Unsafe Shuffle的实现在一定程度上是Tungsten内存管理优化的的主要应用场景。其实现过程实际上和SortShuffleWriter是类似的,但是其中维护和执行的数据结构是不一样的。
UnsafeShuffleWriter 源码解析
1@Override
2public void write(scala.collection.Iterator> records) throws IOException {
3 // Keep track of success so we know if we encountered an exception
4 // We do this rather than a standard try/catch/re-throw to handle
5 // generic throwables.
6 // [1] 使用success记录write是否成功,判断是write阶段的异常还是clean阶段
7 boolean success = false;
8 try {
9 // [2] 遍历所有的数据插入ShuffleExternalSorter
10 while (records.hasNext()) {
11 insertRecordIntoSorter(records.next());
12 }
13 // [3] close排序器使所有数据写出到磁盘,并将多个溢写文件合并到一起
14 closeAndWriteOutput();
15 success = true;
16 } finally {
17 if (sorter != null) {
18 try {
19 // [4] 清除并释放资源
20 sorter.cleanupResources();
21 } catch (Exception e) {
22 // Only throw this error if we won't be masking another
23 // error.
24 if (success) {
25 throw e;
26 } else {
27logger.error("In addition to a failure during writing, we failed during " +
28 "cleanup.", e);
29 }
30 }
31 }
32 }
33}
从上面的代码可以看出,UnsafeShuffleWriter的write过程如下:
[1] 使用success记录write是否成功,判断是write阶段的异常还是clean阶段
[2] 遍历所有的数据插入ShuffleExternalSorter
[3] close排序器使所有数据写出到磁盘,并将多个溢写文件合并到一起
[4] 清除并释放资源
1// open()方法是在初始化UnsafeShuffleWriter调用的,其中会创建sorter, 并创建一个字节输出流,同时封装序列化流
2private void open() throws SparkException {
3 assert (sorter == null);
4 sorter = new ShuffleExternalSorter(
5 memoryManager,
6 blockManager,
7 taskContext,
8 initialSortBufferSize,
9 partitioner.numPartitions(),
10 sparkConf,
11 writeMetrics);
12 // MyByteArrayOutputStream类是ByteArrayOutputStream的简单封装,只是将内部byte[]数组暴露出来】
13 //【DEFAULT_INITIAL_SER_BUFFER_SIZE常量值是1024 * 1024,即缓冲区初始1MB大】
14 serBuffer = new MyByteArrayOutputStream(DEFAULT_INITIAL_SER_BUFFER_SIZE);
15 serOutputStream = serializer.serializeStream(serBuffer);
16}
17
18void insertRecordIntoSorter(Product2 record) throws IOException {
19 assert(sorter != null);
20 // [1] 获取record的key和partitionId
21 final K key = record._1();
22 final int partitionId = partitioner.getPartition(key);
23 // [2] 将record序列化为二进制,并写的字节数组输出流serBuffer中
24 serBuffer.reset();
25 serOutputStream.writeKey(key, OBJECT_CLASS_TAG);
26 serOutputStream.writeValue(record._2(), OBJECT_CLASS_TAG);
27 serOutputStream.flush();
28
29 final int serializedRecordSize = serBuffer.size();
30 assert (serializedRecordSize > 0);
31 // [3] 将其插入到ShuffleExternalSorter中
32 sorter.insertRecord(
33 serBuffer.getBuf(), Platform.BYTE_ARRAY_OFFSET, serializedRecordSize, partitionId);
34 }
这一步是将record插入前的准备,现将序列化为二进制存储在内存中。
[1] 获取record的key和partitionId
[2] 将record序列化为二进制,并写的字节数组输出流serBuffer中
[3]将序列化的二进制数组、partitionid和length 作为参数插入到ShuffleExternalSorter中
那么数据在ShuffleExternalSorter中写入过程是怎么样呢?
1public void insertRecord(Object recordBase, long recordOffset, int length, int partitionId)
2 throws IOException {
3
4 // [1] 判断inMemSorter中的记录是否到达了溢写阈值(默认是整数最大值),如果满足就先进行spill
5 // for tests
6 assert(inMemSorter != null);
7 if (inMemSorter.numRecords() >= numElementsForSpillThreshold) {
8logger.info("Spilling data because number of spilledRecords crossed the threshold " +
9 numElementsForSpillThreshold);
10 spill();
11 }
12 // [2] 检查inMemSorter是否有额外的空间插入,如果可以获取就扩充空间,否则进行溢写
13 growPointerArrayIfNecessary();
14 final int uaoSize = UnsafeAlignedOffset.getUaoSize();
15 // Need 4 or 8 bytes to store the record length.
16 final int required = length + uaoSize;
17 // [3] 判断当前内存空间currentPage是否有足够的内存,如果不够就申请,申请不下来就需要spill
18 acquireNewPageIfNecessary(required);
19
20 assert(currentPage != null);
21 // [4] 获取currentPage的base Object和recordAddress
22 final Object base = currentPage.getBaseObject();
23 final long recordAddress = taskMemoryManager.encodePageNumberAndOffset(currentPage, pageCursor);
24 // [5] 根据base, pageCursor, 先向当前内存空间写长度值,并移动指针
25 UnsafeAlignedOffset.putSize(base, pageCursor, length);
26 pageCursor += uaoSize;
27 // [6] 再写序列化之后的数据, 并移动指指
28 Platform.copyMemory(recordBase, recordOffset, base, pageCursor, length);
29 pageCursor += length;
30 // [7] 将recordAddress和partitionId插入inMemSorter进行排序
31 inMemSorter.insertRecord(recordAddress, partitionId);
32}
从上面分析,数据插入ShuffleExternalSorter总共需要7步:
[1] 判断inMemSorter中的记录是否到达了溢写阈值(默认是整数最大值),如果满足就先进行spill
[2] 检查inMemSorter是否有额外的空间插入,如果可以获取就扩充空间,否则进行溢写
[3] 判断当前内存空间currentPage是否有足够的内存,如果不够就申请,申请不下来就需要spill
[4] 获取currentPage的base Object和recordAddress
[5] 先向当前内存空间写长度值,并移动指针
[6] 再写序列化之后的数据, 并移动指指
[7] 将recordAddress和partitionId插入inMemSorter进行排序
从上面的介绍可以看出在整个插入过程中,主要涉及ShuffleExternalSorter和 ShuffleInMemorySorter两个数据结构类型。下面我们先来简单看下ShuffleExternalSorter 类。
1final class ShuffleExternalSorter extends MemoryConsumer implements ShuffleChecksumSupport {
2
3 private final int numPartitions;
4 private final TaskMemoryManager taskMemoryManager;
5 private final BlockManager blockManager;
6 private final TaskContext taskContext;
7 private final ShuffleWriteMetricsReporter writeMetrics;
8 private final LinkedList allocatedPages = new LinkedList<>();
9
10 private final LinkedList spills = new LinkedList<>();
11
12 /** Peak memory used by this sorter so far, in bytes. **/
13 private long peakMemoryUsedBytes;
14
15 // These variables are reset after spilling:
16 @Nullable private ShuffleInMemorySorter inMemSorter;
17 @Nullable private MemoryBlock currentPage = null;
18 private long pageCursor = -1;
19 ...
20}
可见每个ShuffleExternalSorter 中封装着ShuffleInMemorySorter类。同时封装allocatedPages、spills和currentPage。也就是说ShuffleExternalSorter使用MemoryBlock存储数据,每条记录包括长度信息和K-V Pair。
另外在 ShuffleInMemorySorter 中,通过LongArray 来存储数据,并实现了SortComparator排序方法。其中LongArray 存储的record的位置信息,主要有分区id, page id 和offset。
| ShuffleExternalSorter | 使用MemoryBlock存储数据,每条记录包括长度信息和K-V Pair |
|---|---|
| ShuffleInMemorySorter | 使用long数组存储每条记录对应的位置信息(page number + offset),以及其对应的PartitionId,共8 bytes |
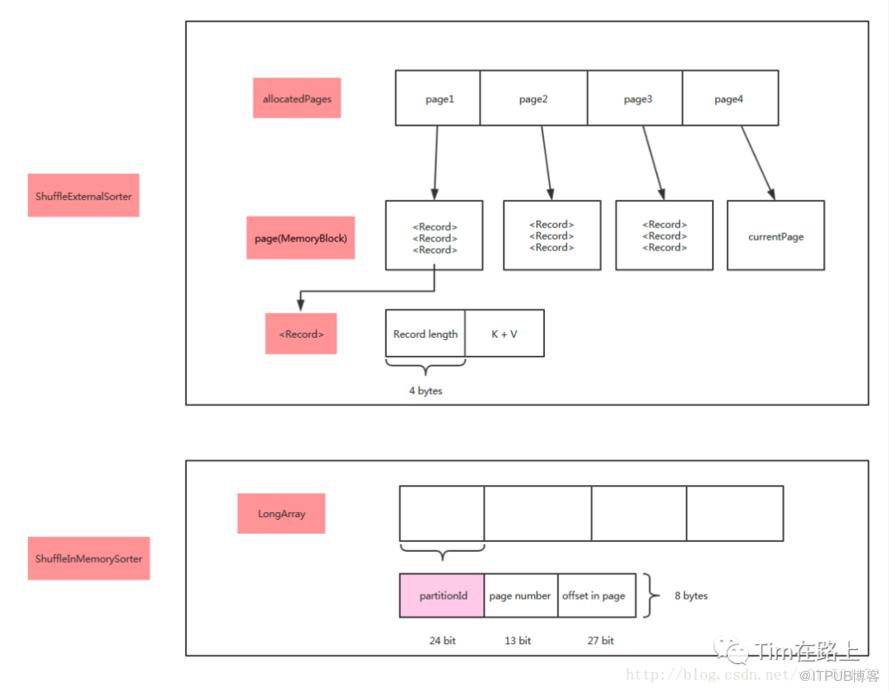
从上面的关于ShuffleExternalSorter 和ShuffleInMemorySorter 可以看出,这里其实质上是使用Tungsten实现了类似于BytesToBytesMap的数据结构,不过将其数组部分LongArray用ShuffleInMemorySorter 进行了封装,其余拆分为ShuffleExternalSorter 。
ShuffleExternalSorter 将数据写入了当前的内存空间,将数据的recordAddress和partitionId写入了ShuffleInMemorySorter ,那么其具体是如何实现排序和数据的溢写的?
1private void writeSortedFile(boolean isLastFile) {
2
3 // [1] 将inMemSorter的数据排序,并返回ShuffleSorterIterator
4 // This call performs the actual sort.
5 final ShuffleInMemorySorter.ShuffleSorterIterator sortedRecords =
6 inMemSorter.getSortedIterator();
7
8 // If there are no sorted records, so we don't need to create an empty spill file.
9 if (!sortedRecords.hasNext()) {
10 return;
11 }
12
13 final ShuffleWriteMetricsReporter writeMetricsToUse;
14
15 ...
16
17 // [2] 创建缓存数据writeBuffer数组,为了避免DiskBlockObjectWriter的低效的写
18 // Small writes to DiskBlockObjectWriter will be fairly inefficient. Since there doesn't seem to
19 // be an API to directly transfer bytes from managed memory to the disk writer, we buffer
20 // data through a byte array. This array does not need to be large enough to hold a single
21 // record;
22 final byte[] writeBuffer = new byte[diskWriteBufferSize];
23
24 // Because this output will be read during shuffle, its compression codec must be controlled by
25 // spark.shuffle.compress instead of spark.shuffle.spill.compress, so we need to use
26 // createTempShuffleBlock here; see SPARK-3426 for more details.
27 final Tuple2 spilledFileInfo =
28 blockManager.diskBlockManager().createTempShuffleBlock();
29 final File file = spilledFileInfo._2();
30 final TempShuffleBlockId blockId = spilledFileInfo._1();
31 final SpillInfo spillInfo = new SpillInfo(numPartitions, file, blockId);
32
33 // Unfortunately, we need a serializer instance in order to construct a DiskBlockObjectWriter.
34 // Our write path doesn't actually use this serializer (since we end up calling the `write()`
35 // OutputStream methods), but DiskBlockObjectWriter still calls some methods on it. To work
36 // around this, we pass a dummy no-op serializer.
37 final SerializerInstance ser = DummySerializerInstance.INSTANCE;
38
39 int currentPartition = -1;
40 final FileSegment committedSegment;
41 try (DiskBlockObjectWriter writer =
42 blockManager.getDiskWriter(blockId, file, ser, fileBufferSizeBytes, writeMetricsToUse)) {
43
44 final int uaoSize = UnsafeAlignedOffset.getUaoSize();
45 // [3] 按分区遍历已经排好序的指针数据, 并未每个分区提交一个FileSegment,并记录分区的大小
46 while (sortedRecords.hasNext()) {
47 sortedRecords.loadNext();
48 final int partition = sortedRecords.packedRecordPointer.getPartitionId();
49 assert (partition >= currentPartition);
50 if (partition != currentPartition) {
51 // Switch to the new partition
52 if (currentPartition != -1) {
53 final FileSegment fileSegment = writer.commitAndGet();
54 spillInfo.partitionLengths[currentPartition] = fileSegment.length();
55 }
56 currentPartition = partition;
57 if (partitionChecksums.length > 0) {
58 writer.setChecksum(partitionChecksums[currentPartition]);
59 }
60 }
61 // [4] 取得数据的指针,再通过指针取得页号与偏移量
62 final long recordPointer = sortedRecords.packedRecordPointer.getRecordPointer();
63 final Object recordPage = taskMemoryManager.getPage(recordPointer);
64 final long recordOffsetInPage = taskMemoryManager.getOffsetInPage(recordPointer);
65 // [5] 取得数据前面存储的长度,然后让指针跳过它
66 int dataRemaining = UnsafeAlignedOffset.getSize(recordPage, recordOffsetInPage);
67 long recordReadPosition = recordOffsetInPage + uaoSize; // skip over record length
68 // [6] 数据拷贝到上面创建的缓存中,通过缓存转到DiskBlockObjectWriter, 并写入数据,移动指针
69 while (dataRemaining > 0) {
70 final int toTransfer = Math.min(diskWriteBufferSize, dataRemaining);
71 Platform.copyMemory(
72 recordPage, recordReadPosition, writeBuffer, Platform.BYTE_ARRAY_OFFSET, toTransfer);
73 writer.write(writeBuffer, 0, toTransfer);
74 recordReadPosition += toTransfer;
75 dataRemaining -= toTransfer;
76 }
77 writer.recordWritten();
78 }
79
80 committedSegment = writer.commitAndGet();
81 }
82 // If `writeSortedFile()` was called from `closeAndGetSpills()` and no records were inserted,
83 // then the file might be empty. Note that it might be better to avoid calling
84 // writeSortedFile() in that case.
85 if (currentPartition != -1) {
86 spillInfo.partitionLengths[currentPartition] = committedSegment.length();
87 spills.add(spillInfo);
88 }
89
90 if (!isLastFile) { // i.e. this is a spill file
91 writeMetrics.incRecordsWritten(
92 ((ShuffleWriteMetrics)writeMetricsToUse).recordsWritten());
93 taskContext.taskMetrics().incDiskBytesSpilled(
94 ((ShuffleWriteMetrics)writeMetricsToUse).bytesWritten());
95 }
96}
溢写排序文件总的来说分为两步:
首先是通过ShuffleInMemorySorter排序,获取对应分区的FileSegment和长度。写文件或溢写前根据数据的PartitionId信息,使用TimSort对ShuffleInMemorySorter的long数组排序,排序的结果为,PartitionId相同的聚集在一起,且PartitionId较小的排在前面,然后按分区写出FileSegment, 并记录每个分区的长度。
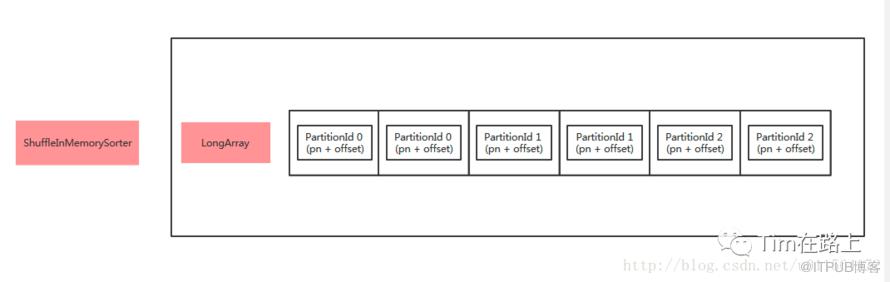
其次是基于排好序的指针执行数据的溢写操作。依次读取ShuffleInMemorySorter中long数组的元素,再根据page number和offset信息去ShuffleExternalSorter中读取K-V Pair写入文件, 溢写前先写入writeBuffer,然后在写入DiskBlockObjectWriter中。
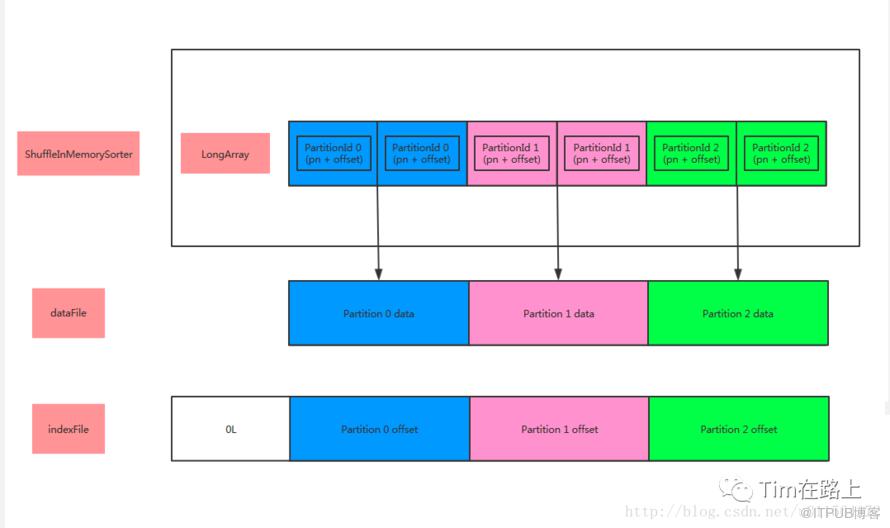
具体的步骤见下:
[1] 将inMemSorter的数据排序,并返回ShuffleSorterIterator
[2] 创建缓存数据writeBuffer数组,为了避免DiskBlockObjectWriter的低效的写
[3] 按分区遍历已经排好序的指针数据, 并未每个分区提交一个FileSegment,并记录分区的大小
[4] 取得数据的指针,再通过指针取得页号与偏移量
[5] 取得数据前面存储的长度,然后让指针跳过它
[6]数据拷贝到上面创建的缓存writeBuffer中,通过缓存转到DiskBlockObjectWriter, 并写入数据,移动指针
最后我们看下,UnsafeShuffleWriter是如何将最后溢写的文件进行合并的?
1// UnsafeShuffleWriter
2void closeAndWriteOutput() throws IOException {
3 assert(sorter != null);
4 updatePeakMemoryUsed();
5 serBuffer = null;
6 serOutputStream = null;
7 // [1] 关闭排序器,并将排序器中的数据全部溢写到磁盘,返回SpillInfo数组
8 final SpillInfo[] spills = sorter.closeAndGetSpills();
9 try {
10 // [2] 将多个溢出文件合并在一起,根据溢出次数和 IO 压缩编解码器选择最快的合并策略
11 partitionLengths = mergeSpills(spills);
12 } finally {
13 sorter = null;
14 for (SpillInfo spill : spills) {
15 if (spill.file.exists() && !spill.file.delete()) {
16logger.error("Error while deleting spill file {}", spill.file.getPath());
17 }
18 }
19 }
20 mapStatus = MapStatus$.MODULE$.apply(
21 blockManager.shuffleServerId(), partitionLengths, mapId);
22}
23
24private long[] mergeSpills(SpillInfo[] spills) throws IOException {
25 long[] partitionLengths;
26 // [1] 如果根本没有溢写文件,写一个空文件
27 if (spills.length == 0) {
28 final ShuffleMapOutputWriter mapWriter = shuffleExecutorComponents
29 .createMapOutputWriter(shuffleId, mapId, partitioner.numPartitions());
30 return mapWriter.commitAllPartitions(
31 ShuffleChecksumHelper.EMPTY_CHECKSUM_VALUE).getPartitionLengths();
32 // [2] 如果只有一个溢写文件,就直接将它写入输出文件中
33 } else if (spills.length == 1) {
34 // [2.1] 创建单个file的map output writer
35 Optional maybeSingleFileWriter =
36 shuffleExecutorComponents.createSingleFileMapOutputWriter(shuffleId, mapId);
37 if (maybeSingleFileWriter.isPresent()) {
38 // Here, we don't need to perform any metrics updates because the bytes written to this
39 // output file would have already been counted as shuffle bytes written.
40 partitionLengths = spills[0].partitionLengths;
41 logger.debug("Merge shuffle spills for mapId {} with length {}", mapId,
42 partitionLengths.length);
43 maybeSingleFileWriter.get()
44 .transferMapSpillFile(spills[0].file, partitionLengths, sorter.getChecksums());
45 } else {
46 partitionLengths = mergeSpillsUsingStandardWriter(spills);
47 }
48 // [3] 如果有多个溢写文件,如果启用并支持快速合并,并且启用了transferTo机制,还没有加密, 就使用NIO zero-copy来合并到输出文件, 不启用transferTo或不支持快速合并,就使用压缩的BIO FileStream来合并到输出文件
49 } else {
50 partitionLengths = mergeSpillsUsingStandardWriter(spills);
51 }
52 return partitionLengths;
53 }
多个spills的合并的具体的实现在mergeSpillsWithFileStream 方法中,为了减少篇幅的冗长这里就不再展开了。
溢写的文件进行合并,有如下几个步骤:
[1] 关闭排序器,并将排序器中的数据全部溢写到磁盘,返回SpillInfo数组
[2] 将多个溢出文件合并在一起,根据溢出次数和 IO 压缩编解码器选择最快的合并策略
[2.1] 如果根本没有溢写文件,写一个空文件
[2.2] 如果只有一个溢写文件,就直接将它写入输出文件中
[2.3] 如果有多个溢写文件,如果启用并支持快速合并,并且启用了transferTo机制,还没有加密, 就使用NIO zero-copy来合并到输出文件, 不启用transferTo或不支持快速合并,就使用压缩的BIO FileStream来合并到输出文件
至此,UnsafeShuffleWriter的实现就介绍完了。
下面我们谈下UnsafeShuffleWriter的优势:
ShuffleExternalSorter使用UnSafe API操作序列化数据,而不是Java对象,减少了内存占用及因此导致的GC耗时,这个优化需要Serializer支持relocation ShuffleExternalSorter存原始数据,ShuffleInMemorySorter使用压缩指针存储元数据,每条记录仅占8 bytes,并且排序时不需要处理原始数据,效率高。
溢写 & 合并这一步操作的是同一Partition的数据,因为使用UnSafe API直接操作序列化数据,合并时不需要反序列化数据。
溢写 & 合并可以使用fastMerge提升效率(调用NIO的transferTo方法),设置spark.shuffle.unsafe.fastMergeEnabled为true,并且如果使用了压缩,需要压缩算法支持SerializedStreams的连接。
排序时并非将数据进行排序,而是将数据的地址指针进行排序
总结,UnsafeShuffleWriter是Tungsten最重要的应用,他的实现原理类似于SortShuffleWriter, 但是基于UnSafe API使用了定义的ShuffleExternalSorter和ShuffleInMemorySorter来存储和维护数据。
其整体流程为,所有的数据在插入前都需要序列化为二进制数组,然后再将其插入到定义的数据结构ShuffleExternalSorter中。
其次在ShuffleExternalSorter中定义了ShuffleInMemorySorter,它主要用于存储数据的partitionId和recordAddress, 另外定义了MemoryBlock页空间数组。
在ShuffleExternalSorter的insertRecord时会先,判断ShuffleInMemorySorter和当前内存空间是否足够新数据的插入,不够需要申请,申请失败则需要spill。
插入数据时会先写入占用内存空间的长度,再写入数据值,最后将recordAddress和partitionId插入ShuffleInMemorySorter中。在进行spill时会将ShuffleInMemorySorter中的数据进行排序,并按照分区生成FileSegment并统计分区的大小,然后遍历指针数组根据地址将对应的数据进行写出。在进行合并时可以直接使用UnSafe API直接操作序列化数据,返回汇总的文件。
通过UnsafeShuffleWriter只会产生两个文件,一个分区的数据文件,一个索引文件。整个UnsafeShuffleWriter过程只会产生2 * M 个中间文件。
今天就先到这里,通过上面的介绍,我们也留下些面试题:
为什么UnsafeShuffleWriter无法支持无法支持map端的aggregation?
为什么UnsafeShuffleWriter分区数的最大值为 (1 << 24) ?
ShuffleExternalSorter实现是基于JVM的吗?以及其在排序上有什么优化?