今天来聊聊Spark 3.3 中的Runtime Filter Joins的实现。
行级运行时过滤器(row-level runtime filters)指的是,Spark 可以根据需要在查询计划中注入和下推 Filter,以便在早期过滤数据,减少 shuffle 和后期计算的中间数据大小。这可以用于补充动态分区修剪(dynamic partition pruning,DPP)和动态文件修剪(dynamic file pruning,DFP),以适应动态文件跳过(dynamic file skipping)不够适用或不够彻底的情况。
在Spark中,Join是一个非常耗费资源耗费时间的操作,一般Join中都会涉及到Shuffle的操作,需要大量的IO操作。 如果我们能够尽可能的在靠近源头上减少参与计算的数据,一方面可以提高查询性能,另一方面也可以减少资源的消耗(网络/IO/CPU等)。Runtime Filter Joins的思路很简单就是利用小表的Join keys基于大表Join keys构造过滤器,来减少大表的数据读取。
在电商的星型数仓的数据关联场景中,可以充分利用过滤之后的维度表,大幅削减事实表的数据扫描量,从整体上提升Join计算的执行性能。
运行时行级过滤
Runtime Filter是在数据库中广泛使用的一种优化技术,其基本原理是通过在join的probe端提前过滤掉那些不会命中join的输入数据来大幅减少join中的数据传输和计算,从而减少整体的执行时间。
下面我们用一个例子来进行说明:
1SELECT * FROM order JOIN items ON order.item_id = items.id WHERE items.price > 7999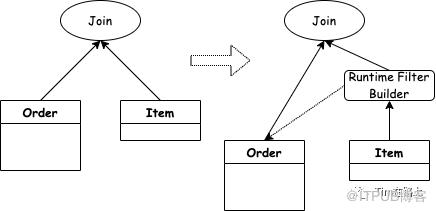
例如上图所示是电商场景中场景的Join场景。在执行上述的Join SQL的时候,不仅需要把全量的order数据传输到join算子里去,还需要依次对Order表中的数据进行Hash和比较运算。这里如果小表的选择度比较高,那么Order大表中的大部分数据是几乎用不上的,如果提前进行过滤掉,可以减少数据的传输和计算的开销。
一句话来表明Spark中的Bloom Filter Joins,即通过使用 Bloom 过滤器和Join另一侧的Join Keys的值来生成 IN 谓词,然后对Join的一侧进行预过滤来提高某些Join的性能。
那么Spark中的运行时的行级过滤是如何实现的呢?
在Spark中使用spark.sql.optimizer.runtime.bloomFilter.enabled和spark.sql.optimizer.runtimeFilter.semiJoinReduction.enabled属性启用的行级运行时过滤器。它引入了两种不同的优化,分别是基于聚合的连接的聚合布隆过滤器和将join转换为带有子查询的Semi-Join Filter。
那为什么有了BloomFilter还需要另一个策略转换为Semi-Join?
这里的原因是考虑到BloomFilter有假阳性的问题,另外如果数据量比较大其结果可能会出现判断错误的情况。所以说如果当构造表数据量较大,但其join keys足够小(或经过过滤后)可以进行广播,那么使用Semi-Join可能会带来更多的收益。
runtimeFilter 源码分析
1. 尝试注入RuntimeFilter,并校验是否满足应用条件。
RuntimeFilter的调用来源于Spark optimizer。在Spark的优化器中注入了runtimeFilter的Rule,在对SQL进行优化时会调用到这个Rule。下面我们来看看InjectRuntimeFilter是如何对SQL进行优化的,最终优化的Plan会长成什么样子呢?
1Batch("InjectRuntimeFilter", FixedPoint(1),
2 InjectRuntimeFilter,
3 RewritePredicateSubquery)
在调用InjectRuntimeFilter规则时会运行其apply方法,在Apply方法中会判断spark.sql.optimizer.runtime.bloomFilter.enabled和spark.sql.optimizer.runtimeFilter.semiJoinReduction.enabled是否被打开,如果都没有打开则不会进行runtimeFilter的优化。否则会调用tryInjectRuntimeFilter方法进行尝试进行运行时过滤的优化。
1private def tryInjectRuntimeFilter(plan: LogicalPlan): LogicalPlan = {
2 var filterCounter = 0
3 // [1] 这里为了避免driver端的oom, 约定一条sql最多只能做10个bloom过滤器
4 val numFilterThreshold = conf.getConf(SQLConf.RUNTIME_FILTER_NUMBER_THRESHOLD)
5 plan transformUp {
6 // 可以看到runtimeFilter只处理相等key的情况
7 case join @ ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, _, _, left, right, hint) =>
8 var newLeft = left
9 var newRight = right
10 (leftKeys, rightKeys).zipped.foreach((l, r) => {
11 // [2] 校验是否满足以下情况
12 // Check if:
13 // 1. There is already a DPP filter on the key
14 // 2. There is already a runtime filter (Bloom filter or IN subquery) on the key
15 // 3. The keys are simple cheap expressions
16 if (filterCounter < numFilterThreshold &&
17 !hasDynamicPruningSubquery(left, right, l, r) &&
18 !hasRuntimeFilter(newLeft, newRight, l, r) &&
19 isSimpleExpression(l) && isSimpleExpression(r)) {
20 val oldLeft = newLeft
21 val oldRight = newRight
22 // [3] 进行应用injectFilter,如果左侧不行会尝试右侧
23 if (canPruneLeft(joinType) && filteringHasBenefit(left, right, l, hint)) {
24 newLeft = injectFilter(l, newLeft, r, right)
25 }
26 // Did we actually inject on the left? If not, try on the right
27 if (newLeft.fastEquals(oldLeft) && canPruneRight(joinType) &&
28 filteringHasBenefit(right, left, r, hint)) {
29 newRight = injectFilter(r, newRight, l, left)
30 }
31 if (!newLeft.fastEquals(oldLeft) || !newRight.fastEquals(oldRight)) {
32 filterCounter = filterCounter + 1
33 }
34 }
35 })
36 join.withNewChildren(Seq(newLeft, newRight))
37 }
38}
从上面源码可以看出,即使开启了开关,也需要进行校验是否满足了以下的情况:
[1] 已注入BloomFilter的数量低于spark.sql.optimizer.runtimeFilter.number.threshold(默认为 10), 这里限制的原因是避免 OOM 问题。
[2] 到目前为止优化的逻辑计划中不存DDP。
[3] BloomFilter和Semi-Join过滤器都不存在已有的RuntimeFilter在对应的Join Keys上。
[4] 左侧和右侧join keys是简单的表达式,此模式匹配的计算操作并不昂贵, 即不包含以下的操作。
1private def isSimpleExpression(e: Expression): Boolean = {
2 !e.containsAnyPattern(PYTHON_UDF, SCALA_UDF, INVOKE, JSON_TO_STRUCT, LIKE_FAMLIY,
3 REGEXP_EXTRACT_FAMILY, REGEXP_REPLACE)
4}
当以上的条件都满足的话,则会进行应用injectFilter的操作,从上面的源码可以看出,会左侧和右侧分别进行尝试应用。下面我们以应用左表进行分析。在应用左侧的filter前,会先根据join keys进行判断是否可以canPruneLeft, 以及通过filteringHasBenefit判断是否应用Filter可以得到收益。
1def canPruneLeft(joinType: JoinType): Boolean = joinType match {
2 case Inner | LeftSemi | RightOuter => true
3 case _ => false
4}
判断left表是否可以进行剪枝,join类型需要为Inner或LeftSemi或RightOuter类型。
1private def filteringHasBenefit(
2 filterApplicationSide: LogicalPlan,
3 filterCreationSide: LogicalPlan,
4 filterApplicationSideExp: Expression,
5 hint: JoinHint): Boolean = {
6 findExpressionAndTrackLineageDown(filterApplicationSideExp,
7 filterApplicationSide).isDefined && isSelectiveFilterOverScan(filterCreationSide) &&
8 (isProbablyShuffleJoin(filterApplicationSide, filterCreationSide, hint) ||
9 probablyHasShuffle(filterApplicationSide)) &&
10 satisfyByteSizeRequirement(filterApplicationSide)
11}
Plan转换是否对查询有益,主要是通过以下条件进行判断的:
[1] 如果过滤器应用端的输入来自单个叶子节点, 过滤器应用程序端是将使用运行时过滤器的连接端。
[2] 过滤器创建端的过滤表达式有一个选择性谓词,例如“=”、“<=”、“IN”、… 完整列表在PredicateHelper#isLikelySelective方法中可用。
[3] 当前的连接树是一个Shuffle连接或Broadcast连接,其下有一个Shuffle连接。
[4] 过滤器应用端的大小大于spark.sql.optimizer.runtime.bloomFilter.applicationSideScanSizeThreshold(默认为 10GB)。
当左侧可以进行prune, 同时应用runtimeFilter预计会产生收益,则会调用injectFilter方法。
1private def injectFilter(
2 filterApplicationSideExp: Expression,
3 filterApplicationSidePlan: LogicalPlan,
4 filterCreationSideExp: Expression,
5 filterCreationSidePlan: LogicalPlan): LogicalPlan = {
6 require(conf.runtimeFilterBloomFilterEnabled || conf.runtimeFilterSemiJoinReductionEnabled)
7 if (conf.runtimeFilterBloomFilterEnabled) {
8 injectBloomFilter(
9 filterApplicationSideExp,
10 filterApplicationSidePlan,
11 filterCreationSideExp,
12 filterCreationSidePlan
13 )
14 } else {
15 injectInSubqueryFilter(
16 filterApplicationSideExp,
17 filterApplicationSidePlan,
18 filterCreationSideExp,
19 filterCreationSidePlan
20 )
21 }
22}
从上面可以看出,如果开启BloomFilter则应用injectBloomFilter,如果开启SemiJoinReduction则应用injectInSubqueryFilter。下面我们依次来看下:
2. 开启BloomFilter,将plan转换为带有聚合布隆器的Join。
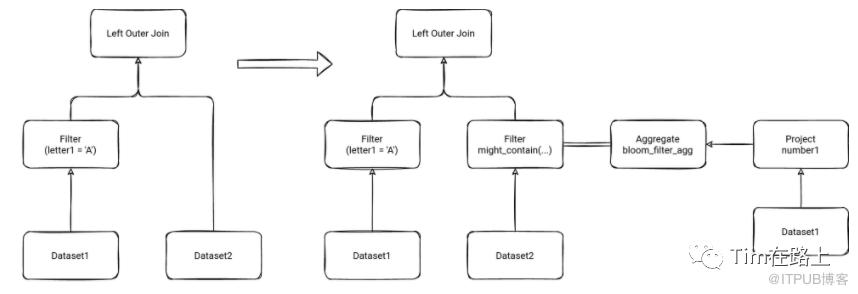
我们来总的看下运行时BloomFilter的实现。从上图可以看出,在开启BloomFilter后,会从Dataset1中根据过滤条件筛选出join所需要的join keys, 然后通过聚合将其更新到bloomFilter中,然后在数据扫描加载Dataset2时,会根据join keys去bloom过滤器中查询是否满足条件,只将满足条件的数据进行查询出,这样可以减少扫描的数据量。下面我们来看下injectBloomFilter方法:
1private def injectBloomFilter(
2 filterApplicationSideExp: Expression,
3 filterApplicationSidePlan: LogicalPlan,
4 filterCreationSideExp: Expression,
5 filterCreationSidePlan: LogicalPlan): LogicalPlan = {
6 // [1] 如果creation side(小表侧)的sizeInBytes大于阈值(默认是10M)则不进行应用。
7 // Skip if the filter creation side is too big
8 if (filterCreationSidePlan.stats.sizeInBytes > conf.runtimeFilterCreationSideThreshold) {
9 return filterApplicationSidePlan
10 }
11 // [2] 将creation side(小表侧)的join keys进行hash后封装bloom过滤器的聚合函数,并封装为agg表达式,过滤器的大小设置为表的行数。
12 val rowCount = filterCreationSidePlan.stats.rowCount
13 val bloomFilterAgg =
14 if (rowCount.isDefined && rowCount.get.longValue > 0L) {
15 new BloomFilterAggregate(new XxHash64(Seq(filterCreationSideExp)),
16 Literal(rowCount.get.longValue))
17 } else {
18 new BloomFilterAggregate(new XxHash64(Seq(filterCreationSideExp)))
19 }
20 val aggExp = AggregateExpression(bloomFilterAgg, Complete, isDistinct = false, None)
21 val alias = Alias(aggExp, "bloomFilter")()
22 // [3] 直接将creation side(小表侧)的逻辑计划应用bloomFilter,同时进行列剪裁和常量合并
23 val aggregate =
24 ConstantFolding(ColumnPruning(Aggregate(Nil, Seq(alias), filterCreationSidePlan)))
25 // [4] 将ApplicationSide(大表侧)的join keys进行hash, 并去BloomFilter查询匹配
26 val bloomFilterSubquery = ScalarSubquery(aggregate, Nil)
27 val filter = BloomFilterMightContain(bloomFilterSubquery,
28 new XxHash64(Seq(filterApplicationSideExp)))
29 // [5] 最终是封装为Filter算子,插入到应用侧(即大表侧)
30 Filter(filter, filterApplicationSidePlan)
31}
从上面的代码可以看出,主要有以下几个步骤:
[1] 如果creation side(小表侧)的sizeInBytes大于阈值(默认是10M),则不进行应用。
[2] 将creation side(小表侧)的join keys进行hash后封装bloom过滤器的聚合函数,并封装为agg表达式,过滤器的大小设置为表的行数。
[3] 直接将creation side(小表侧)的逻辑计划应用bloomFilter,同时进行列剪裁和常量合并
[4] 将ApplicationSide(大表侧)的join keys进行hash, 并去BloomFilter查询匹配
[5] 最终是封装为Filter算子,插入到应用侧(即大表侧)
布隆过滤器的调用在BloomFilterMightContain的方法中,主要根据key的hash值其bloom过滤器中进行查询。
1public boolean mightContainLong(long item) {
2 int h1 = Murmur3_x86_32.hashLong(item, 0);
3 int h2 = Murmur3_x86_32.hashLong(item, h1);
4
5 long bitSize = bits.bitSize();
6 for (int i = 1; i <= numHashFunctions; i++) {
7 int combinedHash = h1 + (i * h2);
8 // Flip all the bits if it's negative (guaranteed positive number)
9 if (combinedHash < 0) {
10 combinedHash = ~combinedHash;
11 }
12 if (!bits.get(combinedHash % bitSize)) {
13 return false;
14 }
15 }
16 return true;
17}
另外需要关注的是,这里的hash函数主要是采用Guava包中Murmur3Hash,另外这里的Bloomfilter是采用之前就给DataFrame实现的方法,其也是参照Guava中进行实现的,限于篇幅就不展开了。其实现主要在BitArray类中,在其内部采用long[] data来表示一个大的bitmap。
3. 开启SemiJoinReductionEnabled,则会将Plan转换为带有子查询的Semi-Join。
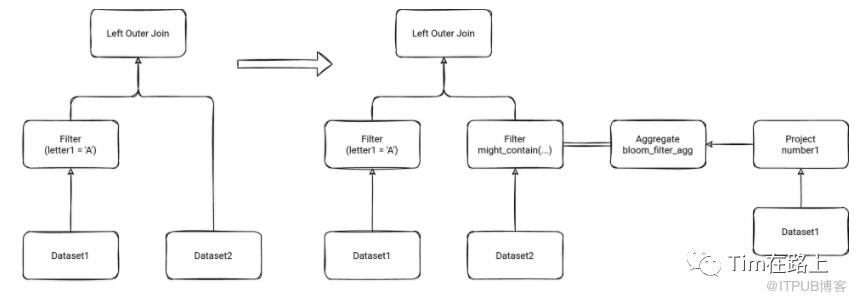
我们先来总的看下SemiJoinFilter的实现。其实这里和DDP非常类似,就是当过滤后的Join keys可以满足广播的情况,将其广播,然后封装为Filter算子,应用到Dataset2的扫描上。下面我们来看下injectInSubqueryFilter是如何实现的?
1private def injectInSubqueryFilter(
2 filterApplicationSideExp: Expression,
3 filterApplicationSidePlan: LogicalPlan,
4 filterCreationSideExp: Expression,
5 filterCreationSidePlan: LogicalPlan): LogicalPlan = {
6 require(filterApplicationSideExp.dataType == filterCreationSideExp.dataType)
7 // [1] 将CreationSide的join keys进行hash, 然后进行聚合
8 val actualFilterKeyExpr = mayWrapWithHash(filterCreationSideExp)
9 val alias = Alias(actualFilterKeyExpr, actualFilterKeyExpr.toString)()
10 val aggregate = Aggregate(Seq(alias), Seq(alias), filterCreationSidePlan)
11 // [2] 如果不满足Broadcast,直接返回,默认10M
12 if (!canBroadcastBySize(aggregate, conf)) {
13 // Skip the InSubquery filter if the size of `aggregate` is beyond broadcast join threshold,
14 // i.e., the semi-join will be a shuffled join, which is not worthwhile.
15 return filterApplicationSidePlan
16 }
17 // [3] 将aggregate和ApplicationSide的keys封装为InSubquery,最后封装为Filter条件
18 val filter = InSubquery(Seq(mayWrapWithHash(filterApplicationSideExp)),
19 ListQuery(aggregate, childOutputs = aggregate.output))
20 Filter(filter, filterApplicationSidePlan)
21}
从上面的代码可以看出,主要有以下几个步骤:
[1] 将CreationSide的join keys进行hash, 然后进行聚合
[2] 如果不满足Broadcast,直接返回,默认10M
[3] 将aggregate和ApplicationSide的keys封装为InSubquery,最后封装为Filter条件
这里的实现很简单就不在过多赘述了。
总结下Spark是如何实现runtimeFilter的,以及有何优缺点:
spark通过InjectRuntimeFilter规则的注入实现两种运行时的filter,分别是bloomFilter和semi-join Filter,这里考虑到的收益和花费的均衡。
需要注意的是bloomFilter需要小表满足其sizeInBytes小于阈值(默认10M), semi-join Filter需要满足小表join keys聚合后可以广播。这里主要是BloomFilter有假阳性的问题,当小表大小大于阈值后,比较大数据量其结果可能会出现错误的情况。
-
从上面的分享可以看出,Spark的runtimeFilter, 在Plan的转换中会存在冗余计算的问题,小表存在两次扫描和过滤的问题。