今天先从一个问题开始。
假如我们创建了一个只有两个字段的Hive分区表,且只在里面插入两行数据(如下所示),那么这个时候Spark会认为这个表有多大?
1CREATE TABLE test.table01 (
2st string COMMENT 'start time',
3et string COMMENT 'end time')
4PARTITIONED BY (dp String) stored as orc;
5insert into test.table01 partition(dp='1998') values('1990-01-15', '2022-03-24');
6insert into test.table01 partition(dp='1998') values('2022-05-15', '2022-03-24');
两行数据的表最大也不过几K大小,但如果其和另一个表进行join(在不开启CBO, 不考虑DPP的情况), 会选择Broadcast Hash Join吗?
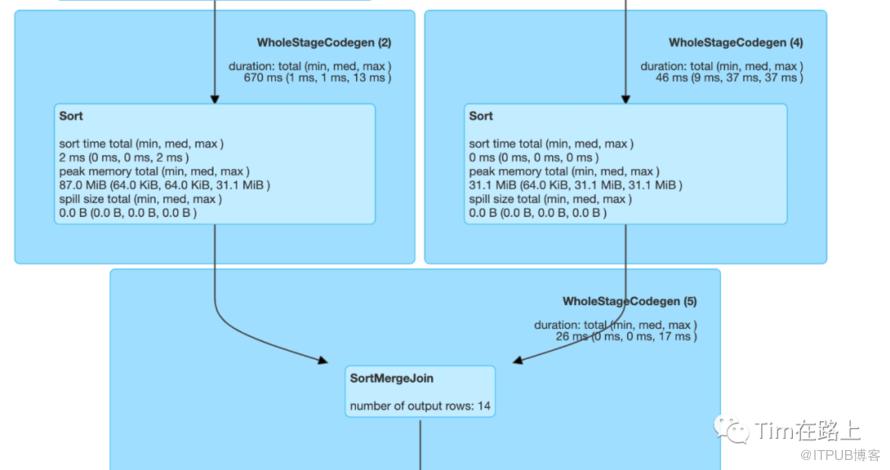
结果可能和你想的不一样,如上图所示,最终的结果其并没选择Broadcast Hash Join而是选择了Sort Merge Join, 为什么会这样呢?
那么接下来我们来分析下SparkSQL中的统计信息。
Statistics的用途
首先在SparkSQL逻辑阶段中,统计信息一般被记录在Statistics类中,最初它只计算了逻辑计划的物理大小。现在它还可以估计行数、列统计信息等。
统计信息在Spark中各处被使用,我们可以在以下这些地方找到:
Join策略的选择上,使用统计信息来确定Spark SQL Join的策略。它通过检查统计信息来校验表是否可广播,或者在Shuffle Hash Join的情况下物理计划的大小是否满足指定的阈值等。
星型表的检测,在星型模式中,区分事实表和维度表需要依赖事实表大于维度表的规则。这时基于统计信息(估计了行数和列数(空值和不同值的数量)统计信息)来判断表的类型。
full outer join和limit一起使用的情况,这时会使用统计信息比较两边的大小并限制join查询的left side或right side。
1case class Statistics(
2 sizeInBytes: BigInt,
3 rowCount: Option[BigInt] = None,
4 attributeStats: AttributeMap[ColumnStat] = AttributeMap(Nil)) {sizeInBytes: 物理大小(以字节为单位),对于叶子运算符此值默认为1, 非叶子运算符为child节点的sizeInBytes乘积。
rowCount:估计的行数
attributeStats:列属性统计信息
从Statistics类定义可以看出,统计信息主要包含三个字段sizeInBytes、rowCount和attributeStats。统计信息首先会由叶节点计算,每个叶节点会以某种方式来计算统计信息。然后他们通过某些rules应用遍历到plan树上。
那么叶节点如何计算统计信息以及传播是如何工作的呢?
如何计算统计数据
叶节点可以通过以下三种方式来计算统计信息。
从元存储中获取统计信息;
Spark 将使用InMemoryFileIndex,通过调用 Hadoop API 来收集数据源中每个文件的大小并将其相加得到总sizeInBytes;
Spark 将使用spark.sql.defaultSizeInBytes配置作为的sizeInBytes指标的默认值,该默认值为 8 EiB。
上面的图很好的总结了Spark在计算统计信息时采取的策略方法。
我们以开头的例子为例:首先test.table01是一个Hive表,它是属于CatalogTable的(其中T表示true, F代表False)。另外我们没有开启CBO, 同时之前也没进行Analyze Table分析。此外test.table01是一个分区表,所以最终将使用spark.sql.defaultSizeInBytes配置作为的sizeInBytes指标的默认值。
下面我们再从代码层面进行分析, 这里还是以Hive表为例:
当我们执行SparkSQL查询Hive表时,会先通过Catalyst将SQL转换为plan树,然后通过应用rule将其从未解析的逻辑计划转换为解析的逻辑计划。在扫描解析Hive表relation时,主要应用的有ResolveRelations和FindDataSourceTable规则。表统计信息的确定是在DetermineTableStats规则中,下面先来看下DetermineTableStats规则是如何实现的。
1class DetermineTableStats(session: SparkSession) extends Rule[LogicalPlan] {
2 private def hiveTableWithStats(relation: HiveTableRelation): HiveTableRelation = {
3 val table = relation.tableMeta
4 val partitionCols = relation.partitionCols
5 val conf = session.sessionState.conf
6 // For partitioned tables, the partition directory may be outside of the table directory.
7 // Which is expensive to get table size. Please see how we implemented it in the AnalyzeTable.
8 // [1] 如果开启了fallBackToHdfsForStats,同时是非分区表,则通过调用Hadoop API进行统计信息
9 val sizeInBytes = if (conf.fallBackToHdfsForStatsEnabled && partitionCols.isEmpty) {
10 try {
11 val hadoopConf = session.sessionState.newHadoopConf()
12 val tablePath = new Path(table.location)
13 val fs: FileSystem = tablePath.getFileSystem(hadoopConf)
14 fs.getContentSummary(tablePath).getLength
15 } catch {
16 case e: IOException =>
17 logWarning("Failed to get table size from HDFS.", e)
18 conf.defaultSizeInBytes
19 }
20 // [2] 否则则采用conf.defaultSizeInBytes
21 } else {
22 conf.defaultSizeInBytes
23 }
24
25 val stats = Some(Statistics(sizeInBytes = BigInt(sizeInBytes)))
26 relation.copy(tableStats = stats)
27 }
[1] 如果开启了fallBackToHdfsForStats,同时是非分区表,则通过调用Hadoop API进行统计信息 [2] 否则则采用conf.defaultSizeInBytes
所以说在查询plan中对于分区的Hive表默认使用的表大小为 Long.MaxValue,它是大于spark.sql.autoBroadcastJoinThreshold,这里的策略是比较保守的。也就是说,默认情况下,Join策略选择规则不会选择其作为broadcast Table,除非它可以确定表的尺寸足够小。
这也就是为什么在开头创建的Hive表在进行Join时,并不会如我们所想的选择BHJ。
SparkSQL使用访问者模式和mixin来在逻辑计划阶段实现统计信息的传播,要实现统计信息的传播就需要实现LogicalPlanStats接口,这样就可以直接在逻辑计划中通过stats来获取当前节点的统计信息。
1trait LogicalPlanStats { self: LogicalPlan =>
2
3 def stats: Statistics = statsCache.getOrElse {
4 if (conf.cboEnabled) {
5 statsCache = Option(BasicStatsPlanVisitor.visit(self))
6 } else {
7 statsCache = Option(SizeInBytesOnlyStatsPlanVisitor.visit(self))
8 }
9 statsCache.get
10 }
1object SizeInBytesOnlyStatsPlanVisitor extends LogicalPlanVisitor[Statistics] {
2
3 private def visitUnaryNode(p: UnaryNode): Statistics = {
4 // There should be some overhead in Row object, the size should not be zero when there is
5 // no columns, this help to prevent divide-by-zero error.
6 val childRowSize = EstimationUtils.getSizePerRow(p.child.output)
7 val outputRowSize = EstimationUtils.getSizePerRow(p.output)
8 // Assume there will be the same number of rows as child has.
9 var sizeInBytes = (p.child.stats.sizeInBytes * outputRowSize) / childRowSize
10 if (sizeInBytes == 0) {
11 // sizeInBytes can't be zero, or sizeInBytes of BinaryNode will also be zero
12 // (product of children).
13 sizeInBytes = 1
14 }
15
16 // Don't propagate rowCount and attributeStats, since they are not estimated here.
17 Statistics(sizeInBytes = sizeInBytes)
18 }
可以看出获取当前运算符的sizeInBytes非常简单且粗略,公式是(childPhysicalSize*outputRowSize)/childRowSize,它是基于child plan和输出行的大小。现在我们再展开getSizePerRow方法,看下RowSize是如何计算的:
1def getSizePerRow(
2 attributes: Seq[Attribute],
3 attrStats: AttributeMap[ColumnStat] = AttributeMap(Nil)): BigInt = {
4 // We assign a generic overhead for a Row object, the actual overhead is different for different
5 // Row format.
6 8 + attributes.map { attr =>
7 if (attrStats.get(attr).map(_.avgLen.isDefined).getOrElse(false)) {
8 attr.dataType match {
9 case StringType =>
10 // string 类型的大小为 8 + 8 + 4 = 20
11 // UTF8String: base + offset + numBytes
12 attrStats(attr).avgLen.get + 8 + 4
13 case _ =>
14 attrStats(attr).avgLen.get
15 }
16 } else {
17 attr.dataType.defaultSize
18 }
19 }.sum
20}
但并非所有的所有的plan节点都是这么计算,一些特定的plan节点可能会覆盖这个结果。在SizeInBytesOnlyStatsPlanVisitor类(没有开启CBO)中,除了visitUnaryNode方法外。还有些特定方法,如visitFilter,visitProject,visitJoin等。
1override def visitFilter(p: Filter): Statistics = visitUnaryNode(p)
2
3override def visitProject(p: Project): Statistics = visitUnaryNode(p)
4
5 override def visitJoin(p: Join): Statistics = {
6 p.joinType match {
7 case LeftAnti | LeftSemi =>
8 // LeftSemi and LeftAnti won't ever be bigger than left
9 p.left.stats
10 case _ =>
11 default(p)
12 }
13 }
14
我们再来看下在开启CBO的情况下Filter算子统计估值:
1object BasicStatsPlanVisitor extends LogicalPlanVisitor[Statistics] {
2 override def visitFilter(p: Filter): Statistics = {
3 FilterEstimation(p).estimate.getOrElse(fallback(p))
4 }
在visitFilter中调用了FilterEstimation.estimate的方法,下面我们展开看看。
1def estimate: Option[Statistics] = {
2 if (childStats.rowCount.isEmpty) return None
3
4 // Estimate selectivity of this filter predicate, and update column stats if needed.
5 // For not-supported condition, set filter selectivity to a conservative estimate 100%
6 val filterSelectivity = calculateFilterSelectivity(plan.condition).getOrElse(1.0)
7
8 val filteredRowCount: BigInt = ceil(BigDecimal(childStats.rowCount.get) * filterSelectivity)
9 val newColStats = if (filteredRowCount == 0) {
10 // The output is empty, we don't need to keep column stats.
11 AttributeMap[ColumnStat](Nil)
12 } else {
13 colStatsMap.outputColumnStats(rowsBeforeFilter = childStats.rowCount.get,
14 rowsAfterFilter = filteredRowCount)
15 }
16 val filteredSizeInBytes: BigInt = getOutputSize(plan.output, filteredRowCount, newColStats)
17
18 Some(childStats.copy(sizeInBytes = filteredSizeInBytes, rowCount = Some(filteredRowCount),
19 attributeStats = newColStats))
20}
在开启CBO的情况下,计算sizeInBytes会首先根据每一列的数据类型信息计算单行的大小,然后乘以rowCount得到最终的sizeInBytes。如果rowCount为零,则将sizeInBytes设置为 1 以避免在其他一些统计信息计算中除以零。
那么如何查看逻辑计划Plan中的sizeInBytes统计信息呢,可以通过explain查看其逻辑计划来查看:

CBO是如何使用统计信息的
Cost-based optimizer(CBO)基于数据表的统计信息(如表大小、数据列分布)来选择优化策略。CBO 支持的统计信息很丰富,比如数据表的行数、每列的基数(Cardinality)、空值数、最大值、最小值和直方图等等。
在CBO中使用统计信息主要是在joinReorder Rule中,使用这个Rule, Spark可以更加精准的选择Join策略,避免在小表join的情况下仍然使用SMJ。
但此规则默认是关闭的使用前需要打开如下配置:
1spark.sql.cbo.enabled=true
2spark.sql.cbo.joinReorder.enabled=true
此外CBO规则的优化依赖于表的统计信息,需要在执行SQL前先运行Analysis Table语句收集统计信息,而各类信息的收集会消耗大量时间:
1ANALYZE TABLE table_name COMPUTE STATISTICS;
2ANALYZE TABLE table_name COMPUTE STATISTICS FOR COLUMNS col_name
3DESCRIBE EXTENDED table_name column_name
CBO 仅支持注册到 Hive Metastore 的数据表,但在大量的应用场景中,数据源往往是存储在分布式文件系统的各类文件,如 Parquet、ORC、CSV 等等。此外,如果在运行时数据分布发生动态变化,CBO 先前制定的执行计划并不会跟着调整、适配。
AQE是如何使用统计信息的
在Adaptive Query Execution ( AQE )中,以更加增强的方式使用统计信息。如果启用了AQE,则在运行时执行每个阶段后利用落盘的数据重新计算统计信息。
1// ShuffleExchangeExec
2override def runtimeStatistics: Statistics = {
3 val dataSize = metrics("dataSize").value
4 val rowCount = metrics(SQLShuffleWriteMetricsReporter.SHUFFLE_RECORDS_WRITTEN).value
5 Statistics(dataSize, Some(rowCount))
6}
7
1def computeStats(): Option[Statistics] = resultOption.map { _ =>
2 // Metrics `dataSize` are available in both `ShuffleExchangeExec` and `BroadcastExchangeExec`.
3 val exchange = plan match {
4 case r: ReusedExchangeExec => r.child
5 case e: Exchange => e
6 case _ => throw new IllegalStateException("wrong plan for query stage:\n " + plan.treeString)
7 }
8 Statistics(sizeInBytes = exchange.metrics("dataSize").value)
9}
总结下,本篇文章的知识点:
Spark中的统计信息首先会由叶节点计算,然后在逻辑计划阶段传播应用到plan树中。
叶节点的统计信息可以通过以下三种方式来估计:
从元存储中获取统计信息
Spark 将使用InMemoryFileIndex,通过调用 Hadoop API 来收集数据源中每个文件的大小并将其相加得到总sizeInBytes。
Spark 将使用spark.sql.defaultSizeInBytes配置作为的sizeInBytes指标的默认值,该默认值为 8 EiB。
使用访问者模式和mixin来在逻辑计划阶段实现统计信息的传播,要实现统计信息的传播就需要实现LogicalPlanStats接口。
Spark默认的plan运算符的sizeInBytes非常简单且粗略, Filter和Project运算符根本不调整值。
使用CBO可以根据先前运行Analysis Table语句收集统计信息(各类信息的收集会消耗大量时间)获取更加精准的sizeInBytes。
使用AQE主要是基于QueryStage阶段落盘的数据信息,在运行时重新计算统计信息,动态的更新逻辑计划和物理计划。