在Spark中shuffleWriter有三种实现,分别是bypassMergeSortShuffleWriter, UnsafeShuffleWriter和SortShuffleWriter。但是shuffleReader却只有一种实现BlockStoreShuffleReader 。
从上一讲中可以知道,这时Spark已经获取到了shuffle元数据包括每个mapId和其location信息,并将其传递给BlockStoreShuffleReader类。接下来我们来详细分析下BlockStoreShuffleReader的实现。
1// BlockStoreShuffleReader
2override def read(): Iterator[Product2[K, C]] = {
3 // [1] 初始化ShuffleBlockFetcherIterator,负责从executor中获取 shuffle 块
4 val wrappedStreams = new ShuffleBlockFetcherIterator(
5 context,
6 blockManager.blockStoreClient,
7 blockManager,
8 mapOutputTracker,
9 blocksByAddress,
10 ...
11 readMetrics,
12 fetchContinuousBlocksInBatch).toCompletionIterator
13
14 val serializerInstance = dep.serializer.newInstance()
15
16 // [2] 将shuffle 块反序列化为record迭代器
17 // Create a key/value iterator for each stream
18 val recordIter = wrappedStreams.flatMap { case (blockId, wrappedStream) =>
19 // Note: the asKeyValueIterator below wraps a key/value iterator inside of a
20 // NextIterator. The NextIterator makes sure that close() is called on the
21 // underlying InputStream when all records have been read.
22 serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
23 }
24
25 // Update the context task metrics for each record read.
26 val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
27 recordIter.map { record =>
28 readMetrics.incRecordsRead(1)
29 record
30 },
31 context.taskMetrics().mergeShuffleReadMetrics())
32
33 // An interruptible iterator must be used here in order to support task cancellation
34 val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
35 // [3] reduce端聚合数据:如果map端已经聚合过了,则对读取到的聚合结果进行聚合。如果map端没有聚合,则针对未合并的进行聚合。
36 val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
37 if (dep.mapSideCombine) {
38 // We are reading values that are already combined
39 val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
40dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
41 } else {
42 // We don't know the value type, but also don't care -- the dependency *should*
43 // have made sure its compatible w/ this aggregator, which will convert the value
44 // type to the combined type C
45 val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
46dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
47 }
48 } else {
49 interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
50 }
51 // [4] reduce端排序数据:如果需要对key排序,则进行排序。基于sort的shuffle实现过程中,默认只是按照partitionId排序。在每一个partition内部并没有排序,因此添加了keyOrdering变量,提供是否需要对分区内部的key排序
52 // Sort the output if there is a sort ordering defined.
53 val resultIter: Iterator[Product2[K, C]] =dep.keyOrdering match {
54 caseSome(keyOrd: Ordering[K]) =>
55 // Create an ExternalSorter to sort the data.
56 val sorter =
57 new ExternalSorter[K, C, C](context, ordering =Some(keyOrd), serializer =dep.serializer)
58 sorter.insertAllAndUpdateMetrics(aggregatedIter)
59 case None =>
60 aggregatedIter
61 }
62
63 // [5] 返回结果集迭代器
64 resultIter match {
65 case _: InterruptibleIterator[Product2[K, C]] => resultIter
66 case _ =>
67 // Use another interruptible iterator here to support task cancellation as aggregator
68 // or(and) sorter may have consumed previous interruptible iterator.
69 new InterruptibleIterator[Product2[K, C]](context, resultIter)
70 }
71}
从上面可见,在BlockStoreShuffleReader.read()读取数据有五步:
[1] 初始化ShuffleBlockFetcherIterator,负责从executor中获取 shuffle 块;
[2] 将shuffle 块反序列化为record迭代器;
[3] reduce端聚合数据:如果map端已经聚合过了,则对读取到的聚合结果进行聚合。如果map端没有聚合,则针对未合并的进行聚合;
[4] reduce端排序数据:如果需要对key排序,则进行排序。基于sort的shuffle实现过程中,默认只是按照partitionId排序。在每一个partition内部并没有排序,因此添加了keyOrdering变量,提供是否需要对分区内部的key排序;
[5] 返回结果集迭代器。
下面我们详细分析下ShuffleBlockFetcherIterator是如何进行fetch数据的:
ShuffleBlockFetcherIterator是如何进行fetch数据的?
当shuffle reader创建 ShuffleBlockFetcherIterator 的实例时,迭代器调用在其initialize()方法。
1// ShuffleBlockFetcherIterator
2private[this] def initialize(): Unit = {
3 // Add a task completion callback (called in both success case and failure case) to cleanup.
4 context.addTaskCompletionListener(onCompleteCallback)
5 // Local blocks to fetch, excluding zero-sized blocks.
6 val localBlocks = mutable.LinkedHashSet[(BlockId, Int)]()
7 val hostLocalBlocksByExecutor =
8 mutable.LinkedHashMap[BlockManagerId, Seq[(BlockId, Long, Int)]]()
9 val pushMergedLocalBlocks = mutable.LinkedHashSet[BlockId]()
10 // [1] 划分数据源的请求:本地、主机本地和远程块
11 // Partition blocks by the different fetch modes: local, host-local, push-merged-local and
12 // remote blocks.
13 val remoteRequests = partitionBlocksByFetchMode(
14 blocksByAddress, localBlocks, hostLocalBlocksByExecutor, pushMergedLocalBlocks)
15 // [2] 以随机顺序将远程请求添加到我们的队列中
16 // Add the remote requests into our queue in a random order
17 fetchRequests ++= Utils.randomize(remoteRequests)
18 assert((0 ==reqsInFlight) == (0 ==bytesInFlight),
19 "expected reqsInFlight = 0 but found reqsInFlight = " +reqsInFlight+
20 ", expected bytesInFlight = 0 but found bytesInFlight = " +bytesInFlight)
21
22 // [3] 发送remote fetch请求
23 // Send out initial requests for blocks, up to our maxBytesInFlight
24 fetchUpToMaxBytes()
25
26 val numDeferredRequest = deferredFetchRequests.values.map(_.size).sum
27 val numFetches = remoteRequests.size -fetchRequests.size - numDeferredRequest
28 logInfo(s"Started$numFetches remote fetches in${Utils.getUsedTimeNs(startTimeNs)}" +
29 (if (numDeferredRequest > 0 ) s", deferred$numDeferredRequest requests" else ""))
30 // [4] 支持executor获取local和remote的merge shuffle数据
31 // Get Local Blocks
32 fetchLocalBlocks(localBlocks)
33 logDebug(s"Got local blocks in${Utils.getUsedTimeNs(startTimeNs)}")
34 // Get host local blocks if any
35 fetchAllHostLocalBlocks(hostLocalBlocksByExecutor)
36pushBasedFetchHelper.fetchAllPushMergedLocalBlocks(pushMergedLocalBlocks)
37}
在shuffle fetch的迭代器中,获取数据请求有下面四步:
[1] 通过不同的获取模式对块进行分区:本地、主机本地和远程块
[2] 以随机顺序将远程请求添加到我们的队列中
[3] 发送remote fetch请求
[4] 获取local blocks
[5] 获取host blocks
[6] 获取pushMerge的local blocks
接下来分析下划分数据源的请求的过程
1private[this] def partitionBlocksByFetchMode(
2 blocksByAddress: Iterator[(BlockManagerId, Seq[(BlockId, Long, Int)])],
3 localBlocks: mutable.LinkedHashSet[(BlockId, Int)],
4 hostLocalBlocksByExecutor: mutable.LinkedHashMap[BlockManagerId, Seq[(BlockId, Long, Int)]],
5 pushMergedLocalBlocks: mutable.LinkedHashSet[BlockId]): ArrayBuffer[FetchRequest] = {
6 ...
7
8val fallback = FallbackStorage.FALLBACK_BLOCK_MANAGER_ID.executorId
9 val localExecIds =Set(blockManager.blockManagerId.executorId, fallback)
10 for ((address, blockInfos) <- blocksByAddress) {
11 checkBlockSizes(blockInfos)
12 // [1] 如果是push-merged blocks, 判断其是否是主机的还是远程请求
13 if (pushBasedFetchHelper.isPushMergedShuffleBlockAddress(address)) {
14 // These are push-merged blocks or shuffle chunks of these blocks.
15 if (address.host == blockManager.blockManagerId.host) {
16numBlocksToFetch+= blockInfos.size
17 pushMergedLocalBlocks ++= blockInfos.map(_._1)
18 pushMergedLocalBlockBytes += blockInfos.map(_._2).sum
19 } else {
20 collectFetchRequests(address, blockInfos, collectedRemoteRequests)
21 }
22 // [2] 如果是localexecIds, 放入localBlocks
23 } else if (localExecIds.contains(address.executorId)) {
24 val mergedBlockInfos =mergeContinuousShuffleBlockIdsIfNeeded(
25 blockInfos.map(info =>FetchBlockInfo(info._1, info._2, info._3)), doBatchFetch)
26numBlocksToFetch+= mergedBlockInfos.size
27 localBlocks ++= mergedBlockInfos.map(info => (info.blockId, info.mapIndex))
28 localBlockBytes += mergedBlockInfos.map(_.size).sum
29 // [3] 如果是host本地,并将其放入hostLocalBlocksByExecutor
30 } else if (blockManager.hostLocalDirManager.isDefined &&
31 address.host == blockManager.blockManagerId.host) {
32 val mergedBlockInfos =mergeContinuousShuffleBlockIdsIfNeeded(
33 blockInfos.map(info =>FetchBlockInfo(info._1, info._2, info._3)), doBatchFetch)
34numBlocksToFetch+= mergedBlockInfos.size
35 val blocksForAddress =
36 mergedBlockInfos.map(info => (info.blockId, info.size, info.mapIndex))
37 hostLocalBlocksByExecutor += address -> blocksForAddress
38 numHostLocalBlocks += blocksForAddress.size
39 hostLocalBlockBytes += mergedBlockInfos.map(_.size).sum
40 // [4] 如果是remote请求,收集fetch请求, 每个请求的最大请求数据大小,是max(maxBytesInFlight / 5, 1L),这是为了提高请求的并发度,保证至少向5个不同的节点发送请求获取数据,最大限度地利用各节点的资源
41 } else {
42 val (_, timeCost) = Utils.timeTakenMs[Unit] {
43 collectFetchRequests(address, blockInfos, collectedRemoteRequests)
44 }
45 logDebug(s"Collected remote fetch requests for$address in$timeCost ms")
46 }
47 }
48 val (remoteBlockBytes, numRemoteBlocks) =
49 collectedRemoteRequests.foldLeft((0L, 0))((x, y) => (x._1 + y.size, x._2 + y.blocks.size))
50 val totalBytes = localBlockBytes + remoteBlockBytes + hostLocalBlockBytes +
51 pushMergedLocalBlockBytes
52 val blocksToFetchCurrentIteration =numBlocksToFetch- prevNumBlocksToFetch
53 ...
54 this.hostLocalBlocks++= hostLocalBlocksByExecutor.values
55 .flatMap { infos => infos.map(info => (info._1, info._3)) }
56 collectedRemoteRequests
57}
划分数据源总共有以下四步:
[1] 如果是push-merged blocks, 判断其是否是主机的还是远程请求
[2] 如果是localexecIds, 放入localBlocks
[3] 如果是host本地,并将其放入hostLocalBlocksByExecutor
[4] 如果是remote请求,收集fetch请求, 每个请求的最大请求数据大小,是max(maxBytesInFlight / 5, 1L),这是为了提高请求的并发度,保证至少向5个不同的节点发送请求获取数据,最大限度地利用各节点的资源
在划分完数据的请求类别后,会依次的进行remote fetch请求,local blocks请求,host blocks请求和获取pushMerge的local blocks。
那么数据是如何被Fetch的呢?接下来我们看下fetchUpToMaxBytes()方法。
1private def fetchUpToMaxBytes(): Unit = {
2 // [1] 如果是延迟请求,如果可以远程块Fetch同时是未达到处理请求的字节数,进行send请求
3 if (deferredFetchRequests.nonEmpty) {
4 for ((remoteAddress, defReqQueue) <-deferredFetchRequests) {
5 while (isRemoteBlockFetchable(defReqQueue) &&
6 !isRemoteAddressMaxedOut(remoteAddress, defReqQueue.front)) {
7 val request = defReqQueue.dequeue()
8 logDebug(s"Processing deferred fetch request for$remoteAddress with "
9 + s"${request.blocks.length} blocks")
10 send(remoteAddress, request)
11 if (defReqQueue.isEmpty) {
12deferredFetchRequests-= remoteAddress
13 }
14 }
15 }
16 }
17
18 // [2] 如果正常可以远程Fetch请求,直接send请求;如果达到处理请求的字节,则创建remoteAddress的延迟请求
19 // Process any regular fetch requests if possible.
20 while (isRemoteBlockFetchable(fetchRequests)) {
21 val request = fetchRequests.dequeue()
22 val remoteAddress = request.address
23 if (isRemoteAddressMaxedOut(remoteAddress, request)) {
24 logDebug(s"Deferring fetch request for$remoteAddress with${request.blocks.size} blocks")
25 val defReqQueue = deferredFetchRequests.getOrElse(remoteAddress, new Queue[FetchRequest]())
26 defReqQueue.enqueue(request)
27deferredFetchRequests(remoteAddress) = defReqQueue
28 } else {
29 send(remoteAddress, request)
30 }
31 }
32}
Fetch请求字节数据:
[1] 如果是延迟请求,如果可以远程块Fetch同时是未达到处理请求的字节数,进行send请求
-
[2] 如果正常可以远程Fetch请求,直接send请求;如果达到处理请求的字节,则创建remoteAddress的延迟请求
它会验证该请求是否应被视为延迟。如果是,则将其添加到deferredFetchRequests中。否则,它会继续并从BlockStoreClient实现发送请求(如果启用了 shuffle 服务,则为ExternalBlockStoreClient ,否则为NettyBlockTransferService)。
1// ShuffleBlockFetcherIterator
2private[this] def sendRequest(req: FetchRequest): Unit = {
3 // ...
4 // [1] 创建了一个**BlockFetchingListener**,在完成请求后会被调用
5 val blockFetchingListener = new BlockFetchingListener {
6 override def onBlockFetchSuccess(blockId: String, buf: ManagedBuffer): Unit = {
7 // ...
8 remainingBlocks -= blockId
9 results.put(new SuccessFetchResult(BlockId(blockId), infoMap(blockId)._2,
10 address, infoMap(blockId)._1, buf, remainingBlocks.isEmpty))
11 // ...
12 }
13 override def onBlockFetchFailure(blockId: String, e: Throwable): Unit = {
14 results.put(new FailureFetchResult(BlockId(blockId), infoMap(blockId)._2, address, e))
15 }
16 }
17
18 // Fetch remote shuffle blocks to disk when the request is too large. Since the shuffle data is
19 // already encrypted and compressed over the wire(w.r.t. the related configs), we can just fetch
20 // the data and write it to file directly.
21 // [2] 如果请求大小超过可以存储在内存中的请求的最大大小 ,则迭代器通过可选地定义DownloadFileManager来发送获取请求
22 if (req.size > maxReqSizeShuffleToMem) {
23 shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray,
24 blockFetchingListener, this)
25 } else {
26 shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray,
27 blockFetchingListener, null)
28 }
在sendRequest中主要进行了以下两个步骤:
[1] 创建了一个BlockFetchingListener,在完成请求后会被调用
[2] 如果请求大小超过可以存储在内存中的请求的最大大小 ,则迭代器通过可选地定义DownloadFileManager来发送获取请求
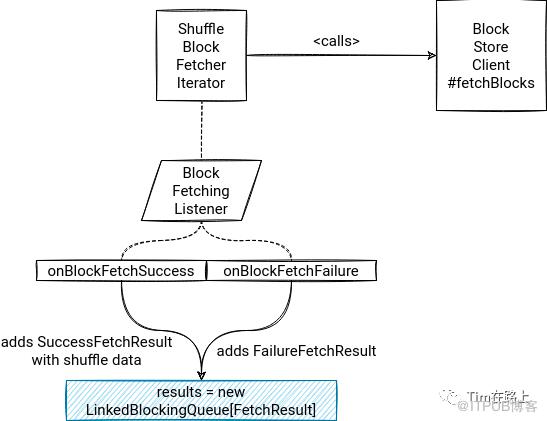
首先,ShuffleBlockFetcherIterator迭代器创建了一个BlockFetchingListener,在其中定义成功执行和实现执行后的回调函数,如果成功执行,它会首先为迭代器加synchronized锁,然后将块数据添加到结果变量中。如果发生错误,同样会先加synchronized锁,然后它将添加一个标记类来指示获取失败。
其次,在ShuffleBlockFetcherIterator类的初始化中会调用BlockStoreClient的fetchBlocks方法,在调用前会判断请求的内容的大小,如果超过门限,则传参定义DownloadFileManager,它会使得shuffleData将被下载到临时文件。
下面我们看下最终的fetchBlocks是如何实现的?
1@Override
2public void fetchBlocks(
3 String host,
4 int port,
5 String execId,
6 String[] blockIds,
7 BlockFetchingListener listener,
8 DownloadFileManager downloadFileManager) {
9 checkInit();
10 logger.debug("External shuffle fetch from {}:{} (executor id {})", host, port, execId);
11 try {
12 // [1] 首先创建并初始化RetryingBlockFetcher类,用它加载shuffle files
13 int maxRetries = transportConf.maxIORetries();
14 RetryingBlockTransferor.BlockTransferStarter blockFetchStarter =
15 (inputBlockId, inputListener) -> {
16 // Unless this client is closed.
17 if (clientFactory != null) {
18 assert inputListener instanceof BlockFetchingListener :
19 "Expecting a BlockFetchingListener, but got " + inputListener.getClass();
20 TransportClient client = clientFactory.createClient(host, port, maxRetries > 0);
21 // [2] 创建OneForOneBlockFetcher,用其进行下载shuffle Data
22 new OneForOneBlockFetcher(client, appId, execId, inputBlockId,
23 (BlockFetchingListener) inputListener, transportConf, downloadFileManager).start();
24 } else {
25 logger.info("This clientFactory was closed. Skipping further block fetch retries.");
26 }
27 };
28 ...
29 // [3] 调用OneForOneBlockFetcher的start方法
30 blockFetchStarter.createAndStart(blockIds, listener);
31 }
32}
[1] 首先创建并初始化RetryingBlockFetcher类,用它加载shuffle files
[2] 创建OneForOneBlockFetcher,用其进行下载shuffle Data
OneForOneBlockFetcher进行Shuffle 数据的下载
OneForOneBlockFetcher是基于RPC通信,从各个Executor端获取shuffle数据,我们首先来简要概述下:
首先,fetcher 会向持有 shuffle 文件的 executor发送FetchShuffleBlocks消息;
其次,executor将register new Stream 同时返回StreamHandle消息到fetcher, 它带有streamId;
在收到StreamHandle响应后,client将stream或load 数据块;
如果downloadFileManager 不为空,则会将结果写入临时文件;对于内存的场景,shuffle bytes将加载到in-memory buffer中;
最终,基于临时文件还是基于内存都会调用sendRequest中定义的BlockFetchingListener回调函数。
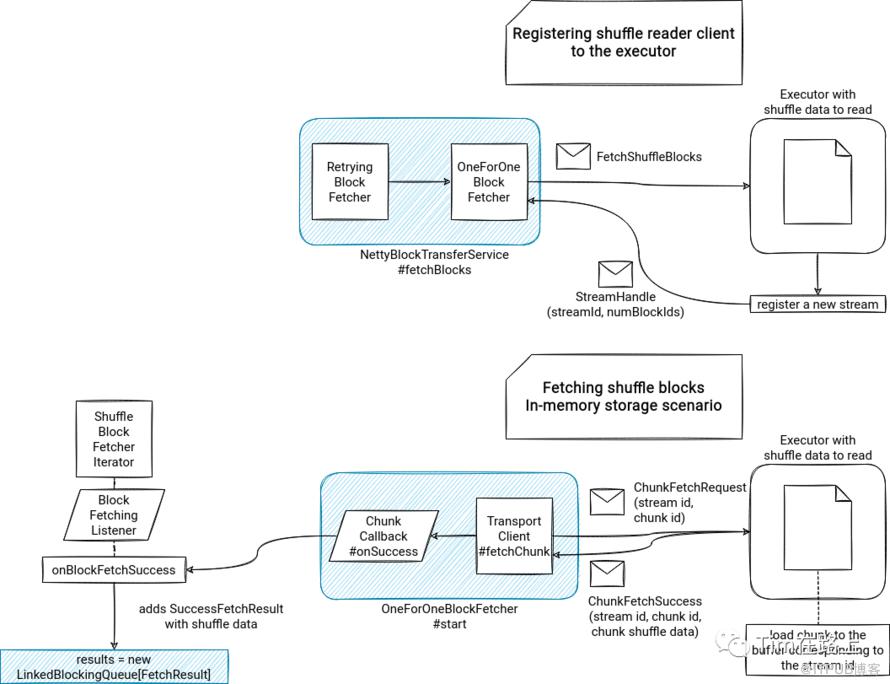
获取到的shuffle data会被放入到new LinkedBlockingQueue[FetchResult],并调用next()方法。如果所有可用的块数据都已被消耗,迭代器将执行之前提供的 fetchUpToMaxBytes()。
到此为止,shuffle reader的大致过程已经走了一遍,但是还有很多的重要细节并没有展开探讨,那么这里就详细总结下整体的流程:
Fetch前的准备
fetch reader 的调用主要是ShuffledRDD和ShuffledRowRDD中,通过传入 不同的partitionspecs给getReader传入不同的调用参数。
在getReader中会先通过mapOutputTracker获取mapid对应的shuffle文件的位置,然后在通过
BlockStoreShuffleReaderreader的唯一实现类进行shuffle fetch;在Driver端mapOutputTracker记录mapId和对应的文件位置主要由MapOutputTrackerMaster进行维护,在创建mapShuffleStage时会向master tracker中注册shuffleid, 在完成mapStage时会更新对应shuffleId中维护的mapid对应的位置信息。在Executor端从MapOutputTrackerWorker中获取位置信息,如果获取不到会向master tracker发送信息,同步信息过来;
处理Fetch请求
在BlockStoreShuffleReader中进行fetch时,会先创建ShuffleBlockFetcherIterator, 并将Fetch分为local, host local, remote不同方式;同时在Fetch时也会有些限制,包括每个Excutor阻塞的fetch request数和fetch shuffle数据是否大于分配的内存;如果请求的数据量过多,超过了内存限制,将通过写入临时文件实现;如果网络通信开销太大,fetcher 将停止读取,并在需要下一个 shuffle 块文件时恢复读取。
最终的Fetch是通过OneForOneBlockFetcher实现的,fetcher 会向持有 shuffle 文件的 executor发送FetchShuffleBlocks消息,executor将register new Stream 同时将数据封装为StreamHandle消息返回到fetcher,client最后再将加载数据块;最终调用BlockFetchingListener回调函数。
Fetch后的处理
-
reduce端聚合数据:如果map端已经聚合过了,则对读取到的聚合结果进行聚合。如果map端没有聚合,则针对未合并的
进行聚合。 ,v> reduce端排序数据:如果需要对key排序,则进行排序。基于sort的shuffle实现过程中,默认只是按照partitionId排序。在每一个partition内部并没有排序,因此添加了keyOrdering变量,提供是否需要对分区内部的key排序
另外需要注意的是SparkSQL中并不会设置ShuffleDependency的排序和聚合,而是通过规则在逻辑树中插入Sort算子实现的。
了解完Shuffle Reader下面是一些思考题:
为什么在调用getReader时要根据partitionspecs的不同传递不同的参数?主要的作用是什么?
远程Fetch和本地Fetch最大的区别是什么?
InterruptibleIterator 和 CompletionIterator 迭代器的作用是什么?
SparkSQL中并不会设置ShuffleDependency的排序和聚合,那么是如何实现排序的?