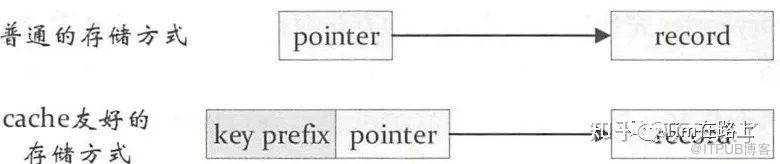
常规的做法是每个键值对record中有一个指针指向该record,对两个record 比较时先根据指针定位到实际数据,然后对实际数据进行比较,由于这个操作涉及的是内存的随机访问,缓存本地化(空间局部性)会变得很低。
针对该缺陷,其中一个方法就是通过指针顺序地储存每个记录的sort key。缓存友好的存储方式会将key和record指针放在一起,以key为前缀,避免内存的随机访问。举个例子,如果sort key是一个64位的整型,那么我们需要在指针阵列中使用128位(64位指针,64位sort key)来指向储存每条记录。
1public final class RecordPointerAndKeyPrefix {
2/**
3 * A pointer to a record; see {@linkorg.apache.spark.memory.TaskMemoryManager} for a description of how these addresses are encoded.
4 */
5public long recordPointer;
6
7/**
8 * A key prefix, for use in comparisons.
9 */
10public long keyPrefix;
11}
对于UnsafeExternalSorter来说排序功能主要依赖于UnsafeInMemorySorter,类似于ShuffieExternalSorter和ShuffleInMemorySorter的关系,区别为数据的插入分为两部分。
一部分是调用Platform方法进行真实数据的插入,另一部分是其索引,真实数据插入的地址和其prefix值的插入,当记录只用prefix来比较大小时,真实数据的排序就转换为索引的排序。
被UnsafeExternalRowSorter使用,实现了InternalRow的排序,用于SortExec物理计划的排序。被UnsafeKVExternalSorter使用,实现了键值对数据的排序功能,用于HashAggregateExec物理计划中保存溢出聚合缓冲区。
3.动态代码生成
Tungsten代码生成分为两个部分,一部分是最基本表达式的代码生成,另一部分称为全阶段代码生成,即WSCG。我们将着重介绍WSCG。
首先,WSCG 到底是什么?WSCG 指的是基于同一 Stage 内操作符之间的调用关系,把多个 RDD 的 compute 函数捏合成一个,生成一份“手写代码”,然后把这一个函数一次性地作用在输入数据上,真正把所有计算融合为一个统一的函数。
那为什么在Spark中引入动态代码生成?
当前绝大数的的数据库系统在处理SQL时都是将其翻译成一系列的关系代数算子表达式,然后依赖这些关系代数算子逐条的处理输入数据并产生结果,叫做Volcano 火山模型(又名迭代器模型)。
我们来简化下迭代器模型:
open() - 初始化一个状态
next() - 产生一个输出
close() - 清理状态
迭代器抽象有三个方法组成,所有的操作符算子只要是实现了迭代器抽象都可以加入到语法树当中参与计算。另外,为了方便操作符之间的数据交换,迭代器模型对所有操作符的输出也做了统一的封装。
对于数据源中的每条数据条目,语法树当中的每个操作符都需要完成如下步骤:从内存中读取父操作符的输出结果作为输入数据;调用 next 方法,以操作符逻辑处理数据;将处理后的结果以统一的标准形式输出到内存,供下游算子消费。
这种迭代处理模式提出的背景是减轻查询处理的IO瓶颈,对CPU的消耗考虑的比较少。所以这样的处理模式带来了以下问题:
虚函数的调用;
代码本地化能力差,需要保存复杂处理信息等。
内存数据的随机存取。
基于以上的问题,现代数据库开始尝试摆脱迭代器模型。
一种方式是考虑面向数据块block的方式,来获得数据向量化的处理优势。这种方式在一定程度上确实能够消除大数据量下的调用代价,但也丢掉了可以按照管道传输数据的优势,并且通常情况下会消耗更多的内存与网络带宽。
另一种方式是采用动态生成来取代解释性的结构。
动态生成可以解决以下3个方面的问题:
大量虚函数的调用,生成的代码全部在一个类中不存在虚函数。
判断数据类型和操作算子等内容的大型分支选择语句。
常数传播的限制,生成的代码中能确定性的折叠常量。
下面我们先来解释下为什么动态代码生成会比火山模型(迭代器模式)有优势?
3.1 无虚函数分派
在继续之前,我们稍微展开解释下什么是虚函数?
虚函数就像 Java 的抽象方法,它们已声明,但仅在子类中实现。
虚函数的存在是为了多态。它虚就虚在所谓“推迟联编”或者“动态联编”上,一个类函数的调用并不是在编译时刻被确定的,而是在运行时刻被确定的。由于编写代码的时候并不能确定被调用的是基类的函数还是哪个派生类的函数,所以被成为“虚”函数。C++中普通成员函数加上virtual关键字就成为虚函数。Java中其实没有虚函数的概念,它的普通函数就相当于C++的虚函数,动态绑定是Java的默认行为。
1public abstract class A {
2 public abstract eat();
3}
4
5public class B extends A {
6 override public eat() {}
7}
8public class C extends A {
9 override public eat() {}
10}
11
12A b = new B();
13b.eat();
例如上面的代码,当你在调用b.eat()时,编译器不知道应该调用A类的哪个实现。要想知道,就必 须查看vtable。vtable 是一个包含所有虚函数的结构。对于每个虚函数条目,它都存储一个指向此函数定义的指针。虚函数分派使用每个类下的 vpointer,进入对应的虚表,最后才解析要执行的代码。但是如果在整个代码动态生成的情况下,由于一切都发生在明确定义实现的 一个类中,因此不存在虚函数。
那么我们再来看下动态代码生成带来的另一个优势。
3.2 内存中的中间数据与 CPU 寄存器
在迭代器模型(火山模型)中,每次操作符将元组传递给另一个操作符时,都需要将元组放入内存(函数调用堆栈),即需要保存在内存复杂处理信息。例如,表扫描的算子在处理一个压缩的数据表时,在迭代的模式下,需要每次产生一个数据元组,因此表扫描算子中需要记录当前数据元组在压缩数据流中的位置,以便根据压缩方式跳转到下一条数据元组的位置。
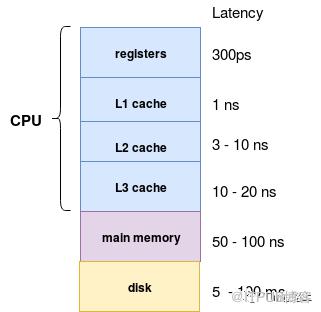
但是在动态代码生成中,编译器实际上将中间数据放在 CPU 寄存器中。同样,CPU 访问内存中的数据所花费的周期数比寄存器中的大几个数量级。
此外对于进行动态生成后的代码,更有利于编译器和 CPU 的优化。
3.3 循环展开和 SIMD
现代编译器和 CPU 在编译和执行简单的 for 循环时非常高效。编译器通常可以自动展开简单循环,甚至生成 SIMD 指令来处理每个 CPU 指令的多个元组。CPU 包括流水线、预取和指令重新排序等特性,这些特性使执行简单循环变得高效。然而,这些编译器和 CPU 并不擅长优化 Volcano 模型所依赖的复杂函数调用图。
循环展开功能属于时间-空间权衡系列,因为它以减少的执行时间换取增加的函数大小。这意味着像这样的 for 循环:
1for (i = 0; i < 100; i++):
2 do_something(i)
可以由编译器重写为这种优化的(循环展开)形式:
1for (i = 0; i < 100; i += 2):
2 do_something(i)
3 do_something(i+1)
除上面的以外,在动态生成代码中的每一条指令都是明确的,可以顺序加载到 CPU 寄存器,源数据也可以顺序地加载到 CPU 的各级缓存中,从而大幅提升了 CPU 的工作效率。
长话短说,下面我们先来简单了解了WSCG的生成过程,后面我们在单独篇幅介绍。
3.4 WSCG是如何动态生成代码的?
首先在本质上,WSCG 机制的工作过程就是基于一份“性能较差的代码”,在运行时动态地重构出一份“性能更好的代码”。
WSCG 是如何在运行时动态生成代码的?问题来了,WSCG 是怎么在运行时动态生成代码的呢?
我们都知道一条SparkSQL最终也会被转换为一种RDD, 其过程分别要经过两个阶段。
逻辑计划;2. 物理计划。
SQLQuery → Unresolved LogicalPlan → Analyzed LogicalPlan → Optimized LogicalPlan (逻辑计划阶段)→ Iterator PhysicalPlan → SparkPlan → Prepared SparkPlan → RDD (物理计划阶段)
如上图所示逻辑计划阶段会将SQL转换为逻辑算子数,将其作为一种中间态;物理计划阶段会将逻辑计划转换为物理算子树,树节点会直接对应生成RDD或者是RDD的转换。
在Spark Plan 在转换成 Physical Plan 之前,会应用一系列的 Preparation Rules。这其中很重要的一环就是 CollapseCodegenStages 规则,它的作用正是尝试为每一个 Stages 生成“手写代码”。
总的来说,手写代码的生成过程分为两个步骤:
从父节点到子节点,递归调用 doProduce,生成代码框架
从子节点到父节点,递归调用 doConsume,向框架填充每一个操作符的运算逻辑
总结
Tungsten是针对spark cpu瓶颈的一揽子Runtime的优化策略,其中最主要的是内存管理和二进制处理,缓存感知计算以及代码生成。
在内存管理和二进制处理上,主要针对的是Java对象占用内存的空间大和Jvm垃圾回收的开销大的问题,Spark引入了基于二进制数组存储的UnsafeRow,它将所有的对象和数据存储为二进制数组,避免了大量java对象的创建,降低 GC 压力。此外Tungsten统一管理 Off Heap 和 On Heap 内存空间, 并基于此重新实现了自定义的Map等数据结构,进一步提升数据存储效率与 GC 效率。
在缓存敏感计算上,Tungsten通过设计缓存优化的数据结构来提高缓存的命中率,常规的对两个record 比较时,会先根据指针定位到实际数据,用拿到的实际数据进行比较。Tungsten在存储record的指针时同时会存储数据的前缀,以key为前缀,避免内存的随机访问。
在动态代码生成上,传统的基于迭代的火山模型,存在大量虚函数的调用,需要保存复杂处理信息,以及随机存取和中间数据需要物化到内存的问题。基于此Spark开始基于向量化和动态代码生成来摆脱火山模型。Tungsten 利用 CollapseCodegenStages 规则,经过两层递归调用把 Catalyst 输出的 Spark Plan 加工成了一份“手写代码”,并把这份手写代码会交付给 DAGScheduler。拿到代码之后,DAGScheduler 再去协调自己的两个小弟 TaskScheduler 和 SchedulerBackend,完成分布式任务调度。
下面我们会着重再介绍Codegen。