在Spark2.0版本以前,Spark的核心一直是Core模块。而SQL的优化采用的主要是基于启发式、静态的优化过程。在Spark3.0时,Spark的核心已经变成了SQL模块。
启发式的静态优化又叫做基于规则的优化, 即RBO。主要是基于专家经验式的优化SQL的执行。常见的优化方式主要有三类:谓词下推、常量合并和列剪枝。但是这几种方式并不能估算出准确的表的数据量。
例如在创建分区表时(非CBO),表的大小为每列数据类型占用字节数 * Long.MaxValue 之和。可见在创建分区表时并不会去统计表的行数。即使只插入一条数据,此表会被认为是很大的表。显然这与事实是严重不符合的。
为了解决RBO的局限性,在Spark 2.2时引入SQL常见的优化方式,基于成本的优化方式,即CBO。基于数据表的统计信息(如表大小、数据列分布)来选择优化策略。
但是CBO仅仅支持注册到 Hive Metastore 的数据表, 但即使是Hive 表,开发者还需要在之前调用 ANALYZE TABLE COMPUTE STATISTICS 语句收集统计信息。对于数据量比较大的表会造成严重的性能回归。
什么是AQE ?
用一句话来概括,AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化。
从定义中,我们不难发现,AQE 优化机制触发的时机是 Shuffle Map 阶段执行完毕。也就是说,AQE 优化的频次与执行计划中 Shuffle 的次数一致。如果你的查询SQL不引入shuffle自然也不会触发AQE。
另外和CBO不同的是,CBO是基于表的统计信息,AQE是基于Shuffle中间落盘的临时文件的统计信息。
AQE 从运行时获取统计信息,在条件允许的情况下,优化决策可以分别作用到逻辑计划和物理计划。
下面再来回顾下AQE与非AQE的流程上的区别:
在非AQE的情况下,Spark作业被提交给DAGScheduler并转换为DAG图。在DAGScheduler通过调用createResultStage方法,依次从下游到上游遍历RDD寻找ShuffleDependency为划分父Stage。
在Spark中Stage有两种类型:ResultStage是执行pipeline中用于执行操作的最后阶段。而 ShuffleMapStage是中间阶段,它为 shuffle 写入mapper输出文件。
当一个 ShuffleMapStage 创建时,它会在 shuffledIdToMapStage哈希映射中注册,该哈希映射从 shuffle 依赖 ID 映射到创建的 ShuffleMapStage。
当 createResultStage方法创建并返回最终结果阶段时,提交最终阶段运行。在提交当前阶段之前,需要先提交所有的父阶段。通过 getMissingParentStages方法获取父阶段,该方法首先找到当前阶段的 shuffle 依赖项,并在shuffledIdToMapStage 哈希映射中查找为 shuffle 依赖项创建的 ShuffleMapStage。
在开启AQE的情况下,在prepared Physical stage阶段,将应用InsertAdaptiveSparkPlan规则。当 AdaptiveSparkPlanExec 被执行时,它会调用 getFinalPhysicalPlan方法来启动执行流程。在AQE也会通过递归调用方法来创建Stage, 不过该方法是AdaptiveSparkPlanExec中的createQueryStages方法。如果当前节点是 Exchange 节点并且其所有子阶段都已实现,则新的 QueryStage。
然后物化createQueryStages方法返回的新阶段 ,该阶段在内部将阶段提交给 DAGScheduler 以独立运行并返回阶段执行的map输出统计信息。然后根据新的统计信息重新优化和重新规划查询计划。然后评估新规划的物理计划的成本并与旧物理计划的成本进行比较。如果新的物理计划比旧的运行成本低,则使用新的物理计划进行剩余处理。
总而言之,在AQE的情况下,Spark提前了stage的划分,将整个物理计划树划分为子QueryStage, 并依赖于DAGScheduler支持提交单个MapStage的能力进行依次提交子QueryStage。然后依据上个执行的QueryStage统计信息重新优化和重新规划查询计划。而在非AQE的情况下直接将整个物理计划树提交到DAGScheduler, 在DAGScheduler中划分stage,这时整个物理计划树已经固定。
AQE的三大特性是:动态选择join策略、自动的分区合并和自动处理数据倾斜的join。
初见AQE源码轮廓
一切梦的开始源于InsertAdaptiveSparkPlan物理优化Rule, 它是AQE开启的入口。我们都知道在SparkSQL从逻辑计划转换为物理计划后,并不能直接被执行,还需要经过preparations 阶段。
InsertAdaptiveSparkPlan优化Rule就是被调用在QueryExecution.preparations中。
其实并不是所有的任务都可以使用AQE, 从其原理我们知道只有存在Shuffle的SparkSQL任务才会有可能使用到AQE。但开启AQE也并不是那么容易。
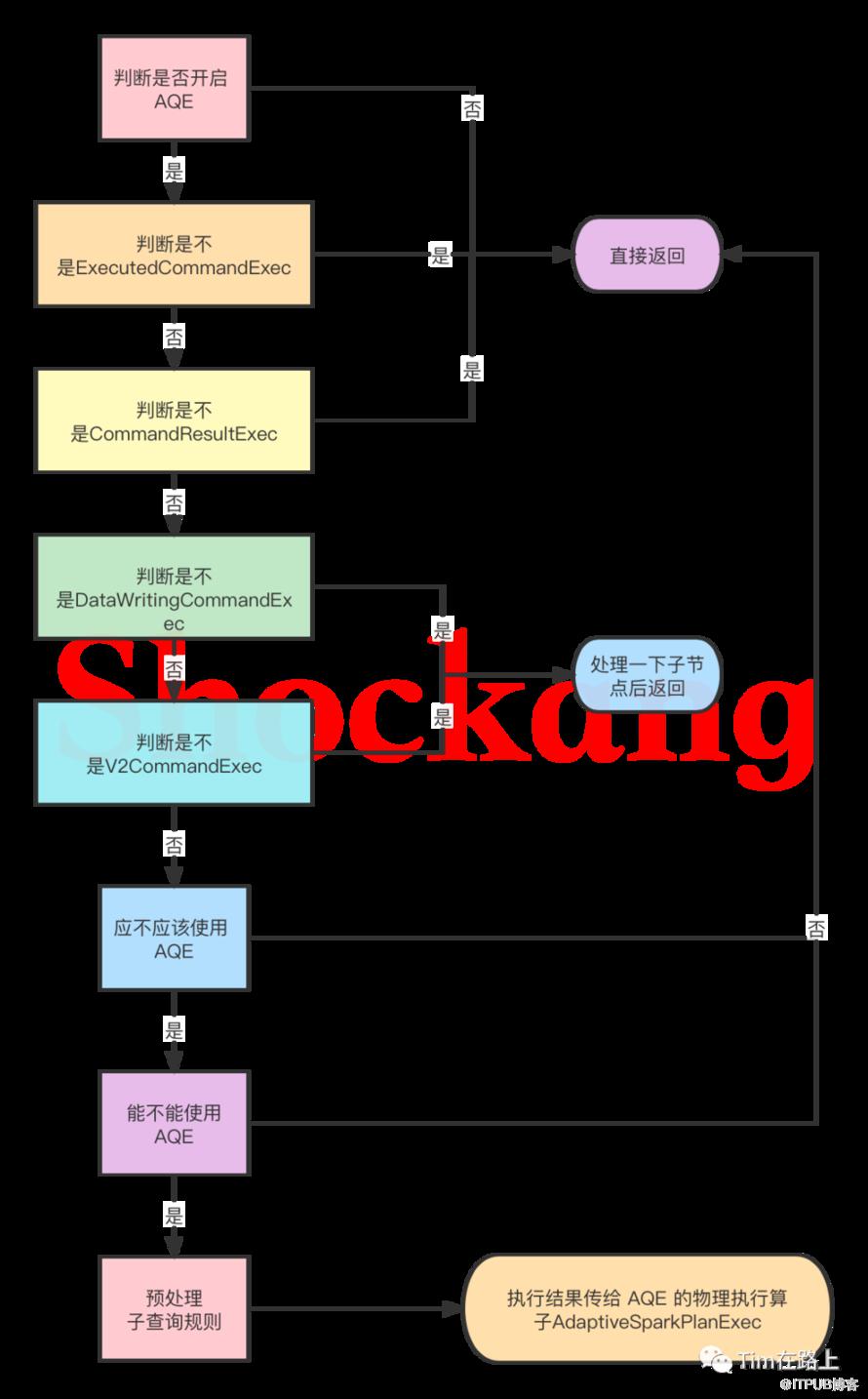
1//InsertAdaptiveSparkPlan
2private def applyInternal(plan: SparkPlan, isSubquery: Boolean): SparkPlan = plan match {
3 // [1] 判断是否开启AQE
4 case _ if !conf.adaptiveExecutionEnabled => plan
5 // [2] 和数据写入相关的命令算子不会应用AQE
6 case _: ExecutedCommandExec => plan
7 case _: CommandResultExec => plan
8 case c: DataWritingCommandExec => c.copy(child = apply(c.child))
9 case c: V2CommandExec => c.withNewChildren(c.children.map(apply))
10 // [3] 判断是否满足以下条件之一可以应用AQE
11 case _ if shouldApplyAQE(plan, isSubquery) =>
12 // [4] 验证是否支持AQE
13 if (supportAdaptive(plan)) {
14
15// 判断是否满足以下条件之一可以应用AQE
16private def shouldApplyAQE(plan: SparkPlan, isSubquery: Boolean): Boolean = {
17 // 1. 开启AQE强制应用
18 // 2. query中包含子查询
19 conf.getConf(SQLConf.ADAPTIVE_EXECUTION_FORCE_APPLY) || isSubquery || {
20 plan.find {
21 // 3. query 包含Exchange算子或者是否需要添加Exchange算子,即存在shuffle or broadcast事件
22 case _: Exchange => true
23 case p if !p.requiredChildDistribution.forall(_ == UnspecifiedDistribution) => true
24 case p => p.expressions.exists(_.find {
25 case _: SubqueryExpression => true
26 case _ => false
27 }.isDefined)
28 }.isDefined
29 }
30 }
31
32private def supportAdaptive(plan: SparkPlan): Boolean = {
33 sanityCheck(plan) &&
34 !plan.logicalLink.exists(_.isStreaming) &&
35 plan.children.forall(supportAdaptive)
36 }
从上面的代码可以看出判断是否可以应用AQE有以下几步:
[1] 判断是否开启AQE
[2] 首先和数据写入相关的命令算子不会应用AQE
[3] 其次判断是否满足以下条件之一可以应用AQE
[4] 验证是否支持AQE
开启AQE需要满足以下至少其中一个:
开启AQE强制应用的开关;
query中包含子查询;
query 包含Exchange算子或者是否需要添加Exchange算子,即存在shuffle or broadcast事件。
当以上条件满足其中一个时,还将执行AQE支持验证,这也会使 AQE 申请无效,首先我们来看下sanityCheck方法:
1private def sanityCheck(plan: SparkPlan): Boolean =
2 plan.logicalLink.isDefined
3
4def logicalLink: Option[LogicalPlan] =
5 getTagValue(SparkPlan.LOGICAL_PLAN_TAG)
6 .orElse(getTagValue(SparkPlan.LOGICAL_PLAN_INHERITED_TAG))
其中SparkPlan.LOGICAL_PLAN_TAG用来记录当前的SparkPlan是从哪个LogicalPlan转换而来的,而如果找不到对应的逻辑计划,我们就会给它一个默认值SparkPlan.LOGICAL_PLAN_INHERITED_TAG,表示的是继承自祖先的逻辑计划。
从上面的源码可以看出物理计划与其初始逻辑计划需要链接,逻辑计划稍后在自适应查询执行中使用,以将其转换为 AQE 可理解的格式LogicalQueryStage。
所以说,只有当前的物理计划满足下面3 个条件时,才能支持自适应查询执行(AQE):
当前的物理计划需要关联一个逻辑计划,如果连继承自祖先的逻辑计划都没有定义的时候,就不能使用 AQE 了。
当前的物理计划关联的逻辑计划不能来自流式数据源。
当前的物理计划的所有子节点都必须支持AQE验证条件。
预处理子查询
1if (supportAdaptive(plan)) {
2 try {
3 // Plan sub-queries recursively and pass in the shared stage cache for exchange reuse.
4 // Fall back to non-AQE mode if AQE is not supported in any of the sub-queries.
5 // [1] 预处理子查询,先要构建一个子查询 Map
6 val subqueryMap = buildSubqueryMap(plan)
7 // [2] 应用自适应的子查询Rule
8 val planSubqueriesRule = PlanAdaptiveSubqueries(subqueryMap)
9 val preprocessingRules = Seq(
10 planSubqueriesRule)
11 // Run pre-processing rules.
12 // [3] 运行预处理规则
13 val newPlan = AdaptiveSparkPlanExec.applyPhysicalRules(plan, preprocessingRules)
14 logDebug(s"Adaptive execution enabled for plan:$plan")
15 // [4] 调用AdaptiveSparkPlanExec算子
16 AdaptiveSparkPlanExec(newPlan, adaptiveExecutionContext, preprocessingRules, isSubquery)
17 } catch {
18 caseSubqueryAdaptiveNotSupportedException(subquery) =>
19 logWarning(s"${SQLConf.ADAPTIVE_EXECUTION_ENABLED.key} is enabled " +
20 s"but is not supported for sub-query:$subquery.")
21 plan
22 }
23}
如果满足以上条件,则递归地build plan子查询,并传入共享阶段缓存以供Exchange重用。如果任何子查询都不支持 AQE,则回退到非 AQE 模式。
在buildSubqueryMap(plan)执行后会为所有子查询返回 表达式 ID 到 执行计划的映射。
然后,我们会将子查询 Map 传给自适应子查询Rule——PlanAdaptiveSubqueries 。这个规则会递归地检查物理计划树中是否存在ScalarSubquery、InSubquery和 DynamicPruningSubquery,并进行针对性处理。
执行AQE 的物理执行算子
构建好预处理子查询规则后,我们通过AdaptiveSparkPlanExec.applyPhysicalRules方法来执行规则,这个方法会应用 SparkPlan 上的一系列物理算子规则。
最后将执行结果传给 AQE 的物理执行算子AdaptiveSparkPlanExec 。
那么接下来专注于AdaptiveSparkPlanExec ,看看在其中到底发生了什么?
AdaptiveSparkPlanExec
既然它是物理计划执行算子,那么它的核心就在于Executor,即方法——doExecute 。
1override def doExecute(): RDD[InternalRow] = {
2 withFinalPlanUpdate(_.execute())
3}
可以看出其调用了withFinalPlanUpdate来获取最终的物理计划的更新,然后在withFinalPlanUpdate中又调用getFinalPhysicalPlan 获取最终的物理计划。
在getFinalPhysicalPlan会将currentPhysicalPlan传给createQueryStages方法,这个方法的输出类型是CreateStageResult,这个方法会从下到上递归的遍历物理计划树生成新的Query stage,这个 createQueryStages 方法在每次计划发生变化时都会被调用。
createQueryStages会从下到上遍历并应用物理计划树的所有节点,根据节点的类型不同其处理也是不同的:
对于Exchange类型的节点,exchange会被QueryStageExec节点替代。如果开启了stageCache,同时exchange节点是存在的stage, 则直接重用stage作为QueryStage, 并封装返回CreateStageResult。否则,从下向上迭代,如果孩子节点都迭代完成,将基于broadcast转换为BroadcastQueryStageExec,shuffle作为ShuffleQueryStageExec,并将其依次封装为CreateStageResult。
对于QueryStageExec节点类型,直接封装为CreateStageResult 返回。
对于其余类型,createQueryStages 函数应用于节点的直接子节点,这当然会导致再次调用 createQueryStages 并创建其他 QueryStageExec。
下面的代码就是当节点为Exchange类型时,如果迭代创建新的QueryStageExec的过程,可见其是按照ShuffleExchangeLike和BroadcastExchangeLike进行模式匹配的。
1private def newQueryStage(e: Exchange): QueryStageExec = {
2 val optimizedPlan = optimizeQueryStage(e.child, isFinalStage = false)
3 val queryStage = e match {
4 case s: ShuffleExchangeLike =>
5 val newShuffle =applyPhysicalRules(
6 s.withNewChildren(Seq(optimizedPlan)),
7 postStageCreationRules(outputsColumnar = s.supportsColumnar),
8Some((planChangeLogger, "AQE Post Stage Creation")))
9 if (!newShuffle.isInstanceOf[ShuffleExchangeLike]) {
10 throw new IllegalStateException(
11 "Custom columnar rules cannot transform shuffle node to something else.")
12 }
13ShuffleQueryStageExec(currentStageId, newShuffle, s.canonicalized)
14 case b: BroadcastExchangeLike =>
15 val newBroadcast =applyPhysicalRules(
16 b.withNewChildren(Seq(optimizedPlan)),
17 postStageCreationRules(outputsColumnar = b.supportsColumnar),
18Some((planChangeLogger, "AQE Post Stage Creation")))
19 if (!newBroadcast.isInstanceOf[BroadcastExchangeLike]) {
20 throw new IllegalStateException(
21 "Custom columnar rules cannot transform broadcast node to something else.")
22 }
23BroadcastQueryStageExec(currentStageId, newBroadcast, b.canonicalized)
24 }
25currentStageId+= 1
26 setLogicalLinkForNewQueryStage(queryStage, e)
27 queryStage
28}
QueryStageExec查询阶段(Stage)是查询计划的独立子图,在继续执行查询计划的其他算子之前,查询阶段将实现其输出,物化输出的数据统计信息可用于优化后续的查询阶段。
从上面的代码可以看出有两种类型的QueryStageExec可以物化统计数据,用于AQE的后序优化。
Shuffle 查询阶段:这个阶段将其输出具体化为 Shuffle 文件,Spark 启动另一个作业来执行进一步的算子。
广播查询阶段:这个阶段将其输出具体化为 Driver JVM 中的一个数组。Spark 在执行进一步的算子之前先广播数组。
下面我们在返回getFinalPhysicalPlan方法中,看返回CreateStageResult之后是如何操作的:
1// [1] 是否所有的孩子stage都已经被物化
2while (!result.allChildStagesMaterialized) {
3 currentPhysicalPlan= result.newPlan
4 if (result.newStages.nonEmpty) {
5 // [2] 通知监听器物理计划已经变更
6 stagesToReplace = result.newStages ++ stagesToReplace
7 executionId.foreach(onUpdatePlan(_, result.newStages.map(_.plan)))
8
9 // [3] 先提交广播阶段的任务,以避免等待用于计划任务并导致广播超时
10 val reorderedNewStages = result.newStages
11 .sortWith {
12 case (_: BroadcastQueryStageExec, _: BroadcastQueryStageExec) => false
13 case (_: BroadcastQueryStageExec, _) => true
14 case _ => false
15 }
16 // [4] 等待下一个完成的stage,这表明新的统计数据可用,并且可能可以创建新的阶段。
17 // Start materialization of all new stages and fail fast if any stages failed eagerly
18 reorderedNewStages.foreach { stage =>
19 try {
20 stage.materialize().onComplete { res =>
21 if (res.isSuccess) {
22 events.offer(StageSuccess(stage, res.get))
23 } else {
24 events.offer(StageFailure(stage, res.failed.get))
25 }
26 }(AdaptiveSparkPlanExec.executionContext)
27 } catch {
28 case e: Throwable =>
29 cleanUpAndThrowException(Seq(e),Some(stage.id))
30 }
31 }
32 }
33 ...
34 // [5] 尝试重新优化和重新规划。如果新计划的成本小于或者等于当前的计划就采用新计划;
35 val logicalPlan = replaceWithQueryStagesInLogicalPlan(currentLogicalPlan, stagesToReplace)
36 val (newPhysicalPlan, newLogicalPlan) = reOptimize(logicalPlan)
37 val origCost =costEvaluator.evaluateCost(currentPhysicalPlan)
38 val newCost =costEvaluator.evaluateCost(newPhysicalPlan)
39 if (newCost < origCost ||
40 (newCost == origCost &¤tPhysicalPlan!= newPhysicalPlan)) {
41logOnLevel(s"Plan changed from$currentPhysicalPlan to$newPhysicalPlan")
42 cleanUpTempTags(newPhysicalPlan)
43currentPhysicalPlan= newPhysicalPlan
44 currentLogicalPlan = newLogicalPlan
45 stagesToReplace =Seq.empty[QueryStageExec]
46 }
47 // [6] 现在一些stage已经结束了,我们可以创建新的阶段。
48 // Now that some stages have finished, we can try creating new stages.
49 result = createQueryStages(currentPhysicalPlan)
50}
从上面我们可以看出在得到getFinalPhysicalPlan的执行步骤:
[1] 是否所有的孩子stage都已经被物化
[2] 通知监听器物理计划已经变更
[3] 先提交广播阶段的任务,以避免等待用于计划任务并导致广播超时
[4] 等待下一个完成的stage,这表明新的统计数据可用,并且可能可以创建新的阶段。
[5] 尝试重新优化和重新规划。如果新计划的成本小于或者等于当前的计划就采用新计划;
[6] 现在一些stage已经结束了,我们可以创建新的阶段。
如你所见,将broadcast或者shuffle作为QueryStage的划分。而当一个QueryStageExec完成后,就会更新CreateStageResult结果。在CreateStageResult发生更新的时候,同时会统计新的数据,然后创建一个更便宜的物理执行计划,来更新当前的物理执行计划。
下面我们来详细分析了尝试重新优化和重新规划的过程:
首先,物理计划的logicalLink指向它起源的逻辑计划,从中可以获取到对应的逻辑计划。在replaceWithQueryStagesInLogicalPlan方法中。会将逻辑计划树中的所有QueryStage替换为LogicalQueryStage。
LogicalQueryStage 是 QueryStageExec的逻辑计划包装,包含QueryStageExec的物理计划片段,QueryStageExec的所有祖先节点都链接到同一逻辑节点。例如,可以将一个逻辑聚合转换为FinalAgg - Shuffle - PartialAgg,其中 Shuffle 将被包装为QueryStageExec,因此LogicalQueryStage将FinalAgg - QueryStageExec作为其物理计划。
转换为LogicalQueryStage后有了新的统计数据可用,然后会调用尝试重新优化。转换后的逻辑计划将被reOptimize(logicalPlan)进行重新优化,最终会调用optimizer.execute(logicalPlan)方法执行。目前3.2.0支持以下几种逻辑优化:
1private valdefaultBatches= Seq(
2Batch("Propagate Empty Relations", fixedPoint,
3 AQEPropagateEmptyRelation,
4 ConvertToLocalRelation,
5 UpdateAttributeNullability),
6Batch("Dynamic Join Selection", Once, DynamicJoinSelection)
7)
以上的优化都是逻辑层面的优化器,主要是实现逻辑层面的优化。
每次重新规划之前,我们都会用逻辑查询阶段来替换当前逻辑计划的对应节点,这会使得在语义上和当前的物理计划保持同步。一旦一个新的计划被采纳,逻辑计划和物理计划都更新后,我们可以清除查询阶段列表,因为此时两个计划在语义和物理上又再次同步了。
1// 当没有未完成的阶段时运行final plan
2// Run the final plan when there's no more unfinished stages.
3currentPhysicalPlan= applyPhysicalRules(
4 optimizeQueryStage(result.newPlan, isFinalStage = true),
5 postStageCreationRules(supportsColumnar),
6Some((planChangeLogger, "AQE Post Stage Creation")))
7isFinalPlan= true
8executionId.foreach(onUpdatePlan(_,Seq(currentPhysicalPlan)))
9currentPhysicalPlan
在所有的stage都被物化后,对于没有未完成的阶段时运行final plan还要运行applyPhysicalRules,在其中传入optimizeQueryStage方法。在这个方法中,会调用queryStageOptimizerRules 进行优化。
1@transient private val queryStageOptimizerRules: Seq[Rule[SparkPlan]] =Seq(
2PlanAdaptiveDynamicPruningFilters(this),
3 ReuseAdaptiveSubquery(context.subqueryCache),
4 // Skew join does not handle `AQEShuffleRead` so needs to be applied first.
5 OptimizeSkewedJoin,
6 OptimizeSkewInRebalancePartitions,
7 CoalesceShufflePartitions(context.session),
8 // `OptimizeShuffleWithLocalRead` needs to make use of 'AQEShuffleReadExec.partitionSpecs'
9 // added by `CoalesceShufflePartitions`, and must be executed after it.
10 OptimizeShuffleWithLocalRead
11)
这里主要是AQE的物理计划层面的优化规则。
但其实optimizeQueryStage在newQueryStage方法,即划分QueryStage中,就已经被调用了,这里属于第二处的调用。
除上面的规则外,详细你也看到了,在applyPhysicalRules方法中还传入了postStageCreationRules规则,属于new stage被创建后应用的物理优化规则。
1private def postStageCreationRules(outputsColumnar: Boolean) =Seq(
2ApplyColumnarRulesAndInsertTransitions(
3 context.session.sessionState.columnarRules, outputsColumnar),
4collapseCodegenStagesRule
5)
最后我们总结下一条SQL在开启AQE后是如何被优化的,如下图所示:
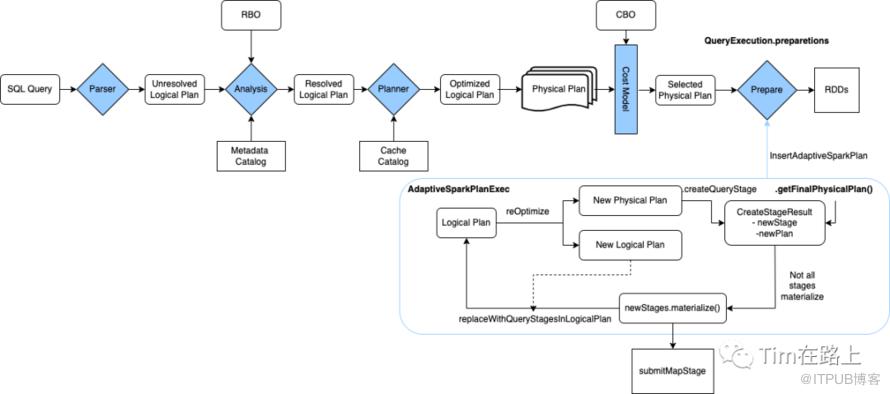
首先,SparkSQL经过catalyst转换为逻辑计划或物理计划树。
其次,在AQE开启后,AdaptiveSparkPlanExec被执行时,它会调用 getFinalPhysicalPlan方法来启动执行流程。通过递归的自下而上的调用createQueryStages方法,将plan树转换为包含QueryStageExec的树,主要是将broadcast和shuffle转换为其对应的QueryStageExec,它将实现其输出,物化输出的数据统计信息可用于优化后续的查询阶段。在第一次转换之后,算法会记住所有新的和未解决的QueryStage,这些阶段稍后会提交以进行物理执行。在newQueryStage中会调用AQE物理计划层面的优化规则。
然后,将当前的逻辑计划中所有的query stages替换为LogicalQueryStage。转换后的逻辑计划有新的统计数据可用,再调用其reOptimize方法这可能会产生一个全新的、基于实用的逻辑计划和物理计划。并比较新旧计划的成本,如果新的优化计划比前一个更优化,则将其提升为新的currentPhysicalPlan和currentLogicalPlan。一旦执行了所有查询阶段,就会生成最终的物理计划。在reOptimize方法中会调用AQE逻辑层面的优化规则。
最后,会再次应用AQE的物理计划层面的优化规则,并返回最终的物理计划。
这次我们先了解AQE的调用过程,后面再继续深探其三大特性的实现源码。
了解了AQE,我们来思考几个问题:
你知道AQE是如何处理数据倾斜的吗?如果倾斜的Task全部都集中到同一个Executor那么AQE还能处理吗?
我们知道,AQE 依赖的统计信息来源于 Shuffle Map 阶段输出的中间文件。你觉得,在运行时,AQE 还有其他渠道可以获得同样的统计信息吗?