数据湖架构的其中一个目的就是让负责批量写入的存储系统也能支持实时的写入的能力,这样可以将存储层统一起来,减少运维花费。但是要建立“流式数仓”,就需要支持update和delete的功能。这是由于实时计算数据不如批处理那样完整和准确,例如存在迟到的数据。
目前在数据湖架构中有两种写入方式,分别是COW(copy on write)和MOR(merge on read)。COW,顾名思义,就是在进行update时先将要更新的数据文件进行copy, 再对其内容进行更新后,再写入新的文件。MOR是指直接写入新的文件,在读取时再将delta文件与base文件进行合并。
其中在本质上来说,COW和MOR是一致的,MOR是延迟了copy和merge的实现。这也就造就了COW适合读行为较多的场景,而MOR适合写较多的场景。
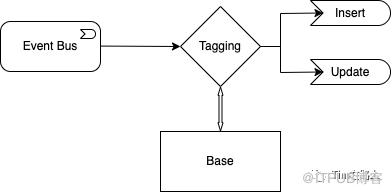
其实不论是COW还是MOR, 在流式数仓中都需要tagging和merge的操作。如果上图所示当Upsert事务到来的时候,首先需求从base数据库中进行查找,判断这是一个insert操作还是update操作,如果没有重复数据,则追加写入文件,否则需要拷贝,再对其内容进行更新后,再写入新的文件(COW)。
下面我们以Hudi的upsert过程进行举例,来分析下其中的性能消耗点:
Hudi中的Upsert
Hudi也是采用元数据日志基于地址链接的snapshot来维护自己的数据的。它的元数据文件存储在隐藏目录.hoodie中,数据文件则是和Hive类似采用分区目录的形式进行组织。每个分区文件被分为多个文件组,用一个fileid进行标识。每个文件组包含几个文件切片,每个切片都包含一个在某个提交/压缩瞬间生成的base文件 (.parquet),以及一组日志文件 ( .log)。其文件的命令方式fileid+time。
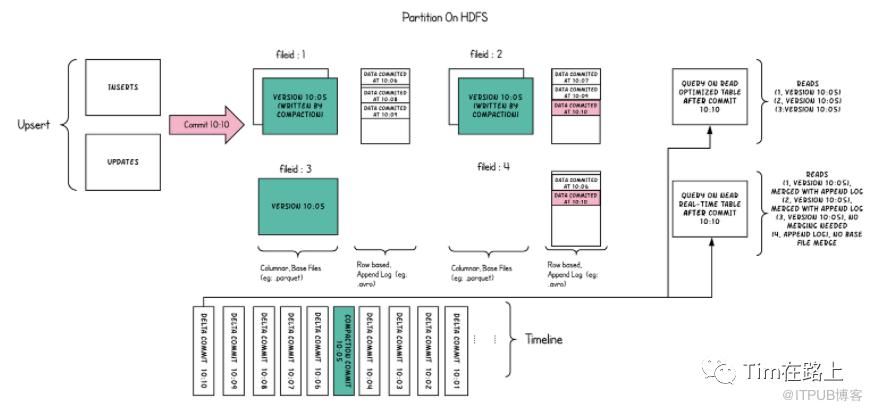
Hudi在upsert时将要更改的内容写入log文件中,然后定期的将log文件和base文件进行合并。
Upsert的总体过程为:
根据partitionPath进行重写分区,partitionPath相同的就会被分到同一个分区中,并交给一个executor负责写入。这是因为分区间是相互隔离的可以通过重分区,将之后的操作进行并发提效。
在record的分区确定后,根据recordKey确定哪些记录是update,哪些记录是insert。如果是update操作,则需要定位到上次写入的fileid(文件组id)。那么如何判断是否是update呢?首先, 这里的recordKey是用户写入时指定的,Hudi使用recordKey与base的数据进行比对,如果找到key相同的就record则认为这次的写入是update,否则是insert。这个查询的过程就是tagging。当然在已有的数据中找寻相同的key是非常耗时的,所以Hudi引入了索引。另对于update的record在写入时会拷贝原有的旧的文件的fileid, 用其生成新的文件。
写入文件的过程分insert和update两部分,update会使用原来的fileid进行写入,insert会生成新的fileid(uuid)进行写入。如果是cow的方式则会拷贝原来的文件,并将其与新update数据进行merge后写入。如果是MOR则是将update数据直接写入,然后再异步的进行merge。
下面我们来详细分析下其中的过程,是否存在优化空间?
可以说upsert或者delete都免不了两个过程:1. 定位操作文件;2. 合并更新文件。
在定位文件,也就是tagging过程中是非常耗时的,我们需要找到当前的操作要影响哪些文件,然后再读取文件中的key进行依次对比。如果在查找中可以跳过绝大部分的文件,那么其效率也就会变的很高。如何跳过绝大部分文件呢?
min-max索引。不论是Delta Lake、Hudi还是Iceberg, 其中都存在min-max索引,但是如果数据分布是比较均匀的,即每个文件文件列的upper_bounds和lower_bounds的range很大,那么min-max索引其实是失效的。但如果文件已排序的, 则其会非常高效的。
BloomFilter索引,BloomFilter虽然可以快速的判断record是否在文件中, 但其存在假阳性的问题,如果随着数据量的增加,其性能也是下降的。
在合并文件,合并文件的过程实质上就是join的过程。
最高效的过程当然是BHJ(Broadcast Hash Join), 但是其需要满足delta数据可以装入内存进行广播。
所以最常用的还是SMJ (Sort Merge Join), SMJ进行合并是代价比较大的,但如果数据的组织方式原本是有序的其实现也会变的高效。
合并文件的优化先按下不表,我们先来看看tagging的过程:
从上面可以看出在Tagging的过程中min-max要求数据的分布最好是有序的,BloomFilter不能处理数据过大的场景,也存在假阳性的问题。当然这里可以通过带范围的拆分来获得更小范围BloomFilter。但是在分区过多,大量随机更新的场景下,无法通过比较范围/过滤器来修剪大量文件,则 Bloom索引仍然存在性能下降和假阳性的问题。
那么当数据分区过多,数据量过大的场景下如何进行tagging?有没有一种数据结构写入后就是有序的,同时支持快速查找和数据的落盘,这当然就是LSM了。
LSM 的重要特点是区域有序,合并写入。所以当数据写入到内存中的时就会通知数据成功写入。而在数据落盘的时候,数据会以片段的形式写入磁盘, 它极大的利用磁盘顺序IO的特性。
我们先来看下Hbase是如何实现的?其查询性能如何?
Hbase的原理
Apache HBase是Hadoop生态系统中的分布式数据存储系统。它是根据Google的Bigtable设计建模的。HBase基于主从架构,将数据集划分(散列或范围)为一组区域,每个区域均由LSM树管理。HBase支持动态区域拆分和合并,以根据给定的工作负载弹性管理系统资源。在这里,我们重点介绍HBase的存储引擎。
HBase的LSM-tree的实现是基于Tiering合并策略,它通过批量存储技术优化了随机IO的问题来提升性能。LSM-tree天然是有序的,其实现了LSM-树众所周知的优化方法布隆过滤器和分区。
今天的LSM-tree更新仍然是追加到内存然后新写一个文件的形式,而不是直接更改原来的数据,这样通过顺序I/O来提升写性能。LSM树实现通常使用并发数据结构(如skip-list或B +树)来组织其内存组件,而它们使用B +树或排序字符串表(SSTables)来组织其磁盘组件。SSTable包含一个数据块列表和一个索引块;数据块存储按键排序的键值对,而索引块存储所有数据块的键范围。
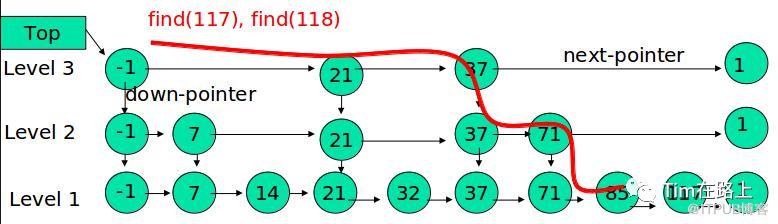
内存用skip-list实现LSM的内存
HBase中对LSM树的实现,是在内存中用一个ConcurrentSkipListMap保存数据。数据写入时,直接写入MemStore中。随着不断写入,一旦内存占用超过一定的阈值时,就把内存部分的数据导出,形成一个有序的数据文件,存储在磁盘上。
跳跃表可以看作是一种特殊的有序链表。跳跃表是由多层有序链表组成。最底一层的链表保存了所有的数据,为了提高链表的查询效率,通过每向上的一层链表依次保存下一层链表的部分数据作为索引,采用空间换取时间等方式提高效率。
2. 磁盘用多路归并实现LSM树的文件合并
随着写入的增加,内存数据会不断地刷新到磁盘上。最终磁盘上的数据文件会越来越多。如果用户有读取请求,则需要将大量的磁盘文件进行多路归并,之后才能读取到所需的数据。LSM树的索引实际上是将写入操作全部转化为了磁盘的顺序写入,提高了写入性能。但是,这种设计是以牺牲一定的读操作性能为代价的,因为读取的时候,需要归并多个文件来获取满足条件的KV,非常消耗磁盘IO。所以,我们知道HBase会通过compaction来合并小文件,降低文件个数,来提高读取效率。
总而言之,Hbase使用跳表实现的LSM,同时其可以通过分层解决数据倾斜和减少写放大,在查询时使用bloomFilter优化点查,可以在大数据量的情况下加速tagging的过程。
下面我们通过源码分析下HbaseIndex实现的过程:
Hudi之HBaseIndex的实现源码
SparkHoodieHBaseIndex是HoodieIndex的子类实现,其主要有两个方法tagLocation()和updateLocation(),分别是tagging的过程和更新索引的过程。
在进行数据写入的时候Hudi会调用tagLocation给输入记录打位置标签。
1@Override
2public HoodieData> tagLocation(
3 HoodieData> records, HoodieEngineContext context,
4 HoodieTable hoodieTable) {
5 return HoodieJavaRDD.of(HoodieJavaRDD.getJavaRDD(records)
6 .mapPartitionsWithIndex(locationTagFunction(hoodieTable.getMetaClient()), true));
7}
可以看到该方法主要使用了locationTagFunction函数来处理原始记录,下面我们来看看其具体实现:
1private Function2Iterator>, Iterator>> locationTagFunction(
2 HoodieTableMetaClient metaClient) {
3
4 // 每次取的批次大小
5 Integer multiGetBatchSize = config.getHbaseIndexGetBatchSize();
6 return (Function2Iterator>, Iterator>>) (partitionNum,
7 hoodieRecordIterator) -> {
8
9 boolean updatePartitionPath = config.getHbaseIndexUpdatePartitionPath();
10 // 限制每秒的查询
11 RateLimiter limiter = RateLimiter.create(multiGetBatchSize * 10, TimeUnit.SECONDS);
12 // [1] 获取HBase连接, 并获取配置的表
13 synchronized (SparkHoodieHBaseIndex.class) {
14 if (hbaseConnection == null || hbaseConnection.isClosed()) {
15 hbaseConnection = getHBaseConnection();
16 }
17 }
18 List> taggedRecords = new ArrayList<>();
19 // 获取配置的表
20 try (HTable hTable = (HTable) hbaseConnection.getTable(TableName.valueOf(tableName))) {
21 List statements = new ArrayList<>();
22 List currentBatchOfRecords = new LinkedList<>();
23 // [2] 遍历该分区上的记录, 根据批量recordKey进行查找
24 while (hoodieRecordIterator.hasNext()) {
25 HoodieRecord rec = hoodieRecordIterator.next();
26 // 根据recordKey生成Get
27 statements.add(generateStatement(rec.getRecordKey()));
28 currentBatchOfRecords.add(rec);
29 // iterator till we reach batch size
30 if (hoodieRecordIterator.hasNext() && statements.size() < multiGetBatchSize) {
31 continue;
32 }
33 // get results for batch from Hbase
34 Result[] results = doGet(hTable, statements, limiter);
35 // clear statements to be GC'd
36 statements.clear();
37 for (Result result : results) {
38 // first, attempt to grab location from HBase
39 HoodieRecord currentRecord = currentBatchOfRecords.remove(0);
40 if (result.getRow() == null) {
41 taggedRecords.add(currentRecord);
42 continue;
43 }
44 // [3] 如果之前数据存在返回值,取出key, commit时间,fileID和分区路径
45 String keyFromResult = Bytes.toString(result.getRow());
46 String commitTs = Bytes.toString(result.getValue(SYSTEM_COLUMN_FAMILY, COMMIT_TS_COLUMN));
47 String fileId = Bytes.toString(result.getValue(SYSTEM_COLUMN_FAMILY, FILE_NAME_COLUMN));
48 String partitionPath = Bytes.toString(result.getValue(SYSTEM_COLUMN_FAMILY, PARTITION_PATH_COLUMN));
49 if (!checkIfValidCommit(metaClient, commitTs)) {
50 // if commit is invalid, treat this as a new taggedRecord
51 taggedRecords.add(currentRecord);
52 continue;
53 }
54 // [4] 校验是否要改变分区, 如果要改变分区创建新的Record,设置分区和位置信息,并间分区插入新的数据record,标记为已打完标签
55 if (updatePartitionPath && !partitionPath.equals(currentRecord.getPartitionPath())) {
56 // delete partition old data record
57 HoodieRecord emptyRecord = new HoodieRecord(new HoodieKey(currentRecord.getRecordKey(), partitionPath),
58 new EmptyHoodieRecordPayload());
59 emptyRecord.unseal();
60 // 设置位置信息
61 emptyRecord.setCurrentLocation(new HoodieRecordLocation(commitTs, fileId));
62 emptyRecord.seal();
63 // insert partition new data record
64 currentRecord = new HoodieRecord(new HoodieKey(currentRecord.getRecordKey(), currentRecord.getPartitionPath()),
65 currentRecord.getData());
66 taggedRecords.add(emptyRecord);
67 taggedRecords.add(currentRecord);
68 // [5] 否则,更新位置信息,标记为已打完标签
69 } else {
70 currentRecord = new HoodieRecord(new HoodieKey(currentRecord.getRecordKey(), partitionPath),
71 currentRecord.getData());
72 currentRecord.unseal();
73 currentRecord.setCurrentLocation(new HoodieRecordLocation(commitTs, fileId));
74 currentRecord.seal();
75 taggedRecords.add(currentRecord);
76 // the key from Result and the key being processed should be same
77 assert (currentRecord.getRecordKey().contentEquals(keyFromResult));
78 }
79 }
80 }
81 } catch (IOException e) {
82 throw new HoodieIndexException("Failed to Tag indexed locations because of exception with HBase Client", e);
83 }
84 return taggedRecords.iterator();
85 };
86}
tagging过程主要为以下步骤:
[1] 获取HBase连接, 并获取配置的表
[2] 遍历该分区上的记录, 根据批量recordKey进行查找
[3] 如果之前数据存在返回值,取出key, commit时间,fileID和分区路径,无返回值则标记结束
[4] 校验是否要改变分区, 如果要改变分区创建新的Record,设置分区和位置信息,并为分区插入新的数据record,标记为已打完标签
[5] 否则,更新位置信息,标记为已打完标签
看到从HBase中取位置信息流程非常简单,即遍历指定分区上所有记录,然后批量生成recordKey从HBase索引表取对应的信息,然后生成位置信息。
那么更新记录的位置信息又是如何实现的,我们来看下updateLocation方法。
1@Override
2public HoodieData updateLocation(
3 HoodieData writeStatus, HoodieEngineContext context,
4 HoodieTable hoodieTable) {
5 // [1] 根据写完数据后状态来计算QPS比例,并生成Allocator
6 JavaRDD writeStatusRDD = HoodieJavaRDD.getJavaRDD(writeStatus);
7 // 如果开启了PUT_BATCH_SIZE_AUTO_COMPUTE则会进行计算QPSFraction,这里是通过获取insert数和并发数进行计算
8 final Option<Float> desiredQPSFraction = calculateQPSFraction(writeStatusRDD);
9 // 获取每个fileid,去重后对应分区数
10 final Map fileIdPartitionMap = mapFileWithInsertsToUniquePartition(writeStatusRDD);
11 JavaRDD partitionedRDD = this.numWriteStatusWithInserts == 0 ? writeStatusRDD :
12 writeStatusRDD.mapToPair(w -> new Tuple2<>(w.getFileId(), w))
13 .partitionBy(new WriteStatusPartitioner(fileIdPartitionMap,
14 this.numWriteStatusWithInserts))
15 .map(w -> w._2());
16 JavaSparkContext jsc = HoodieSparkEngineContext.getSparkContext(context);
17 acquireQPSResourcesAndSetBatchSize(desiredQPSFraction, jsc);
18 // [2] 分区进行更新location
19 JavaRDD writeStatusJavaRDD = partitionedRDD.mapPartitionsWithIndex(updateLocationFunction(),
20 true);
21 // [3] 缓存状态RDD
22 // caching the index updated status RDD
23 writeStatusJavaRDD = writeStatusJavaRDD.persist(SparkMemoryUtils.getWriteStatusStorageLevel(config.getProps()));
24 // force trigger update location(hbase puts)
25 writeStatusJavaRDD.count();
26 this.hBaseIndexQPSResourceAllocator.releaseQPSResources();
27 return HoodieJavaRDD.of(writeStatusJavaRDD);
28}
[1] 根据写完数据后状态来计算QPS比例,并生成Allocator
[2] 分区进行更新location
[3] 缓存状态RDD
从上面的代码可以看出其具体的代码实现是updateLocationFunction方法中。
1 for (HoodieRecord rec : writeStatus.getWrittenRecords()) {
2 if (!writeStatus.isErrored(rec.getKey())) {
3 Option loc = rec.getNewLocation();
4 if (loc.isPresent()) {
5 // [1] 如果rec存在Location,则是一个update,则不需要进行更新
6 if (rec.getCurrentLocation() != null) {
7 // This is an update, no need to update index
8 continue;
9 }
10 // [2] 如果是一个insert, 则需要新插入数据
11 Put put = new Put(Bytes.toBytes(rec.getRecordKey()));
12 put.addColumn(SYSTEM_COLUMN_FAMILY, COMMIT_TS_COLUMN, Bytes.toBytes(loc.get().getInstantTime()));
13 put.addColumn(SYSTEM_COLUMN_FAMILY, FILE_NAME_COLUMN, Bytes.toBytes(loc.get().getFileId()));
14 put.addColumn(SYSTEM_COLUMN_FAMILY, PARTITION_PATH_COLUMN, Bytes.toBytes(rec.getPartitionPath()));
15 mutations.add(put);
16 // [3] 如果是一个删除操作,需要删除HBase中存储的信息
17 } else {
18 // Delete existing index for a deleted record
19 Delete delete = new Delete(Bytes.toBytes(rec.getRecordKey()));
20 mutations.add(delete);
21 }
22 }
23 if (mutations.size() < multiPutBatchSize) {
24 continue;
25 }
26 doMutations(mutator, mutations, limiter);
27 }
28 // process remaining puts and deletes, if any
29 doMutations(mutator, mutations, limiter);
30 }
[1] 如果rec存在Location,则是一个update,则不需要进行更新
[2] 如果是一个insert, 则需要新插入数据
[3] 如果是一个删除操作,需要删除HBase中存储的信息
通过WriteStatus中的HoodieRecord的位置信息判断是否需要更新位置信息,对于存在location无需要更新,对于新插入需要更新,对于删除需要删除HBase中存储的信息。
总而言之,在Hudi中,不论是COW还是MOR, 都免不了Tagging和Merge的过程。
在Tagging过程中,需要使用recordKey与base的数据进行比对,如果找到key相同的就record则为update, 否则为insert。但是当数据量较大时其查询性能就成了其瓶颈。
min-max索引需要数据分布是有序的,才能得到较好的查询性能。BloomFilter索引在数据量较大的情况下会存在性能下降和假阳性的问题,虽然可以通过比较范围/过滤器拆分Bloom过滤,但某些场景仍然存在问题,例如大量随机update。
在数据库场景中的LSM数据结构,通过批量处理数据,将随机IO转换为顺序IO, 同时其可以合并和分层可以存储大量的数据。Hbase采用跳表的方式实现LSM, 同时其可以通过分层解决数据倾斜和减少写放大,在查询时使用bloomFilter优化点查,可以解决大量随机的update/delete场景。当然它存在的问题使得Hudi需要依赖外部组件。
另外在合并的Join过程中,Broadcast Hash Join需要满足delta数据可以装入内存进行广播。Sort merge join是最常用的Join, 如果要提升合并的效率,可以通过排序合并文件,来提升SMJ的效率。