DPP(Dynamic Partition Pruning,动态分区剪裁)是 Spark 3.0引入的非常重要的特性,相对于AQE默认关闭的策略来说,DPP在引入之初就是开启的。
DPP指的是在大表Join小表的场景中,可以充分利用过滤之后的小表,在运行时动态的来大幅削减大表的数据扫描量,从整体上提升关联计算的执行性能。
什么是分区剪裁?
分区剪裁是谓词下推的一种特例,它指的是在分区表中下推谓词,并以文件系统目录为单位对数据集进行过滤,即Spark SQL 对分区表做扫描的时候,是完全可以跳过(剪掉)不满足谓词条件的分区目录,这就是分区剪裁。
例如,在我们的查询语句中,对日志表设置过滤谓词dt >= '2022-08-01',日志表一般是以dt作为分区的,那么在扫描Hive分区表时,可以直接过滤掉小于 '2022-08-01'文件目录。从这里可以看出相比于分区过滤,谓词下推只能算是“小巫见大巫”了。
动态分区剪裁
那么动态分区剪裁又是怎么实现的呢?它背后的逻辑是什么呢?我们来举个例子:
1SELECT t1.id, t2.part_column FROM table1 t1
2 JOIN table2 t2 ON t1.part_column = t2.part_column
3 WHERE t2.id < 5
如上述SQL, t1为大表,t2为小表,两表基于分区列进行join, 同时还存在对小表的过滤扫描。
在没有开启DPP的情况下,执行上述语句需要扫描完整的t1表,这是因为t2.id < 5只是对小表进行了过滤。
那么在开启DPP的它是如何转换的?
首先,由于存在过滤条件( t2.id < 5),它会帮助t2表过滤掉部分数据。与此同时,t2表对应的t2.part_column字段也顺带着经过一轮筛选。
然后,在Join的关联关系 t1.part_column = t2.part_column的作用下,过滤效果会通过 小表t2.part_column 字段传导到大表的 t1.part_column字段。这样一来,传导后的t1.part_column值,就是大表 part_column 全集中的一个子集。把满足条件的 t1.part_column作为过滤条件,应用到大表的数据源,就可以做到减少数据扫描量,提升 I/O 效率。
总而言之,DPP 正是基于上述逻辑实现的,用电商场景来说就是把维度表中的过滤条件,通过关联关系传导到事实表,从而完成事实表的优化。
DPP源码分析
虽然 DPP 是默认就开启的,但并不是所有的数据关联场景都可以享受到 DPP 的优化机制,想要利用 DPP 来加速大表数据的读取和访问,数据关联场景还要满足三个额外的条件。
DPP 是一种分区剪裁机制,它是以分区为单位对大表进行过滤,所以说大表必须是分区表,而且分区字段(可以是多个)必须包含 Join Key。
过滤效果的传导,依赖的是等值的关联关系,比如 t1.part_column = t2.part_column。因此,DPP 仅支持等值 Joins。
执行动态分区过滤必须是收益的,DPP 优化机制才能生效。
下面我们从源码来看看:
(1)DPP的引入和应用需要满足的条件
DPP的逻辑引入是在SparkOptimizer优化器中,以规则的形式进行引入的。其主要实现包含在PartitionPruning逻辑优化规则中。
1override def apply(plan: LogicalPlan): LogicalPlan = plan match {
2 // Do not rewrite subqueries.
3 case s: Subquery if s.correlated => plan
4 case _ if !conf.dynamicPartitionPruningEnabled => plan
5 case _ => prune(plan)
6}
目前DPP的开关是默认开启,另外从上面的代码可以看出其是不会应用到相关的子查询上的。下面我们专注于看下prune(plan)里发生了什么?
1private def prune(plan: LogicalPlan): LogicalPlan = {
2 plan transformUp {
3 // [1] 跳过子查询中包含DPP的情况
4 // skip this rule if there's already a DPP subquery on the LHS of a join
5 case j @ Join(Filter(_: DynamicPruningSubquery, _), _, _, _, _) => j
6 case j @ Join(_, Filter(_: DynamicPruningSubquery, _), _, _, _) => j
7 case j @ Join(left, right, joinType, Some(condition), hint) =>
8 var newLeft = left
9 var newRight = right
10
11 // [2] 提取出等值Join的左右join keys
12 // extract the left and right keys of the join condition
13 val (leftKeys, rightKeys) = j match {
14 case ExtractEquiJoinKeys(_, lkeys, rkeys, _, _, _, _, _) => (lkeys, rkeys)
15 case _ => (Nil, Nil)
16 }
17
18 // checks if two expressions are on opposite sides of the join
19 def fromDifferentSides(x: Expression, y: Expression): Boolean = {
20 def fromLeftRight(x: Expression, y: Expression) =
21 !x.references.isEmpty && x.references.subsetOf(left.outputSet) &&
22 !y.references.isEmpty && y.references.subsetOf(right.outputSet)
23 fromLeftRight(x, y) || fromLeftRight(y, x)
24 }
25
26 // [3] 遍历查询条件谓词,使用 DPP 优化
27 splitConjunctivePredicates(condition).foreach {
28 case EqualTo(a: Expression, b: Expression)
29 if fromDifferentSides(a, b) =>
30 val (l, r) = if (a.references.subsetOf(left.outputSet) &&
31 b.references.subsetOf(right.outputSet)) {
32 a -> b
33 } else {
34 b -> a
35 }
36 // 这里区分左表和右表
37 // there should be a partitioned table and a filter on the dimension table,
38 // otherwise the pruning will not trigger
39 var filterableScan = getFilterableTableScan(l, left)
40 // filterableScan定义表示是否可以分区列剪裁,canPruneLeft是否能剪裁左, hasPartitionPruningFilter能进行剪裁分区
41 if (filterableScan.isDefined && canPruneLeft(joinType) &&
42 hasPartitionPruningFilter(right)) {
43 // 插入谓词
44 newLeft = insertPredicate(l, newLeft, r, right, rightKeys, filterableScan.get)
45 } else {
46 filterableScan = getFilterableTableScan(r, right)
47 if (filterableScan.isDefined && canPruneRight(joinType) &&
48 hasPartitionPruningFilter(left) ) {
49 newRight = insertPredicate(r, newRight, l, left, leftKeys, filterableScan.get)
50 }
51 }
52 case _ =>
53 }
54 Join(newLeft, newRight, joinType, Some(condition), hint)
55 }
56}
从上面的源码中,可以看出主要为下面几步:
[1] 跳过子查询中包含DPP的情况
[2] 提取出等值Join的左右join keys
[3] 遍历查询条件谓词,进行校验可以应用的条件,最后插入 DPP 优化谓词。
在插入谓词前其校验条件主要为,
filterableScan变量表示的是连接的列是否是分区列。
canPruneLeft表示的是能否进行对左表进行剪裁,满足左表剪裁的情况只有Inner 、LeftSemi 、RightOuter的情况。
hasPartitionPruningFilter表示的是你不能在Stream应用程序上应用 DDP, 逻辑计划必须知道选择性谓词的定义,即为下面的代码定义。
1private def hasPartitionPruningFilter (plan: LogicalPlan ): Boolean = {
2 !plan.isStreaming && hasSelectivePredicate(plan)
3}
4
5def isLikelySelective(e: Expression): Boolean = e match {
6 case Not(expr) => isLikelySelective(expr)
7 case And(l, r) => isLikelySelective(l) || isLikelySelective(r)
8 case Or(l, r) => isLikelySelective(l) && isLikelySelective(r)
9 case _: StringRegexExpression => true
10 case _: BinaryComparison => true
11 case _: In | _: InSet => true
12 case _: StringPredicate => true
13 case BinaryPredicate(_) => true
14 case _: MultiLikeBase => true
15 case _ => false
16 }
(2)在Join的一侧插入DPP谓词,另一侧使用Filter过滤
实际上除了需要上述校验条件外,还需要满足一个条件。此外就是自定义了被包装为正则In表达式的DynamicRunning。下面我们直接来看下insertPredicate的实现:
1private def insertPredicate(
2 pruningKey: Expression,
3 pruningPlan: LogicalPlan,
4 filteringKey: Expression,
5 filteringPlan: LogicalPlan,
6 joinKeys: Seq[Expression],
7 partScan: LogicalPlan): LogicalPlan = {
8 // 如果exchange重用是开启的
9 val reuseEnabled = conf.exchangeReuseEnabled
10 val index = joinKeys.indexOf(filteringKey)
11 // 判断剪裁是否有收益
12 lazy val hasBenefit = pruningHasBenefit(pruningKey, partScan, filteringKey, filteringPlan)
13 // 如果开启重用exchange或有收益侧插入一个Filter的过滤子查询算子
14 if (reuseEnabled || hasBenefit) {
15 // insert a DynamicPruning wrapper to identify the subquery during query planning
16 Filter(
17 DynamicPruningSubquery(
18 pruningKey,
19 filteringPlan,
20 joinKeys,
21 index,
22 conf.dynamicPartitionPruningReuseBroadcastOnly || !hasBenefit),
23 pruningPlan)
24 } else {
25 // abort dynamic partition pruning
26 pruningPlan
27 }
28}
在 hasBenefit 中,Spark检查应用 DPP 是否比保持查询不变更有益。这由以下公式控制:
1// 剪枝开销是所有扫描关系的总大小(以字节为单位)
2val overhead = otherPlan.collectLeaves().map(_.stats.sizeInBytes).sum.toFloat
3
4filterRatio * partPlan.stats.sizeInBytes.toFloat > overhead.toFloat
我们假设Join的右侧表有 10MB 的数据,并且过滤器比率是默认值(0.5)。对于该配置,如果Join的左侧大于 20MB,则使用 DPP 将被视为有益。当然当CBO的统计信息可以用时,会使用统计信息计算过滤比。
1val partDistinctCount = distinctCounts(leftAttr, partPlan)
2 val otherDistinctCount = distinctCounts(rightAttr, otherPlan)
3 val availableStats = partDistinctCount.isDefined && partDistinctCount.get > 0 &&
4 otherDistinctCount.isDefined if (!availableStats) {
5 fallbackRatio
6} else if (partDistinctCount.get.toDouble <= otherDistinctCount.get.toDouble) {
7 // 可能存在估计错误,所以我们回退
8 fallbackRatio
9} else {
10 1 - otherDistinctCount.get.toDouble / partDistinctCount.get.toDouble
11}
(3) 物理计划中执行DynamicPruningSubquery
首先,我们来看下定义DynamicPruningSubquery时的传参,从下面可以看出:
1case class DynamicPruningSubquery(
2 pruningKey: Expression,
3 buildQuery: LogicalPlan,
4 buildKeys: Seq[Expression],
5 broadcastKeyIndex: Int,
6 onlyInBroadcast: Boolean,
7 exprId: ExprId = NamedExpression.newExprId)
下面我们来关注下onlyInBroadcast参数。当onlyInBroadcast设置为false时,表示剪枝过滤器可能是有益的,因此即使不能通过重用交换重用广播结果,也应执行剪枝过滤器;否则,仅当它可以通过ReuseeExchange重用广播结果时,才会使用过滤器。
那么onlyInBroadcast的传参是怎样的?从上面的可看出onlyInBroadcast的参数为
conf.dynamicPartitionPruningReuseBroadcastOnly || !hasBenefit 。
其次,在物理计划中DPP主要是在preparations阶段进行调用的,其内容封装为PlanDynamicPruningFilters(sparkSession)规则中。
我们来看下其是如何执行的?
1case DynamicPruningSubquery(
2 value, buildPlan, buildKeys, broadcastKeyIndex, onlyInBroadcast, exprId) =>
3 val sparkPlan = QueryExecution.createSparkPlan(
4 sparkSession, sparkSession.sessionState.planner, buildPlan)
5 // Using `sparkPlan` is a little hacky as it is based on the assumption that this rule is
6 // the first to be applied (apart from `InsertAdaptiveSparkPlan`).
7 // 能否重用exchange的前提是开启开关,同时plan中存在BroadcastHashJoinExec
8 val canReuseExchange = conf.exchangeReuseEnabled && buildKeys.nonEmpty &&
9 plan.exists {
10 case BroadcastHashJoinExec(_, _, _, BuildLeft, _, left, _, _) =>
11 left.sameResult(sparkPlan)
12 case BroadcastHashJoinExec(_, _, _, BuildRight, _, _, right, _) =>
13 right.sameResult(sparkPlan)
14 case _ => false
15 }
16 // [1] 如果可以重用Exchange, 重用BroadcastExchange封装DynamicPruningExpression表达式放到probe一侧
17 if (canReuseExchange) {
18 val executedPlan = QueryExecution.prepareExecutedPlan(sparkSession, sparkPlan)
19 val mode = broadcastMode(buildKeys, executedPlan.output)
20 // plan a broadcast exchange of the build side of the join
21 val exchange = BroadcastExchangeExec(mode, executedPlan)
22 val name = s"dynamicpruning#${exprId.id}"
23 // place the broadcast adaptor for reusing the broadcast results on the probe side
24 val broadcastValues =
25 SubqueryBroadcastExec(name, broadcastKeyIndex, buildKeys, exchange)
26 DynamicPruningExpression(InSubqueryExec(value, broadcastValues, exprId))
27 // [2] 如果onlyInBroadcast为true, 执行动态剪裁查询是不值得的,回退
28 } else if (onlyInBroadcast) {
29 // it is not worthwhile to execute the query, so we fall-back to a true literal
30 DynamicPruningExpression(Literal.TrueLiteral)
31 } else {
32 // [3] 如果onlyInBroadcast为false, 需要在buildPlan上应用聚合,然后封装为DynamicPruningExpression
33 // we need to apply an aggregate on the buildPlan in order to be column pruned
34 val alias = Alias(buildKeys(broadcastKeyIndex), buildKeys(broadcastKeyIndex).toString)()
35 val aggregate = Aggregate(Seq(alias), Seq(alias), buildPlan)
36 DynamicPruningExpression(expressions.InSubquery(
37 Seq(value), ListQuery(aggregate, childOutputs = aggregate.output)))
38 }
下面我们来梳理下DynamicPruningSubquery的具体的执行过程。从上面的代码可以看出,这里分为三种情况:
[1] 如果当前开启了exchangeReuseEnabled,同时Plan中存在BroadcastHashJoinExec,则会重用当前的BroadcastExchangeExec,并将其封装为一个InSubqueryExec,最后再包装为DynamicPruningExpression表达式。其类似于下面的场景:
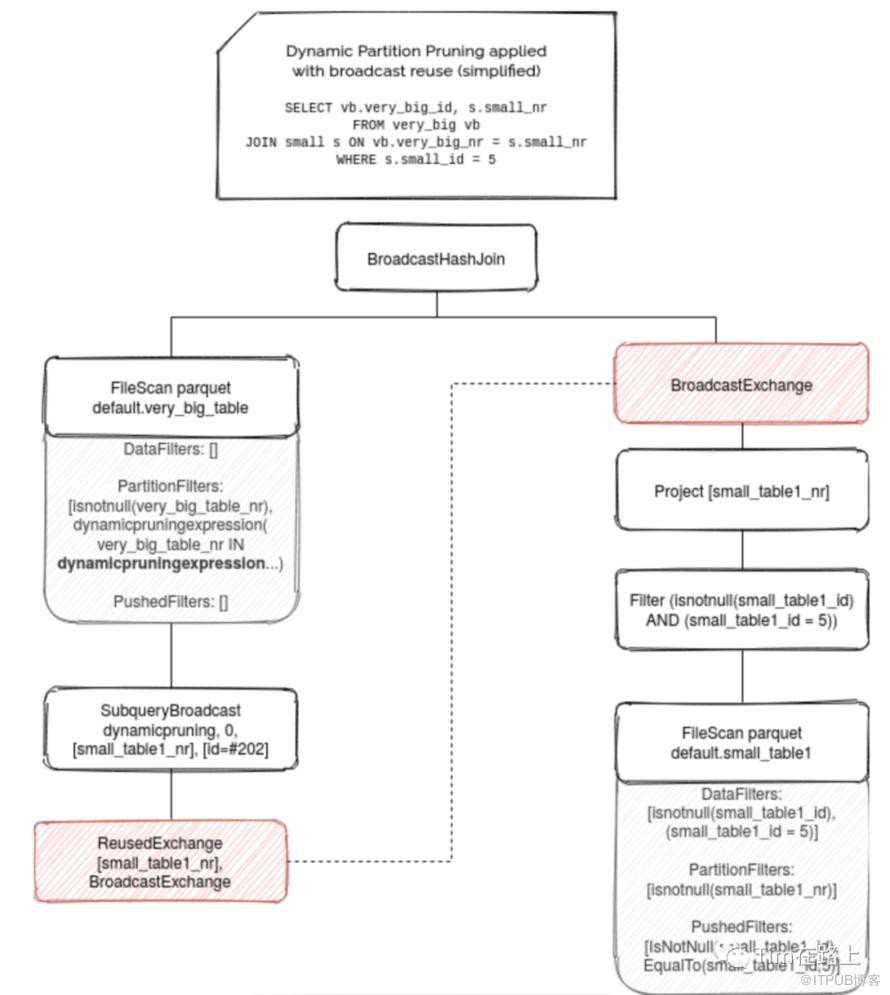
[2] 如果onlyInBroadcast为false, 表明要么是reuseBroadcastOnly设为false(即非broadcast exchange时也可使用), 要么是有收益。首先,需要按照需要过滤的key做一次聚合操作, 然后再将其封装为一个InSubqueryExec,最后包装为DynamicPruningExpression表达式。
[3] 否则,不会执行Query, 执行回退。
相关配置
1spark.sql.optimizer.dynamicPartitionPruning.enabled=true; # 其默认值就是true, spark3 默认是开启DPP的
2spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly=true; # 默认是true,这时只会在动态修剪过滤器中重用BroadcastExchange时,才会应用 DPP,如果设置为false可以在非Broadcast场景应用DPP。
3spark.sql.optimizer.dynamicPartitionPruning.useStats=true; # 如果为true,则将使用不同计数统计信息来计算动态分区修剪后分区表的数据大小,以评估在广播重用不适用的情况下是否值得添加额外的子查询作为修剪过滤器。
4spark.sql.optimizer.dynamicPartitionPruning.fallbackFilterRatio=0.5; # 当统计信息不可用或配置为不使用时,此配置将用作回退过滤器比率,用于计算动态分区修剪后分区表的数据大小,以评估在广播重用不适用的情况下是否值得添加额外的子查询作为修剪过滤器
总结
下面我们来总结下:
动态分区剪裁运作的背后逻辑,就是把小表中的过滤条件,通过关联关系传导到大表。虽然DPP默认在Spark3是开启的,但是要用动态分区剪裁特性还需满足以下四个特性:
大表必须是分区表,并且分区字段必须包含 Join Key;
只支持等值 Joins,不支持大于、小于这种不等值关联关系;
小表存在过滤谓词;
执行动态分区过滤必须是收益的,简单来说大表在乘以过滤比后其大小仍要大于小表。
分区过滤的实现是在逻辑计划的Optimizer阶段,通过注入PartitionPruning规则,将满足条件的待剪裁侧plan中插入自定义了被包装为正则In表达式的DynamicRunning表达式。在物理计划的preparations阶段中,调用PlanDynamicPruningFilters规则,根据是否可以重用broadcast,和是否只支持broadcast来区分具体的执行实现,具体为:
如果当前开启了exchangeReuseEnabled,同时Plan中存在BroadcastHashJoinExec,则会重用当前的BroadcastExchangeExec,并将其封装为一个InSubqueryExec,再包装为DynamicPruningExpression表达式。
如果onlyInBroadcast为false, 表明要么是reuseBroadcastOnly设为false(即非broadcast exchange时也可使用), 要么是有收益。则先按照需要过滤的key做一次聚合, 然后将其封装为一个InSubqueryExec,再包装为DynamicPruningExpression表达式。
否则,不会执行Query, 执行回退。